
대규모 언어 모델(LLM)의 경관이 빠른 속도로 발전하고 있습니다. 모델은 점점 더 강력하고, 기능적이며, 중요한 것은 접근성이 더욱 높아지고 있습니다. Qwen 팀은 최근 다양한 벤치마크에서 인상적인 성능을 자랑하는 최신 세대의 LLM인 Qwen3를 공개했습니다. Mixture-of-Experts(MoE) 같은 플래그십 모델인 Qwen3-235B-A22B가 기존의 정통적인 거대 모델들과 경쟁하고, Qwen3-4B 같은 더 작은 조밀한 모델이 이전 세대의 72B 파라미터 모델과 경쟁하는 Qwen3는 상당한 도약을 나타냅니다.
이번 릴리스의 핵심 측면 중 하나는 두 가지 MoE 변형(Qwen3-235B-A22B 및 Qwen3-30B-A3B)과 0.6B에서 32B 파라미터에 이르는 여섯 개의 조밀한 모델을 포함한 여러 모델의 개방적인 가중치를 제공하는 것입니다. 이러한 개방성은 개발자, 연구자 및 열정가들이 이러한 강력한 도구를 탐색하고 활용하며 구축하도록 초대합니다. 클라우드 기반 API가 편리함을 제공하지만, 개인 정보 보호, 비용 통제, 맞춤화 및 오프라인 접근 가능성 요구로 인해 이러한 정교한 모델을 로컬에서 실행하려는 열망이 커지고 있습니다.
다행히 로컬 LLM 실행을 위한 도구 생태계가 크게 성숙해졌습니다. 이 과정을 간소화하는 두 가지 눈에 띄는 플랫폼은 Ollama와 vLLM입니다. Ollama는 다양한 모델을 시작하는 데 매우 사용자 친화적인 방법을 제공하며, vLLM은 특히 더 큰 모델에 대해 처리량과 효율성을 최적화한 고성능 서비스 솔루션을 제공합니다. 이 문서에서는 Qwen3을 이해하고 Ollama와 vLLM을 사용하여 로컬 머신에서 이러한 강력한 모델을 설정하는 방법을 안내합니다.
개발 팀이 함께 최대 생산성으로 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요?
Apidog는 모든 요구를 충족하고 Postman을 훨씬 더 저렴한 가격으로 대체합니다!
Qwen 3와 벤치마크란?
Qwen3는 Qwen 팀이 개발한 대규모 언어 모델(LLM)의 세 번째 세대로, 2025년 4월에 출시되었습니다. 이 버전은 이전 버전보다 상당한 발전을 나타내며, Mixture-of-Experts(MoE)와 같은 아키텍처 혁신을 통한 향상된 추론 능력, 효율성, 더 넓은 다국어 지원 및 다양한 벤치마크에서의 개선된 성능에 중점을 두고 있습니다. 이 릴리스는 Apache 2.0 라이센스 하에 여러 모델의 개방 가중치를 포함하여 연구 및 개발의 접근성을 촉진했습니다.
Qwen 3 모델 아키텍처 및 변형 설명
Qwen3 패밀리는 전통적인 조밀 모델과 희소 MoE 아키텍처를 포함하여 다양한 계산 예산과 성능 요구를 충족합니다.
조밀 모델: 이 모델들은 추론 중 모든 파라미터를 사용합니다. 주요 아키텍처 세부 사항은 다음과 같습니다:
| 모델 | 레이어 | 어텐션 헤드(쿼리 / 키-값) | 단어 임베딩 결합 | 최대 컨텍스트 길이 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | 예 | 32,768 토큰 (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | 예 | 32,768 토큰 (32K) |
| Qwen3-4B | 36 | 32 / 8 | 예 | 32,768 토큰 (32K) |
| Qwen3-8B | 36 | 32 / 8 | 아니오 | 131,072 토큰 (128K) |
| Qwen3-14B | 40 | 40 / 8 | 아니오 | 131,072 토큰 (128K) |
| Qwen3-32B | 64 | 64 / 8 | 아니오 | 131,072 토큰 (128K) |
참고: 그룹화 쿼리 어텐션(GQA)은 서로 다른 쿼리와 키-값 헤드 수로 표시되며 모든 모델에 사용됩니다.
