
Alibaba의 Qwen 시리즈는 대규모 언어 모델 분야에서 지속적으로 한계를 뛰어넘고 있으며, Qwen3-Next-80B-A3B는 고성능과 효율성이 결합된 대표적인 사례입니다. 엔지니어와 개발자는 거대한 모델의 계산 오버헤드 없이 강력한 추론을 제공하는 모델을 찾습니다. 이 모델은 800억 개의 매개변수를 자랑하면서도 토큰당 30억 개만 활성화하여 이러한 요구를 정면으로 충족합니다. 결과적으로 팀은 더 빠른 추론 속도와 감소된 훈련 비용을 달성하여 실제 배포에 이상적입니다.
이 게시물에서는 Qwen3-Next-80B-A3B의 핵심 구성 요소를 탐색하고, 혁신적인 아키텍처를 분석하며, 경험적 성능 데이터를 검토하고, 실용적인 단계를 통해 API를 숙달합니다. 또한 Apidog와 같은 도구를 통합하여 워크플로우를 향상시킵니다. 이 글을 마치면 이 모델을 애플리케이션에 효과적으로 배포할 수 있는 지식을 갖추게 될 것입니다.
Qwen3-Next-80B-A3B를 정의하는 요소: 핵심 기능 및 혁신
Qwen3-Next-80B-A3B는 Alibaba의 Qwen 제품군에서 속도와 기능 모두에 최적화된 희소 전문가 혼합(MoE) 모델로 등장했습니다. 개발자는 추론 중에 매개변수의 일부만 활성화하여 상당한 리소스 절약을 달성합니다. 특히 이 모델은 512개의 전문가와 함께 토큰당 10개, 공유 전문가 1개로 라우팅하는 초희소 MoE 설정을 사용합니다. 그 결과 Qwen3-32B와 같은 더 밀집된 모델과 유사한 성능을 발휘하면서도 훨씬 적은 전력을 소비합니다.
또한 이 모델은 추론적 디코딩을 가속화하는 기술인 다중 토큰 예측을 지원합니다. 이 기능은 모델이 여러 토큰을 동시에 생성하여 디코딩 단계에서 처리량을 높일 수 있도록 합니다. 개발자는 챗봇이나 실시간 분석 도구와 같이 빠른 응답이 필요한 애플리케이션에 이 기능을 유용하게 활용합니다.
이 시리즈에는 특정 요구 사항에 맞춰진 다양한 모델이 포함됩니다. 일반 사전 훈련을 위한 기본 모델, 미세 조정된 대화 작업을 위한 instruct 버전, 고급 추론 체인을 위한 thinking 버전이 있습니다. 예를 들어, Qwen3-Next-80B-A3B-Thinking은 복잡한 문제 해결에 탁월하며 벤치마크에서 Gemini-2.5-Flash-Thinking과 같은 모델을 능가합니다. 또한 119개 언어를 처리할 수 있어 재훈련 없이 다국어 배포가 가능합니다.
훈련 세부 사항은 추가적인 효율성을 보여줍니다. Alibaba 엔지니어는 확장 효율적인 방법을 사용하여 이 모델을 사전 훈련했으며, Qwen3-32B에 비해 10%의 비용만 발생했습니다. 그들은 2048개의 숨겨진 차원을 가진 48개 레이어에 걸쳐 하이브리드 레이아웃을 활용하여 균형 잡힌 계산 분배를 보장합니다. 결과적으로 이 모델은 다른 모델이 실패하는 32K 토큰 이상에서도 정확도를 유지하며 뛰어난 장문 맥락 이해 능력을 보여줍니다.
실제로 이러한 기능은 개발자가 AI 솔루션을 비용 효율적으로 확장할 수 있도록 지원합니다. 엔터프라이즈 검색 엔진을 구축하든 자동화된 콘텐츠 생성기를 구축하든, Qwen3-Next-80B-A3B는 혁신적인 애플리케이션의 기반을 제공합니다. 이 기반을 바탕으로 다음 섹션에서는 이러한 효율성을 가능하게 하는 아키텍처 요소를 살펴봅니다.
