
대규모 언어 모델(LLM)의 세계는 엄청난 속도로 발전하고 있지만, 효율성과 실시간 적응성 측면에서 여전히 어려움이 남아 있습니다. 2025년 9월 10일, Kimi 시리즈의 혁신적인 주역인 Moonshot AI는 LLM 추론 엔진의 가중치 업데이트를 재정의하는 오픈 소스 미들웨어인 checkpoint-engine을 출시했습니다. 강화 학습(RL)에 최적화된 이 경량 도구는 Kimi-K2와 같은 1조 개 매개변수 규모의 거대 모델을 수천 개의 GPU에 걸쳐 단 20초 만에 새로 고쳐 다운타임을 줄이고 확장성을 크게 향상시킬 수 있습니다.
버튼
이 글은 checkpoint-engine의 아키텍처부터 벤치마크까지 그 메커니즘을 자세히 살펴보고, RL에 미치는 영향과 더 넓은 생태계 적합성을 강조합니다. Moonshot AI는 이 귀중한 도구를 오픈 소스로 공개함으로써 커뮤니티가 LLM의 한계를 더욱 확장할 수 있도록 지원합니다. 이 혁신을 하나씩 자세히 살펴보겠습니다.
Checkpoint-Engine 이해하기: 핵심 개념 및 아키텍처
Checkpoint-Engine이란 무엇인가요?
본질적으로 checkpoint-engine은 LLM 추론 중 가중치를 원활하게 제자리에서 업데이트할 수 있도록 지원하는 미들웨어입니다. 이는 모델이 전체 재학습 없이 반복적인 피드백을 통해 진화하는 RL에서 매우 중요합니다. 전통적인 방법은 긴 재로드로 시스템을 지연시키지만, checkpoint-engine은 간소화되고 오버헤드가 적은 접근 방식으로 이를 해결합니다.
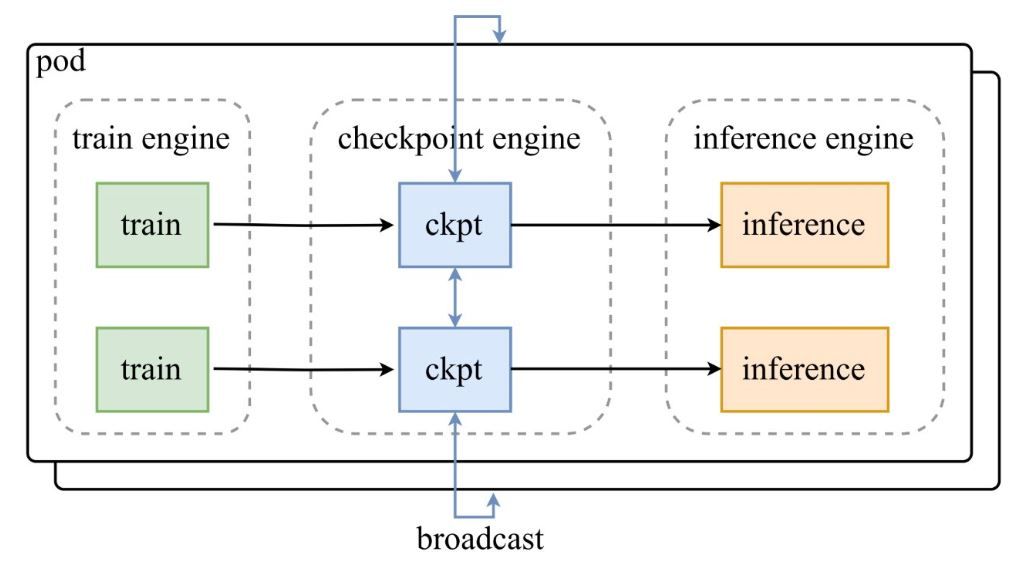
Moonshot AI의 발표 트윗에 있는 아키텍처 다이어그램에서 볼 수 있듯이, 훈련 엔진 포드가 중앙 checkpoint-engine에 체크포인트를 전달하면, 이 엔진이 추론 엔진에 업데이트를 브로드캐스트합니다. GitHub 저장소는 코드에 깊이 파고들어 ParameterServer 클래스를 업데이트 오케스트레이터로 조명합니다.
