
웹 개발의 끊임없이 진화하는 환경에서, GraphQL는 전통적인 REST API의 강력한 대안으로 떠오르며, 데이터 가져오기에 더욱 유연하고 효율적인 접근 방식을 제공합니다. 이 창의적인 기술을 탐험하고 Spring과 원활하게 통합하려는 당신은 올바른 곳에 와 있습니다.
우리의 포괄적인 GraphQL 튜토리얼에 오신 것을 환영합니다. 여기에서 GraphQL의 개념을 해명하고 Spring을 사용하여 GraphQL을 시작하는 과정을 안내할 것입니다.
Spring GraphQL이란 무엇이며 주요 기능은 무엇인가?
Spring GraphQL은 개발자가 원활하게 GraphQL 기반 API를 구축할 수 있도록 지원하는 인기 있는 Spring Framework의 확장입니다. Spring Boot의 손쉬운 개발 환경과 GraphQL의 유연함과 효율성을 결합하여 현대적인 API 개발에 이상적인 선택이 됩니다.
Spring GraphQL의 주요 기능:
- 스키마 우선 개발: Spring GraphQL을 사용하면 개발자는 GraphQL 스키마 정의 언어(Schema Definition Language, SDL)를 사용하여 API의 스키마를 정의하는 것부터 시작할 수 있습니다. 이 스키마 우선 접근 방식은 API 설계가 명확하고 처음부터 잘 정의되도록 하여 보다 조직적이고 구조화된 개발 프로세스를 촉진합니다.
- 리졸버를 통한 데이터 가져오기: Spring GraphQL은 리졸버를 제공하여 데이터 가져오기를 간소화합니다. 리졸버는 GraphQL 쿼리의 각 필드에 필요한 데이터를 가져오는 책임이 있습니다. 개발자는 데이터베이스, 외부 API 또는 기타 데이터 저장소와 같은 다양한 출처에서 데이터를 검색하기 위해 리졸버를 구현할 수 있어 더 큰 유연성과 재사용성을 가능하게 합니다.
- Spring 생태계와의 통합: Spring 가족의 일원으로서 Spring GraphQL은 데이터베이스 상호작용을 위한 Spring Data JPA 및 인증 및 권한 부여를 위한 Spring Security와 같은 다른 Spring 구성 요소와 원활하게 통합됩니다. 이러한 긴밀한 통합은 매끄럽고 응집력 있는 개발 경험을 보장합니다.
- 구독을 통한 실시간 업데이트: Spring GraphQL은 GraphQL 구독을 통해 실시간 데이터 업데이트를 지원합니다. 구독을 통해 클라이언트는 특정 이벤트에 구독하고 해당 이벤트가 발생할 때 실시간 데이터 업데이트를 받을 수 있습니다. 이 기능은 채팅 시스템이나 실시간 데이터 피드와 같은 실시간 애플리케이션을 구축하는 데 특히 유용합니다.
환경 설정 방법은?
GraphQL과 Spring의 여정을 시작하기 전에 설정이 준비되어 있는지 확인하세요. Spring Boot 프로젝트를 GraphQL로 구축하기 위한 환경을 준비하는 방법은 다음과 같습니다:
전제 조건:
- JDK 17: 시스템에 JDK 17이 설치되어 있는지 확인하세요. Oracle 또는 OpenJDK에서 다운로드할 수 있습니다.
- 기본 Spring Boot 이해: Spring Boot의 기본 개념을 알고 있어야 합니다. 이는 GraphQL을 혼합할 때 도움이 됩니다.
Spring Boot 프로젝트 생성:
Spring Initializr: 시작하세요.spring.io, Spring Boot 프로젝트의 시작 지점입니다.
먼저 프로젝트 설정 세부정보를 제공하세요. 프로젝트 이름을 지정하고 역 도메인 형식(예: com.example)의 그룹 이름을 지정하며 앱의 Java 코드에 대한 패키지 이름을 지정합니다. 필요한 경우 설명 및 버전과 같은 메타데이터도 포함할 수 있습니다.
두 번째로, 필요한 종속성을 추가합니다. 종속성 섹션에서 "Spring Web"을 선택하여 Spring으로 웹 애플리케이션을 만들기 위한 지원을 활성화합니다. 마찬가지로 "Spring GraphQL"을 선택하여 GraphQL 관련 기능을 활성화합니다. 프로젝트를 구성하고 종속성을 선택했으면 "Generate" 버튼을 클릭하여 진행합니다.