Qwen3-Next-80B-A3B 아키텍처 분석: 기술 청사진
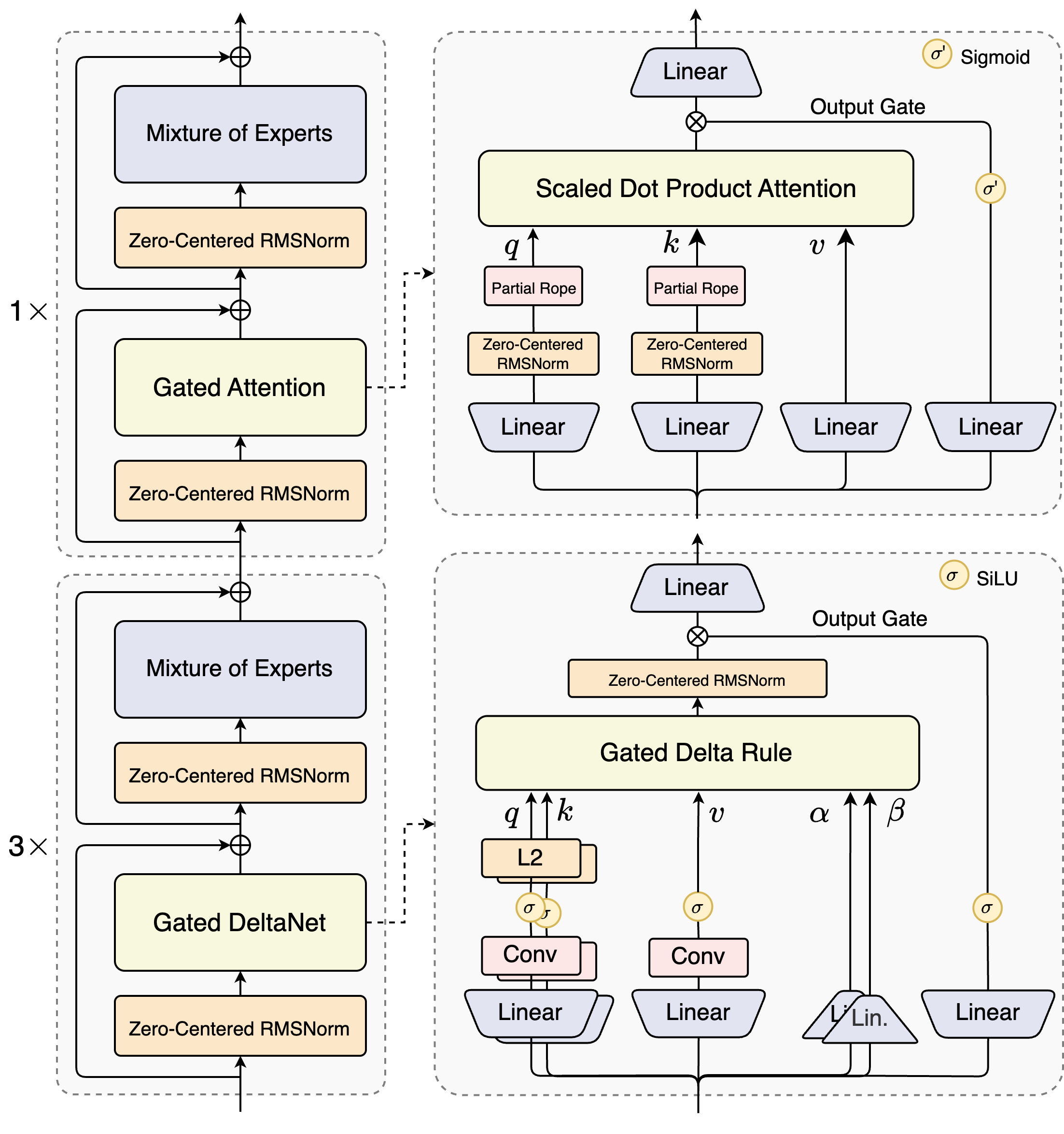
Qwen3-Next-80B-A3B의 설계자들은 게이트 메커니즘과 고급 정규화 기술을 결합한 하이브리드 설계를 도입했습니다. 그 핵심에는 전문가 혼합(MoE) 레이어가 있으며, 여기서 전문가들은 서로 다른 계산 경로를 전문으로 합니다. 모델은 오버헤드를 최소화하기 위해 입력의 일부를 동적으로 라우팅합니다. 예를 들어, 게이트 어텐션 블록은 부분 RoPE 임베딩과 제로 중심 RMSNorm 레이어를 통해 쿼리, 키, 값을 처리하여 긴 시퀀스에서 안정성을 향상시킵니다.
스케일드 닷 프로덕트 어텐션 모듈을 고려해 보세요. 이 모듈은 선형 투영에 이어 시그모이드 활성화에 의해 조절되는 출력 게이트를 통합합니다. 이 설정은 정보 흐름을 정밀하게 제어하여 고차원 공간에서 희석되는 것을 방지합니다. 또한 제로 중심 RMSNorm은 이러한 작업 전후에 적용되어 활성화를 0을 중심으로 배치하여 훈련 중 기울기 문제를 완화합니다.
이 다이어그램은 두 가지 주요 블록을 보여줍니다. 위쪽 블록은 스케일드 닷 프로덕트 어텐션을 사용한 게이트 어텐션에 초점을 맞추고, 아래쪽 블록은 게이트 DeltaNet을 강조합니다. 어텐션 경로(1배 확장)에서 입력은 제로 중심 RMSNorm을 거쳐 게이트 어텐션 코어로 흐릅니다. 여기서 쿼리(q), 키(k), 값(v) 투영은 위치 인코딩을 위해 부분 RoPE를 사용합니다. 어텐션 후, 또 다른 RMSNorm 및 선형 레이어가 MoE로 피드되며, MoE는 시그모이드 게이트 출력을 사용합니다.