아키텍처 구성 요소
- 훈련 엔진: 진행 중인 RL 훈련에서 새로운 가중치를 생성하여 동적 환경에서 정책 개선 사항을 포착합니다.
- 체크포인트 엔진: 최소한의 지연 시간을 위해 추론과 함께 배치되는 미들웨어 코어입니다. 메타데이터 수집을 처리하고 브로드캐스트 또는 P2P 모드를 통해 업데이트를 실행합니다.
- 추론 엔진: 분산 GPU 클러스터 전반에 걸쳐 서비스 연속성을 유지하면서 즉석에서 업데이트를 통합합니다.
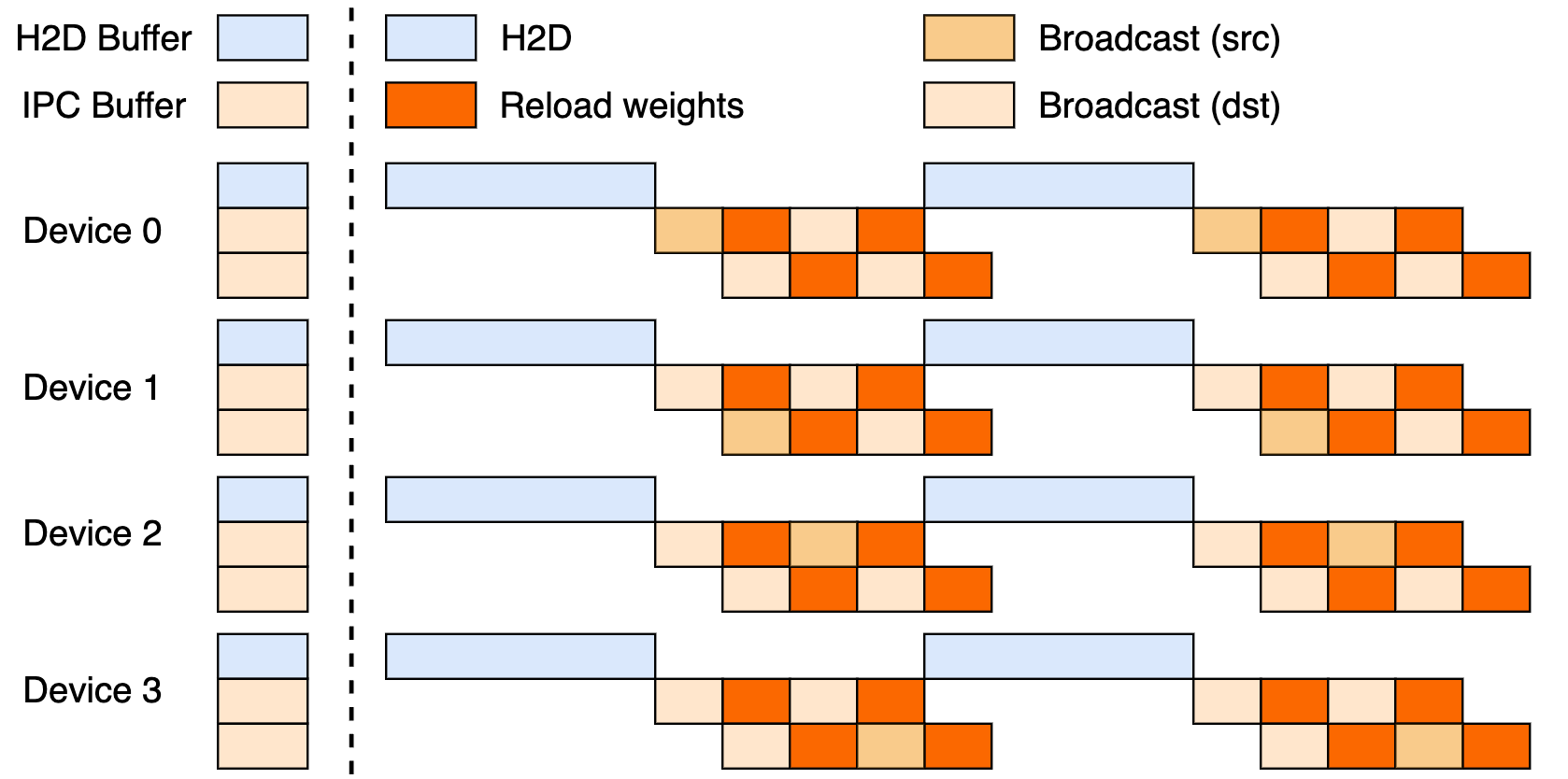
이 설정은 호스트-장치(H2D) 전송, CUDA IPC를 사용한 워커 간 브로드캐스트, 그리고 대상 재로드의 세 단계 파이프라인을 활용합니다. 이러한 단계들을 중첩시킴으로써 GPU 활용도를 극대화하고 전송 병목 현상을 줄입니다.
