
알리바바의 통이 딥리서치(Tongyi DeepResearch)는 300억 매개변수 규모의 MoE(Mixture of Experts) 모델을 통해 자율 AI 에이전트를 재정의합니다. 이 모델은 토큰당 30억 매개변수만 활성화하여 효율적이고 정밀한 웹 연구를 가능하게 합니다. 이 오픈소스 강자는 Humanity's Last Exam(32.9% 대 OpenAI o3의 24.9%) 및 xbench-DeepSearch(75.0% 대 67.0%)와 같은 벤치마크에서 뛰어난 성능을 보여주며, 개발자들이 법률 분석부터 여행 일정까지 복잡하고 다단계적인 쿼리를 독점적인 종속 없이 처리할 수 있도록 지원합니다.
통이 연구소(Tongyi Lab)의 엔지니어들은 장기적인 추론과 동적인 도구 사용을 정면으로 해결하기 위해 이 에이전트를 설계했습니다. 그 결과, 허깅페이스(Hugging Face)를 통해 로컬에서 실행되면서도 실제 환경 합성에서 폐쇄형 모델보다 뛰어난 성능을 보입니다. 이 기술 분석에서는 통이 딥리서치의 희소 아키텍처, 자동화된 데이터 파이프라인, RL 최적화 훈련, 벤치마크에서의 우위, 그리고 배포 팁을 자세히 살펴봅니다. 마지막에는 통이 딥리서치와 Apidog 같은 도구들이 어떻게 프로젝트를 위한 확장 가능한 에이전트 AI를 가능하게 하는지 알게 될 것입니다.
통이 딥리서치 이해하기: 핵심 개념 및 혁신
통이 딥리서치는 심층 정보 검색 및 합성에 중점을 두어 에이전트 AI를 재정의합니다. 단문 생성에 탁월한 기존의 대규모 언어 모델(LLM)과 달리, 이 에이전트는 웹 브라우저와 같은 동적인 환경을 탐색하여 미묘한 통찰력을 발견합니다. 특히, MoE(Mixture of Experts) 아키텍처를 사용하여 전체 300억 매개변수 중 토큰당 30억 매개변수만 선택적으로 활성화합니다. 이러한 효율성은 자원 제약이 있는 하드웨어에서도 강력한 성능을 가능하게 하며, 최대 128K 토큰까지 높은 문맥 인식을 유지합니다.
또한, 이 모델은 인간과 유사한 의사 결정을 모방하는 추론 패러다임과 원활하게 통합됩니다. ReAct 모드에서는 무거운 프롬프트 엔지니어링 없이 생각, 행동, 관찰 단계를 기본적으로 순환합니다. 더 까다로운 작업을 위해 Heavy 모드는 IterResearch 프레임워크를 활성화하여, 문맥 과부하를 피하기 위해 병렬 에이전트 탐색을 조정합니다. 결과적으로 사용자들은 학술 문헌 검토나 시장 분석과 같이 반복적인 정제가 필요한 시나리오에서 우수한 결과를 얻을 수 있습니다.
통이 딥리서치를 차별화하는 점은 개방성에 대한 헌신입니다. 모델 가중치부터 훈련 코드에 이르는 전체 스택은 허깅페이스와 GitHub와 같은 플랫폼에 있습니다. 개발자들은 Tongyi-DeepResearch-30B-A3B 변형에 직접 접근하여 도메인별 요구 사항에 맞춰 미세 조정할 수 있습니다. 또한, 표준 Python 환경과의 호환성은 진입 장벽을 낮춥니다. 예를 들어, Python 3.10으로 Conda 환경을 설정한 후 간단한 pip 명령으로 설치할 수 있습니다.
실용적인 유용성으로 전환하여, 통이 딥리서치는 검증 가능한 출력을 요구하는 애플리케이션에 힘을 실어줍니다. 법률 연구에서는 법규와 판례를 분석하고 출처를 정확하게 인용합니다. 마찬가지로, 여행 계획에서는 실시간 데이터를 교차 참조하여 여러 날의 일정을 구성합니다. 이러한 기능은 의도적인 설계 철학에서 비롯됩니다: 단순한 예측보다 에이전트적 추론을 우선시하는 것입니다.
통이 딥리서치의 아키텍처: 효율성과 성능의 만남
통이 딥리서치의 핵심은 희소 MoE 설계를 활용하여 계산 요구 사항과 표현력을 균형 있게 맞추는 것입니다. 이 모델은 토큰당 전문가의 일부만 활성화하며, 쿼리 복잡성에 따라 입력을 동적으로 라우팅합니다. 이 접근 방식은 밀집 모델에 비해 지연 시간을 최대 90%까지 줄여 실시간 에이전트 배포에 적합하게 만듭니다. 또한, 128K 컨텍스트 창은 긴 문서 체인이나 스레드 웹 검색과 관련된 작업에 필수적인 확장된 상호 작용을 지원합니다.
