
Moonshot AI가 출시한 Kimi K2.5는 오픈소스 모델의 새로운 기준을 세웠습니다. 1조 개의 매개변수와 전문가 혼합(MoE) 아키텍처를 통해 GPT-4o와 같은 독점 거대 모델들과 어깨를 나란히 합니다. 하지만 엄청난 크기 때문에 실행하기가 쉽지 않습니다.
개발자와 연구자에게 K2.5를 로컬에서 실행하는 것은 탁월한 개인 정보 보호, (네트워크 측면에서) 제로 지연 시간, 그리고 API 토큰 비용 절감이라는 이점을 제공합니다. 그러나 7B 또는 70B와 같은 작은 모델과는 달리, 이 모델은 일반 게이밍 노트북에 단순히 로드할 수 없습니다.
이 가이드는 Unsloth의 획기적인 양자화 기술을 활용하여 이 거대한 모델을 (어느 정도) 접근 가능한 하드웨어에 llama.cpp를 사용하여 구동하는 방법과 Apidog를 통해 개발 워크플로우에 통합하는 방법을 탐구합니다.
다운로드 버튼
Kimi K2.5를 실행하기 어려운 이유 (MoE의 도전 과제)
Kimi K2.5는 단순히 "크다"는 것을 넘어, 아키텍처적으로 복잡합니다. Mixtral 8x7B와 같은 일반적인 오픈 모델보다 훨씬 더 많은 전문가(expert)를 가진 전문가 혼합(MoE) 아키텍처를 사용합니다.
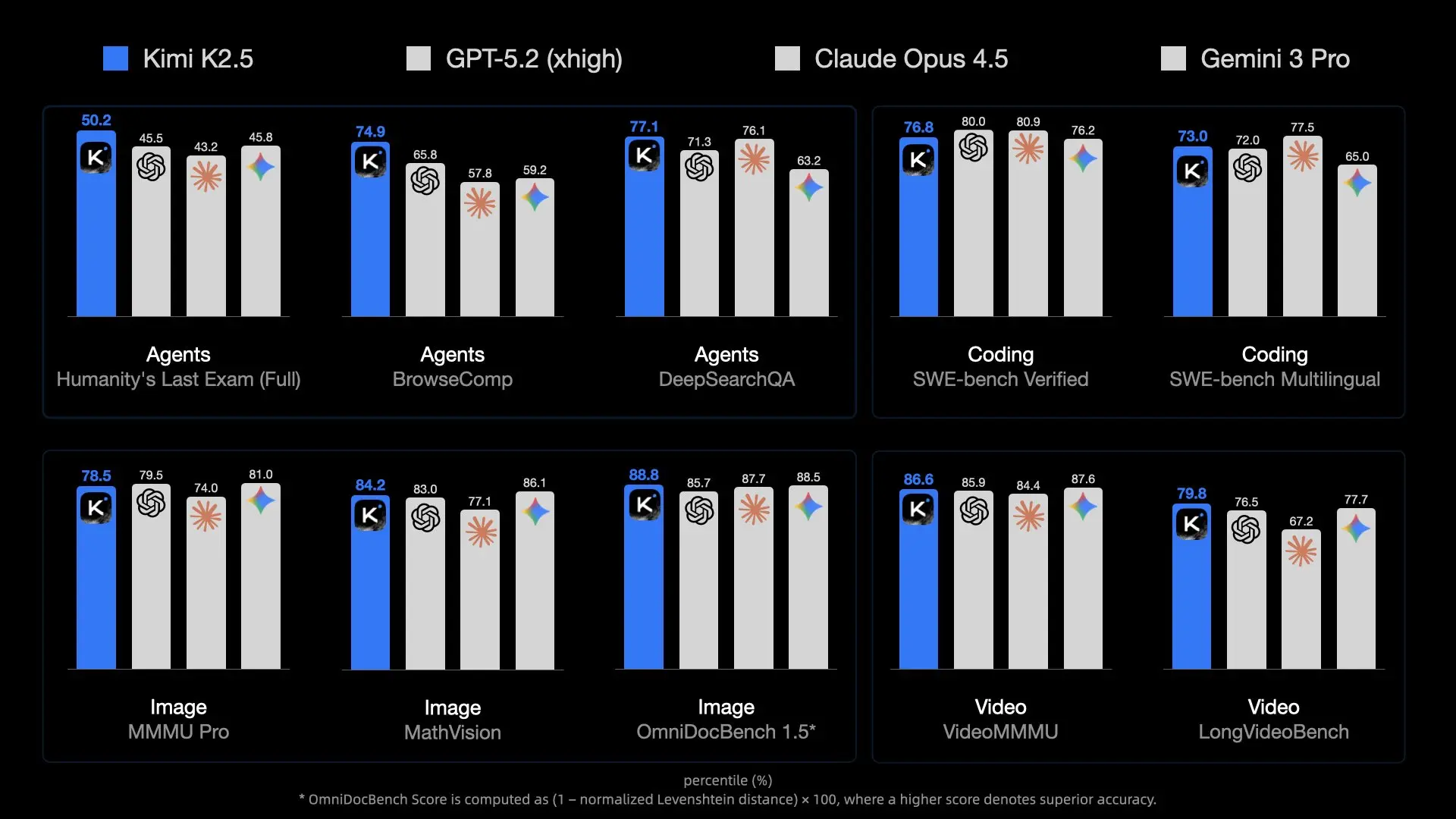
규모 문제
- 총 매개변수: 약 1조 개. 표준 FP16 정밀도에서는 약 2테라바이트의 VRAM이 필요합니다.
- 활성 매개변수: 추론은 토큰당 매개변수의 일부만 사용하지만(MoE 덕분에), 토큰을 올바르게 라우팅하려면 전체 모델을 메모리에 유지해야 합니다.
- 메모리 대역폭: 진짜 병목 현상은 용량이 아니라 속도입니다. 단일 토큰 생성을 위해 메모리 채널을 통해 240GB의 데이터를 이동시키는 것은 소비자 하드웨어에 엄청난 부담을 줍니다.
