
인공지능 환경은 메타의 Llama 4 출시로 근본적으로 변화했습니다. 이는 단순한 개선이 아니라 올해 건축 혁신으로, 업계의 성능 대비 비용 비율을 재정의합니다. 이러한 새로운 모델들은 원시 다중 모달리티를 통한 조기 융합 기술, 매개변수 효율성을 극적으로 개선하는 희소 전문가 혼합(MoE) 아키텍처, 그리고 전례 없는 1,000만 토큰으로 확대되는 문맥 창을 포함한 세 가지 중요한 혁신의 융합을 나타냅니다.
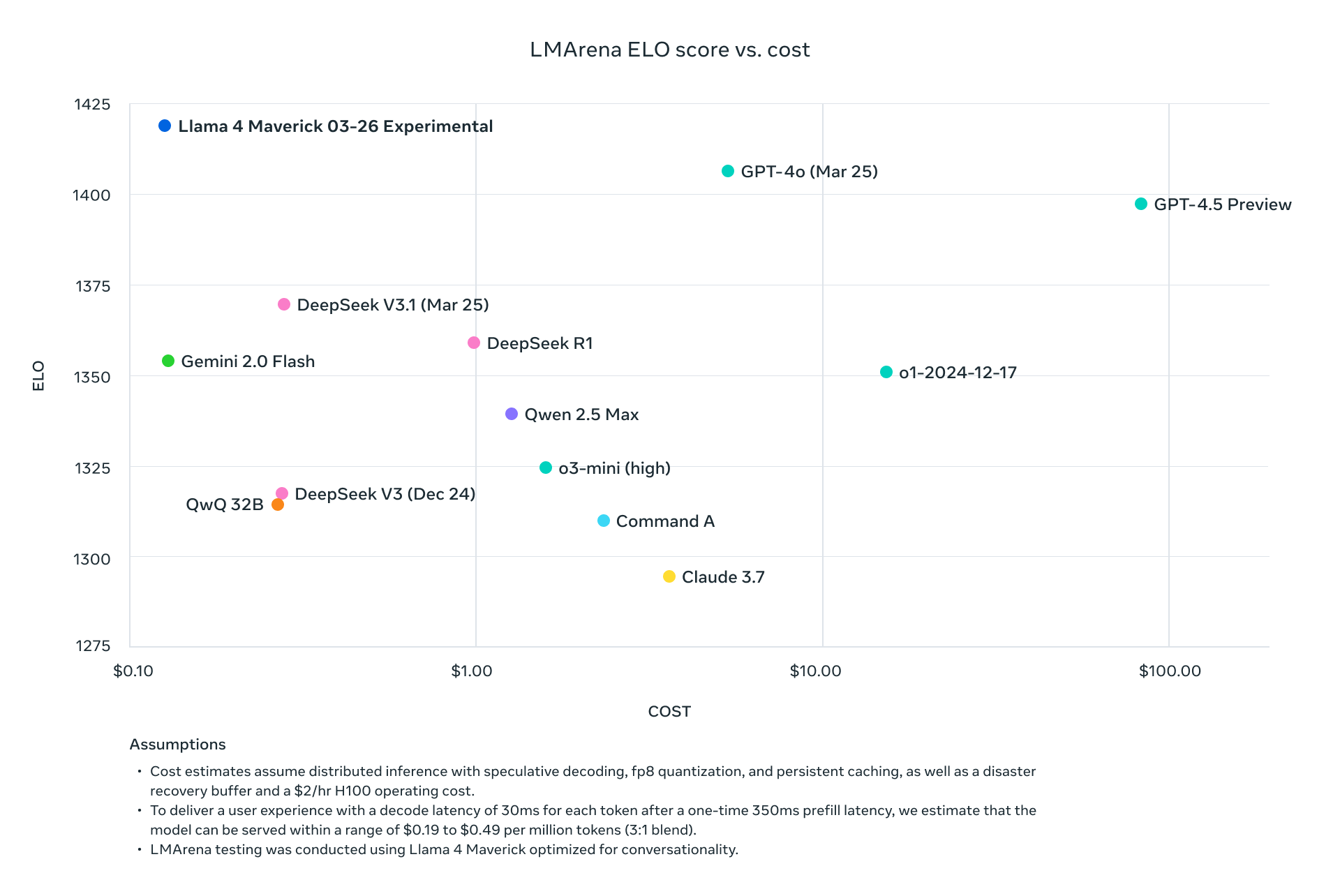
Llama 4 Scout와 Maverick은 현재 산업 리더들과 단순한 경쟁을 넘어서서, 표준 벤치마크에서 그들을 체계적으로 초과 달성하며 컴퓨팅 요구조건을 Dramatically.tr> 줄였습니다. Maverick은 약 9분의 1의 비용으로 GPT-4o보다 더 나은 결과를 달성하고, Scout은 여러 GPU를 필요로 하는 모델보다 우수한 성능을 유지하면서 단일 H100 GPU에 적재됩니다. 메타는 고급 AI 배치의 경제를 근본적으로 변경했습니다.
