메타의 Llama 4 모델인 Llama 4 Maverick과 Llama 4 Scout는 다중 모드 AI 기술에서의 큰 도약을 의미합니다. 2025년 4월 5일에 출시된 이러한 모델은 혼합 전문가(MoE) 아키텍처를 활용하여 텍스트와 이미지를 효율적으로 처리하며, 성능 대 비용 비율이 뛰어납니다. 개발자는 다양한 플랫폼에서 제공하는 API를 통해 이러한 기능을 활용할 수 있어 애플리케이션 통합이 원활하고 강력해집니다.
Llama 4 Maverick과 Llama 4 Scout 이해하기
API 사용에 들어가기 전에 이 모델의 핵심 사양을 이해하세요. Llama 4는 본질적으로 다중 모드를 지원하며, 텍스트와 이미지를 함께 처리합니다. 또한, MoE 디자인은 작업당 일부 매개변수만 활성화하여 효율성을 높입니다.
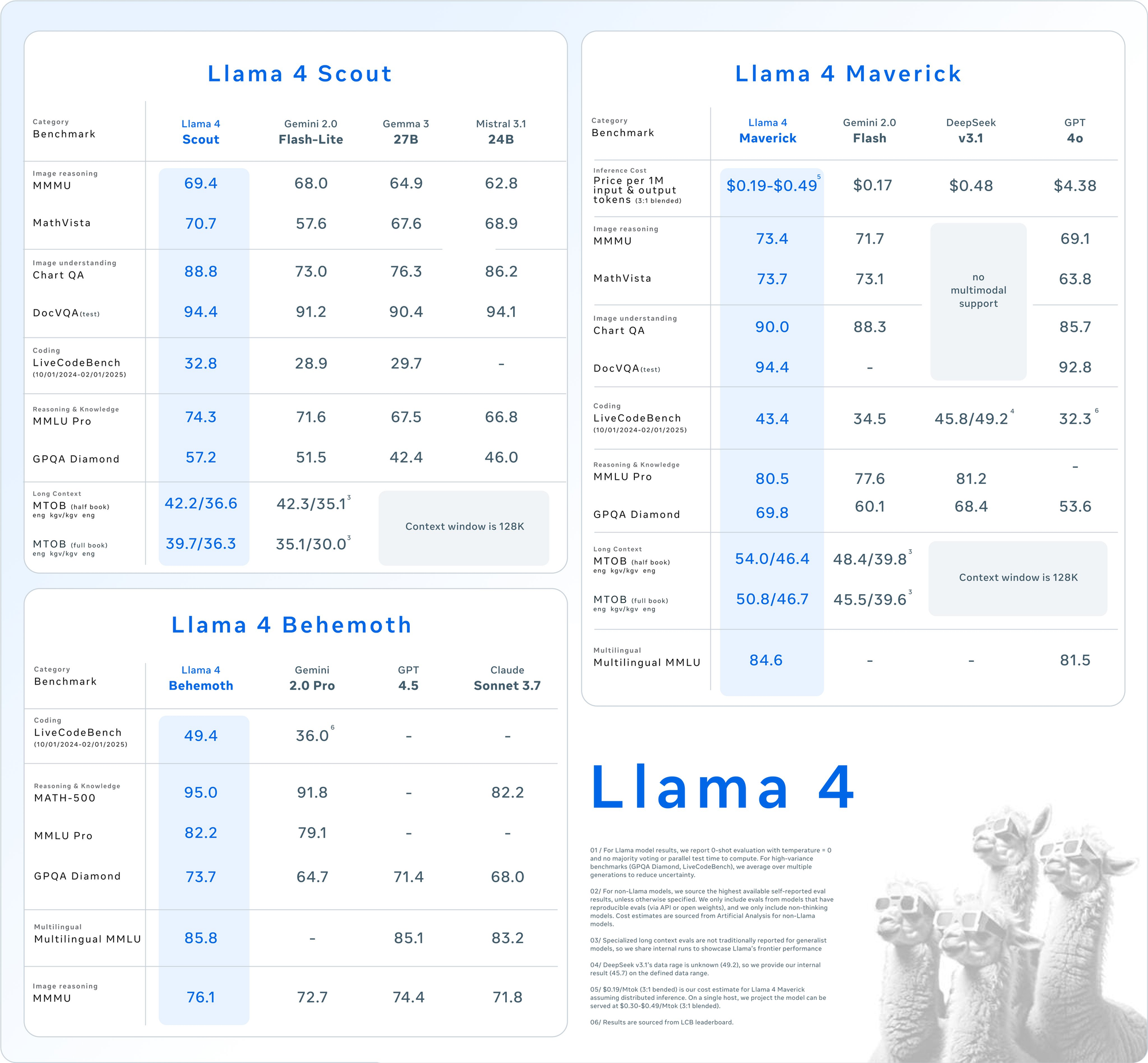
Llama 4 Scout: 효율적인 다중 모드 워크홀이
- 매개변수: 활성화 170억, 총 1090억, 16명의 전문가.
