
문서 처리는 오랫동안 AI의 가장 실용적인 응용 분야 중 하나였습니다. 하지만 대부분의 OCR 솔루션은 정확성과 효율성 사이에서 불편한 타협을 강요합니다. Tesseract와 같은 기존 시스템은 광범위한 전처리를 필요로 합니다. 클라우드 API는 페이지당 요금을 부과하고 지연 시간을 추가합니다. 심지어 최신 비전-언어 모델조차 고해상도 문서 이미지에서 발생하는 토큰 폭발 문제로 어려움을 겪습니다.
DeepSeek-OCR 2는 이러한 상황을 완전히 바꿉니다. 버전 1의 "Contexts Optical Compression" 접근 방식을 기반으로, 새로운 버전은 "Visual Causal Flow"를 도입했습니다. 이 아키텍처는 단순히 문자를 인식하는 것을 넘어 시각적 관계와 맥락을 이해하며, 사람이 실제로 문서를 읽는 방식대로 문서를 처리합니다. 그 결과, 이미지를 64개의 토큰으로 압축하면서도 97%의 정확도를 달성하여, 단일 GPU에서 하루 200,000페이지 이상의 처리량을 가능하게 하는 모델이 탄생했습니다.
이 가이드는 기본적인 설정부터 프로덕션 배포에 이르기까지 모든 것을 다룹니다. 바로 복사하여 붙여넣고 실행할 수 있는 실용적인 코드도 함께 제공됩니다.
DeepSeek-OCR 2란 무엇인가요?
DeepSeek-OCR 2는 문서 이해 및 텍스트 추출을 위해 특별히 설계된 오픈 소스 비전-언어 모델입니다. DeepSeek AI가 2026년 1월에 출시한 이 모델은 원본 DeepSeek-OCR을 기반으로 새로운 "Visual Causal Flow" 아키텍처를 적용했습니다. 이 아키텍처는 문서 내 시각적 요소들이 서로 인과적으로 어떻게 관련되는지를 모델링합니다. 예를 들어, 테이블 헤더가 아래 셀의 해석 방식을 결정하거나, 그림 캡션이 위에 있는 차트를 설명한다는 것을 이해하는 식입니다.
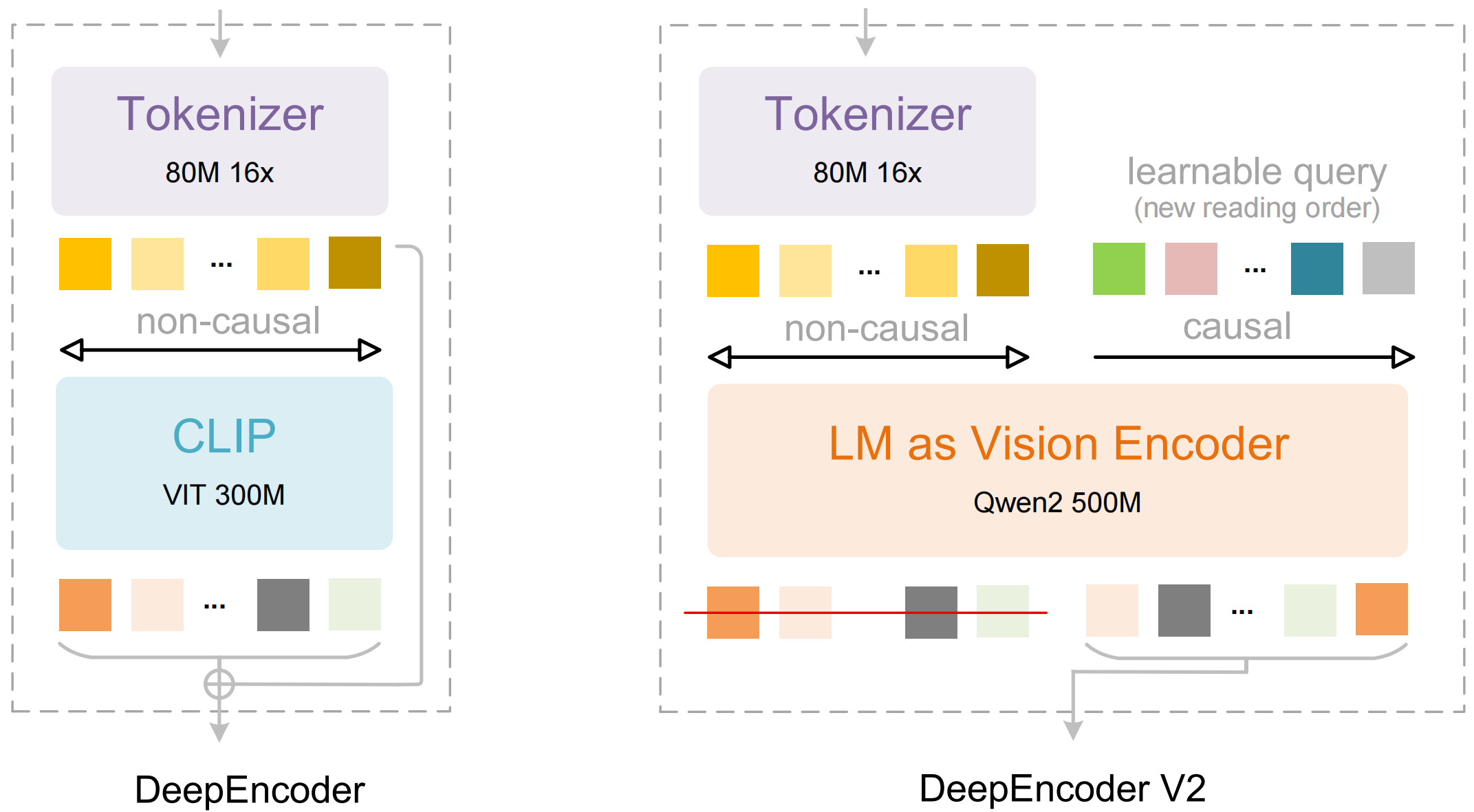
이 모델은 두 가지 주요 구성 요소로 이루어져 있습니다:
- DeepEncoder: 지역적 세부 정보 추출(SAM 기반, 8천만 매개변수)과 전역적 레이아웃 이해(CLIP 기반, 3억 매개변수)를 결합한 듀얼 비전 트랜스포머
- DeepSeek3B-MoE 디코더: 압축된 시각적 표현에서 구조화된 출력(마크다운, LaTeX, JSON)을 생성하는 전문가 혼합 언어 모델
DeepSeek-OCR 2의 차별점:
- 극대화된 압축: 1024×1024 이미지를 4,096개 패치에서 단 256개 토큰으로 축소—16배 감소
- 구조화된 출력: 올바른 테이블, 헤더 및 서식이 적용된 깔끔한 마크다운 생성
- 다중 형식 지원: PDF, 스캔 문서, 스크린샷, 손글씨 메모 등 다양한 형식 처리
- 100개 이상의 언어: 약 100개 언어를 다루는 3천만 페이지 데이터로 훈련됨
- 오픈 웨이트: MIT 라이선스, Hugging Face에서 이용 가능
주요 기능 및 아키텍처
Visual Causal Flow
버전 2의 주요 기능은 "Visual Causal Flow"입니다. 이는 단순한 OCR을 넘어 문서를 이해하는 새로운 접근 방식입니다. 페이지를 평평한 문자 그리드로 취급하는 대신, 모델은 시각적 요소들 간의 인과 관계를 학습합니다.
- 읽기 순서 추론: 다단 레이아웃에 대한 올바른 순서를 자동으로 결정
- 테이블 구조 이해: 헤더, 병합된 셀, 중첩된 테이블 인식
- 그림-캡션 연결: 이미지를 설명과 연결
- 수학 표현식 구문 분석: 인라인 및 블록 LaTeX를 정확하게 처리
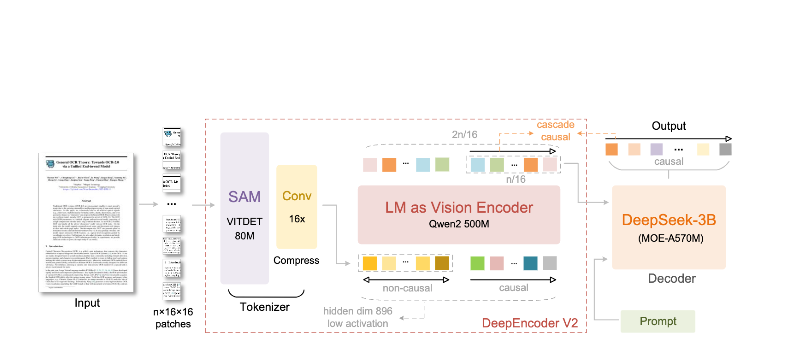
DeepEncoder 아키텍처
DeepEncoder는 마법이 일어나는 곳입니다. 관리 가능한 토큰 수를 유지하면서 고해상도 이미지를 처리합니다.
Input Image (1024×1024)
↓
SAM-base Block (80M params)
- Windowed attention for local detail
- Extracts fine-grained features
↓
CLIP-large Block (300M params)
- Global attention for layout
- Understands document structure
↓
Convolution Block
- 16× token reduction
- 4,096 patches → 256 tokens
↓
Output: Compressed Vision Tokens
압축률 vs. 정확성 트레이드오프
| 압축률 | 비전 토큰 | 정확성 |
|---|---|---|
| 4배 | 1,024 | 99% 이상 |
| 10배 | 256 | 97% |
| 16배 | 160 | 92% |
| 20배 | 128 | ~60% |
대부분의 애플리케이션에서 가장 적합한 지점은 10배 압축률입니다. 이는 97%의 정확도를 유지하면서 프로덕션 배포를 실용적으로 만드는 높은 처리량을 가능하게 합니다.