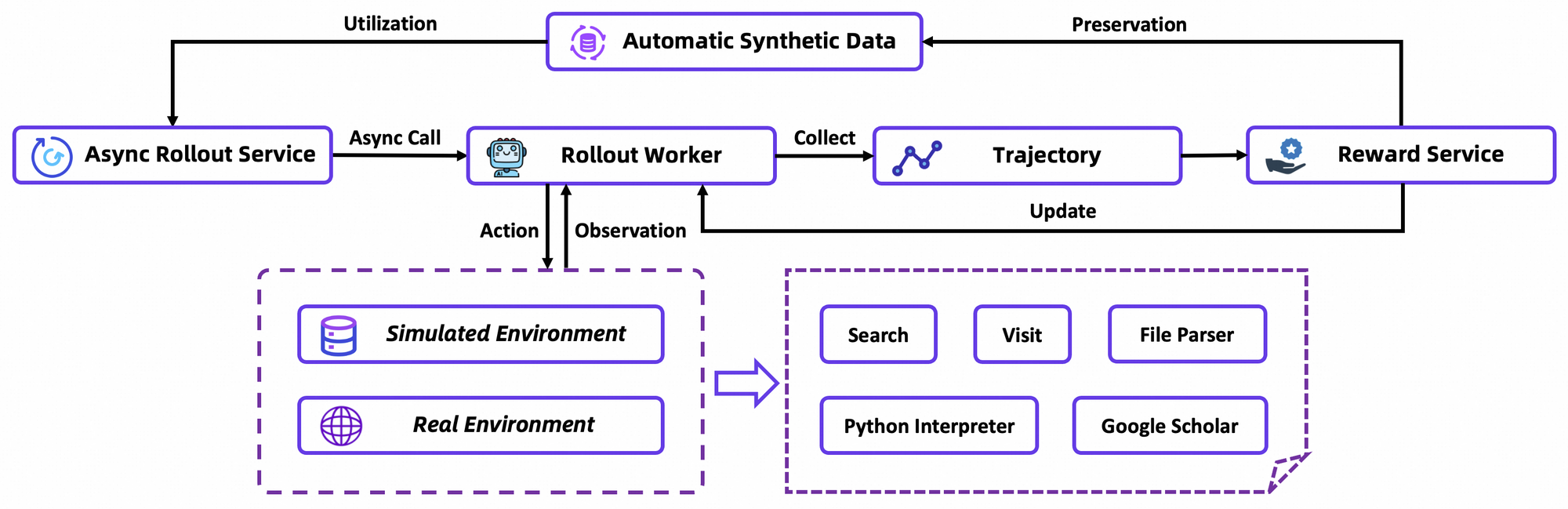
주요 아키텍처 구성 요소에는 행동 접두사 및 관찰 구분 기호와 같은 에이전트 토큰에 최적화된 맞춤형 토크나이저와 브라우저 탐색, 검색 및 계산을 위한 내장 도구 모음이 포함됩니다. 이 프레임워크는 에이전트가 안정적인 환경에서 시뮬레이션된 롤아웃을 통해 학습하는 온-정책 강화 학습(RL) 통합을 지원합니다. 결과적으로, 이 모델은 도구 사용 벤치마크에서 높은 점수를 기록하여 도구 호출에서 환각 현상이 적음을 보여줍니다.
또한, 통이 딥리서치는 그래프 기반 데이터 합성을 통해 파생된 엔티티 기반 지식 메모리를 통합합니다. 이 메커니즘은 응답을 사실적 엔티티에 고정하여 추적 가능성을 향상시킵니다. 예를 들어, 양자 컴퓨팅 발전에 대한 쿼리 중에 에이전트는 WebSailor와 같은 도구를 통해 논문을 검색하고 합성하여 검증 가능한 출처에 기반한 결과를 제공합니다. 따라서 이 아키텍처는 정보를 처리할 뿐만 아니라 적극적으로 큐레이션합니다.
예를 들어, 모델의 다중 모달 입력 처리 방식을 살펴보겠습니다. 주로 텍스트 기반이지만, GitHub 리포지토리를 통한 확장을 통해 이미지 파서 또는 코드 실행기와 통합할 수 있습니다. 개발자들은 추론 스크립트에서 JSONL 형식의 데이터셋 경로를 지정하여 이를 구성합니다. 이처럼 아키텍처는 확장성을 촉진하며 오픈소스 커뮤니티의 기여를 환영합니다.
자동화된 데이터 합성: 통이 딥리서치 역량 강화
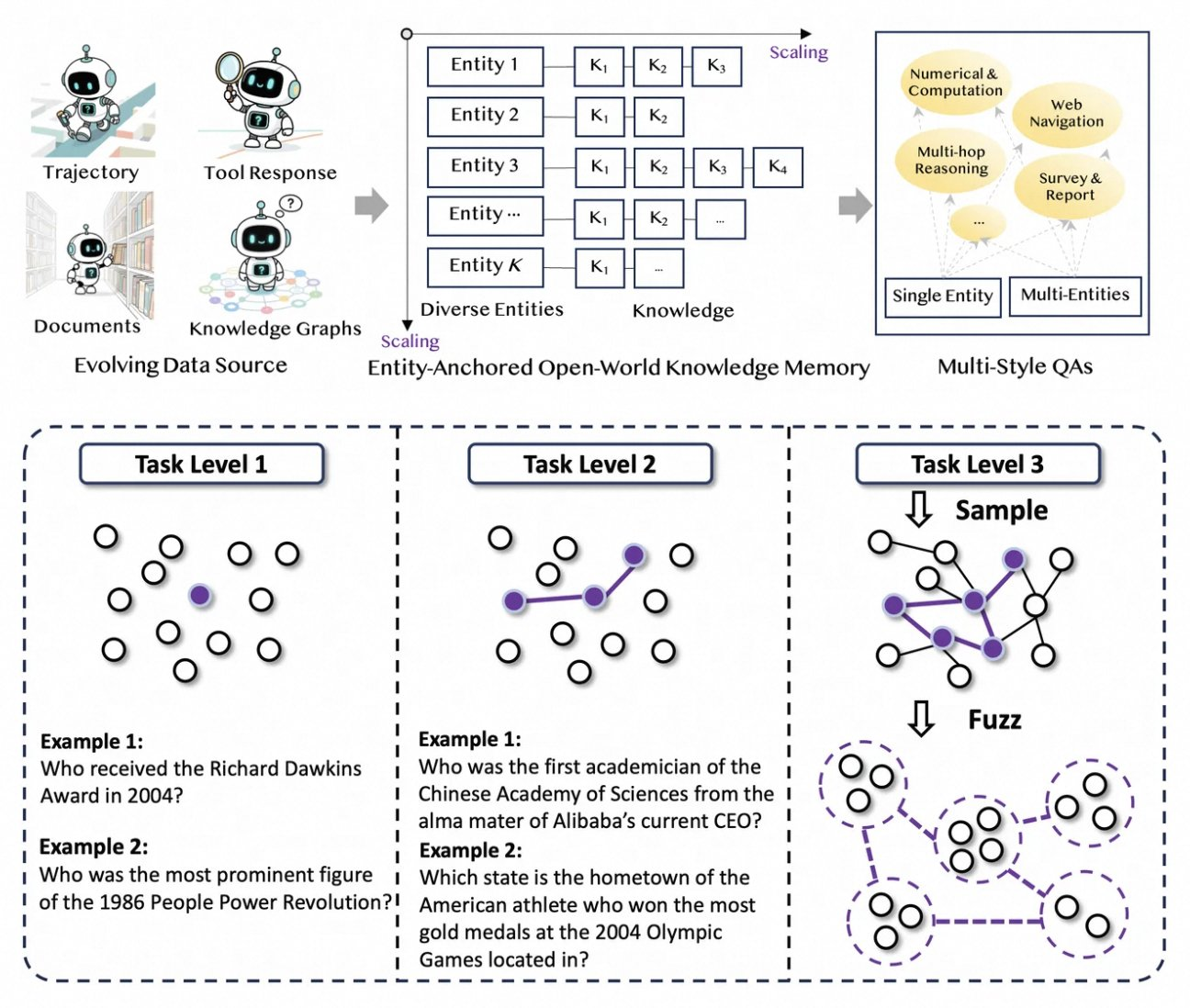
통이 딥리서치는 인간 주석 병목 현상을 제거하는 새롭고 완전히 자동화된 데이터 파이프라인을 통해 발전합니다. 이 과정은 AgentFounder로 시작됩니다. AgentFounder는 원시 코퍼스(문서, 웹 크롤링, 지식 그래프)를 엔티티 기반 QA 쌍으로 재구성하는 합성 엔진입니다. 이 단계는 추론 체인, 도구 호출 및 의사 결정 트리를 포함하는 지속적인 사전 훈련(CPT)을 위한 다양한 궤적을 생성합니다.