- 문맥 창: 최대 1000만 토큰.
- 주요 기능: 다중 문서 요약 및 대규모 코드베이스에 대한 추론과 같은 장기 문맥 작업에서 뛰어남. INT4 양자화로 단일 NVIDIA H100 GPU에 적합함.
- 용도: 빠르고 자원 효율적인 다중 모드 처리가 필요한 개발자에게 이상적입니다.
Llama 4 Maverick: 다재다능한 강력한 모델
- 매개변수: 활성화 170억, 총 4000억, 128명의 전문가.
- 문맥 창: 최대 100만 토큰.
- 주요 기능: 12개 언어(예: 영어, 스페인어, 힌디어)를 지원하며, 텍스트와 이미지 이해에서 높은 품질을 제공합니다. 채팅 및 창작 작문에 최적화되어 있습니다.
- 용도: 기업급 어시스턴트 및 다국어 애플리케이션에 적합합니다.
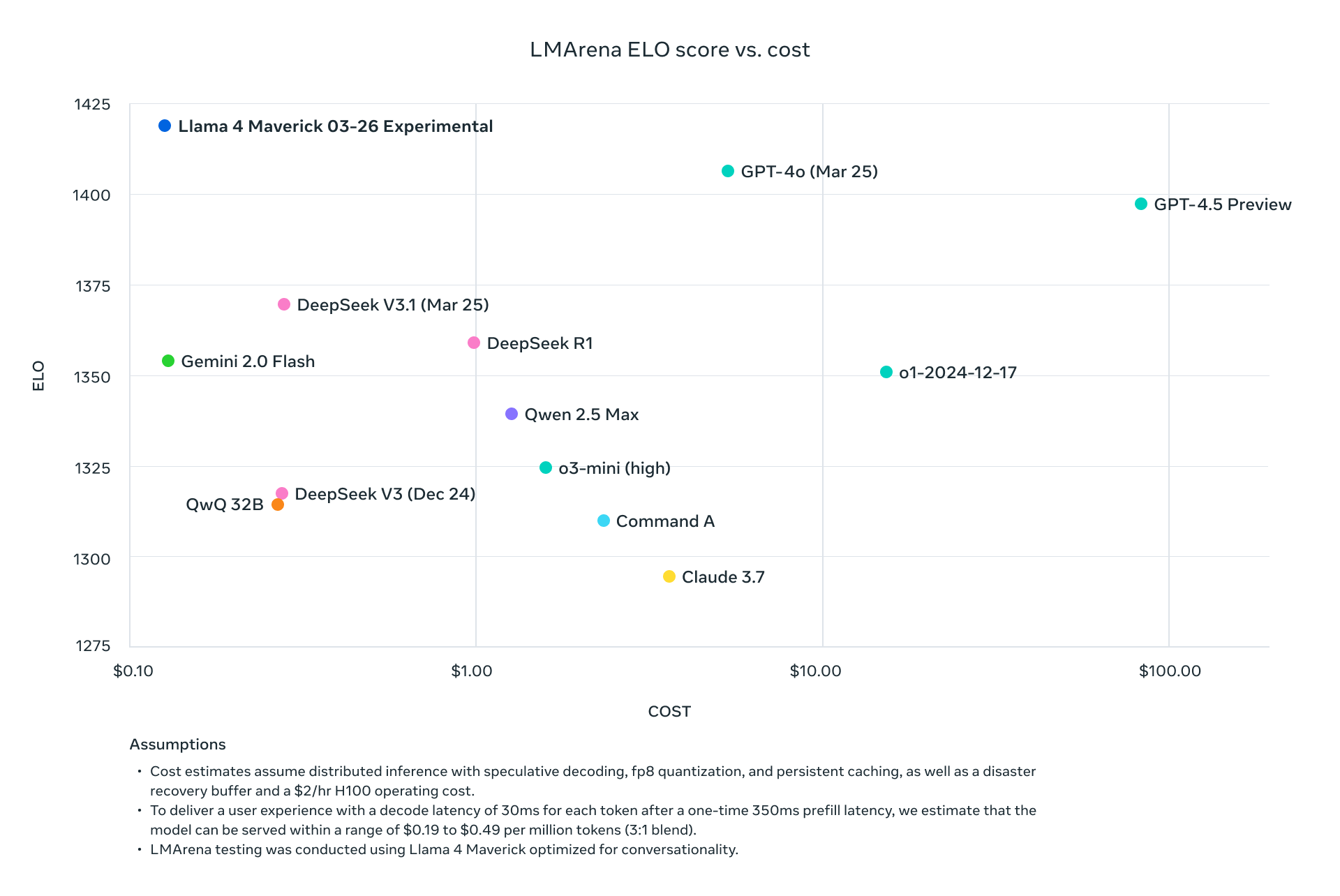
두 모델 모두 Llama 3 같은 이전 모델보다 성능이 우수하며, GPT-4o와 같은 산업 거대 기업들과 경쟁할 수 있는 강력한 선택지입니다.
