
컴퓨터 과학에서 직렬화와 비직렬화는 복잡한 데이터 구조를 저장 또는 전송에 적합한 형식으로 변환하고 다시 원래 형태로 재구성하는 필수 과정입니다.
여러분께 Apidog를 소개합니다. 이는 전체 API 생애 주기를 위한 완벽한 도구를 제공하는 종합 API 개발 플랫폼입니다. 단일 애플리케이션 내에서 API를 구축, 테스트, 모의 및 문서화할 수 있습니다.
Apidog에 대해 더 알고 싶으시다면 아래 버튼을 확인해 보세요.
직렬화란 무엇입니까?
직렬화는 복잡한 데이터 구조(예: 객체 및 배열)를 네트워크를 통해 전송할 수 있는 형식으로 변환하는 과정입니다.
이는 일반적으로 JSON 및 XML과 같은 텍스트 기반 표현을 가리킵니다.
직렬화가 그렇게 중요한 이유는 무엇입니까?
- 데이터 전송: APIs는 클라이언트와 서버 간에 데이터를 교환합니다. 직렬화는 복잡한 데이터를 전송할 수 있는 형식으로 변환합니다.
- 언어 및 플랫폼 독립성: 서로 다른 시스템은 서로 다른 프로그래밍 언어나 플랫폼을 사용할 수 있습니다. 직렬화는 데이터가 기본 기술에 관계없이 이해될 수 있도록 보장합니다.
- 효율성: 직렬화된 데이터는 원래 형태보다 더 간결한 경우가 많아 네트워크 전송 속도를 개선합니다.
- 가독성: JSON 및 XML과 같은 텍스트 기반 형식은 사람이 읽을 수 있어 디버깅 및 문제 해결이 용이합니다.
비직렬화란 무엇입니까?
비직렬화는 직렬화의 역과정입니다. 이는 직렬화된 형식(예: JSON, XML 또는 Protobuf)에서 원래 데이터 구조, 즉 메모리 내 객체로 데이터를 변환하는 과정을 포함합니다.
API에서 비직렬화의 중요성
- 데이터 처리: 비직렬화는 클라이언트가 수신한 데이터를 효과적으로 조작하고 사용할 수 있도록 합니다.
- 객체 생성: 비직렬화는 원시 데이터를 추가 작업을 위한 사용 가능한 객체로 변환합니다.
- 오류 처리: 비직렬화 프로세스는 데이터 손상이나 형식 불일치와 같은 잠재적 오류를 처리할 수 있습니다.
직렬화 및 비직렬화의 코드 예
예제 1 - JSON을 사용한 Python
직렬화
import json
class Person:
def __init__(self, name, age, city):
self.name = name
self.age = age
self.city = city
person = Person("앨리스", 30, "뉴욕")
# JSON으로 직렬화
json_data = json.dumps(person.__dict__)
print(json_data)
비직렬화
import json
# json_data는 위와 동일한 것으로 가정
# JSON에서 비직렬화
person_dict = json.loads(json_data)
deserialized_person = Person(**person_dict)
print(deserialized_person.name)
예제 2 - ObjectOutputStream 및 ObjectInputStream을 사용한 Java
직렬화
import java.io.*;
class Person implements Serializable {
private String name;
private int age;
// 생성자, 게터 및 세터
}
public class SerializationExample {
public static void main(String[] args) throws IOException {
Person person = new Person("밥", 25);
FileOutputStream fileOut = new FileOutputStream("person.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(person);
out.close();
fileOut.close();
}
}
비직렬화
import java.io.*;
class DeserializationExample {
public static void main(String[] args) throws IOException, ClassNotFoundException {
FileInputStream fileIn = new FileInputStream("person.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
Person person = (Person) in.readObject();
in.close();
fileIn.close();
System.out.println(person.getName());
}
}
예제 3 - Binary Formatter를 사용한 C#
직렬화
using System.IO;
using System.Runtime.Serialization.Formatters.Binary;
[Serializable]
class Person {
public string Name;
public int Age;
}
class Program {
static void Main(string[] args)
{
Person person = new Person { Name = "찰리", Age = 35 };
BinaryFormatter formatter = new BinaryFormatter();
using (FileStream stream = new FileStream("person.bin", FileMode.Create, FileAccess.Write))
{
formatter.Serialize(stream, person);
}
}
}
비직렬화
using System.IO;
using System.Runtime.Serialization.Formatters.Binary;
class Program {
static void Main(string[] args)
{
BinaryFormatter formatter = new BinaryFormatter();
using (FileStream stream = new FileStream("person.bin", FileMode.Open, FileAccess.Read))
{
Person person = (Person)formatter.Deserialize(stream);
Console.WriteLine(person.Name);
}
}
}
직렬화 및 비직렬화의 문제점과 모범 사례
직렬화와 비직렬화는 근본적인 과정이지만, 개발자가 해결해야 할 여러 가지 문제를 제시합니다:
문제점
성능
- 직렬화와 비직렬화는 특히 대규모 데이터 세트나 복잡한 객체에 대해 계산 비용이 많이 들 수 있습니다.