다음으로, 파이프라인은 반복적인 업그레이드를 통해 난이도를 높입니다. 후처리 훈련을 위해 WebSailor-V2와 같은 그래프 기반 방법을 사용하여 집합론을 통해 모델링된 박사 학위 수준의 질문과 같은 "초인적인" 도전을 시뮬레이션합니다. 결과적으로 데이터셋은 수백만 개의 고품질 상호 작용을 포함하며, 모델이 여러 도메인에 걸쳐 일반화되도록 보장합니다. 특히, 이러한 자동화는 컴퓨팅과 선형적으로 확장되어 수동 큐레이션 없이 지속적인 업데이트를 가능하게 합니다.
또한, 통이 딥리서치는 견고성을 위해 다중 스타일 데이터를 통합합니다. 행동 합성 기록은 도구 사용 패턴을 포착하고, 다단계 QA 쌍은 계획 기술을 정교하게 만듭니다. 실제로 이는 시끄러운 웹 환경에 적응하여 관련 없는 스니펫을 효과적으로 필터링하는 에이전트를 생성합니다. 개발자를 위해 리포지토리에는 이 파이프라인을 복제하여 사용자 지정 데이터셋 생성을 가능하게 하는 스크립트가 제공됩니다.
양보다 질을 우선시함으로써, 합성 전략은 분포 변화와 같은 에이전트 훈련의 일반적인 함정을 해결합니다. 결과적으로, 이러한 방식으로 훈련된 모델은 벤치마크에서의 우위에서 볼 수 있듯이 실제 작업과 우수한 정렬을 보여줍니다.
종단 간 훈련 파이프라인: CPT에서 RL 최적화까지
통이 딥리서치의 훈련은 에이전트 CPT, 지도 미세 조정(SFT), 강화 학습(RL)이라는 원활한 파이프라인으로 진행됩니다. 먼저, CPT는 기본 모델을 방대한 에이전트 데이터에 노출시켜 웹 탐색 사전 지식과 최신성 신호를 주입합니다. 이 단계는 궤적에 대한 마스크 언어 모델링을 통해 암묵적 계획과 같은 잠재된 기능을 활성화합니다.

CPT에 이어 SFT는 합성 롤아웃을 사용하여 정확한 행동 공식화를 가르치면서 모델을 지시 형식에 맞춥니다. 여기서 모델은 일관된 ReAct 사이클을 생성하고 관찰 구문 분석의 오류를 최소화하는 방법을 학습합니다. 원활하게 전환하면서 RL 단계는 맞춤형 온-정책 알고리즘인 GRPO(Group Relative Policy Optimization)를 사용합니다.
