
2025년 4월 13일, SkyworkAI은 세 가지 모델로 구성된 Skywork-OR1(Open Reasoner 1) 시리즈를 공개했습니다: Skywork-OR1-Math-7B, Skywork-OR1-7B-Preview 및 Skywork-OR1-32B-Preview.
- 이 모델들은 수학 및 코드 추론 능력에 특화된 대규모 규칙 기반 강화 학습으로 훈련되었습니다.
- 딥시크의 증류된 아키텍처를 기반으로 제작되었으며: 7B 변종은 DeepSeek-R1-Distill-Qwen-7B를 기본 모델로 사용하고, 32B 모델은 DeepSeek-R1-Distill-Qwen-32B를 기반으로 합니다.
개발 팀이 함께 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요? 최대 생산성을 위해?
Apidog는 귀하의 모든 요구를 충족하며, Postman을 훨씬 더 저렴한 가격에 대체합니다!

Skywork-OR1-32B: 또 다른 오픈소스 추론 모델이 아닙니다
Skywork-OR1-32B-Preview 모델은 328억 개의 파라미터를 포함하며 BF16 텐서 타입을 사용해 수치 정밀도를 유지합니다. safetensors 형식으로 배포되며 Qwen2 아키텍처를 기반으로 합니다. 모델 저장소에 따르면, 기본 모델인 DeepSeek-R1-Distill-Qwen-32B와 동일한 아키텍처를 유지하되 수학 및 코딩 추론 작업에 특화된 훈련을 거쳤습니다.
Skywork 모델 패밀리의 기본 기술 정보를 살펴보겠습니다:
Skywork-OR1-32B-Preview
- 파라미터 수: 328억
- 기본 모델: DeepSeek-R1-Distill-Qwen-32B
- 텐서 유형: BF16
- 특화 분야: 일반 목적 추론
- 주요 성능:
- AIME24: 79.7 (Avg@32)
- AIME25: 69.0 (Avg@32)
- LiveCodeBench: 63.9 (Avg@4)
32B 모델은 기본 모델 대비 AIME24에서 6.8점, AIME25에서 10.0점 향상된 성능을 보입니다. 671B 파라미터의 DeepSeek-R1과 유사한 성능을 파라미터의 4.9%만으로 달성하여 파라미터 효율성을 입증했습니다.
Skywork-OR1-Math-7B
- 파라미터 수: 76.2억
- 기본 모델: DeepSeek-R1-Distill-Qwen-7B
- 텐서 유형: BF16
- 특화 분야: 수학적 추론
- 주요 성능:
- AIME24: 69.8 (Avg@32)
- AIME25: 52.3 (Avg@32)
- LiveCodeBench: 43.6 (Avg@4)
이 모델은 수학 작업에서 기본 DeepSeek-R1-Distill-Qwen-7B 대비 크게 우수한 성능을 보였습니다(AIME24: 69.8 vs 55.5, AIME25: 52.3 vs 39.2). 이는 특화된 훈련 접근법의 효과를 입증합니다.
Skywork-OR1-7B-Preview
- 파라미터 수: 76.2억
- 기본 모델: DeepSeek-R1-Distill-Qwen-7B
- 텐서 유형: BF16
- 특화 분야: 일반 목적 추론
- 주요 성능:
- AIME24: 63.6 (Avg@32)
- AIME25: 45.8 (Avg@32)
- LiveCodeBench: 43.9 (Avg@4)
Math-7B 변종보다 수학적 특화도는 낮지만 수학과 코딩 작업 간 더 균형 잡힌 성능을 제공합니다.
Skywork-OR1-32B의 훈련 데이터셋
Skywork-OR1 훈련 데이터셋에는 다음이 포함됩니다:
- 검증 가능하고 다양한 11만 개의 수학 문제
- 1만 4천 개의 코딩 질문
- 모든 자료는 오픈소스 데이터셋에서 추출
데이터 처리 파이프라인
- 모델 인식 난이도 추정: 각 문제는 모델의 현재 능력에 상대적인 난이도 점수를 부여받아 대상 훈련이 가능합니다.
- 품질 평가: 훈련 전 엄격한 필터링이 적용되어 데이터셋 품질을 보장합니다.