브로드캐스트 대 P2P 업데이트
브로드캐스트는 동기식, 클러스터 전체 업데이트에서 빛을 발하며, 최적의 흐름을 위해 데이터를 버킷으로 나누는 최고 속도 모드입니다. 반면 P2P는 mooncake-transfer-engine을 통한 RDMA를 사용하여 중단을 피함으로써 피크 시 확장과 같은 유연한 시나리오에서 뛰어납니다. 이러한 이중성은 checkpoint-engine을 안정적인 배포와 유동적인 배포 모두에 다용도로 활용할 수 있게 합니다.
성능 벤치마크: 얼마나 빨라야 충분한가?
20초 만에 1조 개 매개변수 모델 업데이트
Checkpoint-engine의 주요 성과는? Kimi-K2의 1조 개 매개변수를 수천 개의 GPU에 걸쳐 약 20초 만에 업데이트하는 것입니다. 이는 스마트한 파이프라이닝에서 비롯됩니다. 메타데이터 계획은 효율적인 버킷 크기를 설정하고, ZeroMQ 소켓은 전송을 조정하며, 중첩된 H2D/브로드캐스트 단계는 지연 시간을 숨깁니다.
이는 대규모 데이터 셔플로 인해 시스템이 몇 분 동안 유휴 상태가 될 수 있는 기존 기술과 대조됩니다. checkpoint-engine의 제자리 업데이트 방식은 추론을 원활하게 유지하여, 빠른 적응이 필요한 RL에 이상적입니다.
벤치마크 분석
벤치마크 표는 vLLM v0.10.2rc1로 테스트된 모델 및 설정 전반에 걸쳐 뛰어난 결과를 보여줍니다.
| 모델 | 장치 정보 | 메타데이터 수집 | 업데이트 (브로드캐스트) | 업데이트 (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17초 | 3.94초 (1.42GiB) | 8.83초 (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46초 | 6.75초 (2.69GiB) | 16.47초 (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44초 | 12.22초 (2.38GiB) | 25.77초 (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81초 | 15.45초 (2.93GiB) | 36.24초 (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40초 | 13.88초 (2.54GiB) | 33.30초 (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88초 | 21.50초 (2.99GiB) | 34.49초 (4.57GiB) |
저장소의 examples/update.py를 통해 이를 재현할 수 있습니다. FP8 실행에는 vLLM 패치가 필요하며, 이는 대규모 효율성을 강조합니다.
강화 학습에 미치는 영향
RL은 빠른 반복을 통해 발전합니다. checkpoint-engine의 20초 미만 주기는 배치 방식보다 빠른 지속적인 학습 루프를 가능하게 합니다. 이는 적응형 에이전트부터 진화하는 챗봇에 이르기까지, 정책 튜닝에서 매 순간이 중요한 반응형 앱을 구현합니다.
기술 구현: 코드베이스 탐구
오픈 소스 접근성
Moonshot AI의 GitHub 공개는 고급 RL 도구를 대중화합니다. ParameterServer는 업데이트의 핵심으로, 브로드캐스트(빠른 CUDA IPC 공유)와 P2P(초보자를 위한 RDMA)를 제공합니다. update.py 및 테스트(test_update.py)와 같은 예제는 온보딩을 용이하게 합니다.