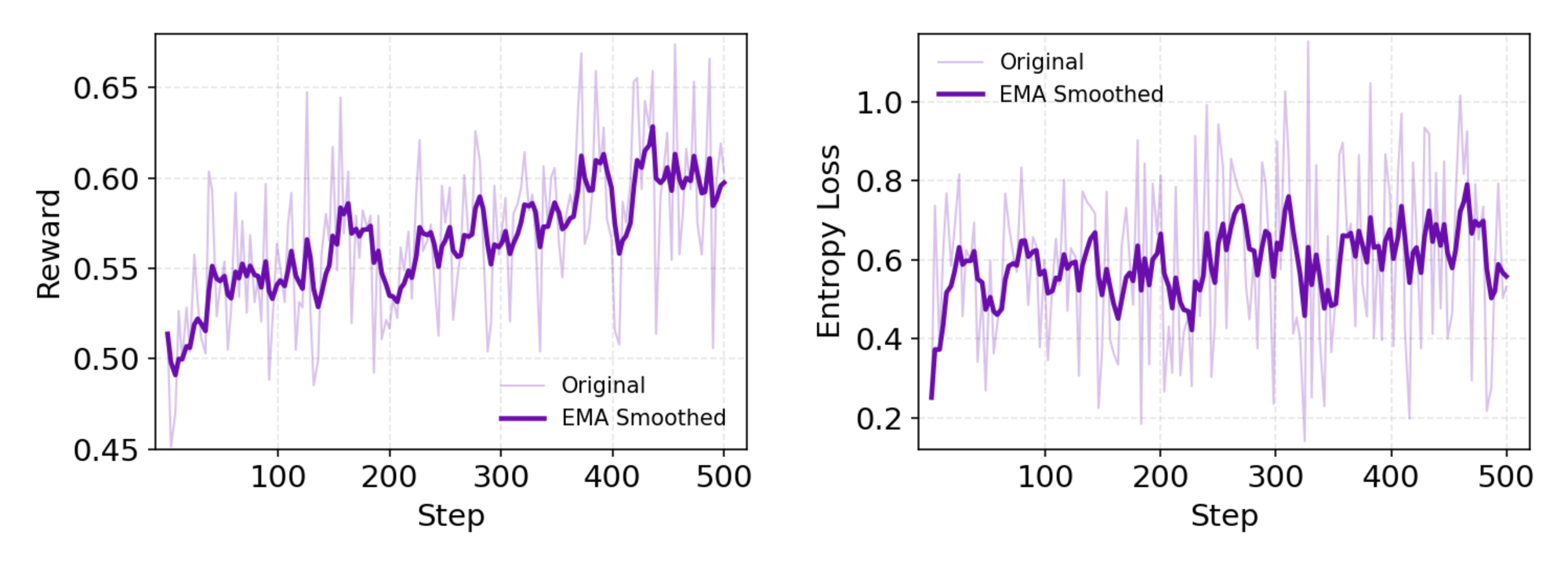
GRPO는 leave-one-out 이점 추정치를 사용하여 토큰 수준 정책 기울기를 계산하여 비정상적인 설정에서 분산을 줄입니다. 또한 음성 샘플을 보수적으로 필터링하여 사용자 지정 시뮬레이터(도구 샌드박스와 결합된 오프라인 위키백과 데이터베이스)에서 업데이트를 안정화합니다. rLLM 프레임워크를 통한 비동기 롤아웃은 수렴 속도를 높여 적당한 컴퓨팅으로 SOTA(State-Of-The-Art)를 달성합니다.
자세히 설명하면, RL 환경은 브라우저 상호 작용을 충실하게 시뮬레이션하며, 단일 행동보다 다단계 성공에 보상을 제공합니다. 이는 에이전트가 부분적인 실패를 반복하는 장기적인 계획을 촉진합니다. 기술적인 참고 사항으로, 손실 함수는 보수성을 위해 KL 발산(KL divergence)을 통합하여 모드 붕괴를 방지합니다. 개발자들은 리포지토리의 평가 스크립트를 통해 이를 복제하고 사용자 지정 정책을 벤치마킹할 수 있습니다.
전반적으로 이 파이프라인은 사일로 없이 사전 훈련과 배포를 연결하여 시행착오를 통해 진화하는 에이전트를 생성하는 획기적인 발전을 의미합니다.