IDE로 프로젝트 가져오기:
먼저 ZIP 파일의 내용을 추출하여 그 내용을 엽니다. 두 번째로, IntelliJ IDEA와 같은 통합 개발 환경(IDE)을 엽니다. 그런 다음 이전에 추출한 프로젝트를 가져옵니다.
그게 다입니다! 환경이 설정되었고, Spring Boot 프로젝트를 만들었으며, GraphQL이 포함되었습니다. IDE는 코딩 모험을 위한 놀이터입니다.
데이터 레이어 설정 방법은?
이 섹션에서는 GraphQL이 데이터 검색 및 관리에 어떻게 도움이 되는지를 보여주기 위해 간단한 예제로 커피샵을 만듭니다.
예제 소개:
커피샵의 API를 개발하여 메뉴와 주문을 관리한다고 상상해 보세요. 이를 설명하기 위해 커피 품목과 고객에 대한 기본 데이터 모델을 정의하고 이 데이터를 처리할 서비스를 설정합니다.
기본 데이터 모델 정의:
두 개의 간단한 데이터 모델인 Coffee와 Size를 생성하는 것으로 시작하겠습니다. 이 모델은 적절한 정보를 나타내는 속성을 가진 Java 클래스로 구현됩니다.
두 개의 서로 다른 파일에 두 개의 클래스를 생성해야 하며 각 클래스에는 속성을 위한 생성자, getter 및 setter를 추가해야 합니다.
public class Coffee {
private int id;
private String name;
private Size size;
// 생성자, getter, setter
}
public class Size {
private int id;
private String name;
// 생성자, getter, setter
}
이 클래스를 생성하고 추가한 후, Spring Boot 프로젝트 내의 적절한 패키지에 위치해 있는지 확인해야 합니다. 패키지 구조는 Spring Initializr에서 프로젝트를 생성할 때 제공한 패키지 이름을 반영해야 합니다.
다음은 Coffee.java 클래스에 setter, getter 및 생성자를 추가하는 방법입니다.
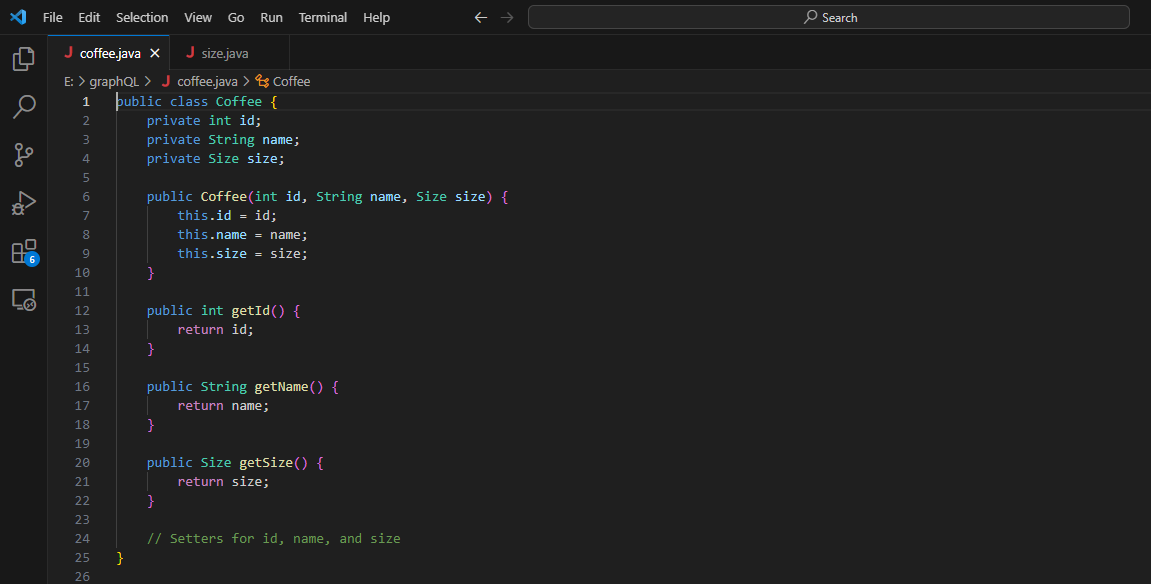