Mixture-of-Experts (MoE) 모델: 이 모델들은 추론 중 각 토큰에 대해 "전문가" Feed-Forward Networks(FFN)의 서브셋만 활성화하여 희소성을 활용합니다. 이는 큰 총 파라미터 수를 유지하면서도 계산 비용을 더 작은 조밀 모델에 가깝게 유지할 수 있게 해줍니다.
| 모델 | 레이어 | 어텐션 헤드(쿼리 / 키-값) | 전문가 수(총 / 활성화) | 최대 컨텍스트 길이 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072 토큰 (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072 토큰 (128K) |
참고: 두 MoE 모델 모두 128명의 총 전문가를 활용하지만 토큰 당 8명만 활성화하여 조밀 모델에 비해 계산 부하를 크게 줄입니다.
Qwen 3 주요 기술 특징
혼합 사고 모드: Qwen3의 두 가지 뚜렷한 모드에서 작동할 수 있는 능력은 사용자가 제어할 수 있는 고유한 특징입니다:
- 사고 모드(기본): 모델은 최종 응답을 생성하기 전에 내부적으로 단계별로 추론(Chain-of-Thought 스타일)을 수행합니다. 이 잠재적인 사고 과정은 캡슐화되어 있으며, 특정 프레임워크 구성에서 최종 답변 전에
<think>...</think>콘텐츠를 출력하는 것과 같은 특수 토큰으로 표시됩니다. 이 모드는 논리적 추론, 수학적 추론 또는 계획을 필요로 하는 복잡한 작업에서 성능을 향상시킵니다. 할당된 계산 추론 예산과 직접적으로 상관된 성능 개선을 가능하게 합니다. - 비사고 모드: 모델은 명시적인 내부 추론 단계 없이 직접적인 응답을 생성하여 간단한 쿼리에서 속도와 계산 비용을 최적화합니다.
사용자는 프롬프트에서/think및/no_think와 같은 태그를 사용하여 다중 턴 대화 중 이 모드 간에 동적으로 전환할 수 있어 지연/비용과 추론 깊이 간의 균형을 세밀하게 조절할 수 있습니다.
광범위한 다국어 지원: Qwen3 모델들은 주요 언어 계통(인도유럽어, 중국-티베트어, 아프리카-아시아어, 오세아니아어, 드라비다어, 튀르크어 등) 전반에 걸쳐 119개 언어 및 방언을 지원하는 다양한 말뭉치에서 사전 훈련되었습니다. 이를 통해 다양한 글로벌 애플리케이션에 적합하게 됩니다.
고급 훈련 방법론:
- 사전 훈련: 모델들은 수조 개의 토큰으로 구성된 대규모 데이터 세트에서 사전 훈련되었습니다. 최종 사전 훈련 단계는 초기 32K 토큰까지 유효한 컨텍스트 창을 확장하는 고품질의 장기 컨텍스트 데이터를 사용하는 것을 포함했으며, 이후 더 큰 모델의 경우 128K로 확장되었습니다.