- 오프라인 및 온라인 필터링: 2단계 필터링 프로세스가 구현됩니다:
- 훈련 전 차선의 예제 제거(오프라인)
- 훈련 중 문제 선택 동적 조정(온라인)
- 거부 샘플링: 최적의 학습 곡선 유지를 위해 훈련 예제 분포를 제어합니다.
고급 강화 학습 훈련 파이프라인
이 모델들은 다음과 같은 기술적 향상이 가미된 GRPO(Generative Reinforcement via Policy Optimization)의 맞춤형 버전을 사용합니다:
- 다단계 훈련 파이프라인: 각 단계는 이전에 획득한 능력에 기반해 훈련이 진행됩니다. GitHub 저장소에는 AIME24 점수가 훈련 단계에 따라 향상되는 것을 보여주는 그래프가 포함되어 있습니다.
- 적응형 엔트로피 제어: 탐험과 활용 간의 균형을 동적으로 조정하여 수렴 안정성을 유지하면서 넓은 탐색을 유도합니다.
- VERL 프레임워크 커스텀 포크: 추론 작업에 특화되게 수정된 VERL 프로젝트 버전으로 훈련됩니다.
전체 논문은 여기에서 읽을 수 있습니다.
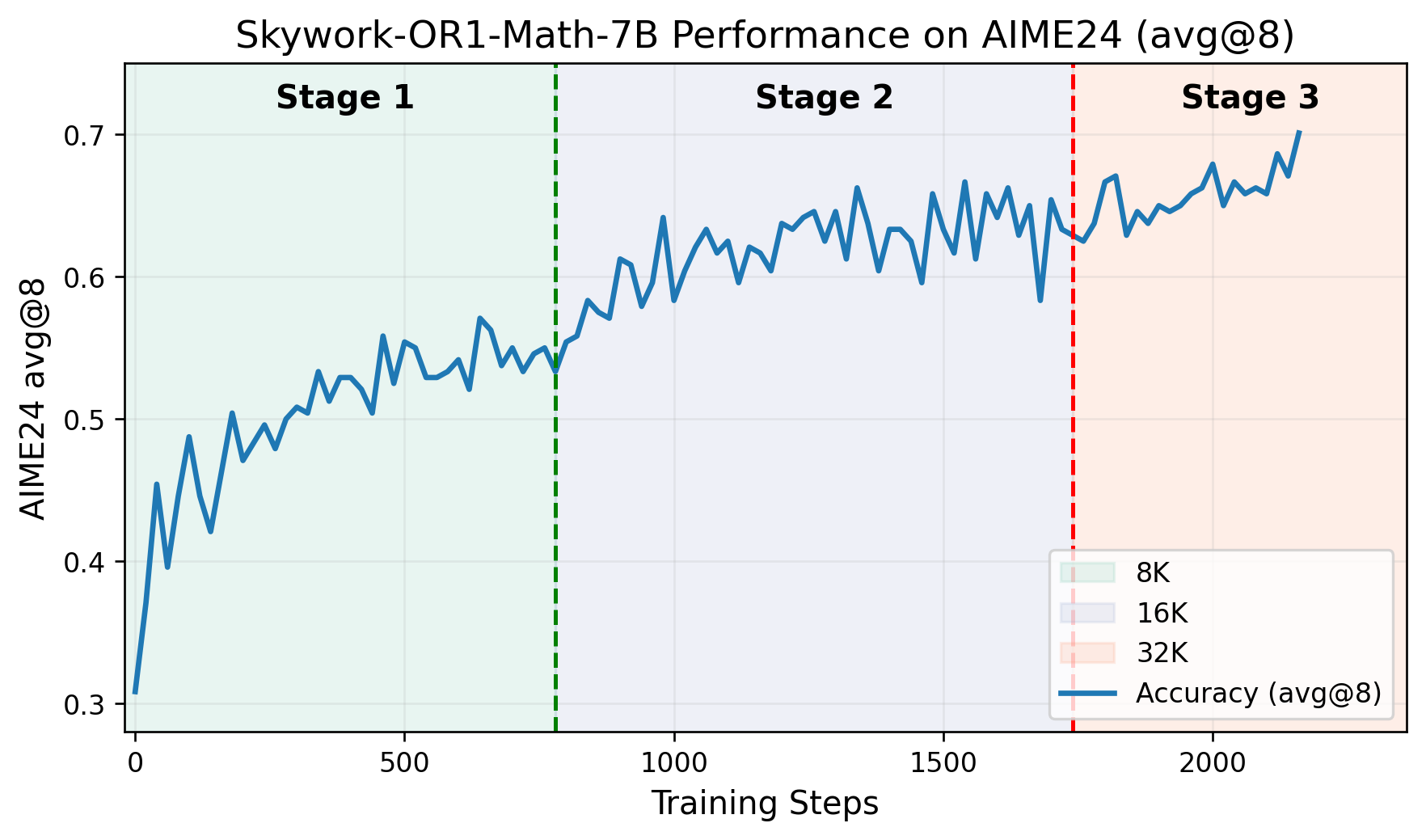
Skywork-OR1-32B 벤치마크
기술 사양:
- 파라미터 수: 328억
- 텐서 유형: BF16
