
환영합니다! 최첨단 AI 도구를 활용하여 웹 스크래핑 및 콘텐츠 분석을 수행하는 방법에 대해 궁금해한 적이 있다면, 당신은 올바른 곳에 있습니다. 오늘은 OpenAI SWARM, Streamlit, 그리고 다중 에이전트 시스템을 결합하여 웹 스크래핑을 보다 똑똑하게 만들고 콘텐츠 분석을 더욱 통찰력 있게 하는 흥미로운 프로젝트를 깊이 있게 탐구할 것입니다. 또한 Apidog가 API 테스트를 간소화하고 API 요구 사항에 대한 보다 저렴한 대안으로 작용할 수 있는 방법을 살펴보겠습니다.
이제 완전한 기능을 갖춘 웹 스크래핑 및 콘텐츠 분석 시스템 구축을 시작해 봅시다!
1. OpenAI SWARM이란?
OpenAI SWARM은 다양한 작업, 특히 웹 스크래핑 및 콘텐츠 분석을 자동화하기 위해 AI와 다중 에이전트 시스템을 활용하는 새로운 접근 방식입니다. SWARM의 핵심은 특정 작업에서 협력하거나 독립적으로 작업할 수 있는 여러 에이전트를 사용하는 데 있습니다.

SWARM의 작동 방식
여러 웹사이트에서 데이터 수집을 위해 스크래핑하고 싶다고 상상해 보십시오. 단일 스크래퍼 봇을 사용하는 것도 가능하지만, 병목 현상이나 오류가 발생하거나 웹사이트에 의해 차단될 위험이 있습니다. 그러나 SWARM를 사용하면 작업의 다양한 측면을 처리하기 위해 여러 에이전트를 배포할 수 있습니다. 일부 에이전트는 데이터 추출에 집중하고, 다른 에이전트는 데이터 정리에, 또 다른 에이전트는 분석을 위한 데이터 변환을 처리합니다. 이 에이전트들은 서로 소통하여 작업을 효율적으로 처리할 수 있게 합니다.
OpenAI의 강력한 언어 모델과 SWARM 방법론을 결합함으로써 인간의 문제 해결을 모방하는 스마트하고 적응력 있는 시스템을 구축할 수 있습니다. 이번 자습서에서는 더 똑똑한 웹 스크래핑과 데이터 처리를 위해 SWARM 기술을 사용할 것입니다.
2. 다중 에이전트 시스템 소개
다중 에이전트 시스템 (MAS)은 복잡한 문제를 해결하기 위해 공유된 환경 내에서 상호작용 하는 자율 에이전트들의 집합입니다. 에이전트들은 작업을 병렬로 수행할 수 있어, 다양한 출처에서 데이터를 수집해야 하거나 다른 처리 단계가 필요한 상황에서 MAS가 이상적입니다.
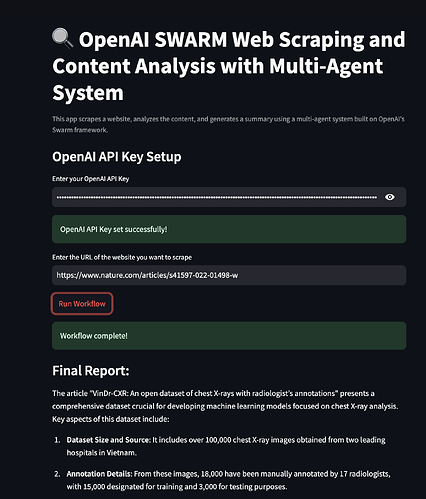
웹 스크래핑의 맥락에서 다중 에이전트 시스템은 다음과 같은 에이전트를 포함할 수 있습니다:
- 데이터 추출: 관련 데이터를 수집하기 위해 다양한 웹 페이지를 크롤링합니다.
- 콘텐츠 파싱: 데이터를 분석을 위해 정리하고 조직합니다.
- 데이터 분석: 수집된 데이터에서 인사이트를 도출하기 위해 알고리즘을 적용합니다.
- 보고: 결과를 사용자에게 친숙한 형식으로 제공합니다.
웹 스크래핑에 다중 에이전트 시스템을 사용하는 이유는 무엇인가요?