데이터 관리 설정:
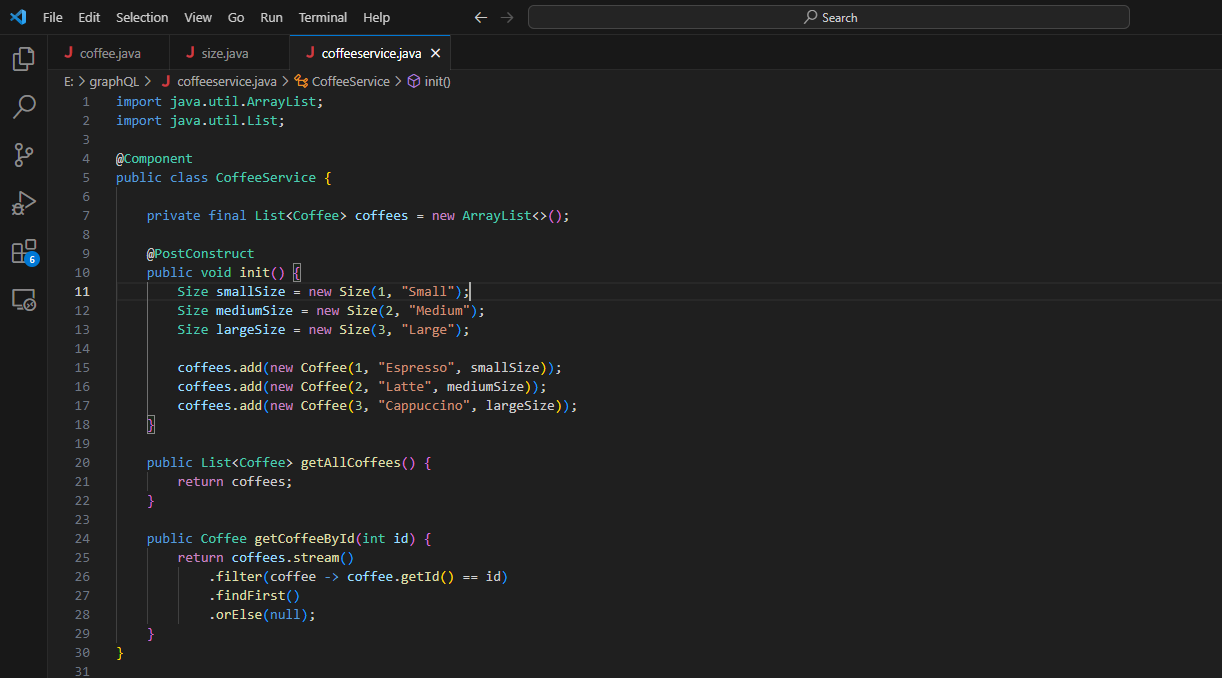
커피 데이터를 관리하는 인메모리 데이터 저장소 역할을 하는 간단한 CoffeeService 클래스를 생성합니다. 이를 보여주기 위해 몇 가지 샘플 커피 항목으로 이 저장소를 채울 것입니다.
import java.util.ArrayList;
import java.util.List;
@Component
public class CoffeeService {
private final List<Coffee> coffees = new ArrayList<>();
@PostConstruct
public void init() {
Size smallSize = new Size(1, "작은 사이즈");
Size mediumSize = new Size(2, "중간 사이즈");
Size largeSize = new Size(3, "큰 사이즈");
coffees.add(new Coffee(1, "에스프레소", smallSize));
coffees.add(new Coffee(2, "라떼", mediumSize));
coffees.add(new Coffee(3, "카푸치노", largeSize));
}
public List<Coffee> getAllCoffees() {
return coffees;
}
public Coffee getCoffeeById(int id) {
return coffees.stream()
.filter(coffee -> coffee.getId() == id)
.findFirst()
.orElse(null);
}
}
CoffeeService 클래스는 커피 관련 데이터를 관리하며, 저장 및 검색 시스템 역할을 합니다. 생성 시 샘플 커피 데이터를 초기화하고, 모든 커피를 검색하거나 특정 ID로 커피를 검색하는 메서드를 제공합니다. 이 추상화는 데이터 접근 및 조작을 간소화하여 GraphQL 스키마 내에서의 상호작용을 위한 데이터를 준비합니다.
