
Qwen3와 같은 대규모 언어 모델(LLM)은 코딩, 추론 및 자연어 이해 분야의 인상적인 능력으로 AI 환경에 혁명을 일으키고 있습니다. Alibaba의 Qwen 팀이 개발한 Qwen3는 효율적인 로컬 배포를 가능하게 하는 양자화된 모델을 제공하여 개발자, 연구원 및 애호가가 자체 하드웨어에서 이러한 강력한 모델을 실행할 수 있도록 합니다. Ollama, LM Studio 또는 vLLM을 사용하든 관계없이 이 가이드는 Qwen3 양자화된 모델을 로컬에서 설정하고 실행하는 과정을 안내합니다.
이 기술 가이드에서는 설정 프로세스, 모델 선택, 배포 방법 및 API 통합에 대해 살펴보겠습니다. 시작해 보겠습니다.
Qwen3 양자화된 모델이란 무엇인가요?
Qwen3는 Alibaba의 최신 LLM 세대로, 코딩, 수학 및 일반 추론과 같은 작업 전반에 걸쳐 고성능을 발휘하도록 설계되었습니다. BF16, FP8, GGUF, AWQ 및 GPTQ 형식과 같은 양자화된 모델은 계산 및 메모리 요구 사항을 줄여 소비자급 하드웨어에서 로컬 배포에 이상적입니다.
Qwen3 제품군은 다양한 모델을 포함합니다:
- Qwen3-235B-A22B (MoE): BF16, FP8, GGUF 및 GPTQ-int4 형식을 지원하는 전문가 혼합 모델입니다.
- Qwen3-30B-A3B (MoE): 유사한 양자화 옵션을 가진 또 다른 MoE 변형 모델입니다.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): BF16, FP8, GGUF, AWQ 및 GPTQ-int8 형식으로 제공되는 밀집 모델입니다.
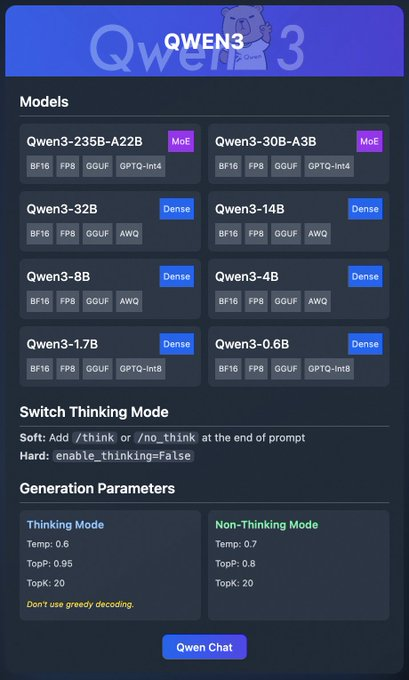
이 모델들은 Ollama, LM Studio 및 vLLM과 같은 플랫폼을 통해 유연한 배포를 지원하며, 이에 대해 자세히 다룰 것입니다. 또한 Qwen3는 더 나은 추론을 위해 토글할 수 있는 "사고 모드"와 출력 품질을 미세 조정하는 생성 매개변수와 같은 기능을 제공합니다.
이제 기본 사항을 이해했으니, Qwen3를 로컬에서 실행하기 위한 필수 조건으로 넘어가겠습니다.
Qwen3를 로컬에서 실행하기 위한 필수 조건
Qwen3 양자화된 모델을 배포하기 전에 시스템이 다음 요구 사항을 충족하는지 확인하세요:
하드웨어:
- 최신 CPU 또는 GPU (vLLM의 경우 NVIDIA GPU 권장).
- Qwen3-4B와 같은 소형 모델의 경우 최소 16GB RAM; Qwen3-32B와 같은 대형 모델의 경우 32GB 이상.
- 충분한 저장 공간 (예: Qwen3-235B-A22B GGUF는 약 150GB 필요).
소프트웨어:
- 호환 가능한 운영 체제 (Windows, macOS 또는 Linux).
- vLLM 및 API 상호 작용을 위한 Python 3.8+.
- Docker (선택 사항, vLLM용).
- 저장소 복제를 위한 Git.
종속성:
torch,transformers및vllm(vLLM용)과 같은 필수 라이브러리 설치.- 공식 웹사이트에서 Ollama 또는 LM Studio 바이너리 다운로드.