벤치마크 성능: 통이 딥리서치가 뛰어난 이유
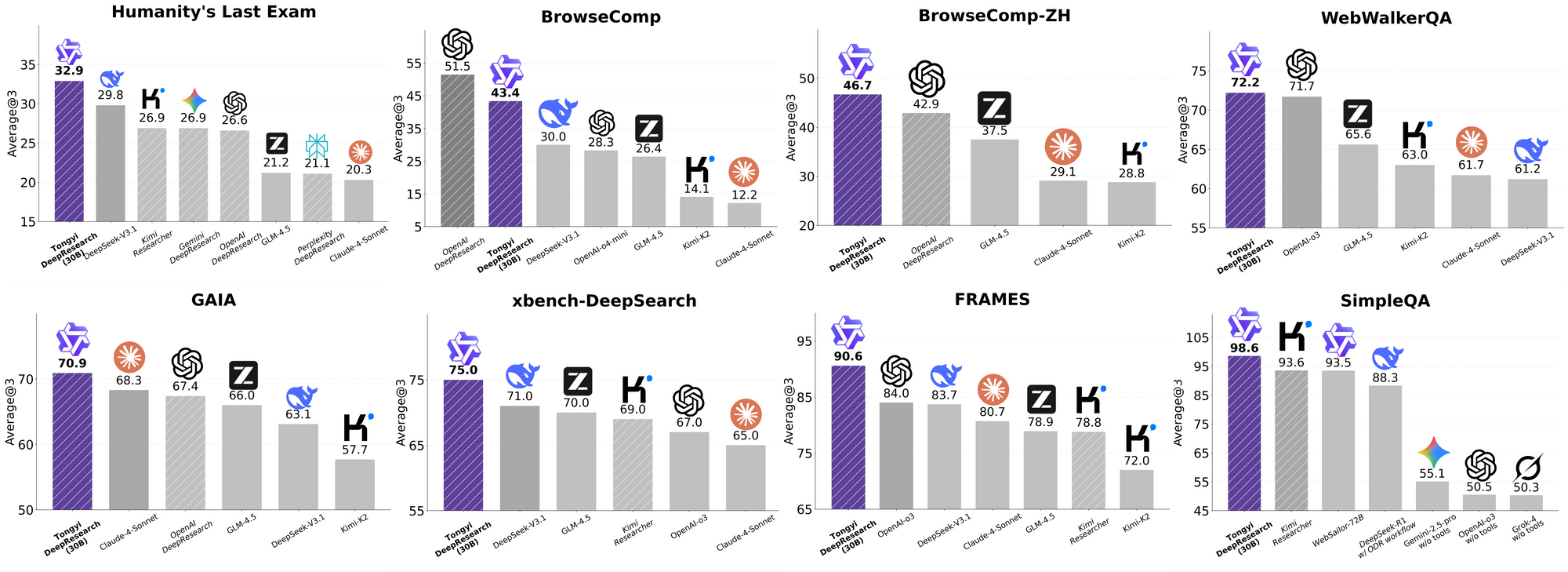
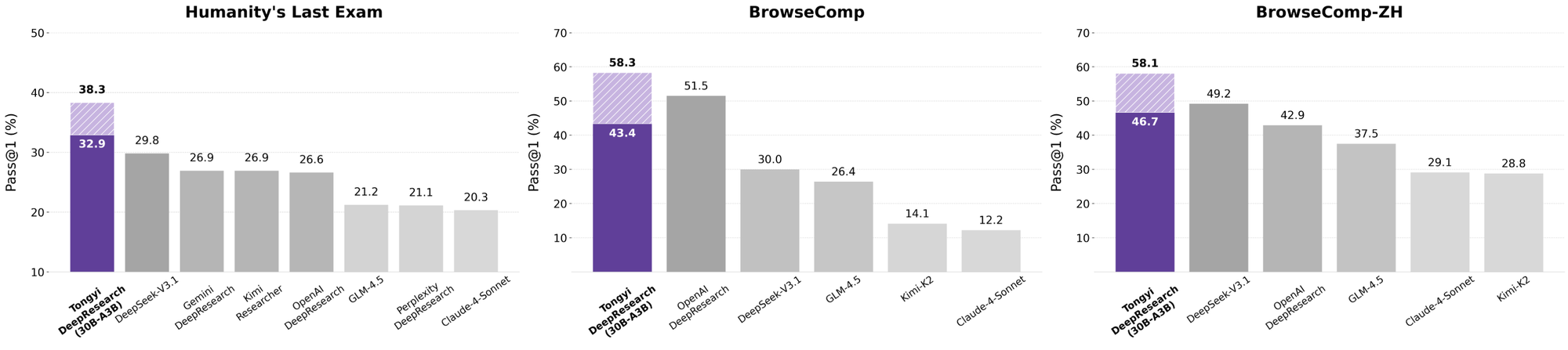
통이 딥리서치는 엄격한 에이전트 벤치마크에서 빛을 발하며 그 설계를 입증합니다. 학술적 추론 능력 테스트인 Humanity's Last Exam(HLE)에서 ReAct 모드에서 32.9점을 기록하여 OpenAI의 o3(24.9점)를 능가합니다. Heavy 모드에서는 이 격차가 38.3점으로 더욱 벌어져 IterResearch의 효율성을 강조합니다.
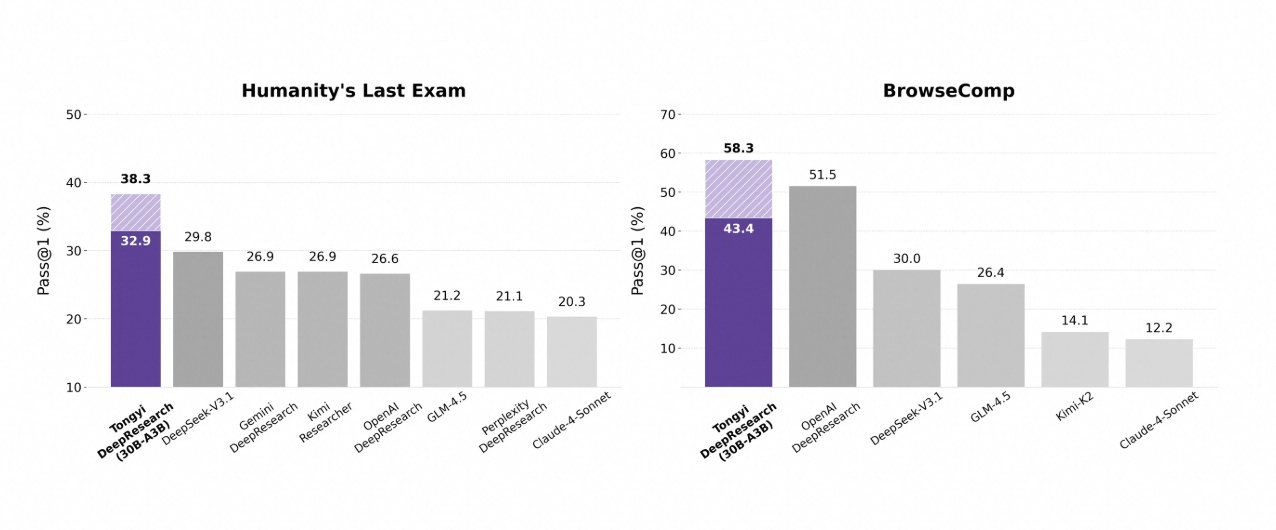
마찬가지로 BrowseComp는 복잡한 정보 탐색을 평가합니다. 통이는 효율성 면에서 o3의 49.7(EN) 및 58.1(ZH)을 약간 앞서는 43.4(EN) 및 46.7(ZH)을 달성했습니다. 심층 쿼리를 위한 사용자 중심 벤치마크인 xbench-DeepSearch에서는 통이가 75.0점을 기록하여 o3의 67.0점보다 높아 우수한 검색 합성을 강조합니다.
