
PDF나 기술 매뉴얼에 직접 질문할 수 있기를 바란 적이 있다면 이 가이드는 당신을 위한 것입니다. 오늘은 DeepSeek R1, 오픈 소스 추론 파워하우스와 Ollama, 로컬 AI 모델을 실행하기 위한 가벼운 프레임워크를 사용하여 Retrieval-Augmented Generation (RAG) 시스템을 구축할 것입니다.
API 테스트를 강화할 준비가 되셨나요? Apidog를 확인하는 것을 잊지 마세요! Apidog는 테스트 및 목업 서버를 생성, 관리 및 실행하는 원스톱 플랫폼 역할을 하여 병목 현상을 정확히 찾아내고 API를 신뢰할 수 있도록 유지합니다.
여러 도구를 운용하거나 방대한 스크립트를 작성하는 대신, 주요 작업 흐름을 자동화하고 매끄러운 CI/CD 파이프라인을 구현하여 제품 기능을 다듬는 데 더 많은 시간을 보낼 수 있습니다.
이러한 식으로 당신의 삶을 간소화할 수 있을 것 같다면, Apidog를 시도해 보세요!
이번 포스트에서는 OpenAI의 o1과 성능이 맞먹지만 비용은 95% 저렴한 DeepSeek R1이 어떻게 RAG 시스템을 강화할 수 있는지 탐구할 것입니다. 왜 개발자들이 이 기술에 몰려드는지, 그리고 당신이 어떻게 이와 함께 자체 RAG 파이프라인을 구축할 수 있는지 알아보겠습니다.
이 로컬 RAG 시스템의 비용은 얼마인가요?
| 구성 요소 | 비용 |
|---|---|
| DeepSeek R1 1.5B | 무료 |
| Ollama | 무료 |
| 16GB RAM PC | $0 |
DeepSeek R1의 1.5B 모델이 여기서 빛나는 이유는:
- 집중된 검색: 각 답변에 3개의 문서 조각만 사용
- 엄격한 프롬프트: "모르겠습니다"는 환각을 방지함
- 로컬 실행: 클라우드 API와 비교하여 제로 지연
필요한 것
코드를 작성하기 전에 도구 세트를 설정합시다:
1. Ollama
Ollama를 통해 DeepSeek R1과 같은 모델을 로컬에서 실행할 수 있습니다.
- 다운로드: https://ollama.com/
- 설치 후, 터미널을 열고 다음을 실행하십시오:
ollama run deepseek-r1 # 7B 모델(기본값)
2. DeepSeek R1 모델 변형
DeepSeek R1은 1.5B부터 671B 파라미터까지 다양한 크기로 제공됩니다. 이 데모에서는 가벼운 RAG에 적합한 1.5B 모델을 사용할 것입니다:
ollama run deepseek-r1:1.5b
프로 팁: 70B와 같은 더 큰 모델은 더 나은 추론을 제공하지만 더 많은 RAM이 필요합니다. 작게 시작한 후 확장하세요!