설치 및 설정
필수 구성 요소
- Python 3.10 이상 (3.12.9 권장)
- CUDA 11.8 이상 및 호환되는 NVIDIA GPU
- 최소 16GB GPU 메모리 (프로덕션 환경에서는 A100-40G 권장)
방법 1: vLLM 설치 (권장)
vLLM은 프로덕션 배포를 위한 최고의 성능을 제공합니다:
# 가상 환경 생성
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# CUDA 지원 vLLM 설치
pip install vllm>=0.8.5
# 최적의 성능을 위한 flash attention 설치
pip install flash-attn==2.7.3 --no-build-isolation
방법 2: Transformers 설치
개발 및 실험용:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
방법 3: Docker (프로덕션)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# 모델 사전 다운로드
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
설치 확인
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
Python 코드 예시
vLLM을 사용한 기본 OCR
문서 이미지에서 텍스트를 추출하는 가장 간단한 방법입니다:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# 모델 초기화
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# 문서 이미지 로드
image = Image.open("document.png").convert("RGB")
# 프롬프트 준비 - "Free OCR."은 표준 추출을 트리거합니다.
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# 샘플링 매개변수 구성
sampling_params = SamplingParams(
temperature=0.0, # OCR을 위한 확정적 결과
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # 테이블을 위한 <td>, </td>
},
skip_special_tokens=False,
)
# 출력 생성
outputs = llm.generate(model_input, sampling_params)
# 마크다운 텍스트 추출
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
여러 문서 일괄 처리
단일 배치로 여러 문서를 효율적으로 처리합니다:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""단일 배치로 여러 이미지 처리."""
# 모든 이미지 로드
images = [Image.open(p).convert("RGB") for p in image_paths]
# 배치 입력 준비
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# 한 번의 호출로 모든 출력 생성
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# 사용법
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # 처음 500자
print()
Transformers 직접 사용하기
추론 프로세스를 더 잘 제어하려면:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# GPU 설정
device = "cuda:0"
# 모델 및 토크나이저 로드
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# 이미지 로드 및 전처리
image = Image.open("document.png").convert("RGB")
# 다른 작업을 위한 다른 프롬프트
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"table": "<image>\nExtract all tables as markdown.",
"math": "<image>\nExtract mathematical expressions as LaTeX.",
}
# 선택한 프롬프트로 처리
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 입력에 이미지 추가 (모델별 전처리)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
높은 처리량을 위한 비동기 처리
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""단일 문서를 비동기적으로 처리합니다."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# 비동기 엔진 초기화
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# 여러 문서를 동시에 처리
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} 문자 추출됨")
asyncio.run(main())
프로덕션 환경에서 vLLM 사용
OpenAI 호환 서버 시작하기
DeepSeek-OCR 2를 API 서버로 배포하기:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
OpenAI SDK로 서버 호출하기
from openai import OpenAI
import base64
# 로컬 서버를 가리키는 클라이언트 초기화
client = OpenAI(
api_key="EMPTY", # 로컬 서버에는 필요 없음
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""이미지를 base64로 인코딩합니다."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""OCR API를 사용하여 문서에서 텍스트를 추출합니다."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# 사용법
result = ocr_document("invoice.png")
print(result)
URL과 함께 사용하기
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Apidog로 테스트하기
OCR API를 효과적으로 테스트하려면 입력 문서와 추출된 출력을 모두 시각화해야 합니다. Apidog는 DeepSeek-OCR 2를 실험하기 위한 직관적인 인터페이스를 제공합니다.
OCR 엔드포인트 설정
1단계: 새 요청 생성
- Apidog를 열고 새 프로젝트를 생성합니다.
http://localhost:8000/v1/chat/completions에 POST 요청을 추가합니다.
