
인공지능의 빠르게 진화하는 세계에서 Qwen 2.5 Omni 7B의 출시로 새로운 이정표에 도달했습니다. 이 알리바바 클라우드의 혁신적인 모델은 여러 형태의 입력을 처리하고 이해하는 능력을 결합하여 텍스트와 음성 출력을 생성하는 멀티모달 AI에서 중요한 도약을 나타냅니다. 이 모델이 무엇이 특별한지, 그리고 어떻게 AI의 능력에 대한 우리의 이해를 재편하고 있는지 자세히 알아보겠습니다.
Qwen 2.5 Omni 7B 내의 "Omni"의 진정한 의미
Qwen 2.5 Omni 7B에서 "Omni"라는 용어는 단순한 브랜딩이 아닌 모델의 능력에 대한 근본적인 설명입니다. 단일 또는 두 가지 데이터 유형에서 뛰어난 많은 멀티모달 모델들과 달리, Qwen 2.5 Omni 7B는 다양한 입력을 인식하고 이해하도록 설계되었습니다:
- 텍스트 (작성된 언어)
- 이미지 (시각 정보)
- 오디오 (소리 및 구어)
- 비디오 (시간적 차원을 가진 움직이는 시각 콘텐츠)
음성 채팅 + 비디오 채팅! Qwen Chat에서 바로 (https://t.co/FmQ0B9tiE7)! 이제 Qwen과 전화통화나 비디오 통화처럼 채팅할 수 있습니다! https://t.co/42iDe4j1Hs에서 데모를 확인하세요.
— Qwen (@Alibaba_Qwen) 2025년 3월 26일
게다가 모든 것을 가능하게 한 모델인 Qwen2.5-Omni-7B를 오픈소스합니다… pic.twitter.com/LHQOQrl9Ha