- 직렬화 형식의 선택은 성능에 상당한 영향을 미칩니다.
데이터 무결성
- 직렬화와 비직렬화 중에 데이터가 정확하게 표현되고 손상되지 않도록 보장하는 것이 중요합니다.
- 데이터 손실이나 불일치는 애플리케이션 오류로 이어질 수 있습니다.
호환성
- 서로 다른 버전의 직렬화된 데이터 간의 호환성을 유지하는 것이 진화하는 시스템에 필수적입니다.
- 스키마 변경은 비직렬화 프로세스를 중단시킬 수 있습니다.
보안
- 직렬화된 데이터는 주입 및 비직렬화 취약점과 같은 공격에 취약할 수 있습니다.
- 직렬화와 비직렬화 중에 민감한 정보를 보호하는 것이 중요합니다.
모범 사례
올바른 직렬화 형식 선택
- 형식(JSON, XML, Protobuf 등)을 선택할 때 데이터 크기, 성능, 가독성 및 호환성과 같은 요소를 고려하세요.
성능 최적화
- 효율적인 알고리즘 및 데이터 구조를 사용하세요.
- 대규모 데이터 세트에 대해 압축을 고려하세요.
- 응용 프로그램을 프로파일링하여 성능 병목 현상을 식별하세요.
데이터 검증
- 비정상적이거나 악의적인 데이터가 비직렬화되지 않도록 철저한 데이터 검증을 구현하세요.
- 스키마 검증 또는 데이터 유형 검사를 사용하세요.
오류를 우아하게 처리
- 비직렬화 실패에 대처하기 위해 견고한 오류 처리 메커니즘을 구현하세요.
- 정보가 풍부한 오류 메시지를 제공하세요.
버전 관리
- 스키마 진화 및 하위 호환성을 계획하세요.
- 버전 관리 메커니즘 또는 호환성 레이어를 사용하세요.
보안
- 암호화 또는 모호화를 통해 민감한 데이터를 보호하세요.
- 주입 공격을 방지하기 위해 입력을 검증하세요.
- 직렬화 라이브러리와 종속성을 보안 패치로 최신 상태로 유지하세요.
테스트
- 직렬화 및 비직렬화 프로세스를 철저히 테스트하세요.
- 테스트 시나리오에 엣지 케이스 및 유효하지 않은 데이터를 포함하세요.
Apidog: 모든 API 문제를 위한 원스톱 솔루션
API 프로세스를 원활하게 하기 위한 API 개발 플랫폼이나 Postman 및 Swagger와 같은 다른 API 도구의 대안을 찾고 계시다면 Apidog를 확인해야 합니다.