2단계: 헤더 구성
Content-Type: application/json
3단계: 요청 본문 구성
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
다양한 문서 유형 테스트
일반적인 문서 유형에 대해 저장된 요청을 생성합니다:
- 송장 추출 - 구조화된 데이터 추출 테스트
- 학술 논문 - LaTeX 수학 처리 테스트
- 손글씨 메모 - 필기 인식 테스트
- 다단 레이아웃 - 읽기 순서 추론 테스트
해상도 모드 비교
다양한 모드를 빠르게 테스트하려면 환경 변수를 설정하세요:
| 모드 | 해상도 | 토큰 | 사용 사례 |
|---|---|---|---|
tiny | 512×512 | 64 | 빠른 미리보기 |
small | 640×640 | 100 | 간단한 문서 |
base | 1024×1024 | 256 | 표준 문서 |
large | 1280×1280 | 400 | 조밀한 텍스트 |
gundam | 동적 | 가변 | 복잡한 레이아웃 |

해상도 모드 및 압축
DeepSeek-OCR 2는 각각 다른 사용 사례에 최적화된 다섯 가지 해상도 모드를 지원합니다:
Tiny 모드 (64 토큰)
최적: 빠른 텍스트 감지, 간단한 양식, 저해상도 입력
# tiny 모드 구성
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Small 모드 (100 토큰)
최적: 깔끔한 디지털 문서, 단일 열 텍스트
Base 모드 (256 토큰) - 기본값
최적: 대부분의 표준 문서, 송장, 편지
Large 모드 (400 토큰)
최적: 조밀한 학술 논문, 법률 문서
Gundam 모드 (동적)
최적: 다양한 레이아웃을 가진 복잡한 다중 페이지 문서
# 건담 모드는 여러 뷰를 결합합니다
# - 세부 사항을 위한 n × 640×640 지역 타일
# - 구조를 위한 1 × 1024×1024 전역 뷰
올바른 모드 선택
def select_mode(document_type: str, page_count: int) -> str:
"""문서 특성에 따라 최적의 해상도 모드를 선택합니다."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # 기본값
# 예시: 1024x1024 이미지와 A100-40G
batch_size = optimal_batch_size(40, (1024, 1024))
print(f"Recommended batch size: {batch_size}") # ~10
PDF 및 문서 처리
PDF를 이미지로 변환
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""PDF 페이지를 PIL 이미지로 변환합니다."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# 지정된 DPI로 렌더링
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# PIL 이미지로 변환
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# 사용법
images = pdf_to_images("report.pdf", dpi=200)
print(f"추출된 페이지 수: {len(images)} 페이지")
전체 PDF 처리 파이프라인
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""전체 PDF를 처리하고 결합된 마크다운을 반환합니다."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# 페이지를 이미지로 변환
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# 페이지 OCR
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# 사용법
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# 파일로 저장
Path("output.md").write_text(markdown)
벤치마크 성능
정확성 벤치마크
| 벤치마크 | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| 페이지당 토큰 수 | 100-256 | 256 | 6,000+ |
| Fox (10배 압축) | 97% | — | — |
| Fox (20배 압축) | 60% | — | — |
처리량 성능
| 하드웨어 | 일일 페이지 수 | 시간당 페이지 수 |
|---|---|---|
| A100-40G (단일) | 200,000+ | ~8,300 |
| A100-40G × 20 | 3,300만+ | ~140만 |
| RTX 4090 | ~80,000 | ~3,300 |
| RTX 3090 | ~50,000 | ~2,100 |
문서 유형별 실제 정확도
| 문서 유형 | 정확성 | 비고 |
|---|---|---|
| 디지털 PDF | 98% 이상 | 최상의 성능 |
| 스캔 문서 | 95% 이상 | 양질의 스캔 |
| 재무 보고서 | 92% | 복잡한 테이블 |
| 손글씨 메모 | 85% | 가독성에 따라 다름 |
| 역사 문서 | 80% | 품질 저하 |
모범 사례 및 최적화
이미지 전처리
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""최적의 OCR을 위해 문서 이미지를 전처리합니다."""
# 필요한 경우 RGB로 변환
if image.mode != "RGB":
image = image.convert("RGB")
# 너무 작으면 크기 조정 (가장 짧은 변이 최소 512px)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# 스캔 문서의 대비 강화
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(1.2)
# 약간 선명하게
image = image.filter(ImageFilter.SHARPEN)
return image
프롬프트 엔지니어링
# 다른 작업을 위한 다른 프롬프트
PROMPTS = {
# 표준 OCR - 가장 빠르고 대부분의 경우에 적합
"ocr": "<image>\nFree OCR.",
# 마크다운 변환 - 더 나은 구조 보존
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
# 테이블 추출 - 표 형식 데이터에 최적화
"table": "<image>\nExtract all tables in markdown format.",
# 수학 추출 - 학술/과학 문서용
"math": "<image>\nExtract all text and mathematical expressions. Use LaTeX for math.",
# 특정 필드 - 양식 추출용
"fields": "<image>\nExtract the following fields: name, date, amount, signature.",
}
메모리 최적화
# 제한된 GPU 메모리용
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.8, # 여유 공간 남기기
max_model_len=8192, # 최대 컨텍스트 줄이기
enable_chunked_prefill=True, # 더 나은 메모리 효율성
)
배치 전략
def optimal_batch_size(gpu_memory_