- 후속 훈련: 모델에 명령 따른 능력, 추론 기술 및 혼합 사고 메커니즘을 부여하기 위해 정교한 4단계 파이프라인이 사용되었습니다:
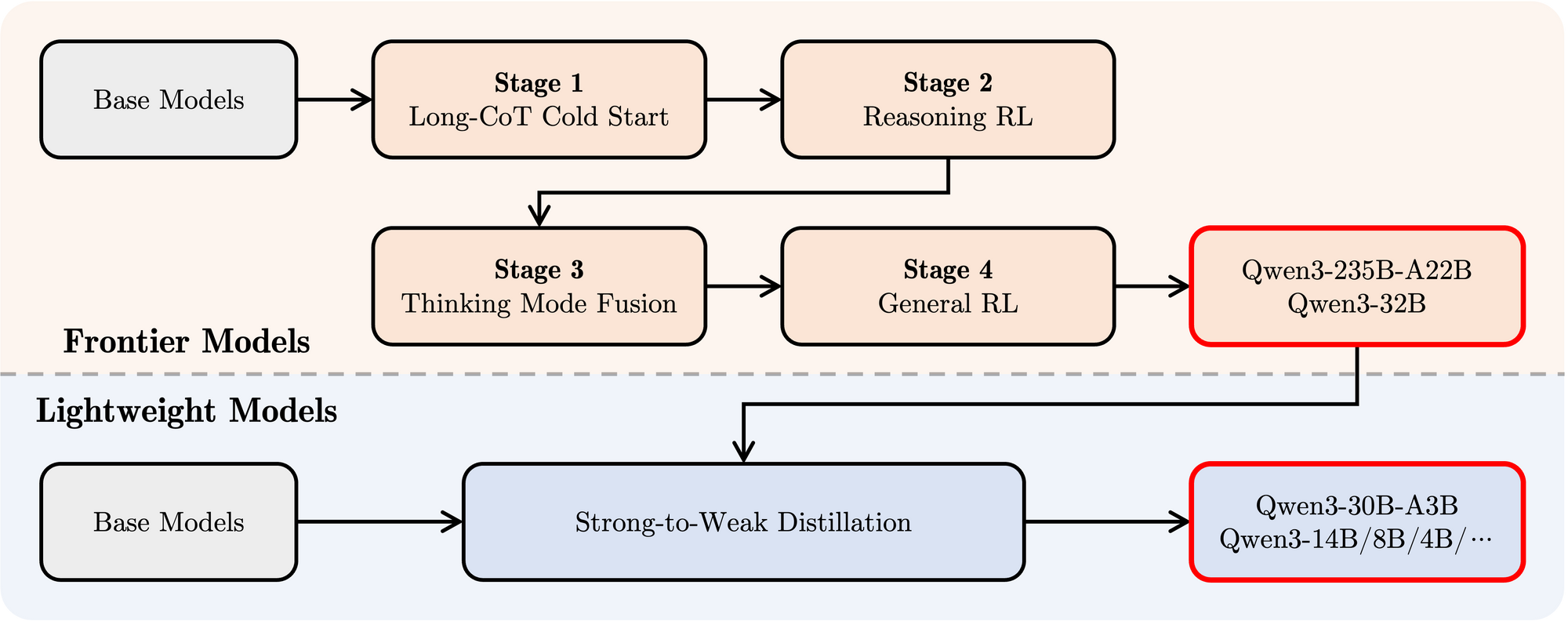
- 긴 CoT 콜드 스타트: 수학, 코딩, 논리적 추론 및 STEM을 포함한 다양한 긴 Chain-of-Thought(COT) 데이터에서 감독 세부 조정(SFT)을 통해 기초적인 추론 능력을 구축합니다.
- 추론 기반 강화 학습(RL): 규칙 기반 보상을 활용하여 추론 작업을 위해 탐색 및 활용을 증대시키기 위해 RL을 위한 계산 자원을 확장합니다.
- 사고 모드 융합: Stage 2 모델이 생성한 긴 CoT 데이터와 표준 지시 조정 데이터의 혼합에 대해 추론 증강 모델을 세부 조정하여 비사고 기능을 통합합니다. 이는 깊은 추론과 빠른 응답 생성을 혼합합니다.
- 일반 RL: 여러 일반 도메인 작업(지시 준수, 형식 준수, 에이전트 기능)에서 RL을 적용하여 전반적인 행동을 정제하고 원치 않는 출력을 완화합니다.