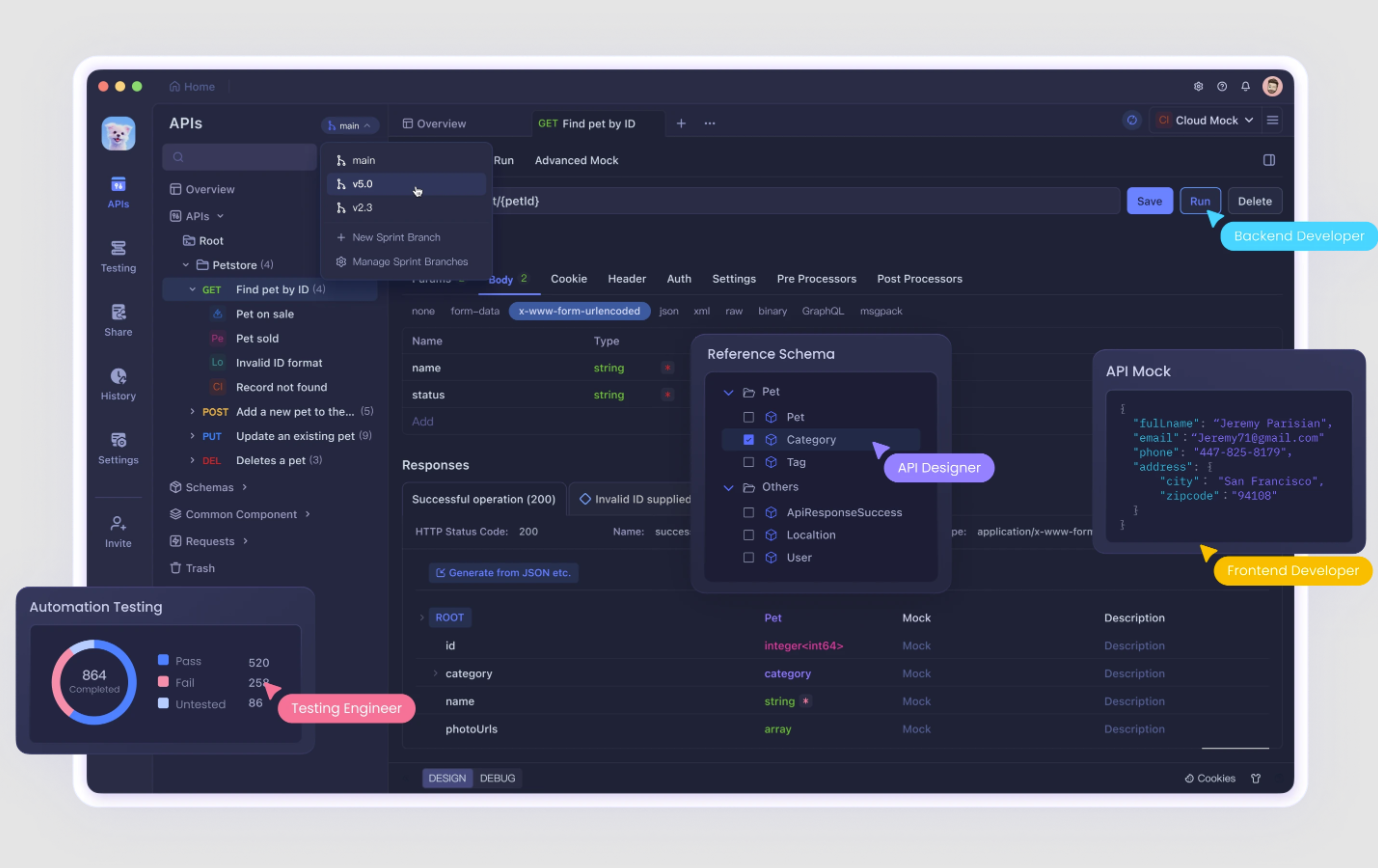
Apidog로 API 만들기
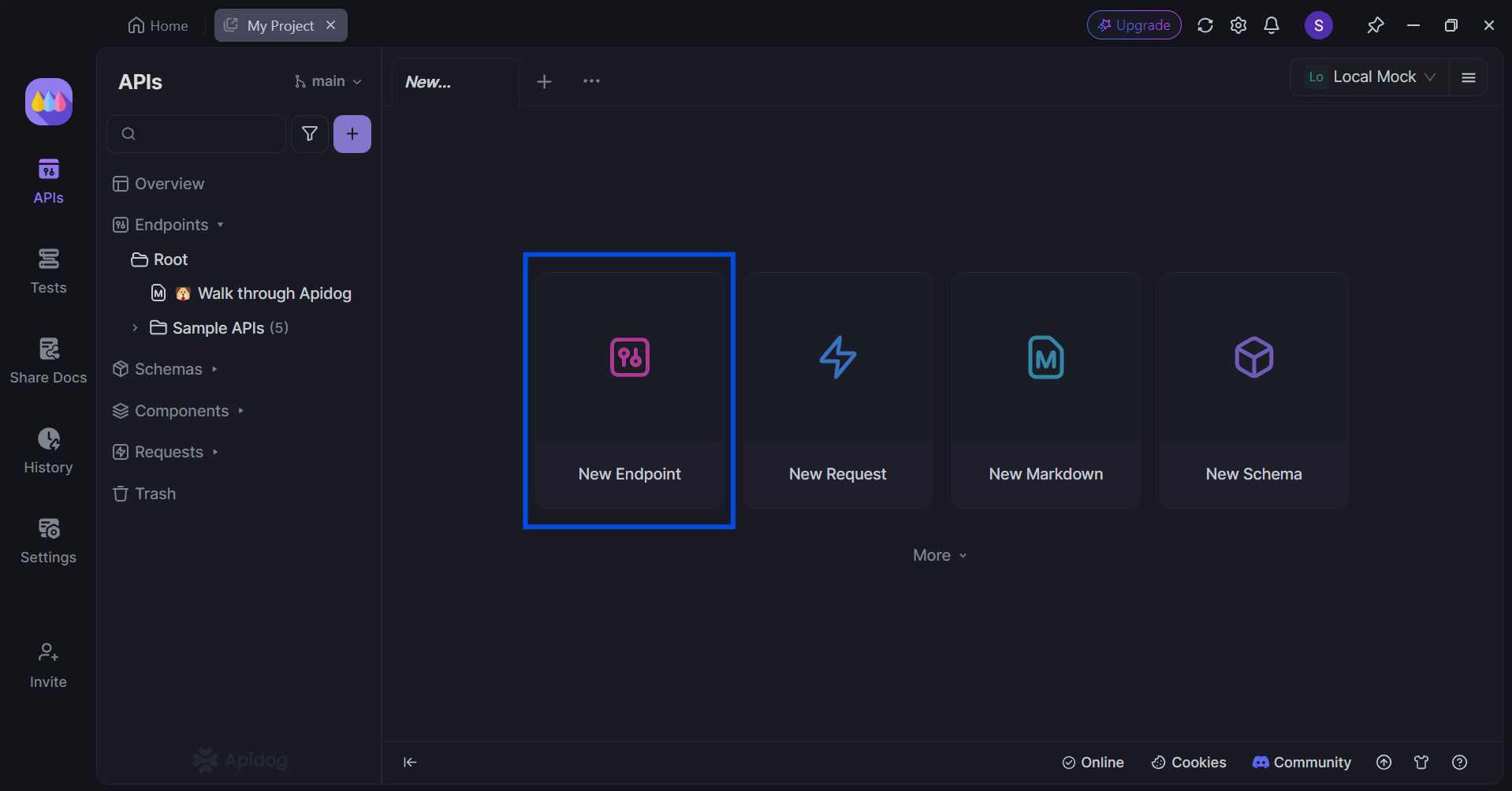
Apidog를 무료로 다운로드한 후, 새 프로젝트를 초기화할 수 있습니다. 새로운 애플리케이션을 위한 새로운 엔드포인트를 생성하는 것부터 시작하세요!