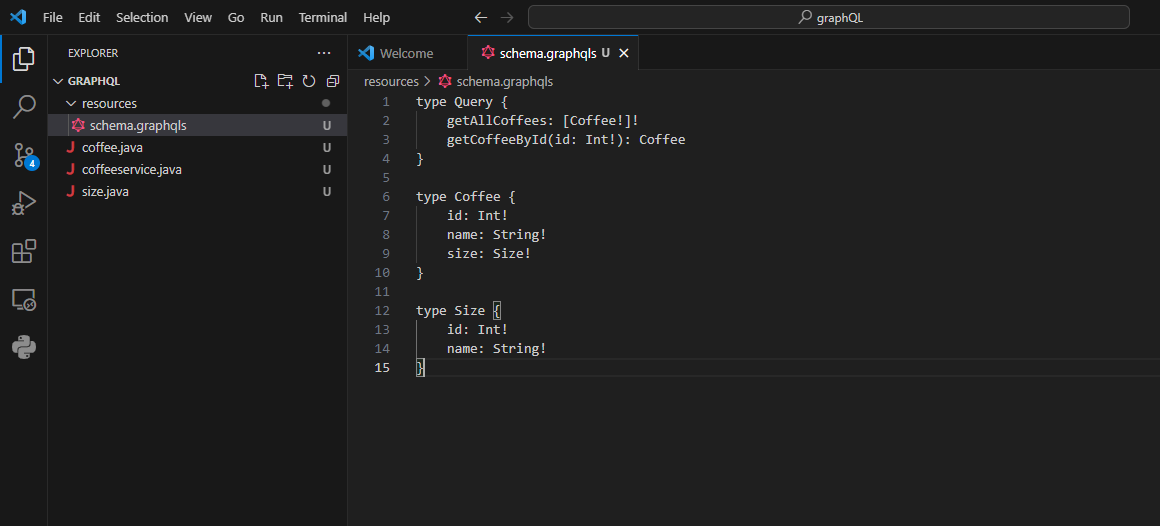
GraphQL 스키마 생성 방법:
schema.graphqls라는 이름의 파일을 src/main/resources 폴더에 생성하고 스키마 정의 언어(Schema Definition Language, SDL)를 사용하여 GraphQL 스키마를 정의합니다.
type Query {
getAllCoffees: [Coffee!]!
getCoffeeById(id: Int!): Coffee
}
type Coffee {
id: Int!
name: String!
size: Size!
}
type Size {
id: Int!
name: String!
}
다음은 이를 수행하는 방법입니다.
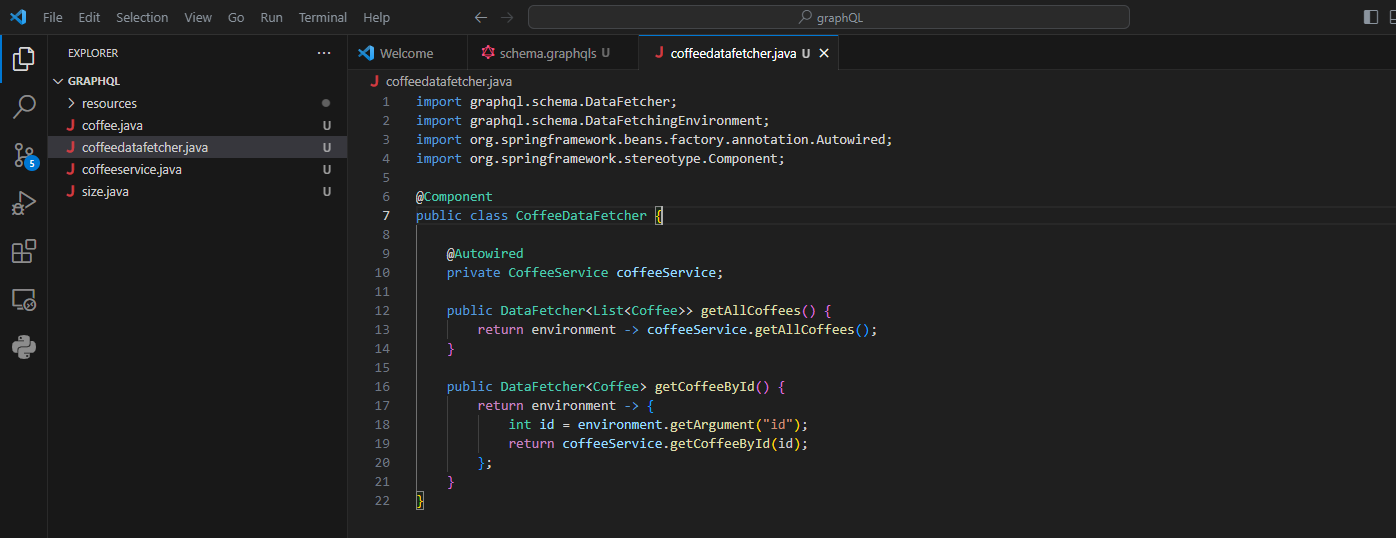
데이터 페처 생성:
코드는 GraphQL 쿼리를 위한 데이터를 검색하는 책임이 있는 CoffeeDataFetcher라는 클래스를 정의합니다. 이 클래스는 Spring이 관리할 수 있도록 @Component로 주석 처리되어 있습니다. getAllCoffees() 페처는 coffeeService.getAllCoffees() 메서드를 사용하여 커피 아이템 목록을 검색합니다. getCoffeeById() 페처는 쿼리 인수에서 ID를 추출하고 이를 사용하여 CoffeeService에서 특정 커피 항목을 검색합니다.