DeltaNet 경로(3배 확장)로 전환하면 아키텍처는 정교한 예측을 위해 게이트 Delta 규칙을 사용합니다. 이 규칙은 q 및 k에 대한 L2 정규화, 로컬 특징 추출을 위한 컨볼루션 레이어, 비선형성을 위한 SiLU 활성화를 특징으로 합니다. 출력 게이트는 선형 투영과 결합되어 일관된 다중 토큰 출력을 보장합니다. 이 블록의 설계는 모델의 추론적 디코딩을 지원하며, 여기서 여러 토큰을 미리 예측하고 후속 패스에서 검증합니다.
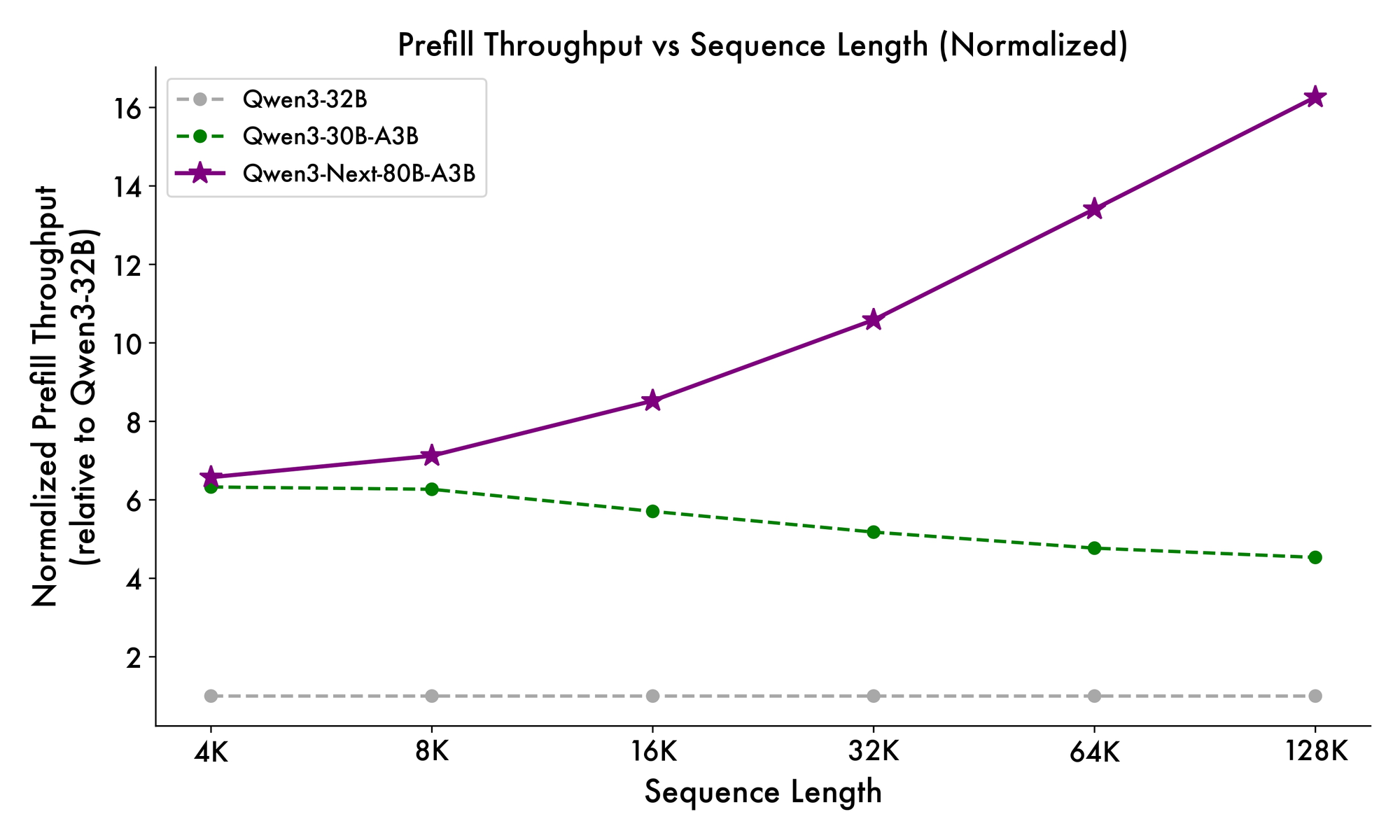