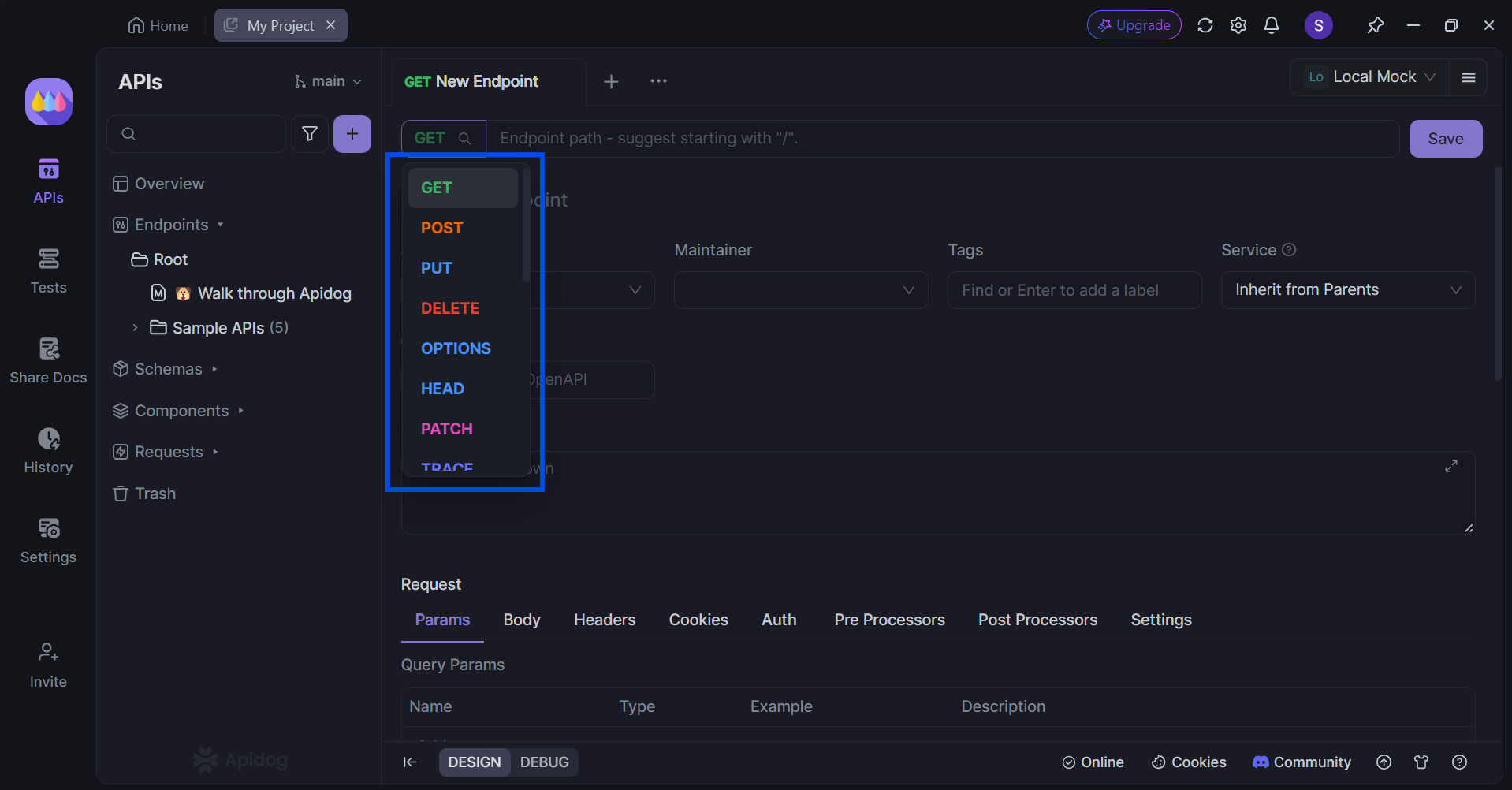
다음으로, API 엔드포인트와 연결된 HTTP 메서드를 선택하세요. 이 단계에서는 매개변수, 헤더, 전처리기 및 후처리기 스크립트와 같은 모든 필수 세부 정보를 포함하는 것이 좋습니다.