RAG 파이프라인 구축: 코드 워크스루
1단계: 라이브러리 가져오기
우리는 다음을 사용할 것입니다:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
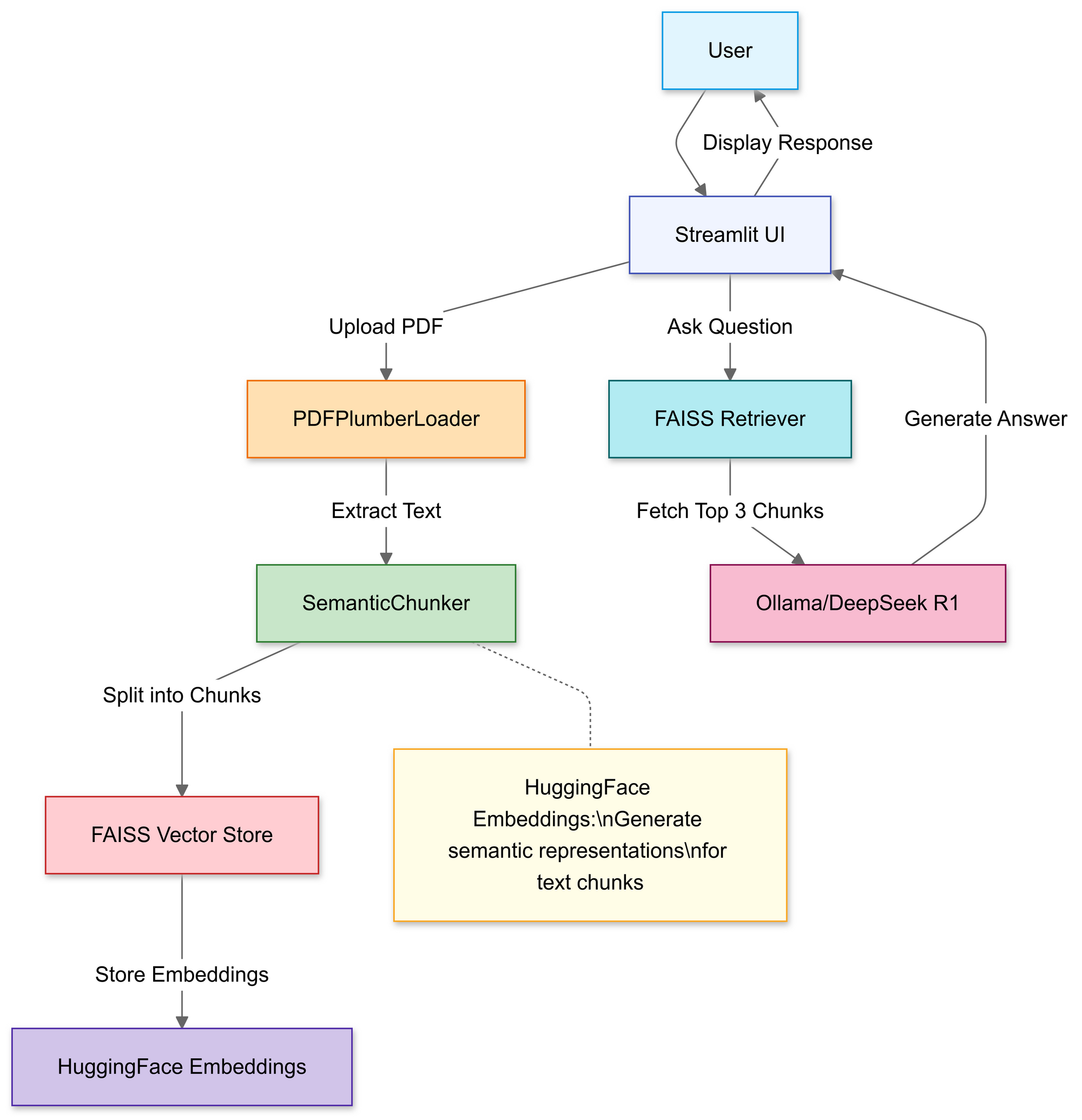
2단계: PDF 업로드 및 처리
이 섹션에서는 Streamlit의 파일 업로더를 사용하여 사용자가 로컬 PDF 파일을 선택할 수 있도록 합니다.
# Streamlit 파일 업로더
uploaded_file = st.file_uploader("PDF 파일 업로드", type="pdf")
if uploaded_file:
# PDF를 임시로 저장
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# PDF 텍스트 로드
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
업로드가 완료되면 PDFPlumberLoader 함수가 PDF에서 텍스트를 추출하여 파이프라인의 다음 단계로 준비합니다. 이 접근 방식은 파일 내용을 읽는 모든 작업을 처리하므로 효율적입니다.