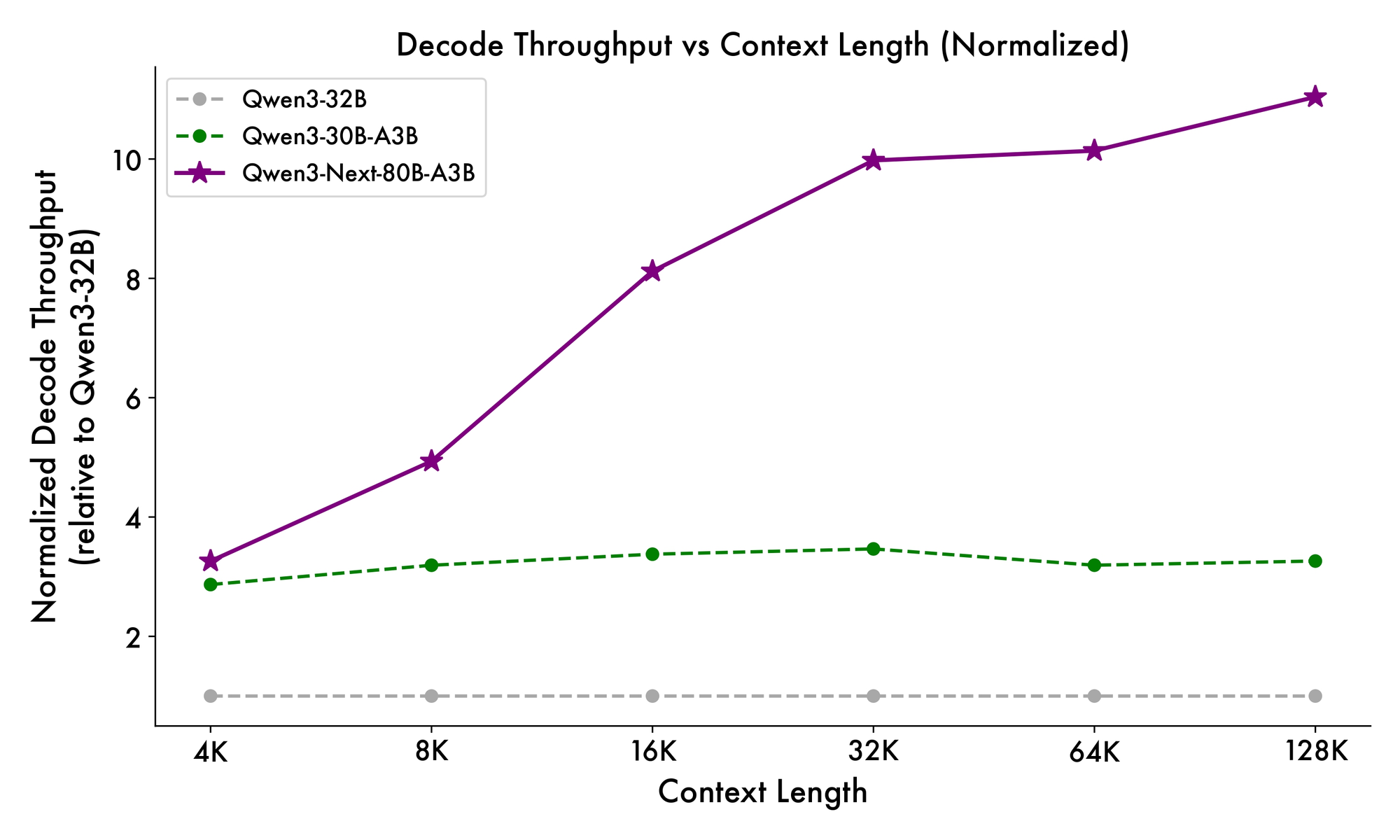
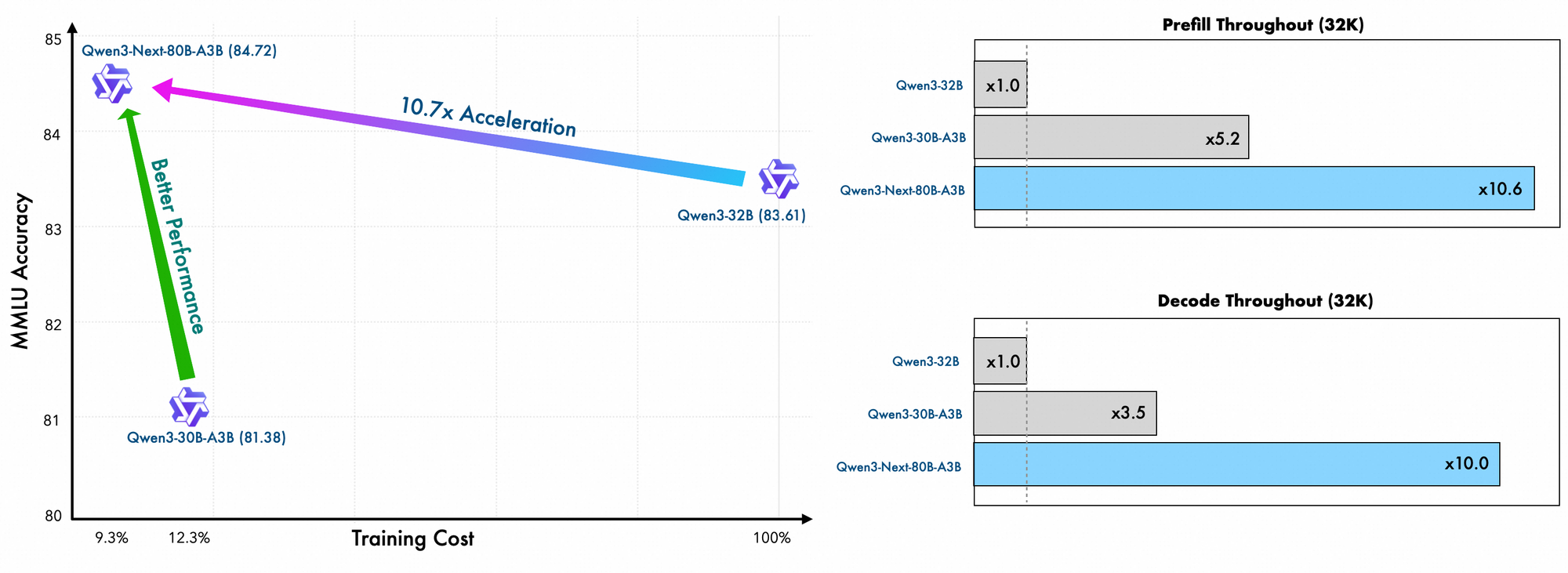
또한 전체 구조는 MoE에 공유 전문가를 통합하여 토큰 전반에 걸쳐 공통 패턴을 처리하고 중복성을 줄입니다. 투영에서 부분 로프 임베딩은 확장된 맥락에서 회전 불변성을 유지합니다. 벤치마크에서 입증된 바와 같이, 이 구성은 Qwen3-32B에 비해 4K 맥락 길이에서 거의 7배 더 높은 처리량을 제공합니다. 32K 토큰 이상에서는 속도가 10배를 초과하여 문서 분석 또는 코드 생성 작업에 적합합니다.