다른 지표들도 이를 뒷받침합니다: FRAMES 90.6점(o3의 84.0점 대비), GAIA 70.9점, SimpleQA 95.0점. 비교 차트는 HLE, BrowseComp, xbench, FRAMES 등에서 통이 딥리서치의 막대가 Gemini, Claude 및 기타 경쟁사들을 압도하는 모습을 시각화합니다. 파란색 막대는 통이의 우위를, 회색 기준선은 경쟁사들의 부족한 점을 나타냅니다.
이러한 결과는 검색 작업을 위한 선택적 전문가 라우팅과 같은 목표 최적화에서 비롯됩니다. 따라서 통이 딥리서치는 경쟁할 뿐만 아니라 오픈소스 에이전트 분야를 선도하고 있습니다.
통이 딥리서치와 업계 선두 주자 비교
개발자들이 AI 에이전트를 평가할 때, 비교는 진정한 가치를 드러냅니다. 통이 딥리서치(30B-A3B)는 o3의 더 큰 규모에도 불구하고 HLE(32.9 대 24.9)와 xbench(75.0 대 67.0)에서 OpenAI의 o3를 능가합니다. 구글의 Gemini에 비해 BrowseComp-ZH에서 35.2점을 기록하며 10점의 우위를 점합니다.
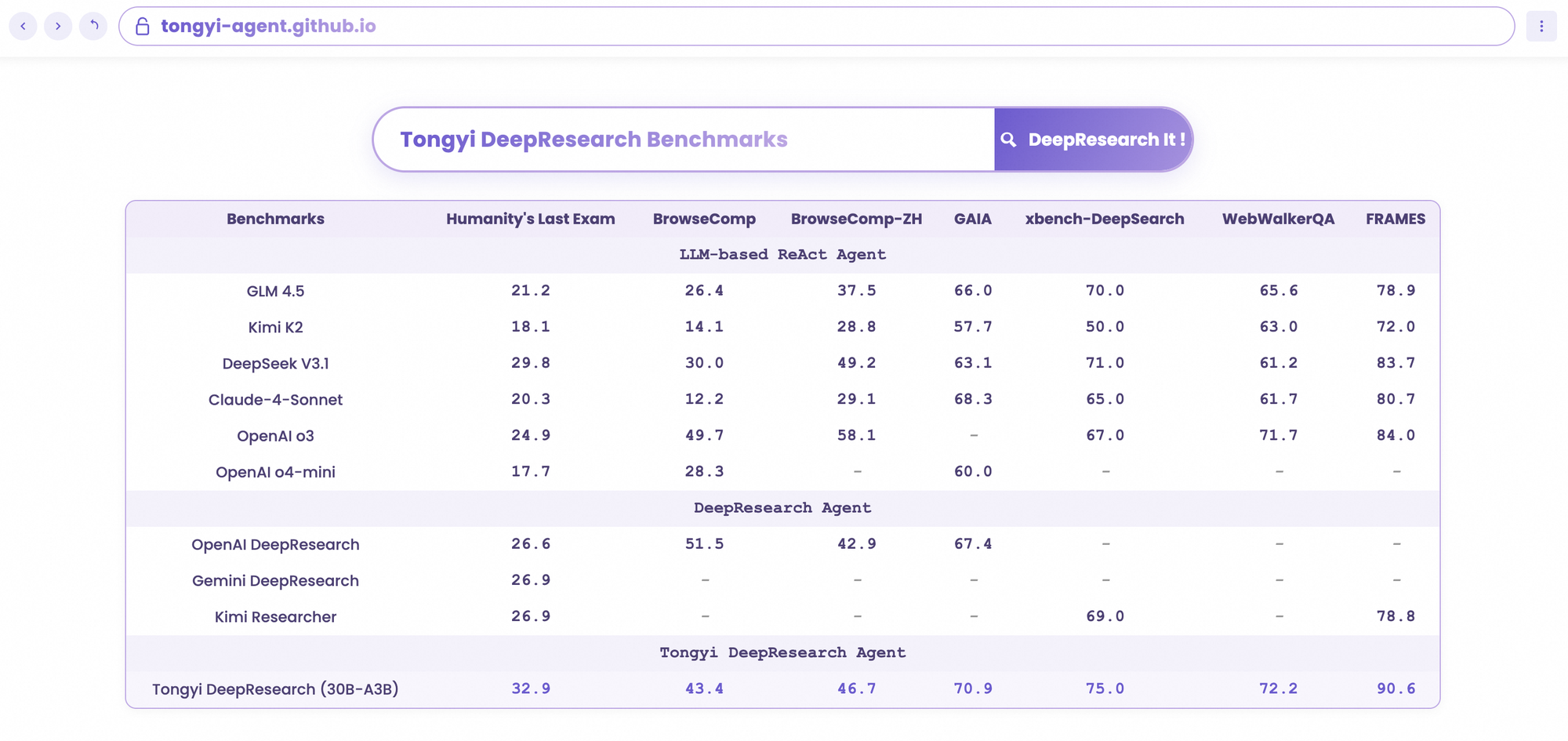
Claude 3.5 Sonnet과 같은 독점 모델은 도구 사용에서 뒤처집니다. 통이의 FRAMES 점수 90.6점은 Sonnet의 84.3점을 압도합니다. Llama 변형과 같은 오픈소스 경쟁자들은 HLE에서 21.1점과 같이 훨씬 더 뒤처집니다. 통이의 MoE 희소성은 더 적은 추론 컴퓨팅을 소비하면서 이러한 동등성을 가능하게 합니다.
또한, 접근성은 판도를 바꿉니다. o3가 API 크레딧을 요구하는 반면, 통이는 허깅페이스를 통해 로컬에서 실행됩니다. API 사용이 많은 워크플로의 경우, Apidog와 함께 사용하여 엔드포인트를 모의하고 도구 호출을 효율적으로 시뮬레이션할 수 있습니다.