이것이 바로 양자화(가중치당 비트 감소)가 필수적인 이유입니다. Unsloth의 극단적인 1.58비트 압축 없이는 슈퍼컴퓨팅 클러스터의 영역에서만 실행할 수 있었을 것입니다.
하드웨어 요구 사항: 실행할 수 있을까요?
"1.58비트" 양자화는 모델 크기를 약 60% 압축하면서도 지능을 손상시키지 않아 이 모델 실행을 가능하게 하는 마법입니다.
최소 사양 (1.58비트 양자화)
- 디스크 공간: 240GB 이상 (NVMe SSD 강력 권장)
- RAM + VRAM: 총 240GB 이상
- 예시 1: RTX 3090 2개 (48GB VRAM) + 256GB 시스템 RAM (가능하지만 느림)
- 예시 2: Mac Studio M2 Ultra (192GB RAM) (부족함, 충돌 또는 심한 스왑 가능성 높음)
- 예시 3: 512GB RAM을 가진 서버 (CPU에서 잘 작동함)
- 연산: AVX2 지원 CPU 또는 NVIDIA GPU
권장 사양 (성능)
사용 가능한 속도(>10 토큰/초)를 얻으려면:
- VRAM: 가능한 한 많을수록 좋습니다. GPU로 레이어를 오프로드하면 속도가 크게 향상됩니다.
- 시스템: H100/H200 GPU 4개 (엔터프라이즈) 또는 512GB DDR5 RAM을 가진 워크스테이션 (소비자/프로슈머).
참고
해결책: Unsloth 다이내믹 GGUF
Unsloth는 Kimi K2.5의 다이내믹 GGUF 버전을 출시했습니다. 이 파일들을 사용하면 llama.cpp에 모델을 로드할 수 있으며, llama.cpp는 CPU(RAM)와 GPU(VRAM) 사이에 워크로드를 지능적으로 분할할 수 있습니다.
다이내믹 양자화란?
표준 양자화는 모든 레이어에 동일한 압축을 적용합니다. Unsloth의 "다이내믹" 접근 방식은 더 스마트합니다:
- 핵심 레이어 (어텐션/라우팅): 지능을 유지하기 위해 더 높은 정밀도(예: 4비트 또는 6비트)로 유지됩니다.