3단계: 문서 전략적으로 나누기
우리는 RecursiveCharacterTextSplitter를 사용하여 원본 PDF 텍스트를 더 작은 세그먼트(청크)로 나누고 싶습니다. 좋은 청킹과 나쁜 청킹의 개념을 설명하겠습니다:
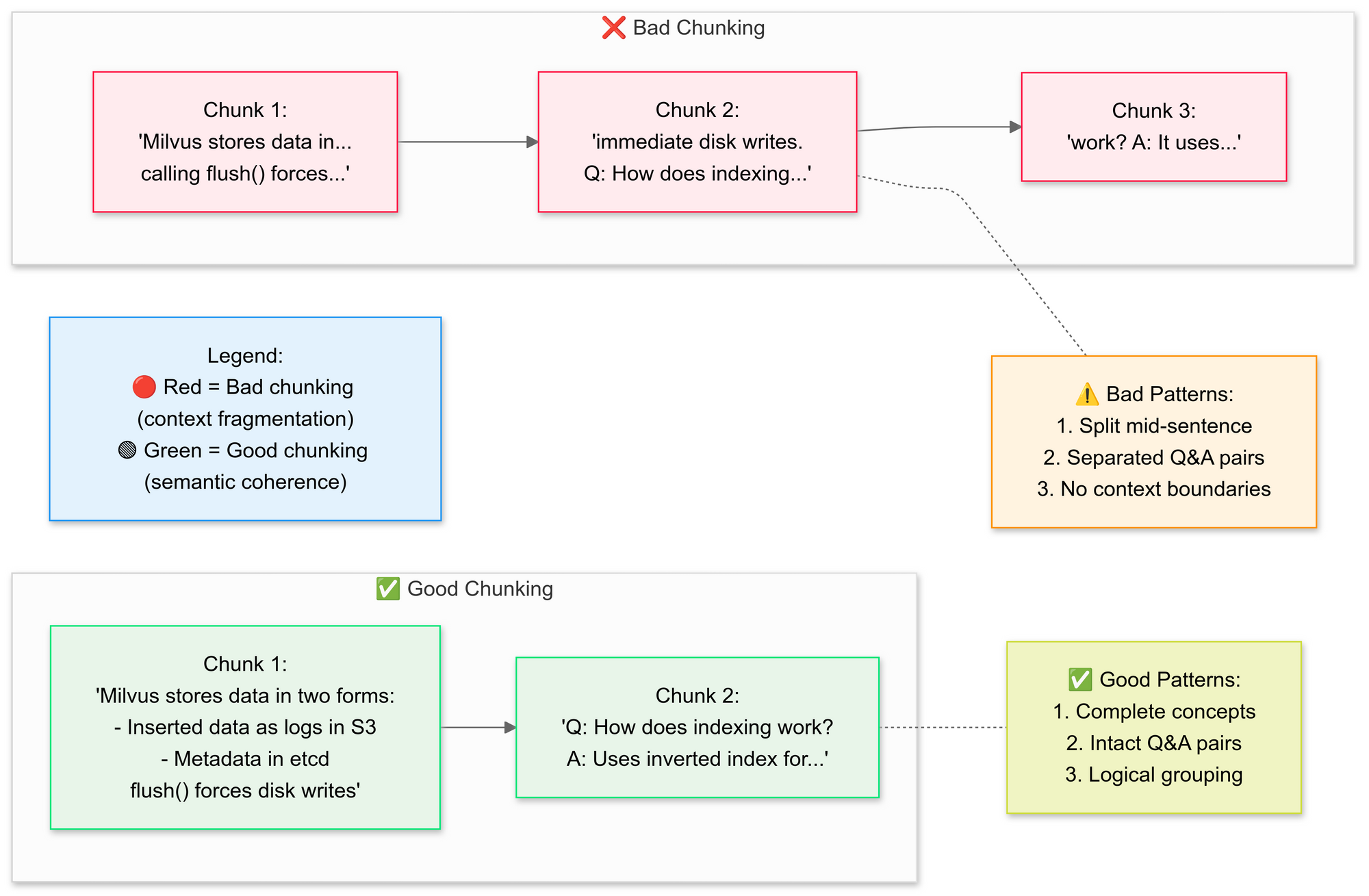
왜 의미적 청킹인가요?