개발자는 미세 조정 시 이러한 모듈성으로부터 이점을 얻습니다. 전문가를 교체하거나 라우팅 임계값을 조정하여 금융 또는 의료와 같은 도메인에 맞게 모델을 전문화할 수 있습니다. 본질적으로 이 아키텍처는 계산을 최적화할 뿐만 아니라 적응성을 촉진합니다. 이러한 통찰력을 바탕으로 이제 이러한 요소가 측정 가능한 성능 향상으로 어떻게 이어지는지 살펴봅니다.
Qwen3-Next-80B-A3B 벤치마킹: 중요한 성능 지표
경험적 평가는 Qwen3-Next-80B-A3B를 효율성 중심 AI의 선두 주자로 자리매김합니다. MMLU 및 HumanEval과 같은 표준 벤치마크에서 기본 모델은 Qwen3-32B보다 활성 매개변수의 10분의 1만 사용함에도 불구하고 뛰어난 성능을 보입니다. 특히 일반 지식에 대한 MMLU에서 78.5%를 달성하여 추론 하위 집합에서 경쟁 모델보다 2-3점 앞섭니다.
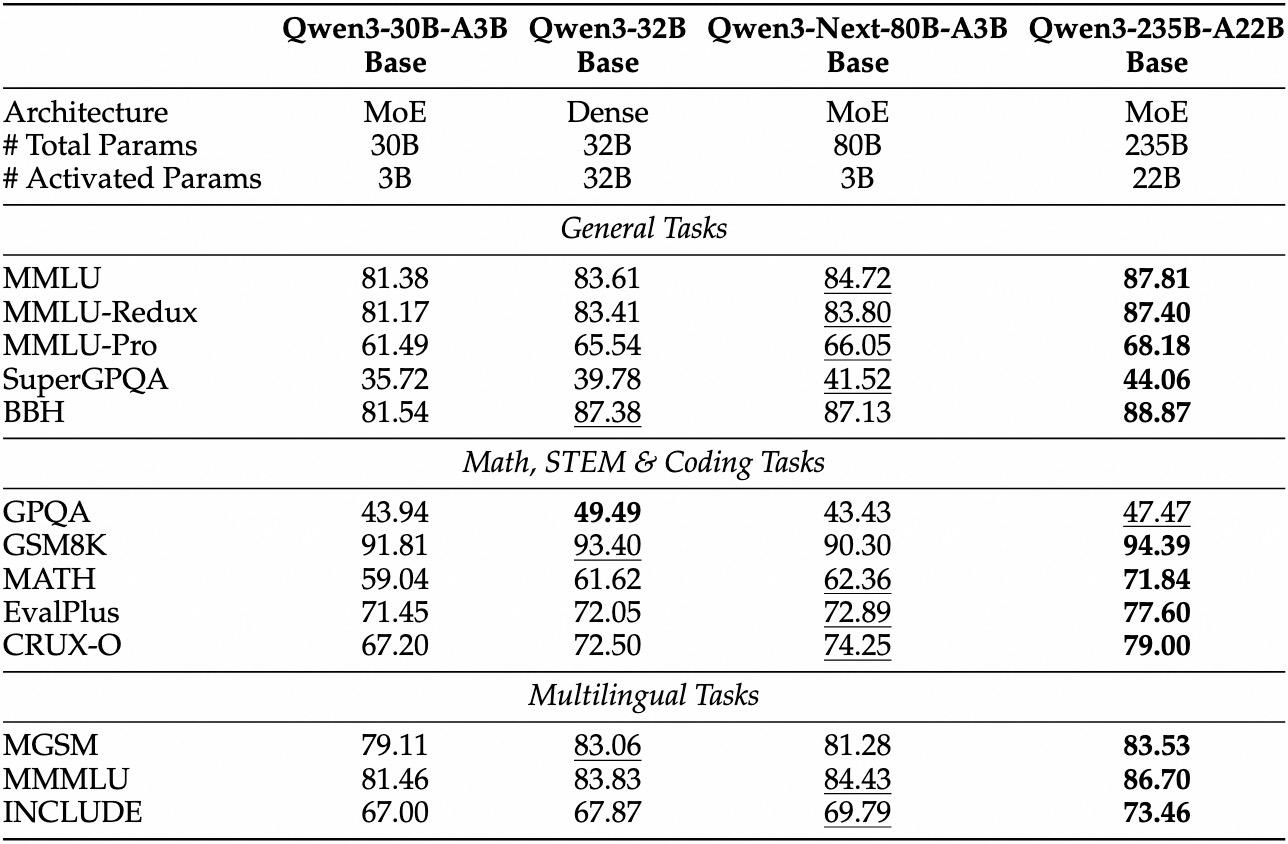
instruct 변형의 경우, 대화 작업에서 지시 따르기 능력이 강점으로 나타납니다. MT-Bench에서 85%를 기록하여 일관된 다중 턴 대화를 보여줍니다. 한편, thinking 모델은 사고 연쇄 시나리오에서 빛을 발하며 수학 문제에 대한 GSM8K에서 92%를 달성하여 Qwen3-30B-A3B-Thinking보다 4% 더 높은 성능을 보입니다.