- 피드포워드 레이어: 공간 절약을 위해 1.58비트 또는 2비트로 공격적으로 압축됩니다.
이 하이브리드 접근 방식은 1조 개 매개변수 모델이 약 240GB에서 실행되면서도, 풀 정밀도로 실행되는 70B 모델보다 뛰어난 추론 능력을 유지하도록 합니다.
- 1.58비트 (UD-TQ1_0): 약 240GB. 가장 작은 실행 가능 버전입니다.
- 2비트 (UD-Q2_K_XL): 약 375GB. 더 나은 추론 성능을 제공하지만, 훨씬 더 많은 RAM이 필요합니다.
- 4비트 (UD-Q4_K_XL): 약 630GB. 거의 풀 정밀도 성능을 제공하며, 엔터프라이즈 하드웨어에서만 가능합니다.
단계별 설치 가이드
CPU/GPU 워크로드를 분할하는 데 가장 효율적인 추론 엔진을 제공하는 llama.cpp를 사용할 것입니다.
1단계: llama.cpp 설치
최신 Kimi K2.5 지원을 보장하려면 llama.cpp를 소스에서 빌드해야 합니다.
Mac/Linux:
# 의존성 설치
sudo apt-get update && sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
# 저장소 클론
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# CUDA 지원으로 빌드 (NVIDIA GPU가 있는 경우)
cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# 또는 CPU/Mac Metal용으로 빌드 (기본값)
# cmake -B build
# 컴파일
cmake --build build --config Release -j --clean-first --target llama-cli llama-server
2단계: 모델 다운로드
Unsloth GGUF 버전을 다운로드합니다. 대부분의 "홈 랩" 설정에는 1.58비트 버전이 권장됩니다.
huggingface-cli 또는 llama-cli를 직접 사용할 수 있습니다.
옵션 A: llama-cli를 이용한 직접 다운로드
# 모델 디렉토리 생성
mkdir -p models/kimi-k2.5
# 다운로드 및 실행 (모델이 캐시됨)
./build/bin/llama-cli \
-hf unsloth/Kimi-K2.5-GGUF:UD-TQ1_0 \
--model-url unsloth/Kimi-K2.5-GGUF \
--print-token-count 0
옵션 B: 수동 다운로드 (관리 용이)
pip install huggingface_hub
# 특정 양자화 버전 다운로드
huggingface-cli download unsloth/Kimi-K2.5-GGUF \
--include "*UD-TQ1_0*" \
--local-dir models/kimi-k2.5
3단계: 추론 실행
이제 모델을 실행해 보겠습니다. 최적의 성능을 위해 Moonshot AI가 권장하는 특정 샘플링 매개변수(temp 1.0, min-p 0.01)를 설정해야 합니다.
./build/bin/llama-cli \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--temp 1.0 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--threads 16 \
--prompt "User: Write a Python script to scrape a website.\nAssistant:"
주요 매개변수:
--fit on: 사용 가능한 VRAM에 맞게 레이어를 GPU로 자동 오프로드합니다 (하이브리드 설정에 필수적).--ctx-size: K2.5는 최대 256k를 지원하지만, 메모리 보존을 위해 16k가 더 안전합니다.
로컬 API 서버로 실행
Kimi K2.5를 앱이나 Apidog와 통합하려면 OpenAI 호환 서버로 실행합니다.
./build/bin/llama-server \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--port 8001 \
--alias "kimi-k2.5-local" \
--temp 1.0 \
--min-p 0.01 \
--ctx-size 16384 \
--host 0.0.0.0
이제 로컬 API는 http://127.0.0.1:8001/v1에서 활성화되었습니다.
Apidog를 로컬 Kimi K2.5에 연결
Apidog는 로컬 LLM을 테스트하는 데 완벽한 도구입니다. curl 스크립트를 작성할 필요 없이 요청을 시각적으로 구성하고, 대화 기록을 관리하며, 토큰 사용량을 디버깅할 수 있습니다.