Llama 4 API를 사용해야 하는 이유는 무엇인가요?
API를 통해 Llama 4를 통합하면 이러한 대규모 모델을 로컬에서 호스팅할 필요가 없어지며, 이는 상당한 하드웨어(예: Maverick의 경우 NVIDIA H100 DGX)가 필요할 수 있습니다. 대신 Groq, Together AI, OpenRouter와 같은 플랫폼이 관리되는 API를 제공하여 다음과 같은 이점을 제공합니다:
- 확장성: 인프라 오버헤드 없이 다양한 부하를 처리할 수 있습니다.
- 비용 효율성: 1토큰당 지불하며, 요금은 Scout의 경우 0.11달러/M 입력 토큰과 같은 낮은 요금부터 시작됩니다.
- 사용 용이성: 간단한 HTTP 요청으로 다중 모드 기능에 접근할 수 있습니다.
다음으로, 이러한 API를 호출하기 위해 환경을 설정해 보겠습니다.
Llama 4 API 호출을 위한 환경 설정하기
Llama 4 Maverick 및 Llama 4 Scout와 API를 통해 상호 작용하기 위해서는 개발 환경을 준비해야 합니다. 다음 단계를 따르세요:
1단계: API 제공업체 선택
여러 플랫폼이 Llama 4 API를 호스팅합니다. 다음은 인기 있는 옵션입니다:
- Groq: 저렴한 추론 제공(Scout: 0.11달러/M 입력, Maverick: 0.50달러/M 입력).
- Together AI: 맞춤형 확장성을 갖춘 전용 엔드포인트 제공.
- OpenRouter: 테스트에 이상적인 무료 계층 제공.
- Cloudflare Workers AI: Scout 지원을 위한 서버리스 배포.
본 가이드에서는 뛰어난 문서화와 성능 덕분에 Groq와 Together AI를 예로 사용하겠습니다.
2단계: API 키 받기
- Groq: groq.com에서 가입하고 개발자 콘솔로 이동하여 API 키를 생성합니다.
- Together AI: together.ai에서 등록한 후 대시보드에서 API 키에 접근합니다.