- 관련 문장을 그룹화합니다(예: "Milvus가 데이터를 저장하는 방법"은 그대로 유지됨)
- 표나 다이어그램을 나누지 않습니다
# 텍스트를 의미적 청크로 분할
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
이 단계에서는 세그먼트가 약간 겹치도록 하여 맥락을 보존하므로 언어 모델이 질문에 보다 정확하게 답변할 수 있습니다. 잘 정의된 작은 문서 청크는 검색을 더 효율적이고 관련성 있게 만듭니다.
4단계: 검색 가능한 지식 기반 생성
분할 후 파이프라인은 세그먼트에 대한 벡터 임베딩을 생성하고 이를 FAISS 인덱스에 저장합니다.
# 임베딩 생성
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# 검색기 연결
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 상위 3개 청크 가져오기
이것은 텍스트를 쿼리하기 훨씬 쉬운 숫자 표현으로 변환합니다. 쿼리는 나중에 이 인덱스를 기준으로 하여 가장 맥락적으로 관련된 청크를 찾습니다.
5단계: DeepSeek R1 구성
여기에서 Deepseek R1 1.5B을 로컬 LLM으로 사용하여 RetrievalQA 체인을 인스턴스화합니다.
llm = Ollama(model="deepseek-r1:1.5b") # 우리의 1.5B 파라미터 모델
# 프롬프트 템플릿 작성
prompt = """
1. 아래 맥락만 사용하세요.
2. 확실하지 않은 경우 "모르겠습니다"라고 말하세요.
3. 답변은 4문장을 넘지 않도록 하세요.
맥락: {context}
질문: {question}
답변:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
이 템플릿은 모델이 PDF의 콘텐츠에 답변을 기반으로 하도록 합니다. 언어 모델을 FAISS 인덱스와 연결된 검색기로 감싸면서 체인에서 수행된 모든 쿼리는 PDF의 내용을 참조하여 답변을 제공합니다.
6단계: RAG 체인 조립
다음으로, 업로드, 청킹 및 검색 단계를 일관된 파이프라인으로 연결할 수 있습니다.
# 체인 1: 답변 생성
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# 체인 2: 문서 청크 결합
document_prompt = PromptTemplate(
template="맥락:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# 최종 RAG 파이프라인
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
이것은 RAG(검색 증강 생성) 설계의 핵심으로, 대형 언어 모델이 자체 훈련만으로 의존하지 않고 검증된 맥락을 제공합니다.