더욱 인상적인 것은 이 모델이 다양한 입력을 받을 수 있을 뿐만 아니라 텍스트와 자연스러운 음성 출력을 스트리밍 형식으로 응답할 수 있다는 점입니다. 이러한 "다대다" 기능은 보다 자연스럽고 인간 같은 AI 상호작용을 향한 중요한 발전을 나타냅니다.
Qwen 2.5 Omni 7B의 혁신적인 아키텍처: 설명
사고하는 사람-말하는 사람: 새로운 패러다임
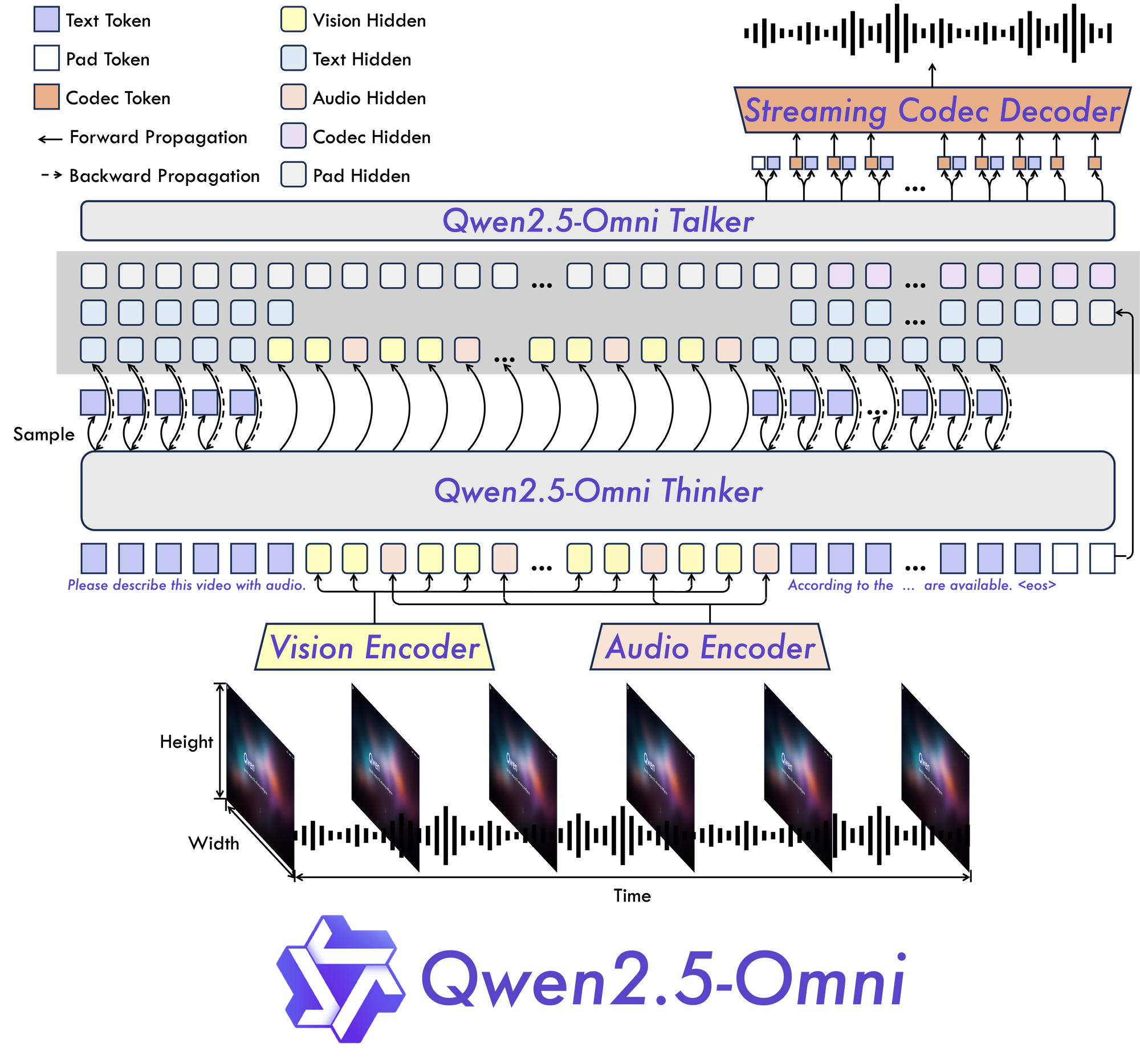
Qwen 2.5 Omni 7B의 핵심에는 기본적인 "사고하는 사람-말하는 사람" 아키텍처가 있습니다. 이 혁신적인 설계는 정보의 다양한 유형 간에 원활한 처리를 가능하게 하는 엔드 투 엔드 멀티모달 모델을 특별히 구축합니다.
이 이름에서 알 수 있듯이, 이 아키텍처는 정보의 인지 처리(사고)와 출력 생성(말하기)을 분리합니다. 이러한 분리는 모델이 멀티모달 데이터의 내재된 복잡성을 효과적으로 관리하고 여러 형식으로 적절한 응답을 생성할 수 있도록 합니다.
TMRoPE: 시간 정렬 문제 해결
Qwen 2.5 Omni 7B의 가장 중요한 혁신 중 하나는 시간 정렬 멀티모달 RoPE(TMRoPE) 메커니즘입니다. 이 돌파구는 멀티모달 AI의 가장 까다로운 측면 중 하나인 다양한 출처의 시간 데이터를 동기화하는 것을 다룹니다.
비디오와 오디오를 동시에 처리할 때, 모델은 시각적 사건이 해당 소리나 언어와 어떻게 정렬되는지를 이해해야 합니다. 예를 들어, 사람의 입술 움직임과 그들이 말하는 단어를 일치시키려면 정확한 시간 정렬이 필요합니다. TMRoPE는 이러한 동기화를 달성하기 위한 정교한 프레임워크를 제공하여 모델이 시간에 따라 전개되는 멀티모달 입력에 대한 일관된 이해를 구축할 수 있도록 합니다.