1. 새 요청 생성
Apidog를 열고 새 HTTP 프로젝트를 생성합니다. 다음 주소로 POST 요청을 생성합니다:http://127.0.0.1:8001/v1/chat/completions
2. 헤더 구성
다음 헤더를 추가합니다:
Content-Type:application/jsonAuthorization:Bearer not-needed(로컬 서버는 일반적으로 키를 무시하지만, 좋은 습관입니다)
3. 본문 설정
OpenAI 호환 형식을 사용합니다:
{
"model": "kimi-k2.5-local",
"messages": [
{
"role": "system",
"content": "당신은 로컬에서 실행되는 Kimi입니다."
},
{
"role": "user",
"content": "양자 컴퓨팅을 한 문장으로 설명해 주세요."
}
],
"temperature": 1.0,
"max_tokens": 1024
}
4. 전송 및 확인
보내기를 클릭합니다. 응답 스트림이 들어오는 것을 볼 수 있습니다.
Apidog를 사용하는 이유?
- 지연 시간 추적: 로컬 모델이 응답하는 데 걸리는 시간(첫 토큰까지의 시간)을 정확히 확인합니다.
- 기록 관리: Apidog는 채팅 세션을 유지하여 로컬 모델의 다중 턴 대화 기능을 쉽게 테스트할 수 있도록 합니다.
- 코드 생성: 프롬프트가 작동하면 Apidog에서 "코드 생성"을 클릭하여 앱에서 이 로컬 서버를 사용하는 Python/JS 스니펫을 얻을 수 있습니다.
자세한 문제 해결 및 성능 튜닝
1조 개 매개변수 모델을 실행하는 것은 소비자 하드웨어를 한계까지 밀어붙입니다. 여기 모델을 안정적으로 유지하기 위한 고급 팁이 있습니다.
"모델 로드 실패: 메모리 부족"
이것이 가장 흔한 오류입니다.
- 컨텍스트 감소:
--ctx-size를 4096 또는 8192로 낮춥니다. - 앱 닫기: Chrome, VS Code, Docker를 종료합니다. 모든 RAM 바이트가 필요합니다.
- 디스크 오프로딩 사용 (최후의 수단):
llama.cpp는 모델 부분을 디스크에 매핑할 수 있지만, 추론 속도는 토큰/초 미만으로 떨어집니다.
"엉터리 출력" 또는 반복적인 텍스트
Kimi K2.5는 샘플링에 민감합니다. 다음을 사용하고 있는지 확인하세요:
Temperature: 1.0 (놀랍게도 높지만, 이 모델에 권장됨)Min-P: 0.01 (낮은 확률 토큰을 잘라내는 데 도움이 됨)Top-P: 0.95
느린 생성 속도
0.5 토큰/초의 속도가 나온다면, 시스템 RAM 대역폭 또는 CPU 속도에 병목 현상이 발생하고 있을 가능성이 높습니다.
- 최적화:
--threads가 물리적 CPU 코어 수(논리적 스레드 아님)와 일치하는지 확인합니다. - GPU 오프로드: 작은 GPU에 10개의 레이어를 오프로드하는 것만으로도 프롬프트 처리 시간을 크게 향상시킬 수 있습니다.
- NUMA 지원: 듀얼 소켓 서버를 사용하는 경우,
llama.cpp빌드 플래그에서 NUMA 인식을 활성화하여 메모리 접근을 최적화합니다.
충돌 처리
모델이 로드되지만 생성 중에 충돌하는 경우:
- 스왑 확인: 대용량 스왑 파일(100GB 이상)이 활성화되어 있는지 확인합니다. 256GB RAM이 있어도 일시적인 스파이크가 프로세스를 종료시킬 수 있습니다.
- KV 캐시 오프로드 비활성화: VRAM이 부족한 경우 KV 캐시를 CPU에 유지합니다(
--no-kv-offload).
준비되셨나요?
Kimi K2.5를 로컬에서 실행하든 API를 사용하기로 결정하든, Apidog는 AI 통합을 테스트하고, 문서화하며, 모니터링하기 위한 통합 플랫폼을 제공합니다. Apidog를 무료로 다운로드하고 지금 바로 실험을 시작하세요.
다운로드 버튼