이러한 필수 조건이 충족되면 Qwen3 양자화된 모델을 다운로드하는 단계로 진행하겠습니다.
1단계: Qwen3 양자화된 모델 다운로드
먼저 신뢰할 수 있는 소스에서 양자화된 모델을 다운로드해야 합니다. Qwen 팀은 Hugging Face 및 ModelScope에서 Qwen3 모델을 제공합니다.
Hugging Face에서 다운로드하는 방법
- Hugging Face Qwen3 컬렉션을 방문합니다.
- 경량 배포를 위해 GGUF 형식의 Qwen3-4B와 같은 모델을 선택합니다.
- "Download" 버튼을 클릭하거나
git clone명령을 사용하여 모델 파일을 가져옵니다:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- 모델 파일을
/models/qwen3-4b-gguf와 같은 디렉토리에 저장합니다.
ModelScope에서 다운로드하는 방법
- ModelScope Qwen3 컬렉션으로 이동합니다.
- 원하는 모델과 양자화 형식(예: AWQ 또는 GPTQ)을 선택합니다.
- 파일을 수동으로 다운로드하거나 프로그래밍 방식 액세스를 위해 해당 API를 사용합니다.
모델 다운로드가 완료되면 Ollama를 사용하여 배포하는 방법을 살펴보겠습니다.
2단계: Ollama를 사용하여 Qwen3 배포
Ollama는 최소한의 설정으로 LLM을 로컬에서 실행하는 사용자 친화적인 방법을 제공합니다. Qwen3의 GGUF 형식을 지원하여 초보자에게 이상적입니다.
Ollama 설치
- Ollama 공식 웹사이트를 방문하여 운영 체제에 맞는 바이너리를 다운로드합니다.
- 설치 프로그램을 실행하거나 명령줄 지침에 따라 Ollama를 설치합니다:
curl -fsSL https://ollama.com/install.sh | sh
- 설치를 확인합니다:
ollama --version
Ollama로 Qwen3 실행
- 모델을 시작합니다:
ollama run qwen3:235b-a22b-q8_0- 모델이 실행되면 명령줄을 통해 상호 작용할 수 있습니다:
>>> 안녕하세요, 무엇을 도와드릴까요?
Ollama는 또한 프로그래밍 방식 액세스를 위한 로컬 API 엔드포인트(일반적으로 http://localhost:11434)를 제공하며, 이는 나중에 Apidog를 사용하여 테스트할 것입니다.
다음으로, Qwen3를 실행하기 위해 LM Studio를 사용하는 방법을 살펴보겠습니다.
3단계: LM Studio를 사용하여 Qwen3 배포
LM Studio는 모델 관리를 위한 그래픽 인터페이스를 제공하는 또 다른 인기 있는 로컬 LLM 실행 도구입니다.
LM Studio 설치
- LM Studio 공식 웹사이트에서 다운로드합니다.
- 화면 지침에 따라 애플리케이션을 설치합니다.
- LM Studio를 실행하고 정상적으로 작동하는지 확인합니다.
LM Studio에서 Qwen3 로드
LM Studio에서 "Local Models" 섹션으로 이동합니다.