실시간 상호작용을 위해 설계됨
Qwen 2.5 Omni 7B는 실시간 애플리케이션을 염두에 두고 구축되었습니다. 이 아키텍처는 지연이 낮은 스트리밍을 지원하여 청크 입력 처리를 가능하게 하고 즉각적인 출력 생성을 제공합니다. 이로 인해 음성 비서, 라이브 비디오 분석 또는 실시간 번역 서비스와 같이 반응성 상호작용이 필요한 애플리케이션에 이상적입니다.
Qwen 2.5 Omni 7B 성능: 벤치마크가 스스로 말합니다
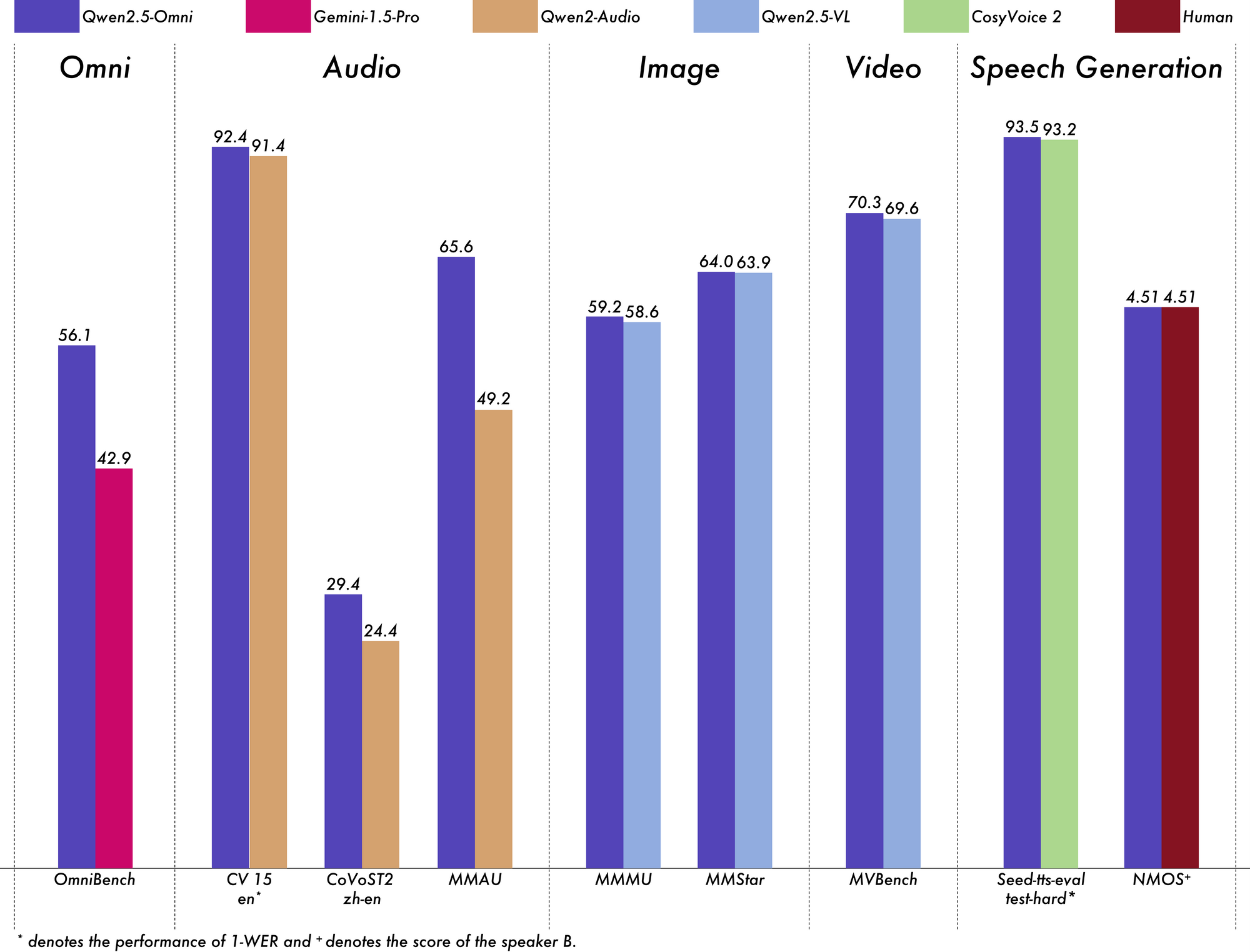
모든 AI 모델의 진정한 테스트는 엄격한 벤치마크에서의 성능이며, Qwen 2.5 Omni 7B는 모든 분야에서 인상적인 결과를 제공합니다.