본 기술 분석은 이러한 모델을 구동하는 아키텍처 혁신을 분해하고, 추론, 코딩, 다국어 및 다중 모달 작업에 대한 종합적인 벤치마크 데이터 및 주요 제공자의 API 가격 구조를 조사합니다. AI 인프라 옵션을 평가하는 기술적 결정권자들에게는 이러한 혁신적인 모델의 생산 환경에서 효율성을 극대화하기 위한 상세한 성능/비용 비교 및 배치 전략을 제공합니다.
메타 Llama 4 오픈 소스 및 오픈 웨이트는 오늘부터 Hugging Face에서 다운로드할 수 있습니다:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Llama 4는 1,000만 문맥 창을 어떻게 달성했나요?
전문가 혼합(MoE) 구현
모든 Llama 4 모델은 근본적으로 효율성 공식을 변경하는 정교한 MoE 아키텍처를 사용합니다:
| 모델 | 활성 매개변수 | 전문가 수 | 총 매개변수 | 매개변수 활성화 방법 |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | 토큰별 라우팅 |
| Llama 4 Maverick | 17B | 128 | 400B | 공유 + 토큰당 단일 라우팅 전문가 |
| Llama 4 Behemoth | 288B | 16 | ~2T | 토큰별 라우팅 |
Llama 4 Maverick의 MoE 설계는 특히 정교하며, 밀집 및 MoE 레이어를 번갈아 사용합니다. 각 토큰은 공유 전문가와 128개의 라우팅된 전문가 중 하나를 활성화하므로, 특정 토큰을 처리하기 위해서는 총 400B의 매개변수 중 약 17B만 활성화됩니다.
다중 모달 아키텍처
Llama 4 다중 모달 아키텍처:
├── 텍스트 토큰
│ └── 원시 텍스트 처리 경로
├── 비전 인코더 (Enhance MetaCLIP)
│ ├── 이미지 처리
│ └── 이미지를 토큰 시퀀스로 변환
└── 조기 융합 레이어
└── 모델 백본에서 텍스트 및 비전 토큰 통합
이 조기 융합 접근 방식은 30조 개 이상의 혼합된 텍스트, 이미지 및 비디오 데이터를 사전 훈련할 수 있게 하여, 레트로핏 접근 방식보다 유의미하게 더 일관된 다중 모달 기능을 생성합니다.
확장된 문맥 창을 위한 iRoPE 아키텍처
Llama 4 Scout의 1,000만 토큰 문맥 창은 혁신적인 iRoPE 아키텍처를 활용합니다:
# iRoPE 아키텍처의 의사 코드
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# 짝수 레이어: 포지션 임베딩 없는 교차 주의
return attention_no_positional(tokens)
else:
# 홀수 레이어: RoPE (Rotary Position Embeddings)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# 추론 중 길이 일반화를 개선하는 온도 스케일링
return scale_attention_scores(tokens, temperature_factor)
이 아키텍처는 Scout가 전례 없는 길이의 문서를 처리하면서 일관성을 유지할 수 있도록 하며, 이전 Llama 모델의 문맥 창보다 약 80배 더 큰 스케일링 요인을 제공하여 처리를 확장합니다.