"Add Model"을 클릭하고 모델을 검색하여 다운로드합니다:
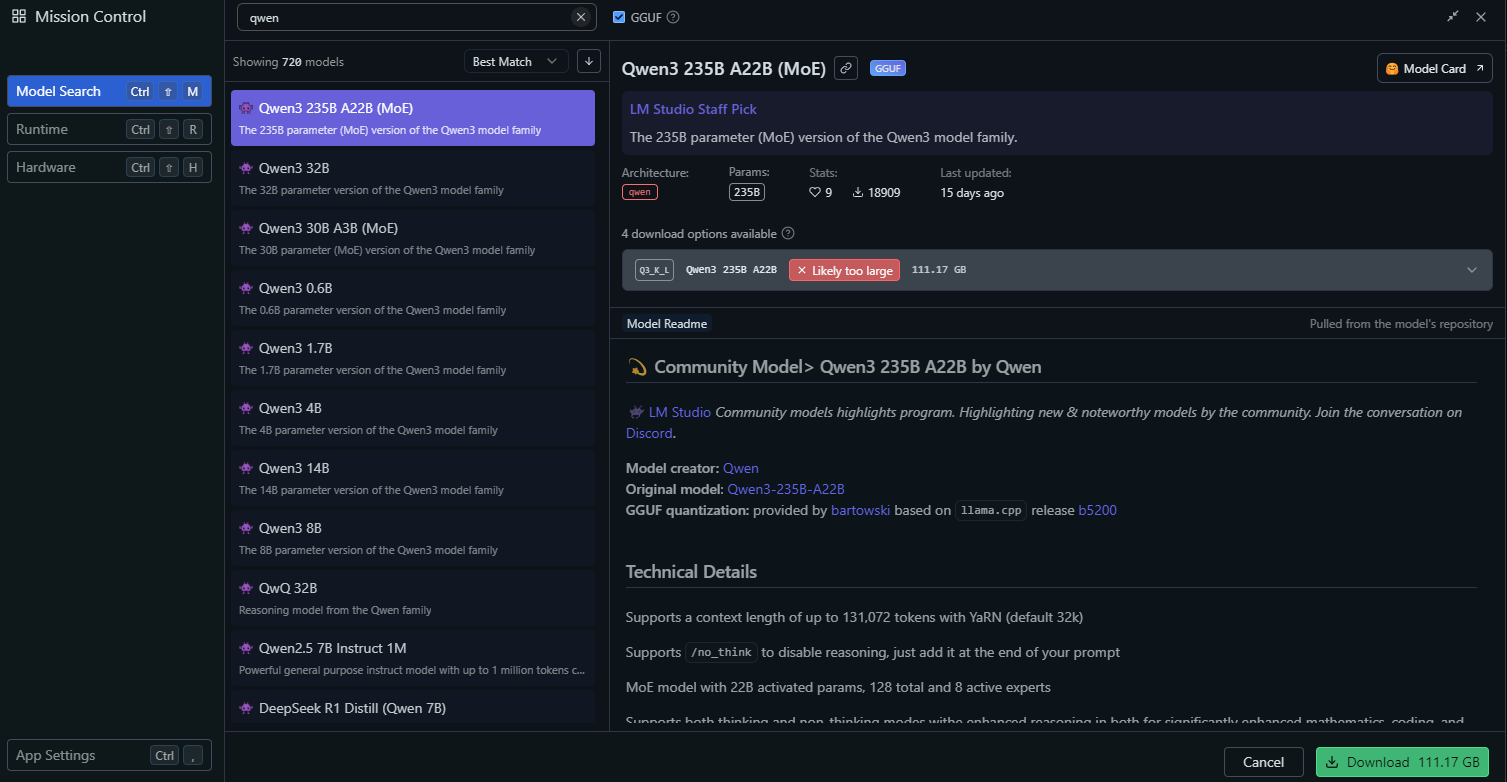
다음과 같은 모델 설정을 구성합니다:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
이 설정은 Qwen3의 권장 사고 모드 매개변수와 일치합니다.
"Start Server"를 클릭하여 모델 서버를 시작합니다. LM Studio는 로컬 API 엔드포인트(예: http://localhost:1234)를 제공합니다.
LM Studio에서 Qwen3와 상호 작용
- LM Studio의 내장 채팅 인터페이스를 사용하여 모델을 테스트합니다.
- 또는 API 테스트 섹션에서 살펴볼 API 엔드포인트를 통해 모델에 액세스합니다.
LM Studio 설정이 완료되었으니, vLLM을 사용하는 고급 배포 방법으로 넘어가겠습니다.
4단계: vLLM을 사용하여 Qwen3 배포
vLLM은 LLM에 최적화된 고성능 서빙 솔루션으로, Qwen3의 FP8 및 AWQ 양자화된 모델을 지원합니다. 강력한 애플리케이션을 구축하는 개발자에게 이상적입니다.
vLLM 설치
- 시스템에 Python 3.8+가 설치되어 있는지 확인합니다.
- pip를 사용하여 vLLM을 설치합니다:
pip install vllm
- 설치를 확인합니다:
python -c "import vllm; print(vllm.__version__)"
vLLM으로 Qwen3 실행
Qwen3 모델로 vLLM 서버를 시작합니다.
# 모델 로드 및 실행:
vllm serve "Qwen/Qwen3-235B-A22B"--enable-thinking=False 플래그는 Qwen3의 사고 모드를 비활성화합니다.