7단계: 웹 인터페이스 시작
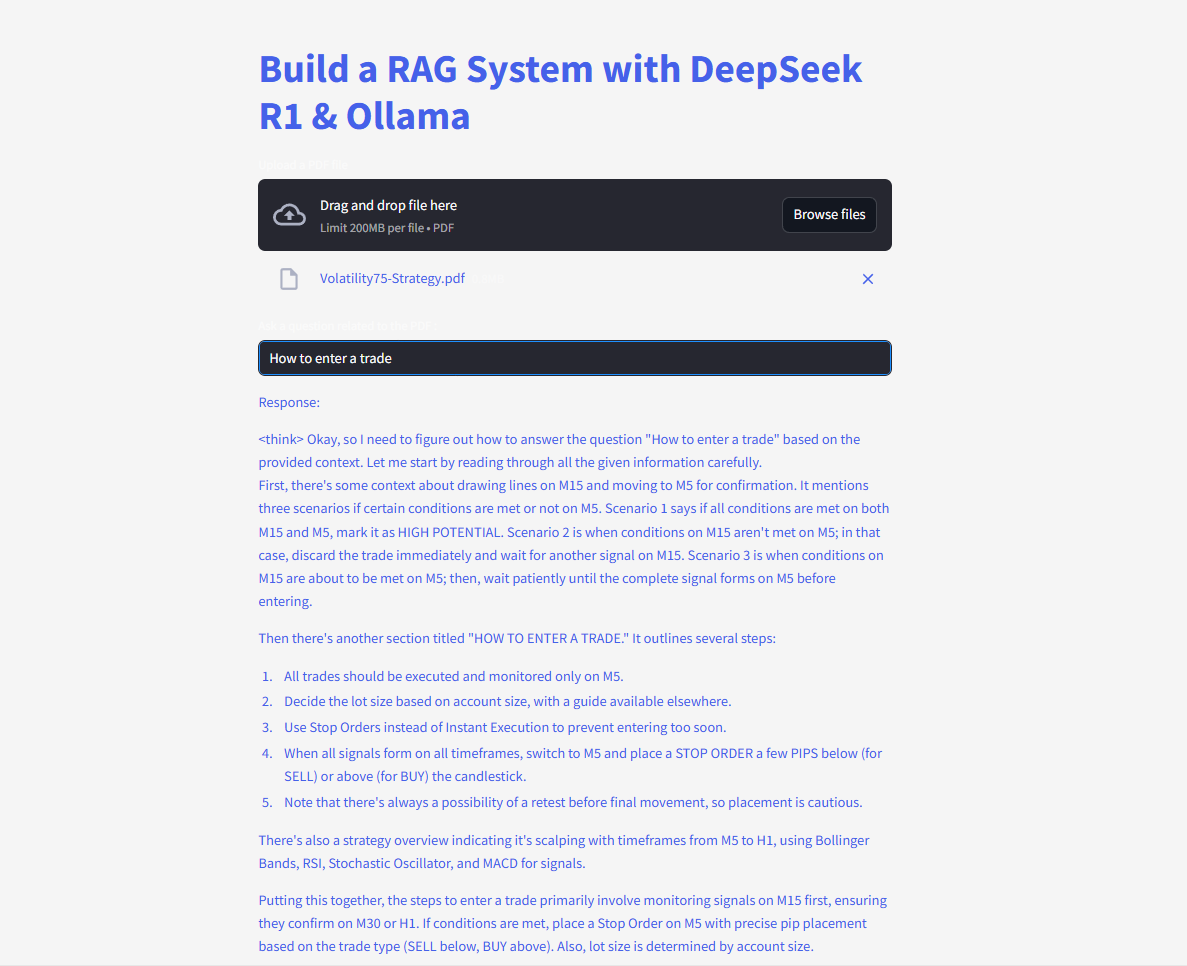
마지막으로, 코드는 Streamlit의 텍스트 입력 및 작성 기능을 사용하여 사용자가 질문을 입력하고 즉시 응답을 볼 수 있도록 합니다.
# Streamlit UI
user_input = st.text_input("PDF에 질문하세요:")
if user_input:
with st.spinner("고민 중..."):
response = qa(user_input)["result"]
st.write(response)
사용자가 쿼리를 입력하자마자 체인은 가장 일치하는 청크를 검색하고 이를 언어 모델에 피드하여 답변을 표시합니다. langchain 라이브러리가 제대로 설치되면 이 코드는 이제 누락된 모듈 오류 없이 작동해야 합니다.
질문하고 제출하여 즉각적인 답변을 받으세요!
전체 코드는 다음과 같습니다:
DeepSeek와 함께하는 RAG의 미래
자체 검증 및 다중 홉 추론과 같은 기능이 개발 중인 DeepSeek R1은 더욱 진보된 RAG 애플리케이션의 잠금을 해제할 준비가 되어 있습니다. 단순히 질문에 답하는 것이 아닌 자신의 논리를 논의하는 AI를 상상해 보세요—자율적으로.