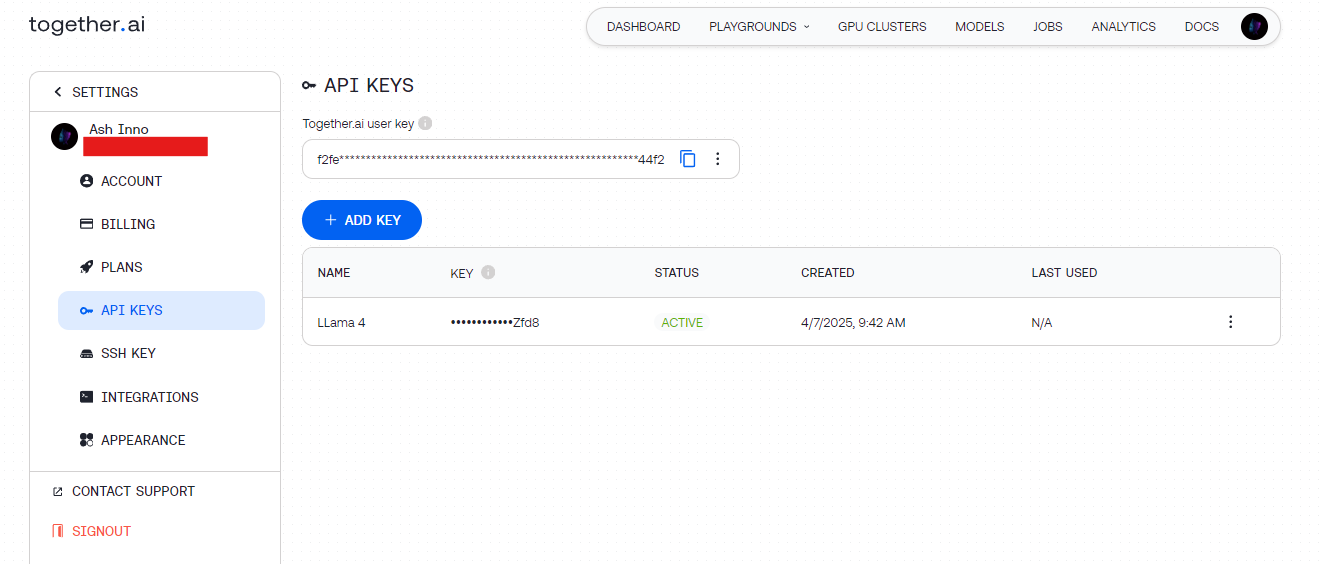
이 키를 안전하게 보관하세요(예: 환경 변수에 보관하여 하드코딩을 피함).
3단계: 의존성 설치
간편성을 위해 Python을 사용하세요. 필요한 라이브러리를 설치하세요:
pip install requests
테스트의 경우 Apidog는 API 엔드포인트를 시각적으로 디버그할 수 있도록 도와줍니다.
첫 번째 Llama 4 API 호출하기
귀하의 환경이 준비되면 Llama 4 API에 요청을 보내십시오. 기본 텍스트 생성 예제부터 시작해 보겠습니다.
예제 1: Llama 4 Scout를 사용한 텍스트 생성(Groq)
import requests
import os
# API 키 설정
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# 페이로드 정의
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "AI에 대한 짧은 시를 작성해 주세요."}
],
"max_tokens": 150,
"temperature": 0.7
}
# 헤더 설정
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 요청 보내기
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
출력: Scout의 효율적인 MoE 아키텍처를 활용하여 생성된 간결한 시.
예제 2: Llama 4 Maverick을 사용한 다중 모드 입력(Together AI)
Maverick은 다중 모드 작업에서 뛰어납니다. 이미지를 설명하는 방법은 다음과 같습니다:
import requests
import os
# API 키 설정
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# 이미지와 텍스트가 포함된 페이로드 정의
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "이 이미지를 설명해 주세요."
}
]
}
],
"max_tokens": 200
}
# 헤더 설정
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 요청 보내기
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
출력: Maverick의 이미지-텍스트 정렬을 보여주는 이미지에 대한 상세한 설명.
성능 최적화를 위한 API 요청 최적화
효율성을 극대화하려면 Llama 4 API 호출을 조정하세요. 다음 기법을 고려하십시오:
문맥 길이 조정
- Scout: 긴 문서를 위해 1000만 토큰 창을 사용합니다. 대형 입력을 처리하기 위해
max_model_len을 설정합니다(지원되는 경우). - Maverick: 속도와 품질의 균형을 맞추기 위해 채팅 애플리케이션에서는 100만 토큰으로 제한합니다.
매개변수 미세 조정
- 온도: 사실 기반 응답을 위해 낮게(예: 0.5), 창의성을 위해 높게(예: 1.0).
- 최대 토큰: 불필요한 계산을 피하기 위해 출력 길이를 제한합니다.
배치 처리
여러 프롬프트를 하나의 요청으로 보내지(API가 이를 지원하는 경우) 지연 시간을 줄입니다. 제공업체 문서를 확인하여 배치 엔드포인트를 찾으세요.
Llama 4 API로 고급 사용 사례 탐색하기
이제 Llama 4의 모든 잠재력을 발휘하기 위해 고급 통합을 탐색해 보세요.
사용 사례 1: 다국어 챗봇
Maverick은 12개 언어를 지원합니다. 고객 지원 봇을 구축해 보세요:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
출력: Maverick의 다국어 유창성을 활용한 스페인어 응답.