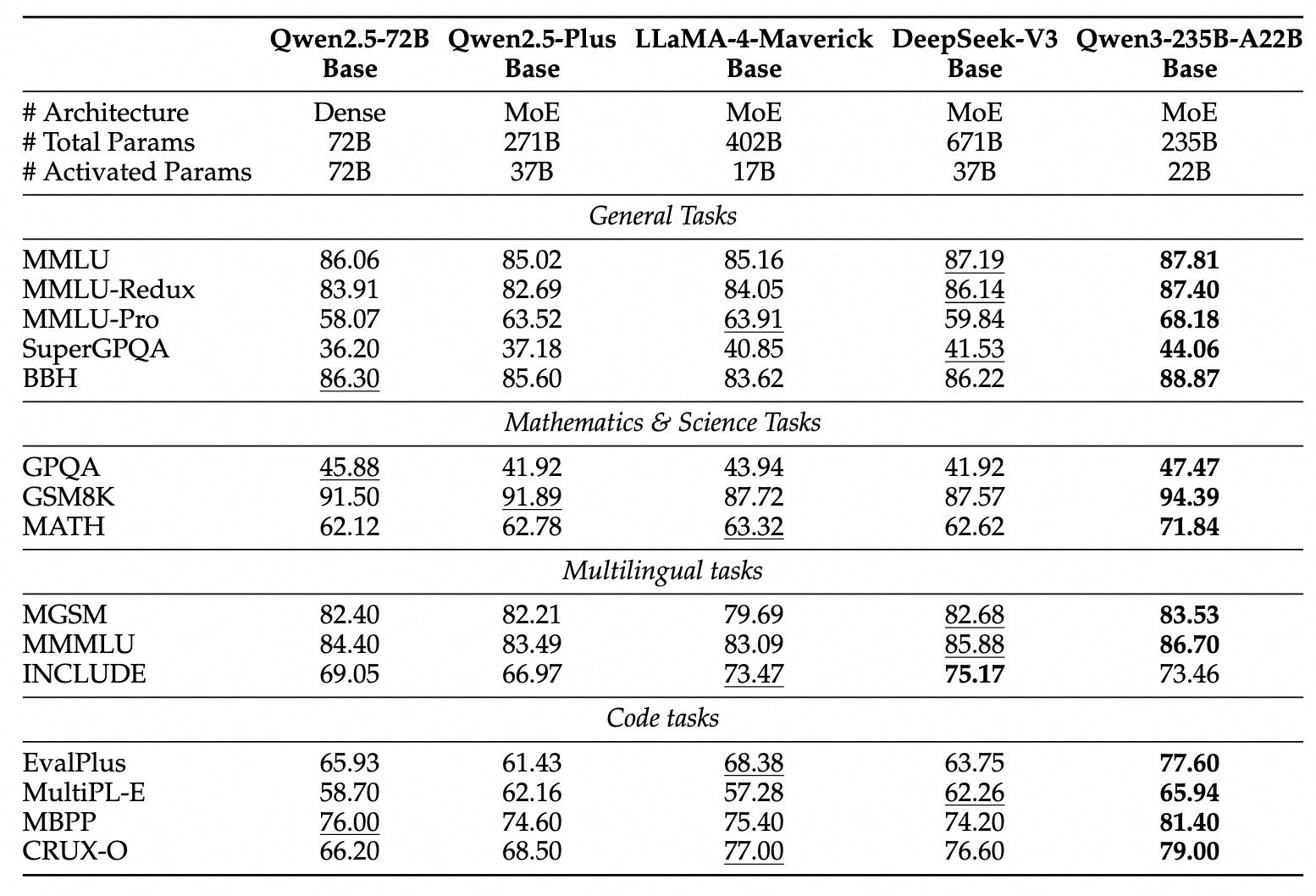
Qwen 3 벤치마크 성능
Qwen3는 다른 주요 동시 모델들에 비해 매우 경쟁력 있는 성능을 보여줍니다:
플래그십 MoE: Qwen3-235B-A22B 모델은 DeepSeek-R1, Google's o1 및 o3-mini, Grok-3, Gemini-2.5-Pro와 같은 최고급 모델들과 비교할 수 있는 결과를 다양한 벤치마크에서 달성합니다. 이들 벤치마크는 코딩, 수학 및 일반 능력을 평가합니다.