서버가 시작되면 http://localhost:8000에서 API 엔드포인트를 제공합니다.
최적의 성능을 위해 vLLM 구성
vLLM은 다음과 같은 고급 구성을 지원합니다:
- Tensor Parallelism: GPU 설정에 따라
--tensor-parallel-size를 조정합니다. - Context Length: Qwen3는 최대 32,768 토큰을 지원하며,
--max-model-len 32768을 통해 설정할 수 있습니다. - Generation Parameters: API를 사용하여
temperature,top_p및top_k를 설정합니다 (예: 비사고 모드의 경우 0.7, 0.8, 20).
vLLM이 실행되면 Apidog를 사용하여 API 엔드포인트를 테스트해 보겠습니다.
5단계: Apidog로 Qwen3 API 테스트
Apidog는 API 엔드포인트를 테스트하는 강력한 도구로, 로컬에 배포된 Qwen3 모델과 상호 작용하는 데 완벽합니다.
Apidog 설정
- Apidog 공식 웹사이트에서 Apidog를 다운로드하여 설치합니다.
- Apidog를 실행하고 새 프로젝트를 생성합니다.
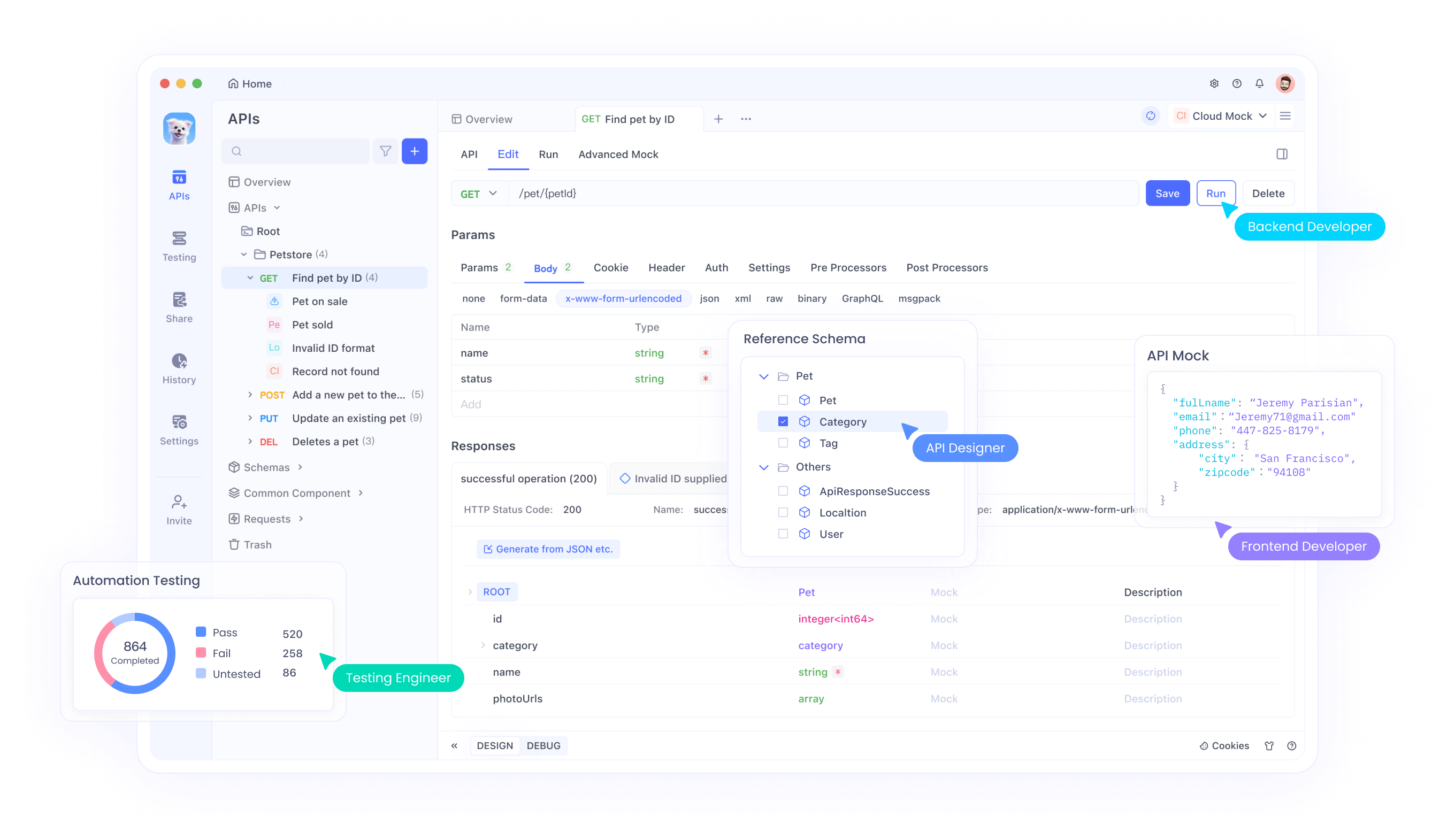
Ollama API 테스트
- Apidog에서 새 API 요청을 생성합니다.