멀티모달 이해에서의 선두주자
일반 멀티모달 이해를 위한 OmniBench 벤치마크에서 Qwen 2.5 Omni 7B는 평균 점수 56.13%를 기록합니다. 이는 Gemini-1.5-Pro(42.91%)와 MIO-Instruct(33.80%)와 같은 다른 모델들보다 훨씬 뛰어납니다. 특정 OmniBench 카테고리에서의 뛰어난 성능도 주목할 만합니다:
- 음성 작업: 55.25%
- 소리 사건 작업: 60.00%
- 음악 작업: 52.83%
이 포괄적인 성능은 모델이 여러 모달리티를 효과적으로 통합하고 추론할 수 있는 능력을 보여줍니다.
오디오 처리에서 뛰어남
오디오-텍스트 작업에서 Qwen 2.5 Omni 7B는 자동 음성 인식(ASR)에서 거의 최첨단 결과를 보여줍니다. Librispeech 데이터셋에서 단어 오류율(WER)은 1.6%에서 3.5%까지로, Whisper-large-v3와 같은 특화된 모델과 비교할 수 있습니다.
Meld 데이터셋의 소리 사건 인식에서 0.570의 점수로 최고의 성능을 보여주며, 음악 이해에서도 GiantSteps Tempo 벤치마크에서 0.88을 기록하며 우수한 성과를 보입니다.
강력한 이미지 이해
이미지-텍스트 작업에서 Qwen 2.5 Omni 7B는 MMMU 벤치마크에서 59.2의 점수를 기록하며, 이는 GPT-4o-mini의 60.0에 근접합니다. RefCOCO 바인딩 작업에서는 90.5%의 정확도로 Gemini 1.5 Pro의 73.2%를 초과합니다.
인상적인 비디오 이해
자막이 없는 비디오-텍스트 작업에서 이 모델은 Video-MME에서 64.3의 점수를 기록하여 특화된 비디오 모델과 거의 동등한 성능을 보입니다. 자막이 추가되면 성능이 72.4로 증가하여 여러 정보 소스를 효과적으로 통합할 수 있는 능력을 보여줍니다.
자연스러운 음성 생성
Qwen 2.5 Omni 7B는 단순히 이해하는 것에 그치지 않고 말을 합니다. 음성 생성에서 스피커 유사도 점수는 0.754에서 0.752에 이르며, Seed-TTS_RL과 같은 전용 텍스트-음성 변환 모델과 비교할 수 있습니다. 이는 자연스럽고 개별 스피커의 목소리 특성을 유지하는 음성을 생성하는 능력을 보여줍니다.
강력한 텍스트 능력 유지
멀티모달에 초점을 맞추고 있음에도 불구하고 Qwen 2.5 Omni 7B는 텍스트 전용 작업에서도 뛰어난 성과를 보입니다. 수학적 추론(GSM8K 점수: 88.7%) 및 코드 생성을 통해 강력한 결과를 달성합니다. 텍스트 전용 Qwen2.5-7B 모델(93.6%의 GSM8K 점수)과 비교할 때 약간의 타협이 있지만, 포괄적인 멀티모달 능력을 위해서라면 이러한 약간의 저하는 합리적인 거래입니다.