작은 MoE: Qwen3-30B-A3B 모델은 QwQ-32B 모델들보다 훨씬 뛰어난 성능을 보이며, 추론 중 활성화되는 파라미터 비율(3B 대 32B)에서 효율성을 강조합니다.
조밀한 모델: 아키텍처 및 훈련 진전을 통해 Qwen3의 조밀한 모델은 일반적으로 더 큰 Qwen2.5 조밀한 모델들의 성능과 일치하거나 이를 초과합니다. 예를 들어:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(일부 측면에서Qwen2.5-72B-Instruct와 경쟁)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
특히 Qwen3 조밀 기본 모델은 STEM, 코딩 및 추론 작업에서 선임 모델에 비해 특히 강력한 성능 개선을 보여줍니다.
MoE 효율성: Qwen3 MoE 기본 모델은 약 10%의 파라미터만 활성화하여도 상당히 더 큰 Qwen2.5 조밀 모델과 비교할 수 있는 성능을 달성하여 훈련 및 추론 컴퓨팅에서 상당한 비용 절감을 이룹니다.
이러한 벤치마크 결과는 Qwen3가 높은 성능과 MoE 변형의 개선된 계산 효율성을 함께 제공하는 최첨단 모델 패밀리로서의 입지를 강화합니다. 이 모델들은 Hugging Face, ModelScope 및 Kaggle과 같은 표준 플랫폼을 통해 제공되며, Ollama, vLLM, SGLang, LMStudio 및 llama.cpp와 같은 인기 배포 프레임워크의 지원을 받아 다양한 워크플로 및 애플리케이션에 통합될 수 있습니다.
Ollama로 Qwen 3 로컬 실행하는 방법
Ollama는 LLM을 로컬에서 다운로드하고 관리하며 실행하는 데 그 단순성으로 엄청난 인기를 얻고 있습니다. 대부분의 복잡성을 추상화하며, 커맨드라인 인터페이스와 API 서버를 제공합니다.
1. 설치:
Ollama 설치는 일반적으로 간단합니다. 공식 Ollama 웹사이트(ollama.com)를 방문하여 운영 체제에 맞는 다운로드 지침을 따릅니다(맥OS, 리눅스, 윈도우).
2. Qwen3 모델 다운로드:
Ollama는 즉시 사용할 수 있는 모델 라이브러리를 유지합니다. 특정 Qwen3 모델을 실행하려면 ollama run 명령어를 사용합니다. 모델이 로컬에 없으면 Ollama가 자동으로 다운로드합니다. Qwen 팀은 여러 Qwen3 변형 모델을 Ollama 라이브러리를 통해 직접 제공합니다.
Ollama 웹사이트의 Qwen3 페이지에서 사용 가능한 Qwen3 태그를 찾을 수 있습니다(예: ollama.com/library/qwen3). 일반적인 태그는 다음과 같을 수 있습니다:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(더 작은 MoE 모델)
예를 들어, 4B 파라미터 모델을 실행하려면 단순히 터미널을 열고 다음을 입력합니다:
ollama run qwen3:4b
이 명령은 모델을 다운로드하고(필요한 경우) 인터랙티브 채팅 세션을 시작합니다.
3. 모델과 상호작용:ollama run 명령이 활성화되면 프롬프트를 터미널에 직접 입력할 수 있습니다. Ollama는 또한 로컬 서버를 시작합니다(일반적으로 http://localhost:11434에서) OpenAI 표준과 호환되는 API를 노출합니다. curl 또는 파이썬, 자바스크립트 등의 다양한 클라이언트 라이브러리를 사용하여 프로그래밍적으로 상호작용할 수 있습니다.
4. 하드웨어 고려사항:
로컬에서 LLM을 실행하려면 상당한 자원이 필요합니다.