사용 사례 2: Scout를 사용한 문서 요약
Scout의 1000만 토큰 창은 대규모 텍스트 요약에서 탁월합니다:
long_text = "..." # 자세한 문서를 여기에 입력하세요
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"이 내용을 요약해 주세요: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
출력: Scout가 효율적으로 처리한 간결한 요약.
Apidog를 사용한 디버깅 및 테스트
API를 테스트하는 것은, 특히 다중 모드 입력의 경우 까다로울 수 있습니다. Apidog가 빛을 발하는 곳입니다:
- 시각적 인터페이스: 코딩 없이 요청을 작성하고 보낼 수 있습니다.
- 오류 추적: 요금 한도 초과 또는 잘못 형성된 페이로드와 같은 문제를 식별합니다.
- 모의 응답: 프론트엔드 개발을 위한 Llama 4의 출력을 시뮬레이션합니다.
제공된 예제를 Apidog에서 테스트하기 위해:
- Apidog를 열고 새 요청을 만듭니다.
- URL을 설정합니다(예:
https://api.groq.com/v1/chat/completions).

- 헤더(
Authorization,Content-Type)를 추가합니다.
- JSON 페이로드를 붙여넣습니다.

- 요청을 보내고 응답을 검토합니다.

이 워크플로우는 귀하의 Llama 4 API 통합이 원활하게 실행되도록 보장합니다.
Llama 4를 위한 API 제공업체 비교
적절한 제공업체 선택은 비용과 성능에 영향을 미칩니다. 다음은 분석입니다:
| 제공업체 | 모델 지원 | 가격 (입력/출력 M당) | 문맥 제한 | 비고 |
|---|---|---|---|---|
| Groq | Scout, Maverick | 0.11달러/0.34달러 (Scout), 0.50달러/0.77달러 (Maverick) | 128K (확장 가능) | 최저 비용, 높은 속도 |
| Together AI | Scout, Maverick | 맞춤형 (전용 엔드포인트) | 1M (Maverick) | 확장 가능, 기업 중심 |
| OpenRouter | 둘 다 | 무료 계층 제공 | 128K | 테스트에 좋음 |
| Cloudflare | Scout | 사용량 기반 | 131K | 서버리스 단순성 |
프로젝트의 규모와 예산에 따라 선택하세요. 프로토타입을 위해서는 OpenRouter의 무료 계층로 시작한 후 Groq 또는 Together AI로 확대하세요.
Llama 4 API 통합을 위한 모범 사례
견고한 통합을 보장하려면 다음 지침을 따르세요:
- 요율 제한: 제공업체의 제한을 준수하세요(예: Groq의 경우 분당 100 요청). 재시도를 위해 지수 백오프를 구현하세요.
- 오류 처리: HTTP 오류(예: 429 Too Many Requests)를 포착하고 기록하세요.
- 보안: API 키를 암호화하고 HTTPS 엔드포인트를 사용하세요.
- 모니터링: 비용 관리를 위해 토큰 사용량을 추적하세요. 특히 Maverick의 높은 요금에 주의하세요.
일반 API 문제 해결하기
문제가 발생했나요? 신속하게 해결하세요:
- 401 Unauthorized: API 키를 확인하세요.
- 429 Rate Limit Exceeded: 요청 빈도를 줄이거나 요금제를 업그레이드하세요.
- 페이로드 오류: JSON 형식이 제공업체의 사양과 일치하는지 확인하세요(예:
messages배열).
Apidog는 이러한 문제를 시각적으로 진단하는 데 도움을 주어 시간을 절약합니다.
결론
Llama 4 Maverick과 Llama 4 Scout를 API를 통해 통합하면 개발자가 최소한의 오버헤드로 최첨단 애플리케이션을 구축할 수 있습니다. Scout의 긴 문맥 효율성이나 Maverick의 다국어 능력이 필요하든, 이러한 모델은 접근 가능한 엔드포인트를 통해 최상급 성능을 제공합니다. 이 가이드를 따르면 API 호출을 효과적으로 설정, 최적화 및 문제 해결할 수 있습니다.
더 깊이 들어갈 준비가 되셨나요? Groq 및 Together AI와 같은 제공업체를 사용해보고, Apidog를 활용해 작업 흐름을 개선하세요. 다중 모드 AI의 미래가 여기 있습니다—오늘 바로 구축을 시작하세요!