본질적으로 통이 딥리서치는 엘리트 성능을 민주화하며 폐쇄형 생태계에 도전합니다.
실제 적용 사례: 통이 딥리서치 활용
통이 딥리서치는 벤치마크를 넘어 실질적인 영향을 미칩니다. 알리바바의 내비게이션 앱인 Gaode Mate에서는 Heavy 모드를 통해 항공편, 호텔, 이벤트를 병렬로 쿼리하여 복잡한 여행을 계획합니다. 사용자들은 인용이 포함된 합성된 일정을 받아 계획 시간을 70% 단축할 수 있습니다.
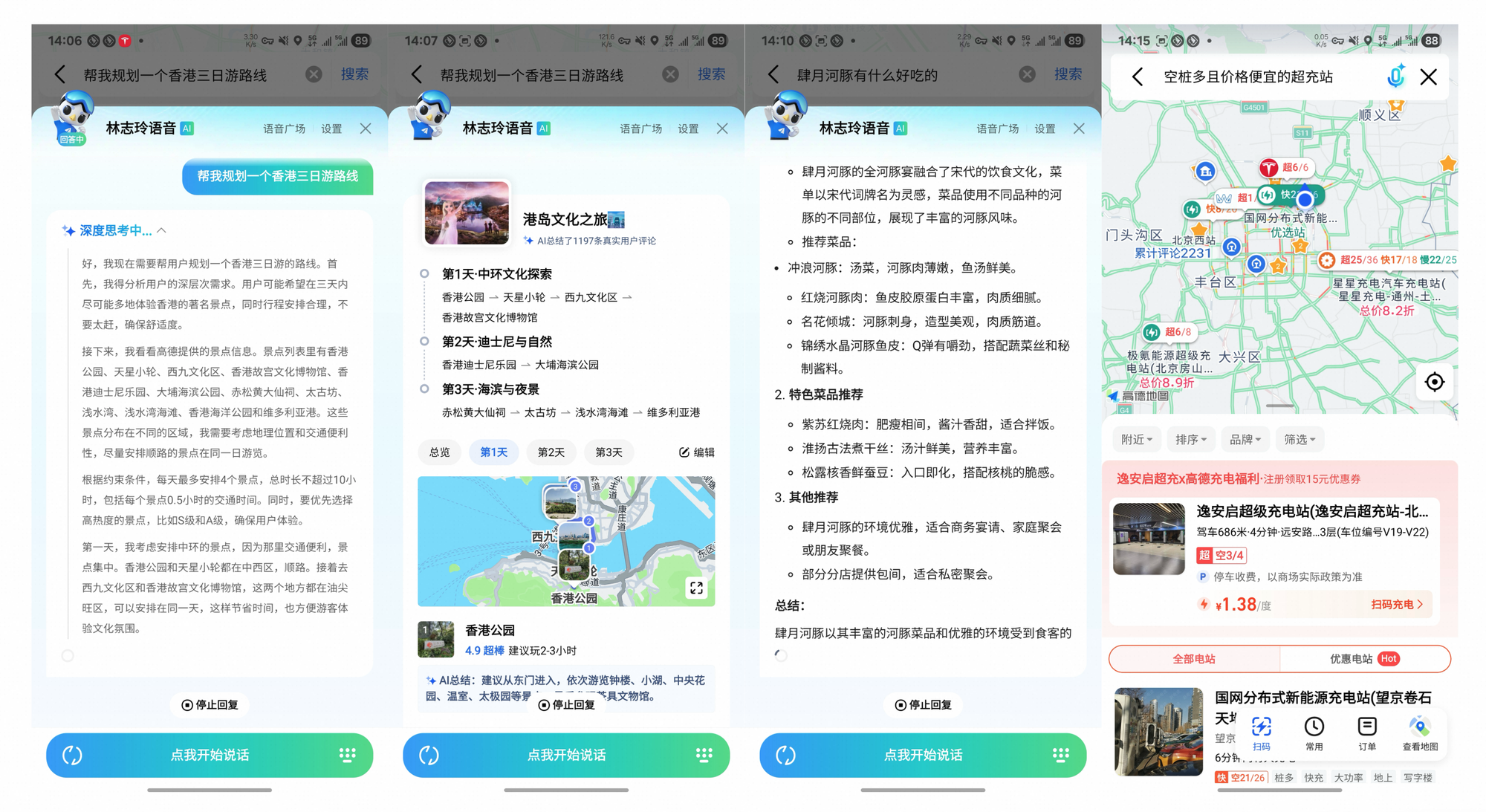
마찬가지로 통이 파루이(Tongyi FaRui)는 법률 연구에 혁명을 일으킵니다. 이 에이전트는 법규를 분석하고, 판례를 교차 참조하며, 검증 가능한 링크가 포함된 요약 보고서를 생성합니다. 전문가들은 출력을 신속하게 검증하여 중요한 영역에서의 오류를 최소화합니다.