다중 에이전트 시스템은 실패에 강하며 비동기식으로 작동할 수 있습니다. 이는 하나의 에이전트가 실패하거나 문제가 발생하더라도 나머지 에이전트는 계속 작업을 수행할 수 있음을 의미합니다. 따라서 SWARM 접근 방식은 웹 스크래핑 프로젝트에서 더 높은 효율성, 확장성, 그리고 장애 허용성을 보장합니다.
3. Streamlit: 개요
Streamlit 은 데이터 분석, 머신 러닝 및 자동화 프로젝트를 위한 사용자 정의 웹 애플리케이션을 쉽게 만들고 공유할 수 있도록 하는 인기 있는 오픈 소스 Python 라이브러리입니다. Intercative 사용자 인터페이스를 만들 수 있는 프레임워크를 제공합니다.
Streamlit을 사용하는 이유는 무엇인가요?
- 사용 편리성: Python 코드를 작성하면 Streamlit이 이를 사용자 친화적인 웹 인터페이스로 변환합니다.
- 신속한 프로토타입 제작: 새로운 아이디어를 빠르게 테스트하고 배포할 수 있습니다.
- AI 모델과의 통합: 머신 러닝 라이브러리 및 API와 원활하게 통합됩니다.
- 사용자 정의: 다양한 사용 사례에 대해 복잡한 앱을 구축할 만큼 유연합니다.
우리 프로젝트에서 Streamlit을 사용하여 웹 스크래핑 결과를 시각화하고 콘텐츠 분석 메트릭을 표시하며 다중 에이전트 시스템을 제어하기 위한 인터랙티브한 인터페이스를 생성할 것입니다.
4. Apidog가 게임 체인저인 이유
Apidog 은 전통적인 API 개발 및 테스트 도구에 대한 강력한 대안입니다. 디자인에서 테스트 및 배포에 이르기까지 API 생명 주기 전체를 지원하며, 모두 하나의 통합 플랫폼 내에서 가능합니다.
Apidog의 주요 기능:
- 사용자 친화적인 인터페이스: 사용하기 쉬운 드래그 앤 드롭 API 디자인.
- 자동화된 테스트: 추가 스크립트 없이 포괄적인 API 테스트를 수행합니다.
- 내장 문서: 상세한 API 문서를 자동으로 생성합니다.
- 더 저렴한 가격 계획: 경쟁업체에 비해 저렴한 옵션을 제공합니다.
Apidog는 API 통합 및 테스트가 중요한 프로젝트에 적합하여 비용 효과적이고 포괄적인 솔루션을 제공합니다.
Apidog를 무료로 다운로드하여 이러한 이점을 직접 경험해 보십시오.
5. 개발 환경 설정하기
코드에 들어가기 전에 환경이 준비되어 있는지 확인합시다. 필요한 사항은 다음과 같습니다:
- Python 3.7+
- Streamlit:
pip install streamlit를 통해 설치합니다. - BeautifulSoup: 웹 스크래핑을 위해
pip install beautifulsoup4를 통해 설치합니다. - Requests:
pip install requests를 통해 설치합니다. - Apidog: API 테스트를 위해 Apidog의 공식 웹사이트에서 다운로드할 수 있습니다.
위 사항이 모두 설치되었는지 확인하십시오. 이제 환경을 구성합시다.
6. 웹 스크래핑을 위한 다중 에이전트 시스템 구축
OpenAI SWARM과 Python 라이브러리를 사용하여 웹 스크래핑을 위한 다중 에이전트 시스템을 구축해 보겠습니다. 여기서의 목표는 여러 웹사이트에서 데이터 수집, 파싱 및 분석과 같은 작업을 수행하기 위한 여러 에이전트를 만드는 것입니다.
1단계: 에이전트 정의
다양한 작업을 위한 에이전트를 생성합니다:
- 크롤러 에이전트: 웹 페이지에서 원시 HTML을 수집합니다.
- 파서 에이전트: 의미 있는 정보를 추출합니다.
- 분석 에이전트: 인사이트를 도출하기 위해 데이터를 처리합니다.