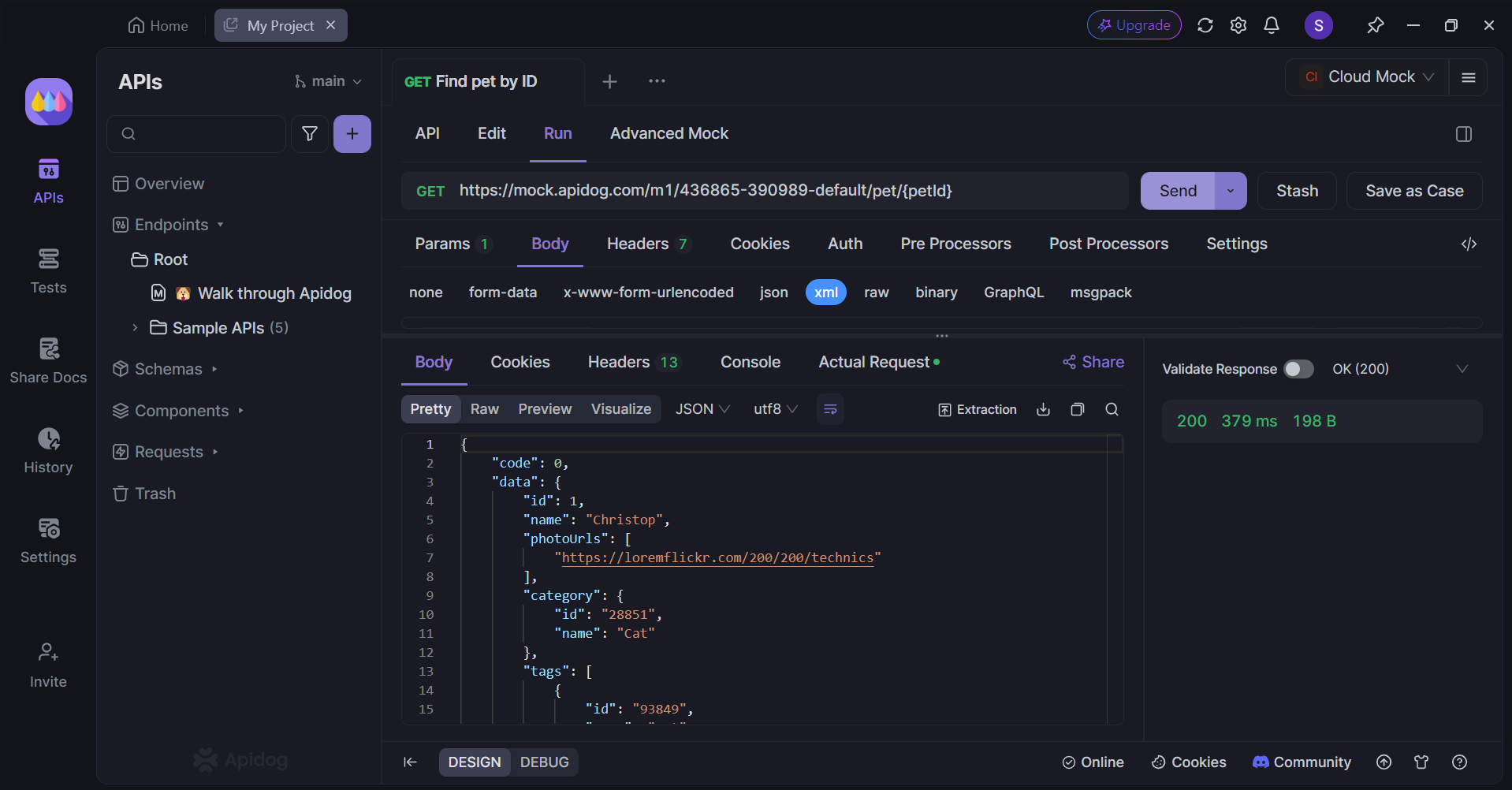
API를 완료하면 전송 버튼을 눌러 API 응답을 확인하세요. 단순하면서도 직관적인 사용자 인터페이스 덕분에 문제를 쉽게 식별할 수 있습니다.