- RAM: 더 작은 모델(0.6B, 1.7B)도 몇 기가바이트의 RAM을 필요로 합니다. 더 큰 모델(8B, 14B, 32B, 30B-A3B)은 훨씬 더 많은 RAM을 요구하며, 종종 16GB, 32GB 또는 그 이상이 필요할 수 있습니다.
- VRAM(GPU): 적정 성능을 위해 충분한 VRAM을 갖춘 전용 GPU 사용을 강력히 권장합니다. Ollama는 호환 가능한 GPU(NVIDIA, Apple Silicon)를 자동으로 활용합니다. VRAM의 양은 전체 GPU에서 원활하게 실행할 수 있는 가장 큰 모델을 결정하게 되며, 이는 추론 속도를 크게 향상시킵니다.
- CPU: Ollama는 CPU에서 모델을 실행할 수 있지만, 성능은 GPU에서보다 훨씬 느리게 됩니다.
Ollama는 빠르게 시작하고, 로컬 개발 및 실험, 단일 사용자 채팅 애플리케이션 구축에 적합하며, 특히 소비자급 하드웨어에서 효과적입니다(제한 내에서).
Ollama를 vLLM으로 로컬에서 실행하는 방법
vLLM은 PagedAttention과 같은 최적화를 사용하는 고처리량 LLM 제공 라이브러리로, 추론 속도와 메모리 효율성을 크게 개선하여 요구가 높은 애플리케이션과 더 큰 모델 제공에 적합합니다. vLLM 팀은 Qwen3 출시 시점에 대한 뛰어난 지원을 제공합니다.
1. 설치:
pip를 사용하여 vLLM을 설치합니다. 일반적으로 가상 환경을 사용하는 것이 권장됩니다:
pip install -U vllm
필요한 전제 조건이 갖춰져 있는지 확인하세요. 일반적으로 호환 가능한 NVIDIA GPU와 적절한 CUDA 도구 키트가 필요합니다. 필요한 특정 사항은 vLLM 문서를 참조하세요.
2. Qwen3 모델 제공:
vLLM은 vllm serve 명령을 사용하여 모델을 로드하고 OpenAI 호환 API 서버를 시작합니다. Qwen 팀과 vLLM 문서는 Qwen3 실행에 대한 지침을 제공합니다.
제공된 정보를 바탕으로, 다음은 FP8 양자화를 사용하여 메모리 사용량을 줄이고 4개의 GPU에 걸쳐 텐서 병렬성을 출시하는 대형 Qwen3-235B MoE 모델을 제공하는 방법입니다:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
이 명령을 분해해 봅시다:
Qwen/Qwen3-235B-A22B-FP8: 이는 모델 식별자로, 아마도 Hugging Face 리포지토리 위치를 가리킵니다.FP8는 8비트 부동 소수점 양자화를 사용함을 나타내며, FP16 또는 BF16에 비해 모델의 메모리 점유율을 줄이는 데 중요합니다.--enable-reasoning: 이 플래그는 Qwen3의 혼합 사고 기능을 vLLM에서 활성화하는 데 필수적입니다.--reasoning-parser deepseek_r1: Qwen3의 사고 출력은 특정 형식을 갖고 있습니다. vLLM은 이를 처리하기 위해 파서를 필요로 합니다. 블로그 게시물에서는 vLLM에 대해deepseek_r1파서를 사용해야 함을 언급합니다. 이는 vLLM이 사고 단계를 최종 응답과 분리할 수 있음을 보장합니다.--tensor-parallel-size 4: 이는 vLLM에 모델의 가중치와 계산을 4개의 GPU에 분산하도록 지시합니다. 텐서 병렬성은 하나의 GPU에 적합하지 않을 만큼 큰 모델을 실행하는 데 필수적입니다. 가용한 GPU에 따라 이 숫자를 조정하면 됩니다.
다른 Qwen3 모델(예: Qwen/Qwen3-30B-A3B 또는 Qwen/Qwen3-32B)에 대해 이 명령을 조정하고, 하드웨어에 따라 tensor-parallel-size와 같은 매개변수를 조정할 수 있습니다.