- 모델 형식: Safetensors
- 아키텍처 패밀리: Qwen2
- 기본 모델: DeepSeek-R1-Distill-Qwen-32B
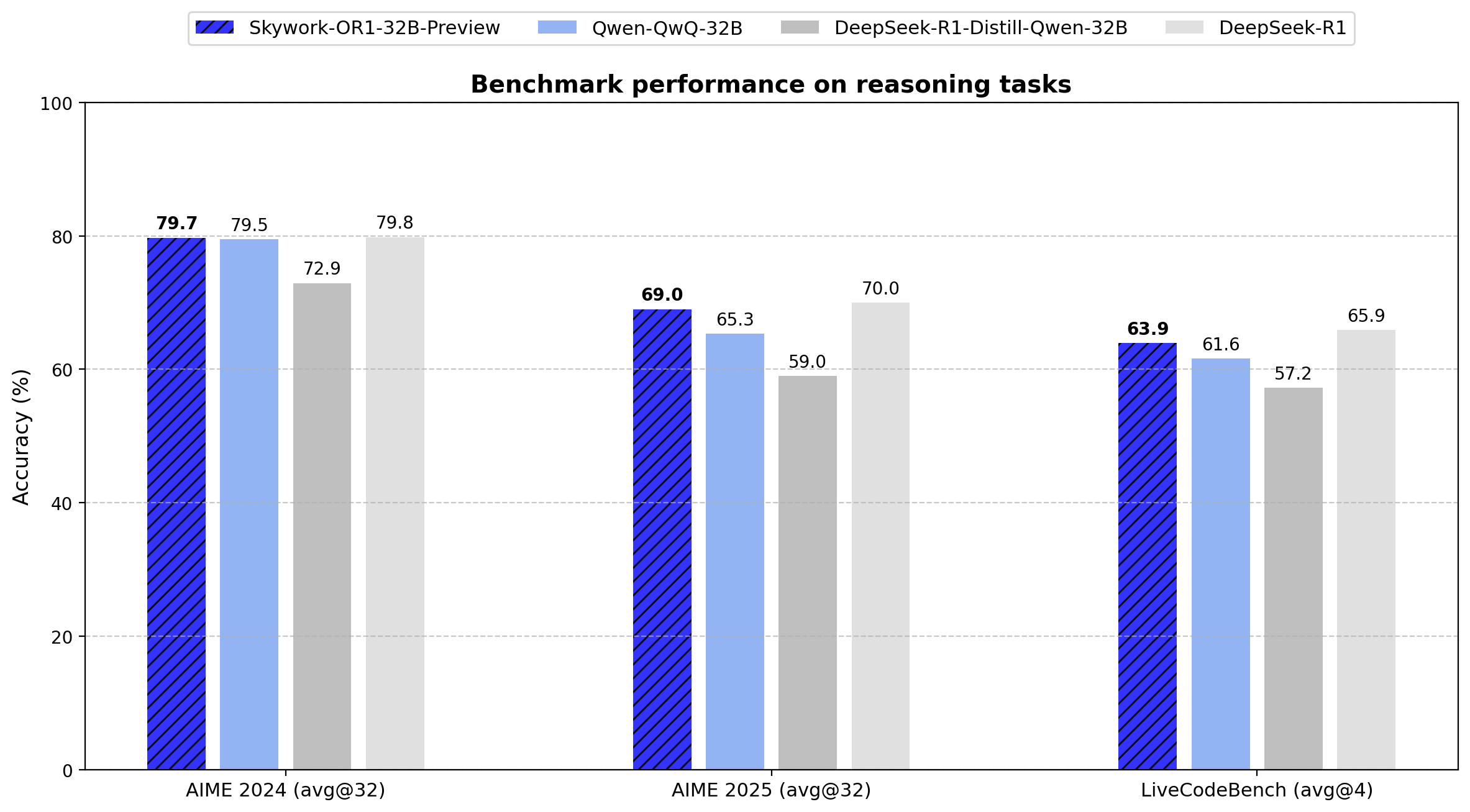
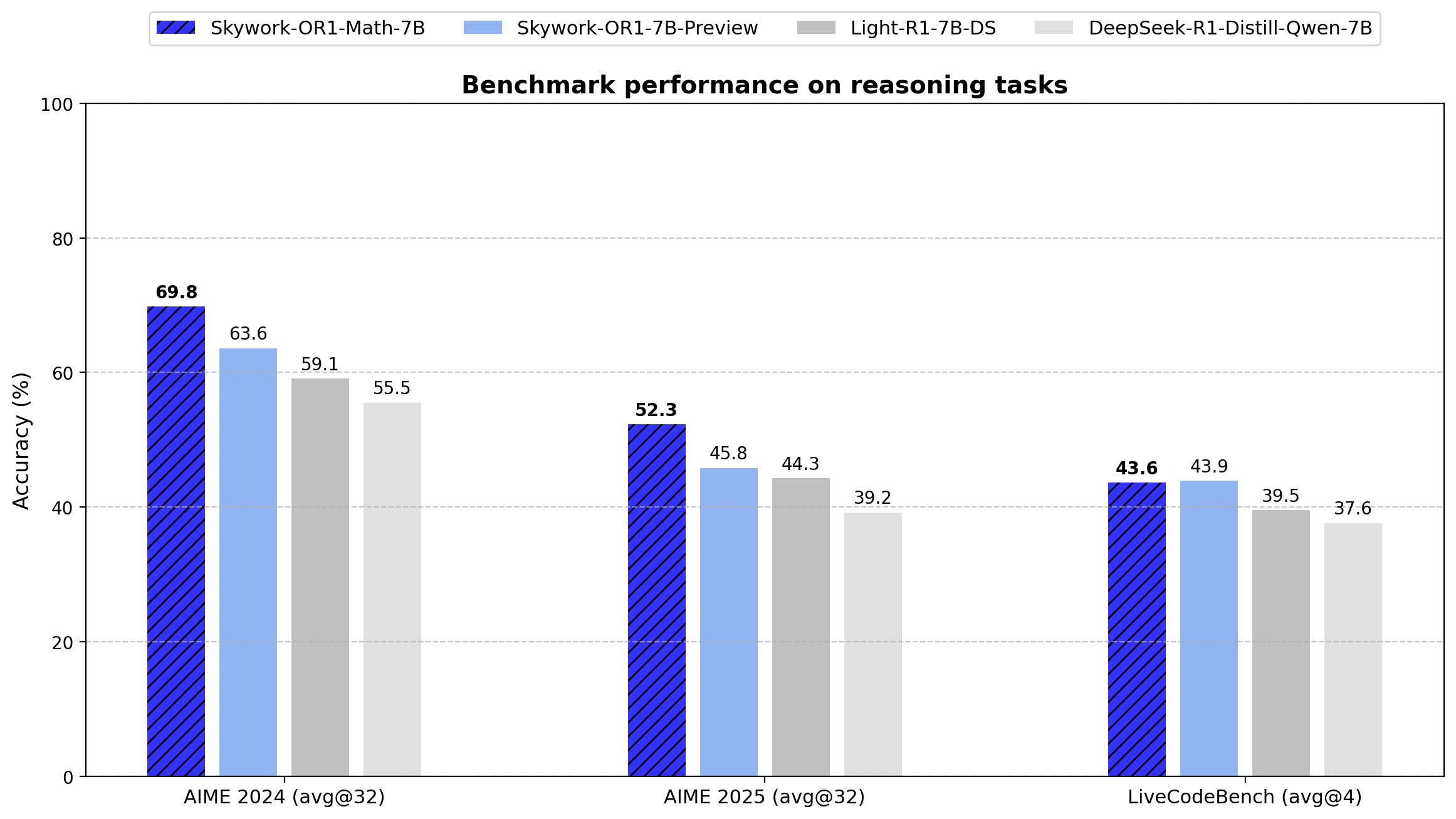
Skywork-OR1 시리즈는 기존의 Pass@1 대신 Avg@K를 주요 평가 지표로 도입했습니다. 이 메트릭은 여러 독립적 시도(AIME 테스트는 32회, LiveCodeBench은 4회)의 평균 성능을 계산하여 분산을 줄이고 추론 일관성의 더 신뢰할 수 있는 측정을 제공합니다.