여기에서 Python으로 간단한 CrawlerAgent를 정의하는 방법은 다음과 같습니다:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"{self.url}에서 콘텐츠를 가져오는 데 실패했습니다.")
except Exception as e:
print(f"오류: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
2단계: 파서 에이전트 추가
ParserAgent는 원시 HTML을 정리하고 구조화합니다:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # 예: 모든 단락 추출
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
3단계: 분석 에이전트 추가
이 에이전트는 자연어 처리(NLP) 기술을 적용하여 콘텐츠를 분석합니다.
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # 예: 가장 일반적으로 사용되는 10개 단어
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. SWARM 및 Streamlit을 이용한 콘텐츠 분석
이제 에이전트들이 함께 작업하고 있으므로, Streamlit을 사용하여 결과를 시각화해 보겠습니다.
1단계: Streamlit 앱 만들기
Streamlit을 가져오고 기본 앱 구조를 설정하는 것으로 시작하세요:
import streamlit as st
st.title("다중 에이전트 시스템을 활용한 웹 스크래핑 및 콘텐츠 분석")
st.write("더 똑똑한 데이터 추출을 위해 OpenAI SWARM 및 Streamlit 사용.")
2단계: 에이전트 통합
사용자가 URL을 입력하고 스크래핑 및 분석 결과를 확인할 수 있도록 에이전트를 Streamlit 앱에 통합합니다.
url = st.text_input("스크래핑할 URL을 입력하세요:")
if st.button("스크래핑 및 분석"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("가장 일반적으로 사용되는 10개 단어")
st.write(analysis_result)
else:
st.error("콘텐츠를 가져오지 못했습니다. 다른 URL을 시도해 보십시오.")
else:
st.warning("유효한 URL을 입력해 주세요.")
3단계: 앱 배포
다음 명령어를 사용하여 앱을 배포할 수 있습니다:
streamlit run your_script_name.py

8. Apidog를 사용한 API 테스트
이제 Apidog가 웹 스크래핑 애플리케이션에서 API 테스트에 어떻게 도움이 되는지 살펴보겠습니다.
1단계: Apidog 설정
Apidog의 공식 웹사이트에서 Apidog를 다운로드하여 설치합니다. 설치 가이드를 따라 환경을 설정합니다.
2단계: API 요청 생성
Apidog 내에서 직접 API 요청을 생성하고 테스트할 수 있습니다. GET, POST, PUT, DELETE와 같은 다양한 요청 유형을 지원하여 모든 웹 스크래핑 시나리오에서 다양하게 사용할 수 있습니다.
3단계: API 테스트 자동화
Apidog로 테스트 자동화 스크립트를 작성하여 외부 서비스에 연결할 때 다중 에이전트 시스템의 응답을 검증합니다. 이를 통해 시스템의 안정성과 일관성을 유지할 수 있습니다.
9. Streamlit 애플리케이션 배포하기
응용 프로그램이 완성되면 공용 액세스를 위해 배포하십시오. Streamlit은 Streamlit Sharing 서비스를 통해 이를 쉽게 만듭니다.
- 코드를 GitHub에 호스팅하십시오.
- Streamlit Sharing으로 이동하여 GitHub 리포지토리를 연결하십시오.
- 한 번의 클릭으로 앱을 배포하십시오.
10. 결론
축하합니다! 이제 OpenAI SWARM, Streamlit, 그리고 다중 에이전트 시스템을 사용하여 강력한 웹 스크래핑 및 콘텐츠 분석 시스템을 구축하는 방법을 배웠습니다. SWARM 기술이 스크래핑을 더 똑똑하게 만들고 콘텐츠 분석을 더 정확하게 수행할 수 있는 방법을 탐구했습니다. Apidog를 통합함으로써 API 테스트 및 검증에 대한 통찰력을 얻어 여러분의 시스템의 신뢰성을 확보할 수 있게 되었습니다.
이제 Apidog를 무료로 다운로드하여 강력한 API 테스트 기능으로 프로젝트를 더욱 향상시켜 보십시오. Apidog는 다른 솔루션에 비해 더 저렴하고 효율적인 대안으로 개발자에게 원활한 경험을 제공합니다.
이번 튜토리얼을 통해 복잡한 데이터 스크래핑 및 분석 작업을 더 효과적으로 수행할 준비가 되었습니다. 행운을 빕니다! 코딩을 즐기세요!