3. vLLM 서버와 상호작용:vllm serve가 실행되고 나면 OpenAI API 사양을 반영하는 API 서버(기본적으로 http://localhost:8000)를 호스트합니다. 다음과 같은 표준 도구를 사용하여 상호작용할 수 있습니다:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # 사용한 모델 이름
"prompt": "Mixture-of-Experts의 개념을 설명해 주세요.",
"max_tokens": 150,
"temperature": 0.7
}'
- 파이썬 OpenAI 클라이언트:
from openai import OpenAI
# 로컬 vLLM 서버를 가리킵니다.
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # 사용한 모델 이름
prompt="로봇이 음악을 발견하는 짧은 이야기를 쓰세요.",
max_tokens=200
)
print(completion.choices[0].text)
4. 성능 및 사용 사례:
vLLM은 높은 처리량(초당 많은 요청)과 낮은 지연이 필요한 시나리오에서 빛을 발합니다. Its optimizations make it suitable for:
- 로컬 LLM으로 동력을 장착한 애플리케이션 구축.
- 여러 사용자에게 동시에 모델 제공.
- 다중 GPU 설정이 필요한 대형 모델 배포.
- 성능이 중요한 생산 환경.
Apidog로 Ollama 로컬 API 테스트하기
Apidog는 Ollama의 API 모드와 잘 어울리는 API 테스트 도구입니다. 요청을 보내고, 응답을 보고, Qwen3 설정을 효율적으로 디버깅할 수 있습니다.
Apidog와 Ollama를 사용하는 방법은 다음과 같습니다:
- 새 API 요청 만들기:
- 엔드포인트:
http://localhost:11434/api/generate - 요청을 보내고 Apidog의 실시간 타임라인에서 응답을 모니터링합니다.
- Apidog의 JSONPath 추출을 사용하여 응답을 자동으로 구문 분석합니다. 이 기능은 Postman과 같은 도구보다 뛰어납니다.


스트리밍 응답:
- 실시간 애플리케이션의 경우 스트리밍을 활성화합니다:
- Apidog의 자동 병합 기능은 스트리밍된 메시지를 통합하여 디버깅을 수월하게 만듭니다.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "AI에 대한 시를 쓰세요.", "stream": true}'

이 프로세스는 모델이 예상대로 작동하는지 확인하여 Apidog가 유용한 추가 기능임을 입증합니다.
결론
강력하고 다양한 Qwen3 모델 패밀리의 출시와 Ollama 및 vLLM과 같은 성숙한 로컬 실행 도구들은 AI 실무자들에게 흥미로운 시기를 나타냅니다. Ollama의 플러그 앤 플레이 단순성을 개인 사용 및 실험을 위해 우선시하든, 강력한 애플리케이션 구축을 위한 vLLM의 고성능 제공 능력을 선택하든, 최신 LLM을 로컬에서 실행하는 것이 그 어느 때보다 더 용이해졌습니다.
Qwen3-30B-A3B 또는 더 큰 조밀 변형 모델을 자신의 하드웨어에 가져옴으로써 전례 없는 제어, 개인 정보 보호 및 비용 효율성을 확보할 수 있습니다. 이러한 모델의 고급 기능인 혼합 사고 및 광범위한 다국어 지원을 혁신적인 프로젝트에 활용할 수 있습니다. 하드웨어와 소프트웨어 생태계가 계속해서 개선됨에 따라 대규모 언어 모델의 힘이 점점 더 민주화될 것이며, 먼 클라우드 서버에서 우리 로컬 머신으로 이동하게 될 것입니다. Ollama 및 vLLM을 사용하여 Qwen3를 실험해 보며 이 로컬 AI 혁명의 최전선에서 경험해 보세요.
개발 팀이 함께 최대 생산성으로 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요?
Apidog는 모든 요구를 충족하고 Postman을 훨씬 더 저렴한 가격으로 대체합니다!