전문 API 문서 작성
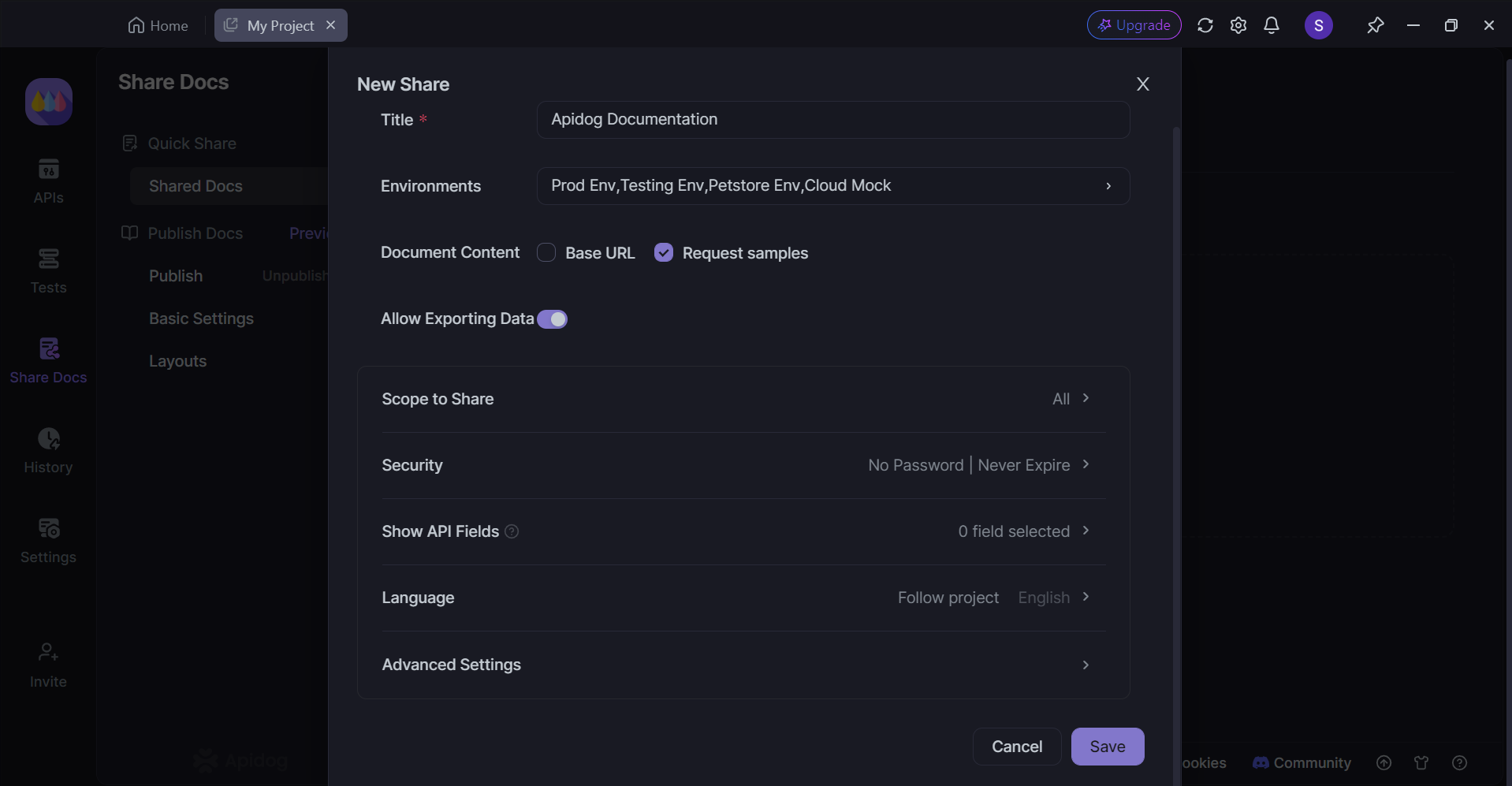
API 설계를 완료한 후, 설계 단계에서 포함한 세부 정보를 템플릿으로 사용하여 몇 초 만에 API 문서를 생성할 수 있습니다.
개인 도메인을 원하시는지, 그리고 API 문서를 비공개로 유지할지 여부도 고려해야 합니다. 추가 보안을 위해 추가 비밀번호를 설정할 수 있습니다!