추론 속도는 매력의 핵심입니다. 4K 맥락에서 디코딩 처리량은 Qwen3-32B의 4배에 달하며, 더 긴 길이에서는 10배까지 확장됩니다. 프롬프트 처리에 중요한 사전 채우기 단계는 희소 MoE 덕분에 7배 향상된 성능을 보여줍니다. 전력 소비도 그에 따라 감소하며, 훈련 비용은 더 밀집된 모델의 10% 수준입니다.
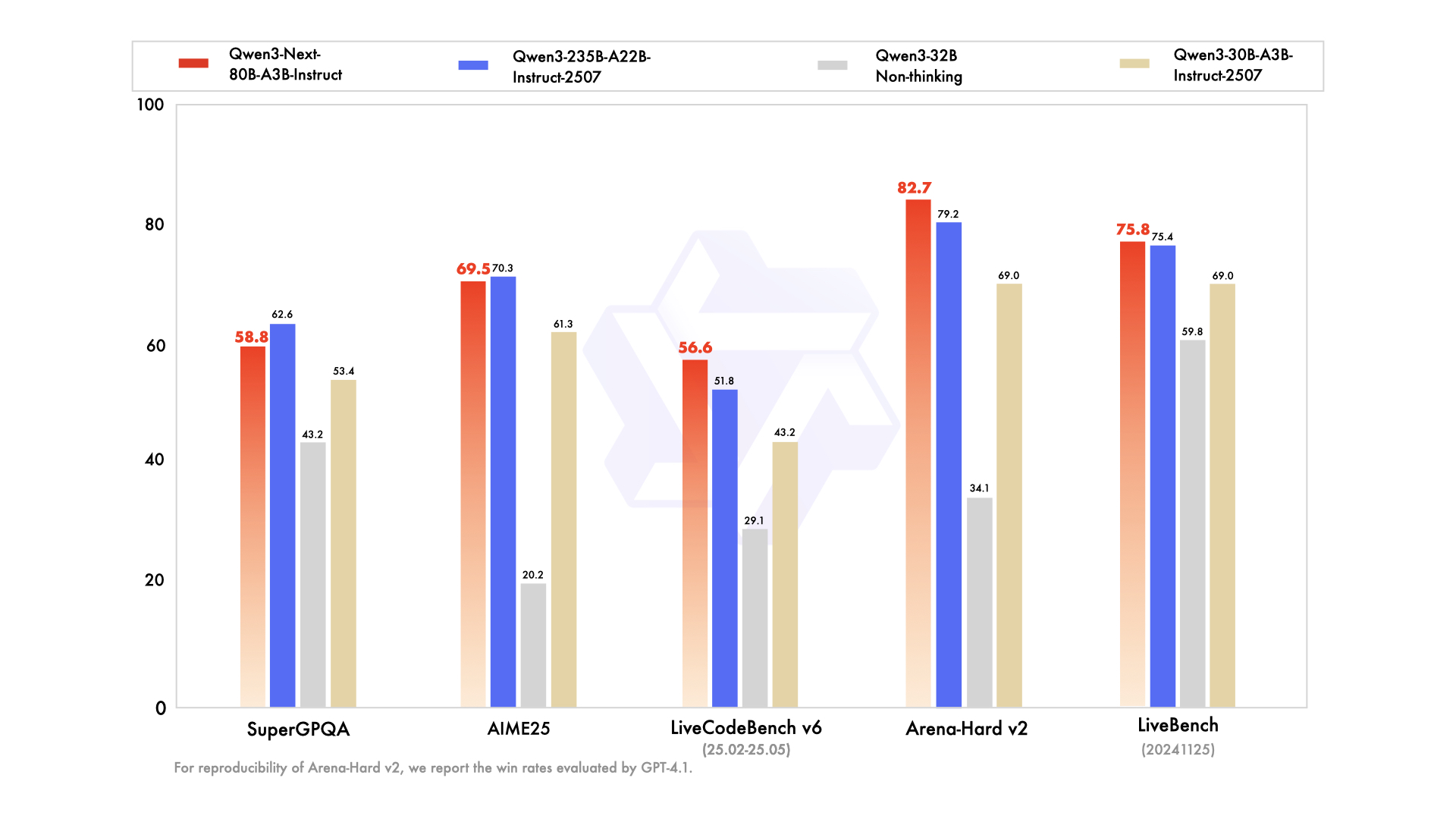
경쟁 모델과의 비교는 그 우위를 강조합니다. Llama 3.1-70B에 비해 Qwen3-Next-80B-A3B-Thinking은 RULER(장문 맥락 회상)에서 15% 앞서며, 128K 토큰의 세부 정보를 정확하게 회상합니다. DeepSeek-V2에 비해서는 속도 저하 없이 더 나은 다국어 지원을 제공합니다.