종합 벤치마크 분석
표준 벤치마크 성능 지표
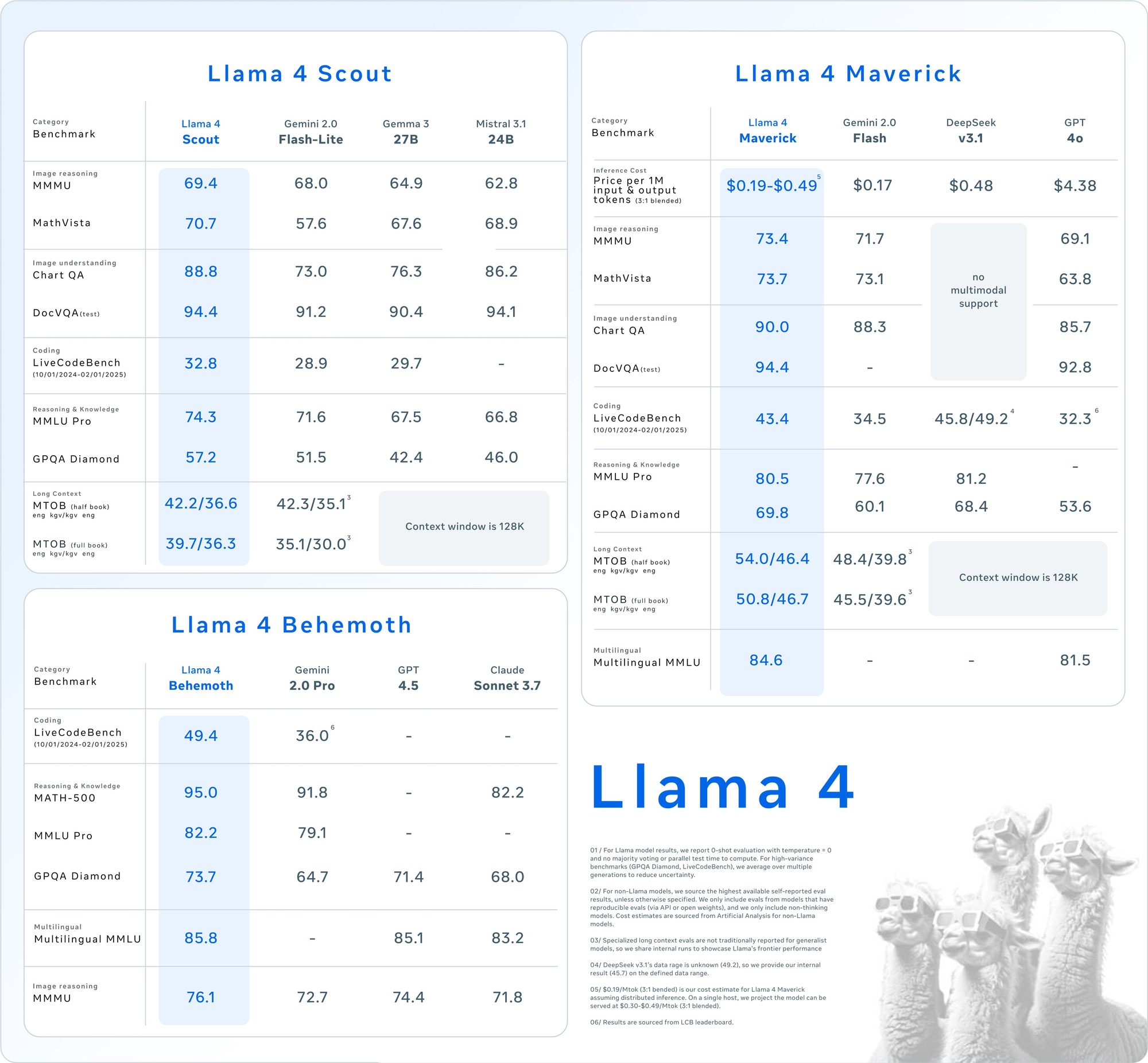
주요 평가 스위트에 대한 자세한 벤치마크 결과는 Llama 4 모델의 경쟁적 위치를 드러냅니다:
| 카테고리 | 벤치마크 | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| 이미지 추론 | MMMU | 73.4 | 69.1 | 71.7 | 다중 모달 지원 없음 |
| MathVista | 73.7 | 63.8 | 73.1 | 다중 모달 지원 없음 | |
| 이미지 이해 | ChartQA | 90.0 | 85.7 | 88.3 | 다중 모달 지원 없음 |
| DocVQA (테스트) | 94.4 | 92.8 | - | 다중 모달 지원 없음 | |
| 코딩 | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| 추론 및 지식 | MMLU Pro | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamond | 69.8 | 53.6 | 60.1 | 68.4 | |
| 다국어 번역 | 다국어 MMLU | 84.6 | 81.5 | - | - |
| 긴 문맥 | MTOB (반 책) eng→kgv/kgv→eng | 54.0/46.4 | 문맥은 128K로 제한됩니다. | 48.4/39.8 | 문맥은 128K로 제한됩니다. |
| MTOB (전체 책) eng→kgv/kgv→eng | 50.8/46.7 | 문맥은 128K로 제한됩니다. | 45.5/39.6 | 문맥은 128K로 제한됩니다. |
Llama 4 API 가격
이 API 도구는 모델의 엔드포인트를 손쉽게 테스트하고 디버그할 수 있도록 해줍니다. Apidog를 무료로 다운로드하여 Mistral Small 3.1의 기능을 탐색하며 작업 흐름을 간소화하세요!