- 엔드포인트를
http://localhost:11434/api/generate로 설정합니다. - 요청을 구성합니다:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- 요청을 보내고 응답을 확인합니다.
vLLM API 테스트
- Apidog에서 다른 API 요청을 생성합니다.
- 엔드포인트를
http://localhost:8000/v1/completions로 설정합니다. - 요청을 구성합니다:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- 요청을 보내고 출력을 확인합니다.
Apidog를 사용하면 Qwen3 배포를 쉽게 검증하고 API가 올바르게 작동하는지 확인할 수 있습니다. 이제 모델의 성능을 미세 조정해 보겠습니다.
6단계: Qwen3 성능 미세 조정
Qwen3의 성능을 최적화하려면 사용 사례에 따라 다음 설정을 조정하세요:
사고 모드
Qwen3는 X 게시물 이미지에서 강조된 것처럼 향상된 추론을 위한 "사고 모드"를 지원합니다. 두 가지 방법으로 제어할 수 있습니다:
- Soft Switch: 프롬프트에
/think또는/no_think를 추가합니다.
- 예:
이 수학 문제를 푸세요 /think.
- Hard Switch: vLLM에서
--enable-thinking=False를 사용하여 사고를 완전히 비활성화합니다.
생성 매개변수
더 나은 출력 품질을 위해 생성 매개변수를 미세 조정합니다:
- Temperature: 사고 모드의 경우 0.6, 비사고 모드의 경우 0.7을 사용합니다.
- Top-P: 0.95 (사고) 또는 0.8 (비사고)로 설정합니다.
- Top-K: 두 모드 모두 20을 사용합니다.
- Qwen 팀의 권장 사항에 따라 욕심 많은 디코딩은 피합니다.
이러한 설정을 실험하여 창의성과 정확성 사이의 원하는 균형을 달성하세요.
일반적인 문제 해결
Qwen3를 배포하는 동안 몇 가지 문제가 발생할 수 있습니다. 일반적인 문제에 대한 해결책은 다음과 같습니다:
Ollama에서 모델 로드 실패:
Modelfile의 GGUF 파일 경로가 올바른지 확인합니다.- 모델을 로드할 만큼 시스템에 충분한 메모리가 있는지 확인합니다.
vLLM Tensor Parallelism 오류:
- "output_size is not divisible by weight quantization block_n"과 같은 오류가 표시되면
--tensor-parallel-size를 줄입니다 (예: 4로).
Apidog에서 API 요청 실패:
- 서버 (Ollama, LM Studio 또는 vLLM)가 실행 중인지 확인합니다.
- 엔드포인트 URL과 요청 페이로드를 다시 확인합니다.
이러한 문제를 해결하면 원활한 배포 경험을 보장할 수 있습니다.
결론
Ollama, LM Studio 및 vLLM과 같은 도구를 사용하면 Qwen3 양자화된 모델을 로컬에서 실행하는 것이 간단한 프로세스입니다. 애플리케이션을 구축하는 개발자이든 LLM을 실험하는 연구원이든 Qwen3는 필요한 유연성과 성능을 제공합니다. 이 가이드를 따르면 Hugging Face 및 ModelScope에서 모델을 다운로드하고, 다양한 프레임워크를 사용하여 배포하고, Apidog로 해당 API 엔드포인트를 테스트하는 방법을 배웠습니다.
오늘 Qwen3 탐색을 시작하고 프로젝트를 위한 로컬 LLM의 힘을 잠금 해제하세요!