| 벤치마크 | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruct) | 81.9% | 83.5% |
이 표는 일관된 우수성을 강조합니다. 결과적으로 조직은 품질과 비용의 균형을 맞추기 위해 이를 생산에 채택합니다. 이론에서 실천으로 전환하여 이제 API 액세스 도구를 갖추게 됩니다.
Qwen3-Next-80B-A3B API 액세스 설정: 전제 조건 및 인증
Alibaba는 클라우드 플랫폼인 DashScope를 통해 Qwen API를 제공하여 원활한 통합을 보장합니다. 먼저 Alibaba Cloud 계정을 생성하고 Model Studio 콘솔로 이동합니다. 모델 목록에서 Qwen3-Next-80B-A3B를 선택합니다. 이 모델은 기본, instruct, thinking 모드로 제공됩니다.
대시보드의 "API 키"에서 API 키를 얻습니다. 이 키는 요청을 인증하며, 요금 제한은 계층에 따라 다릅니다(무료 계층은 월 1M 토큰 제공). OpenAI 호환 호출의 경우 기본 URL을 https://dashscope.aliyuncs.com/compatible-mode/v1로 설정합니다. 기본 DashScope 엔드포인트는 https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation을 사용합니다.
pip를 통해 Python SDK를 설치합니다: pip install dashscope. 이 라이브러리는 직렬화, 재시도 및 오류 구문 분석을 처리합니다. 또는 사용자 지정 구현을 위해 requests와 같은 HTTP 클라이언트를 사용할 수 있습니다.
보안 모범 사례에 따라 환경 변수에 키를 저장합니다: export DASHSCOPE_API_KEY='your_key_here'. 결과적으로 코드는 환경 전반에 걸쳐 이식성을 유지합니다. 설정이 완료되면 첫 번째 API 호출을 작성합니다.
실습 가이드: Python 및 DashScope로 Qwen3-Next-80B-A3B API 사용
DashScope는 Qwen3-Next-80B-A3B와의 상호 작용을 단순화합니다. 챗봇과 유사한 응답을 위해 instruct 변형을 사용하여 기본적인 생성 요청으로 시작합니다.
다음은 시작 스크립트입니다.
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
이 코드는 프롬프트를 보내고 최대 200개의 토큰을 검색합니다. 모델은 효율성 향상을 강조하는 간결한 설명을 제공합니다. thinking 모드의 경우 'qwen3-next-80b-a3b-thinking'으로 전환하고 추론 지침을 추가합니다: "답변하기 전에 단계별로 생각하세요."
고급 매개변수는 제어를 향상시킵니다. 핵 샘플링을 위해 top_p=0.9를 설정하거나 루프를 피하기 위해 repetition_penalty=1.1을 설정합니다. 긴 맥락의 경우 모델의 128K 기능을 활용하기 위해 max_context_length=131072를 지정합니다.
실시간 앱을 위한 스트리밍 처리:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
이는 UI 통합에 이상적인 토큰별 출력을 제공합니다. 오류 처리는 할당량 문제(예: 잔액 부족에 대한 10402)에 대해 response.code를 확인하는 것을 포함합니다.
또한 함수 호출은 유용성을 확장합니다. JSON 스키마에 도구를 정의합니다.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
모델은 의도를 구문 분석하고 도구 호출을 반환하며, 이를 외부에서 실행합니다. 이 패턴은 에이전트 워크플로우를 강화합니다. 이러한 예시를 통해 강력한 파이프라인을 구축할 수 있습니다. 다음으로, 매번 코딩하지 않고 이러한 호출을 테스트하고 개선하기 위해 Apidog를 통합합니다.
워크플로우 향상: Qwen3-Next-80B-A3B API 테스트를 위한 Apidog 통합
Apidog는 API 개발을 간소화된 프로세스로 전환하며, 특히 Qwen3-Next-80B-A3B와 같은 AI 엔드포인트에 유용합니다. 이 플랫폼은 AI를 통한 지능형 자동화를 기반으로 설계, 모킹, 테스트 및 문서화를 하나의 인터페이스에 결합합니다.