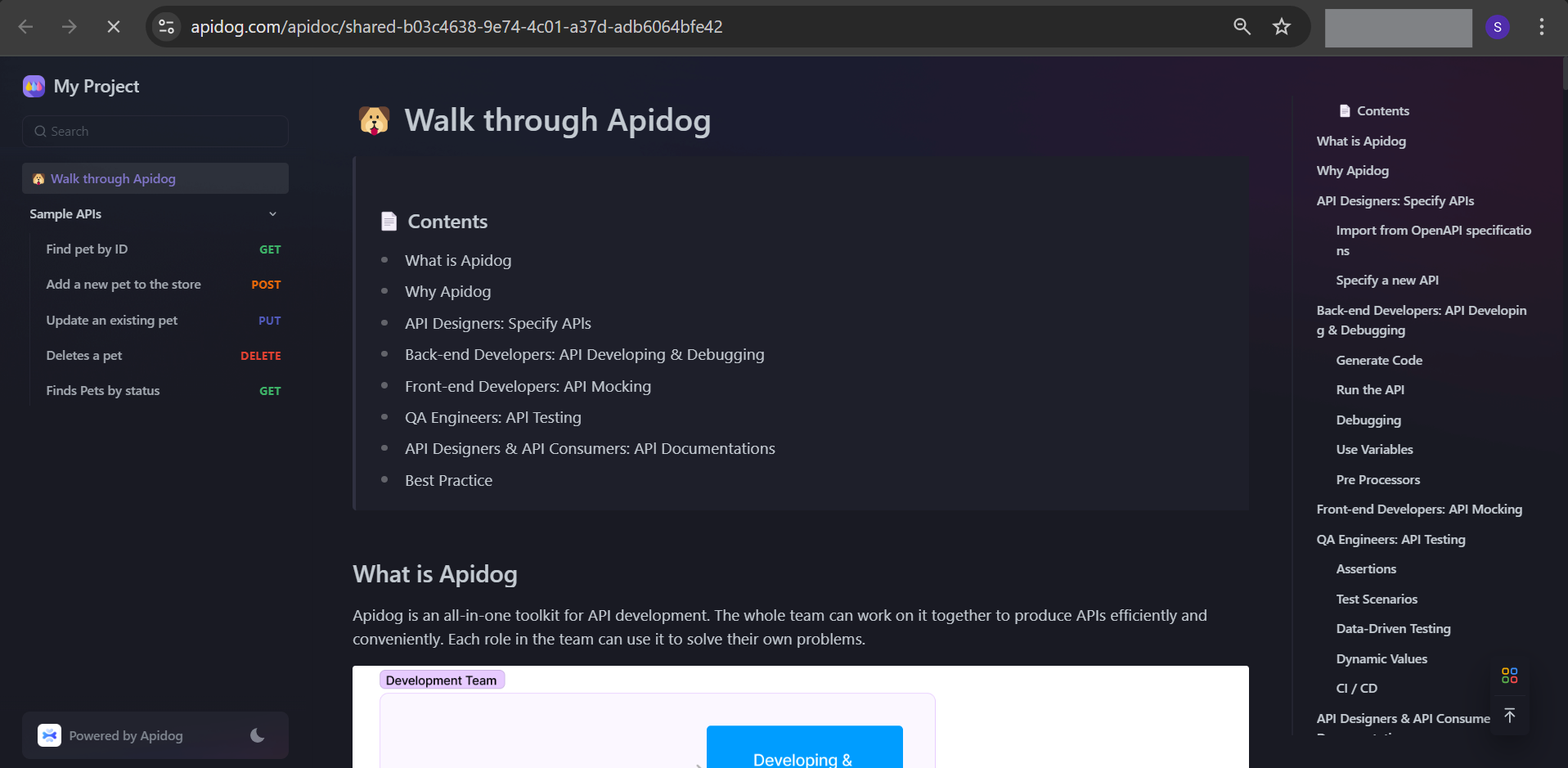
그리고 그것으로 - URL로 공유할 준비가 된 API 문서가 완성되었습니다! 이제 문서를 어떻게 공유할지 결정하면 됩니다.
결론
직렬화와 비직렬화는 현대 컴퓨팅에 필수적이며, 복잡한 데이터 구조와 전송 가능하고 저장 가능한 표현 간의 다리 역할을 합니다. 데이터 교환, 저장 및 처리에서 막대한 이점을 제공하는 동시에 이러한 프로세스는 성능 오버헤드, 데이터 무결성 문제 및 보안 위험과 같은 잠재적 문제를 초래합니다.
기술이 계속 발전함에 따라 직렬화와 비직렬화의 중요성은 더욱 커질 것입니다. 데이터 형식, 압축 기술 및 보안 프로토콜의 발전이 이러한 프로세스의 미래를 형성할 것입니다. 직렬화 및 비직렬화 원칙에 대한 깊은 이해는 개발자가 디지털 시대에 효율적이고 안전하며 확장 가능한 애플리케이션을 구축하는 데 점점 더 중요해질 것입니다.