Qwen 2.5 Omni 7B의 실제 응용 프로그램:
Qwen 2.5 Omni는 미쳤어요!
— Jeff Boudier 🤗 (@jeffboudier) 2025년 3월 26일
7B 모델이
텍스트, 이미지, 오디오, 비디오를 입력으로 받고
텍스트와 오디오를 출력으로 주며
이렇게 잘 작동할 수 있다는 게 믿기지 않아요!
오픈 소스 Apache 2.0
아래 링크를 통해 사용해 보세요!
정말 잘 하셨어요 @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
Qwen 2.5 Omni 7B의 다재다능함은 다양한 분야에서 실용적인 응용 프로그램의 폭을 넓혀줍니다.
향상된 커뮤니케이션 인터페이스
지연이 낮은 스트리밍 기능으로 인해 실시간 음성 및 비디오 채팅 애플리케이션에 이상적입니다. 가상 비서가 시각적으로 인식하고, 듣고, 자연스럽게 말할 수 있으며, 언어 및 비언어적 커뮤니케이션 신호를 이해하고 자연스러운 음성으로 응답할 수 있도록 상상해 보세요.
고급 콘텐츠 분석
모델의 다양한 모달리티를 처리하고 이해하는 능력은 포괄적인 콘텐츠 분석을 위한 강력한 도구로 자리 잡습니다. 텍스트, 이미지, 오디오 및 비디오에서 동시에 주요 정보를 자동으로 식별하여 멀티미디어 문서에서 통찰력을 추출할 수 있습니다.
접근 가능한 음성 인터페이스
완전한 음성 명령 수행에서 강력한 성능을 통해 Qwen 2.5 Omni 7B는 보다 자연스럽고 진정으로 핸즈프리 상호작용이 가능합니다. 이는 장애가 있는 사용자나 핸즈프리 작동이 필수적인 상황에서 접근성 기능을 혁신할 수 있습니다.
창의적인 콘텐츠 생성
텍스트와 자연스러운 음성을 모두 생성할 수 있는 이 모델은 콘텐츠 생성에 대한 새로운 가능성을 열어줍니다. 비디오용 내레이션을 자동으로 생성하는 것부터 학생의 질문에 적절한 설명으로 응답하는 대화형 교육 자료를 생성하는 데 이르기까지, 그 응용은 무궁무진합니다.
멀티모달 고객 서비스
기업들은 Qwen 2.5 Omni 7B를 활용하여 음성 통화, 비디오 채팅, 서면 메시지 등 다양한 채널에서 고객 쿼리를 분석하고 각 요청에 자연스럽고 적절하게 응답하는 고객 서비스 시스템을 배포할 수 있습니다.
실용적인 고려 사항 및 한계
Qwen 2.5 Omni 7B는 멀티모달 AI의 중요한 발전을 나타내지만, 작업할 때 염두에 두어야 할 몇 가지 실용적인 고려사항이 있습니다.
하드웨어 요구 사항
모델의 포괄적인 능력은 상당한 계산 요구 사항을 동반합니다. FP32 정밀도로 상대적으로 짧은 15초 비디오를 처리하려면 약 93.56GB의 GPU 메모리가 필요합니다. BF16 정밀도로도 60초 비디오를 처리하려면 여전히 약 60.19GB가 필요합니다.
이러한 요구 사항은 고급 하드웨어에 접근할 수 없는 사용자에게 접근성을 제한할 수 있습니다. 그러나 이 모델은 호환되는 하드웨어에서 성능을 개선하는 데 도움이 되는 Flash Attention 2와 같은 다양한 최적화를 지원합니다.