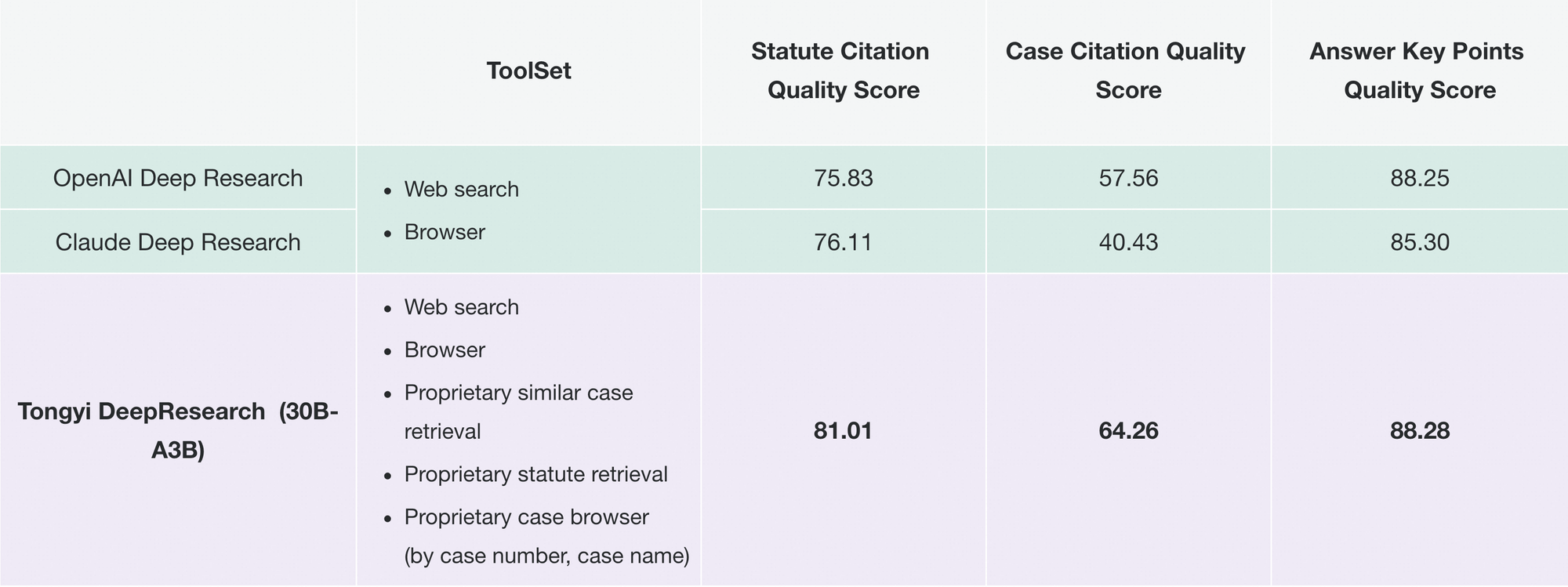
이 외에도 기업들은 경쟁사 데이터를 스크랩하고 트렌드를 합성하는 등 시장 정보 분석에 통이 딥리서치를 활용합니다. 리포지토리의 모듈성은 JSON 구성을 통해 사용자 지정 도구를 추가하는 등 이러한 확장을 지원합니다.
도입이 증가함에 따라 통이 딥리서치는 LangChain과 같은 생태계에 통합되어 에이전트 스웜을 강화합니다. API 개발자를 위해 Apidog는 배포 전에 통합을 검증하여 이를 보완합니다.
이러한 사례들은 소비자 앱부터 B2B 도구에 이르기까지 모델이 신뢰할 수 있는 자율성을 제공한다는 확장성을 보여줍니다.
통이 딥리서치 시작하기: 개발자 가이드
GitHub 리포지토리를 사용하여 통이 딥리서치를 손쉽게 구현하세요. 먼저 Conda 환경을 생성합니다: conda create -n deepresearch python=3.10. 활성화하고 설치합니다: pip install -r requirements.txt.
eval_data/에 question 및 answer 키를 사용하여 JSONL 형식으로 데이터를 준비합니다. 파일의 경우, 질문 앞에 이름을 붙여 file_corpus/에 저장합니다. 모델 경로(예: Hugging Face URL) 및 도구용 API 키를 위해 run_react_infer.sh를 편집합니다.
실행: bash run_react_infer.sh. 출력은 지정된 경로에 저장되며 분석 준비가 완료됩니다.
Heavy 모드의 경우, 코드에서 IterResearch 매개변수를 구성합니다. 에이전트 수와 라운드를 설정합니다. evaluation/ 스크립트를 통해 벤치마크를 수행하고 기준선과 비교합니다.
로그를 통해 문제를 해결하세요. 토크나이저 불일치와 같은 일반적인 문제는 BF16 텐서 검사를 통해 해결됩니다. 기능을 향상시키려면 Apidog를 무료로 다운로드하여 API 시뮬레이션을 하고, 실제 호출 없이 도구 엔드포인트를 테스트하세요.
이 설정은 에이전트 프로토타입을 신속하게 만들 수 있도록 해줍니다.
향후 방향: 통이 딥리서치 추가 확장
앞으로 통이 연구소는 128K를 넘어선 컨텍스트 확장을 목표로 하며, 책 한 권 분량의 분석과 같은 초장기적인 시야를 가능하게 합니다. 그들은 더 큰 MoE 기반에서 검증을 계획하고 확장성 한계를 탐구하고 있습니다.
RL 개선 사항에는 효율성을 위한 부분적 롤아웃과 변화를 완화하기 위한 오프-정책 방법이 포함됩니다. 커뮤니티 기여를 통해 비전 또는 다국어 도구를 통합하여 범위를 넓힐 수 있습니다.
오픈소스가 발전함에 따라 통이 딥리서치는 협력적인 발전을 이끌며 AGI(인공 일반 지능) 추구를 촉진할 것입니다.
결론: 통이 딥리서치 시대를 맞이하세요
통이 딥리서치는 효율성, 개방성, 강력함을 결합하여 에이전트 AI를 혁신합니다. 벤치마크, 아키텍처 및 애플리케이션은 통이 딥리서치를 OpenAI의 제품과 같은 경쟁자들을 능가하는 선두 주자로 자리매김하게 합니다. 개발자 여러분, 이 강력한 기능을 활용하세요. 모델을 다운로드하고, 실험하며, Apidog와 통합하여 원활한 API를 만드세요.
자율성을 향해 나아가는 분야에서 통이 딥리서치는 발전을 가속화합니다. 오늘부터 구축을 시작하세요. 통찰력이 기다리고 있습니다.