import graphql.schema.DataFetcher;
import graphql.schema.DataFetchingEnvironment;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class CoffeeDataFetcher {
@Autowired
private CoffeeService coffeeService;
public DataFetcher<List<Coffee>> getAllCoffees() {
return environment -> coffeeService.getAllCoffees();
}
public DataFetcher<Coffee> getCoffeeById() {
return environment -> {
int id = environment.getArgument("id");
return coffeeService.getCoffeeById(id);
};
}
}
다음은 이를 수행하는 방법입니다.
GraphQL 컨트롤러 생성:
Spring에서 GraphQL 컨트롤러는 GraphQL 스키마와 상호작용할 수 있는 엔드포인트를 제공합니다. 이러한 컨트롤러는 들어오는 쿼리를 처리하고 해당 데이터를 반환합니다.
import graphql.GraphQL;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class GraphQLController {
@Autowired
private GraphQL graphQL;
@PostMapping("/graphql")
public Map<String, Object> executeQuery(@RequestBody String query) {
ExecutionResult executionResult = graphQL.execute(query);
return executionResult.toSpecification();
}
}
이 컨트롤러는 들어오는 GraphQL 쿼리를 처리하고 GraphQL 스키마와 상호작용합니다. GraphQL 쿼리를 요청 본문에 POST 요청으로 받아들이는 /graphql라는 RESTful 엔드포인트를 제공합니다. 그런 다음 컨트롤러는 GraphQL 인스턴스를 사용하여 쿼리를 실행하고 실행 결과를 맵으로 반환합니다.
Spring GraphQL은 개발자가 GraphQL 쿼리 언어를 사용하여 효율적인 API를 구축할 수 있게 해주는 강력한 프레임워크입니다. 데이터 검색을 여러 엔드포인트가 지시하는 전통적인 REST API와 달리, GraphQL은 클라이언트가 단일 요청에서 필요한 데이터가 무엇인지 정확히 지정할 수 있게 하여 데이터의 과다 가져오기 또는 부족 가져오기를 줄여줍니다. Spring GraphQL은 Spring 생태계의 강점을 활용하여 Spring Boot의 단순성과 GraphQL의 유연성을 결합합니다.
이 과정에는 데이터 모델 정의, 데이터를 관리할 서비스 계층 생성, 유형 및 쿼리를 갖춘 스키마 설정이 포함됩니다. Spring GraphQL의 스키마 우선 접근 방식은 명확한 설계와 구조화된 개발 프로세스를 보장합니다. 리졸버를 통한 데이터 가져오기가 단순화되며, 구독을 통한 실시간 업데이트가 용이해집니다.
GraphQL 테스트 도구:
GraphQL은 API를 구축하는 인기 있는 방법이 되었으며, API가 제대로 작동하는지 확인하기 위한 테스트가 중요합니다. 테스트 도구는 개발자가 GraphQL API가 의도대로 작동하는지 확인하는 데 도움을 줍니다.
이 도구 중 하나는 Apidog로, API 테스트를 용이하게 하기 위한 다양한 기능을 제공합니다. Apidog이 무엇을 할 수 있는지 살펴보고 GraphQL에 유용한 기타 테스트 도구를 언급하겠습니다.
Apidog:
Apidog은 API 생성 프로세스 전체를 아우르는 다용도 툴킷입니다. 디자인, 테스트 등을 돕는 API에 대한 스위스 군용 칼과 같습니다. Apidog이 제공하는 것은 다음과 같습니다:
Apidog이 GraphQL 테스트를 위해 제공하는 것:
Apidog은 GraphQL API 테스트에도 잘 작동합니다. 다음과 같은 기능이 있습니다:
- GraphQL 지원: Apidog은 GraphQL API를 테스트하고 디버깅할 수 있습니다.
- 자동화: 작업을 자동화하고 API 정의를 동기화된 상태로 유지할 수 있습니다.
- 데이터베이스 통합: Apidog은 더 나은 테스트를 위해 데이터베이스에 연결할 수 있습니다.
결론
API가 계속 진화함에 따라 GraphQL, Spring GraphQL 및 Apidog와 같은 도구의 조합이 API 제작 방식을 재구성합니다. 이러한 조합은 개발자에게 더 많은 제어력과 효율성을 제공하여 강력하고 적응 가능하며 성능이 뛰어난 API를 생성합니다.