호환성은 vLLM(워커 확장 기능을 통해)으로 시작하며, 다음으로 SGLang을 위한 후크가 고려됩니다. 부분적인 3단계 파이프라인은 아직 활용되지 않은 잠재력을 시사합니다.
최적화 기술
주요 기술은 다음과 같습니다.
- 파이프라인 중첩: 통신과 복사가 동시에 실행되어 실제 시간을 단축합니다.
- 버킷 최적화: 메타데이터 기반 크기 조정은 샤딩 및 네트워크에 맞춰 조정됩니다.
- ZeroMQ 제어: 추론 엔진에 대한 저지연 신호 전달.
이는 PCIe 충돌부터 메모리 부족(필요시 직렬로 전환)에 이르는 1조 개 매개변수 관련 난관을 해결합니다.
현재의 한계
P2P의 랭크-0 퍼널은 대규모에서 병목 현상을 일으킬 수 있으며, 전체 파이프라인은 개선을 기다리고 있습니다. vLLM에 대한 집중은 폭을 제한하지만, 패치는 DeepSeek-V3.1과 같은 모델의 FP8 격차를 메웁니다. 저장소에서 진화를 지켜보세요.
기존 프레임워크와의 통합: vLLM 및 그 이상
vLLM과의 협력
Checkpoint-engine은 vLLM의 PagedAttention과 기본적으로 페어링되어 부드러운 RL 추론을 제공합니다. 이 조합은 vLLM 업데이트에서 암시되었듯이 1조 개 모델에서 20초 동기화를 달성하며, 이는 오픈 협업이 처리량을 증폭시킨다는 점을 시사합니다.
Claude 및 Apidog로의 잠재적 확장
Anthropic의 Claude로 확장하면 안전에 중점을 둔 채팅에 RL의 역동성을 불어넣어 실시간 미세 조정을 가능하게 할 수 있습니다. Apidog는 ZeroMQ 조정 중 엔드포인트 모킹에 완벽하게 적합합니다. Apidog를 무료로 다운로드하여 이러한 브리지를 손쉽게 프로토타입화하세요.
더 넓은 생태계에 미치는 영향
Ollama 또는 LM Studio에 연결하면 1조 개 매개변수 모델의 기능을 로컬화하여 독립 개발자들에게 공평한 기회를 제공할 수 있습니다. 이러한 파급 효과는 더욱 포괄적인 AI 환경을 조성합니다.
미래 전망: Checkpoint-Engine의 미래는?
확장성 및 성능 향상
전체 파이프라인 배포는 시간을 더 단축할 수 있으며, P2P 분산화는 진정한 유연성을 위해 병목 현상을 제거합니다. RDMA 조정은 클라우드 네이티브의 강점을 약속합니다.
커뮤니티 기여
오픈 소스는 수정 및 포트를 환영합니다. SGLang 병합 또는 PCIe 독립 모드를 생각해 보세요. 트윗의 초기 반응은 흥분으로 가득하며, 추진력을 더하고 있습니다.
산업 적용
실시간 번역부터 자율 주행 RL에 이르기까지, checkpoint-engine은 변화가 많은 도메인에 적합합니다. 그 속도는 모델을 최신 상태로 유지하여 민첩성 면에서 경쟁사를 능가합니다.
LLM 추론의 새로운 시대?
Checkpoint-engine은 오픈 소스 방식으로 가중치 문제를 해결하며 민첩한 LLM의 미래를 예고합니다. 영리한 아키텍처와 벤치마크에 힘입은 20초 만의 1조 개 매개변수 새로 고침은 한계에도 불구하고 RL 분야에서 그 위상을 확고히 합니다.
개발 흐름을 위해 Apidog와 페어링하거나 하이브리드 스마트를 위해 Claude와 함께 사용하면 혁신이 급증합니다. GitHub를 추적하고, Apidog를 무료로 받고, 오늘날 추론을 재편하는 혁명에 동참하세요!
버튼