아래는 시리즈의 모든 모델에 대한 정확한 벤치마크 결과입니다:
데이터는 Skywork-OR1-32B-Preview가 20배 많은 파라미터(671B vs 32.8B)를 가진 DeepSeek-R1과 거의 동등한 성능을 보임을 입증합니다(AIME24: 79.7 vs 79.8, AIME25: 69.0 vs 70.0, LiveCodeBench: 63.9 vs 65.9).
Skywork-OR1 모델은 다음 기술 사양으로 구현할 수 있습니다:
Skywork-OR1 모델 테스트 방법
다음은 Skywork-OR1-32B, Skywork-OR1-7B 및 Skywork-OR1-Math-7B의 Hugging Face 모델 카드입니다:



평가 스크립트를 실행하려면 다음 단계를 따르세요:
도커 환경:code
docker pull whatcanyousee/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te2.0-megatron0.11.0-v0.0.6
docker run --runtime=nvidia -it --rm --shm-size=10g --cap-add=SYS_ADMIN -v <경로>:<경로> 이미지:태그
Conda 환경 설정:code
conda create -n verl python==3.10
conda activate verl
pip3 install torch==2.4.0 --index-url <https://download.pytorch.org/whl/cu124>
pip3 install flash-attn --no-build-isolation
git clone <https://github.com/SkyworkAI/Skywork-OR1.git>
cd Skywork-OR1
pip3 install -e .
AIME24 평가 재현:code
MODEL_PATH=Skywork/Skywork-OR1-32B-Preview \\\\
DATA_PATH=or1_data/eval/aime24.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime24_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_32b.sh
AIME25 평가:code
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/aime25.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime25_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
LiveCodeBench 평가:code
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/livecodebench/livecodebench_2408_2502.parquet \\\\
SAMPLES=4 \\\\
TASK_NAME=LiveCodeBench_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
현재 Skywork-OR1 모델은 "Preview" 버전으로 표시되며, 최종 버전은 첫 발표 후 2주 이내에 공개될 예정입니다. 개발자는 다음과 같은 추가 기술 문서를 공개할 계획입니다:
- 훈련 방법론을 상세히 설명하는 기술 보고서
- Skywork-OR1-RL-Data 데이터셋
- 추가 훈련 스크립트
GitHub 저장소는 훈련 스크립트가 "현재 정리 중이며 1-2일 내에 제공될 예정"이라고 명시하고 있습니다.
 SkyworkAI
SkyworkAI결론: Skywork-OR1-32B의 기술적 평가
Skywork-OR1-32B-Preview 모델은 파라미터 효율적인 추론 모델 분야에서 큰 진전을 나타냅니다. 328억 개의 파라미터로 6710억 파라미터의 DeepSeek-R1 모델과 여러 벤치마크에서 거의 동등한 성능 지표를 달성했습니다.
아직 검증되지는 않았지만, 이러한 결과는 고급 추론 능력이 필요한 실제 애플리케이션에서 Skywork-OR1-32B-Preview가 상당히 큰 모델에 대한 실행 가능한 대안을 제시함을 시사합니다. 이는 계산 리소스 요구 사항을 크게 줄이면서 가능합니다.
또한, 이 모델들의 오픈소스 특성과 평가 스크립트, 향후 공개될 훈련 데이터는 언어 모델의 추론 능력을 연구하는 연구자와 실무자에게 귀중한 기술 자원을 제공합니다.
개발 팀이 함께 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요? 최대 생산성을 위해?
Apidog는 귀하의 모든 요구를 충족하며, Postman을 훨씬 더 저렴한 가격에 대체합니다!