먼저 DashScope 스키마를 Apidog로 가져옵니다. 새 프로젝트를 생성하고 엔드포인트 POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation을 추가한 다음 API 키를 헤더 X-DashScope-API-Key: your_key로 붙여넣습니다.
요청을 시각적으로 설계합니다. 모델 매개변수를 'qwen3-next-80b-a3b-instruct'로 설정하고, 본문에 JSON 형식으로 프롬프트를 입력합니다 {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}}. Apidog의 AI는 테스트 사례를 제안하며, 엣지 케이스 프롬프트 또는 고온 샘플과 같은 변형을 생성합니다.
일련의 테스트를 순차적으로 실행합니다. 예를 들어, 온도에 따른 지연 시간을 벤치마킹합니다.
- 테스트 1: 온도 0.1, 프롬프트 길이 100 토큰.
- 테스트 2: 온도 1.0, 맥락 10K 토큰.
이 도구는 응답 시간, 토큰 사용량, 오류율과 같은 지표를 추적하고 대시보드에서 추세를 시각화합니다. 오프라인 개발을 위한 모의 응답: Apidog는 기록 데이터를 기반으로 Qwen 출력을 시뮬레이션하여 프론트엔드 빌드를 가속화합니다.
문서화는 컬렉션에서 자동으로 생성됩니다. MoE 라우팅 노트와 같은 Qwen3-Next-80B-A3B 세부 사항을 포함하여 예시와 함께 OpenAPI 사양을 내보냅니다. 협업 기능을 통해 팀은 환경을 공유하여 일관된 테스트를 보장할 수 있습니다.
한 시나리오에서 개발자는 다국어 프롬프트를 테스트합니다. Apidog의 AI는 불일치를 감지하고 언어 힌트 추가와 같은 수정 사항을 제안합니다. 그 결과 사용자 보고서에 따르면 통합 시간이 40% 단축됩니다. AI 특정 테스트의 경우 지능형 데이터 생성을 활용합니다. 스키마를 입력하면 프로덕션 트래픽을 모방하는 현실적인 프롬프트를 생성합니다.
또한 Apidog는 CI/CD 훅을 지원하여 파이프라인에서 API 테스트를 실행합니다. 배포 후 자동화된 유효성 검사를 위해 GitHub Actions에 연결합니다. 이 폐쇄 루프 접근 방식은 Qwen 기반 앱의 버그를 최소화합니다.
고급 전략: 프로덕션을 위한 Qwen3-Next-80B-A3B API 호출 최적화
최적화는 기본 사용을 엔터프라이즈급 안정성으로 끌어올립니다. 먼저, 가능한 경우 요청을 일괄 처리합니다. DashScope는 호출당 최대 10개의 프롬프트를 지원하여 요약 팜과 같은 병렬 작업의 오버헤드를 줄입니다.
토큰 경제학을 모니터링합니다. 모델은 활성 매개변수당 요금을 부과하므로 간결한 프롬프트는 비용 절감 효과를 가져옵니다. 구조화된 출력을 위해 API의 result_format='message'를 사용하여 후처리 없이 JSON을 직접 구문 분석합니다.
고가용성을 위해 지수 백오프를 사용하여 재시도를 구현합니다.
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
이는 429 속도 제한과 같은 일시적인 오류를 처리합니다. DashScope는 싱가포르 및 미국 엔드포인트를 제공하므로 지역에 걸쳐 호출을 분산하여 수평적으로 확장합니다.
보안 고려 사항에는 프롬프트 주입을 방지하기 위한 입력 정화가 포함됩니다. API로 전달하기 전에 화이트리스트에 대해 사용자 입력을 검증합니다. 또한 GDPR을 준수하여 감사 목적으로 익명화된 응답을 로깅합니다.
초장문 맥락과 같은 엣지 케이스에서는 입력을 청크로 나누고 예측을 연결합니다. thinking 변형이 여기에 도움이 됩니다. "1단계: 섹션 A 분석; 2단계: B와 통합"과 같은 프롬프트를 사용합니다. 이는 10만 개 이상의 토큰에 걸쳐 일관성을 유지합니다.
개발자는 Alibaba 플랫폼을 통해 미세 조정을 탐색하기도 하지만, API 사용자는 프롬프트 엔지니어링을 고수합니다. 결과적으로 이러한 전술은 확장 가능하고 안전한 배포를 보장합니다.
마무리: Qwen3-Next-80B-A3B가 주목할 가치가 있는 이유
Qwen3-Next-80B-A3B는 희소 MoE, 하이브리드 게이트 및 뛰어난 벤치마크를 통해 효율적인 AI를 재정의합니다. 개발자는 DashScope를 통해 API를 활용하여 신속한 프로토타이핑을 수행하며, Apidog와 같은 도구를 통해 엄격한 테스트를 거쳐 향상된 기능을 제공합니다.
이제 아키텍처의 미묘한 차이부터 생산 최적화에 이르기까지 청사진을 손에 쥐었습니다. 이러한 통찰력을 구현하여 더 빠르고 스마트한 시스템을 구축하세요. 오늘 실험해 보세요. 확장 가능한 인텔리전스의 미래가 기다립니다.