음성 유형 사용자 정의
흥미롭게도 Qwen 2.5 Omni 7B는 오디오 출력에 대해 여러 음성 유형을 지원합니다. 현재 두 가지 음성 옵션을 제공합니다:
- 첼시: "꿀처럼 부드럽고, 부드러운 따뜻함과 빛나는 선명함"을 가진 여성 목소리
- 이든: "밝고, 경쾌"하며 "감염성 에너지와 따뜻하고 다가가기 쉬운 분위기"를 가진 남성 목소리
이 사용자 정의는 모델의 실용적인 응용 프로그램에서의 유연성에 또 다른 차원을 추가합니다.
기술적 통합 고려 사항
Qwen 2.5 Omni 7B를 구현할 때 주의해야 할 몇 가지 기술 세부 사항이 있습니다:
- 모델은 오디오 출력을 위해 특정 프롬프트 패턴이 필요합니다.
- 올바른 다중 라운드 대화를 위해
use_audio_in_video매개변수의 일관된 설정이 필요합니다. - 비디오 URL 호환성은 특정 라이브러리 버전(HTTPS 지원을 위한 torchvision ≥ 0.19.0)에 따라 달라집니다.
- 모델은 현재 "다대다" 모델을 지원하는 제한으로 인해 Hugging Face Inference API를 통해 사용할 수 없습니다.
멀티모달 AI의 미래
Qwen 2.5 Omni 7B는 단순한 AI 모델 이상의 의미를 갖습니다. 여러 감각 모달리티를 통합된 엔드 투 엔드 아키텍처로 결합함으로써, 인간과 유사하게 세상을 인식하고 상호작용할 수 있는 AI 시스템에 한 걸음 더 다가가고 있습니다.
시간 정렬을 위한 TMRoPE 통합은 멀티모달 처리의 근본적인 도전을 해결하고, 사고하는 사람-말하는 사람 아키텍처는 다양한 입력을 효과적으로 결합하고 적절한 출력을 생성하기 위한 프레임워크를 제공합니다. 벤치마크 전반에서의 강력한 성능은 통합된 멀티모달 모델이 특화된 단일 모달리티 모델과 경쟁할 수 있으며 때로는 그것을 초월할 수 있음을 보여줍니다.
계산 자원이 보다 접근 가능해지고 효율적인 모델 배포 기술이 개선됨에 따라, Qwen 2.5 Omni 7B와 같은 진정한 멀티모달 AI의 보편적인 사용이 더욱 보편화될 것으로 기대됩니다. 이 기술은 의료, 교육, 엔터테인먼트 및 고객 서비스와 같은 거의 모든 산업에 걸쳐 응용될 것입니다.
결론
Qwen 2.5 Omni 7B는 멀티모달 AI의 진화에서 놀라운 성과로 자리 잡습니다. 그 포괄적인 "Omni" 능력, 혁신적인 아키텍처 및 인상적인 교차 모달 성능은 다음 세대의 인공지능 시스템의 선도적인 예로 자리매김하게 합니다.
시각적, 청각적, 텍스트 및 음성을 한 원 모델로 결합함으로써, Qwen 2.5 Omni 7B는 다양한 AI 기능 간의 전통적인 경계를 허물고 있습니다. 이는 인간과 AI가 보다 자연스럽고 직관적인 방식으로 상호작용할 수 있는 AI 시스템을 만드는 데 중요한 진전을 나타냅니다.
실용적인 한계가 있지만, 특히 하드웨어 요구 사항에 관한 부분, 모델의 성과는 AI가 우리가 살고 있는 풍부한 멀티모달 세상을 원활하게 처리하고 응답할 수 있는 흥미로운 미래를 가리킵니다. 이러한 기술이 계속 발전하고 보다 접근 가능해짐에 따라, 우리는 수많은 응용 프로그램과 분야에서 기술과 상호작용하는 방식을 변화시킬 것으로 예상됩니다.
Qwen 2.5 Omni 7B는 기술적 성과에 불과하지 않습니다. 이는 다양한 형태의 커뮤니케이션 간의 경계가 허물어지는 미래를 보여줍니다. 인간과 AI가 상호작용하는 더 자연스럽고 직관적인 방법을 창출하는 길로 향하는 방향입니다.