
OpenAI API처럼 100개 이상의 거대 언어 모델(LLM)과 채팅하고 싶으신가요? 챗봇을 만들든, 작업을 자동화하든, 아니면 단순히 기술에 몰입하든, LiteLLM은 OpenAI 스타일의 동일한 형식을 사용하여 OpenAI, Anthropic, Ollama 등의 LLM을 호출할 수 있는 도구입니다. 저는 API 호출을 단순화하기 위해 LiteLLM을 깊이 파고들었는데, 코드를 깔끔하고 유연하게 유지하는 데 정말 큰 도움이 됩니다. 이 초보자 가이드에서는 공식 문서를 기반으로 LiteLLM을 설정하고, 로컬 Ollama 모델과 OpenAI의 GPT-4o를 호출하고, 응답을 스트리밍하는 방법까지 보여드리겠습니다. AI 프로젝트를 화창한 오후처럼 부드럽게 만들 준비가 되셨나요? 시작해 봅시다!
LiteLLM이란 무엇인가요? 당신의 LLM API 슈퍼파워
LiteLLM은 OpenAI Chat Completions 형식을 사용하여 OpenAI, Anthropic, Azure, Hugging Face 및 Ollama를 통한 로컬 모델과 같은 100개 이상의 LLM API를 호출할 수 있는 오픈 소스 Python 라이브러리이자 프록시 서버입니다. 입력 및 출력을 표준화하고, API 키를 처리하며, 스트리밍, 대체(fallback), 비용 추적과 같은 유용한 기능을 추가하여 각 제공업체마다 코드를 다시 작성할 필요가 없습니다. 22.7K 이상의 GitHub 스타를 기록하고 Adobe 및 Lemonade와 같은 회사에서 채택한 LiteLLM은 개발자들 사이에서 인기가 높습니다. MkDocs와 같은 도구로 API 문서를 작성하든 AI 앱을 구축하든, LiteLLM은 워크플로우를 단순화합니다. 설정하고 작동하는 모습을 살펴봅시다!
LiteLLM 환경 설정하기
LiteLLM으로 LLM을 호출하기 전에 시스템을 준비해 봅시다. 이 과정은 초보자에게 친숙하며, 각 단계가 자세히 설명되어 있어 쉽게 따라할 수 있습니다.
1. 필수 도구 확인: 다음 도구가 필요합니다.
- Python: 3.8 버전 이상. 터미널에서
python --version을 실행하세요. 없거나 너무 오래된 버전이라면 python.org에서 다운로드하세요. Python은 LiteLLM 스크립트를 실행합니다. - pip: Python의 패키지 관리자로, Python 3.4 이상에 포함되어 있습니다.
pip --version으로 확인하세요. 없다면get-pip.py를 다운로드하고python get-pip.py를 실행하세요. - Ollama: 로컬 모델을 위해 필요합니다. ollama.com에서 다운로드하고
ollama --version으로 확인하세요 (예: 0.1.44). 로컬 LLM 테스트에 사용할 것입니다.
빠진 것이 있나요? 지금 설치하여 원활하게 진행하세요.
2. 프로젝트 폴더 생성: 체계적으로 관리합시다.
mkdir litellm-api-test
cd litellm-api-test
이 폴더는 LiteLLM 프로젝트를 담을 것이며, cd 명령으로 폴더 안으로 이동합니다.
3. 가상 환경 설정: Python 가상 환경으로 패키지 충돌을 방지하세요.
python -m venv venv
활성화하세요:
- Mac/Linux:
source venv/bin/activate - Windows:
venv\Scripts\activate
터미널에 (venv)가 보이면 LiteLLM의 종속성을 격리하는 깨끗한 환경에 있는 것입니다.
4. OpenAI API 키 받기: GPT-4o 테스트를 위해 openai.com에 가입하고 API 키 메뉴로 이동하여 키를 생성하세요. 나중에 필요하니 안전하게 저장하세요.
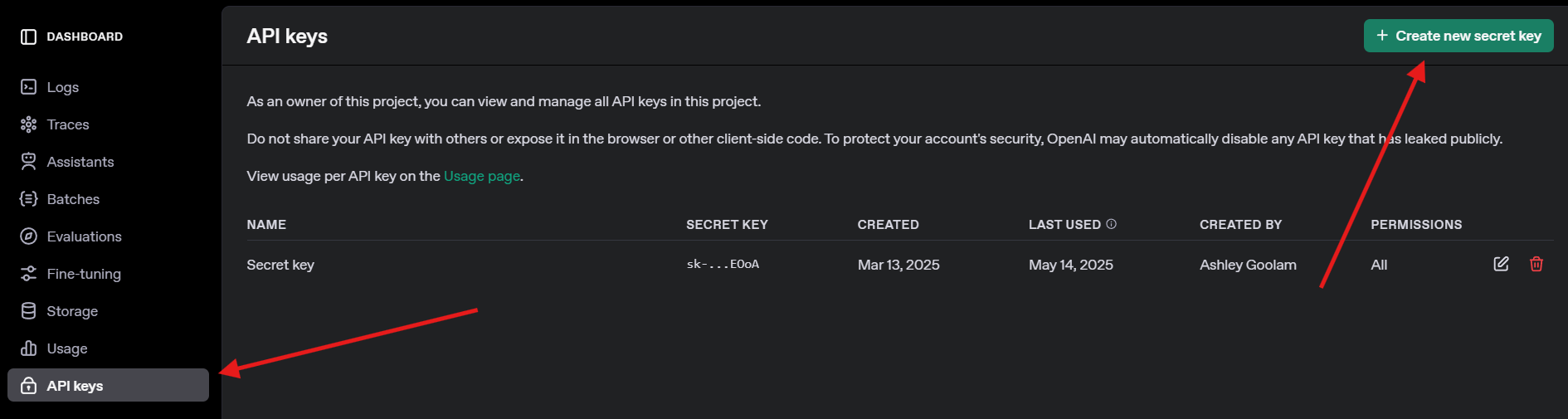
LiteLLM 및 Ollama 설치하기
이제 LiteLLM을 설치하고 로컬 모델을 위해 Ollama를 설정해 봅시다. 이 과정은 빠르며 API 호출을 위한 준비를 마칩니다.
1. LiteLLM 설치: 활성화된 가상 환경에서 다음을 실행하세요.
pip install litellm openai
이것은 LiteLLM과 OpenAI SDK(호환성을 위해 필요)를 설치합니다. pydantic 및 httpx와 같은 종속성도 함께 설치됩니다.
2. LiteLLM 확인: 설치를 확인하세요.
python -c "import litellm; print(litellm.__version__)"
1.40.14 또는 그 이상의 버전이 표시될 것입니다. 실패하면 pip를 업데이트하세요 (pip install --upgrade pip).
3. Ollama 설정: Ollama가 실행 중인지 확인하고 Llama 3 (8B)와 같은 경량 모델을 가져오세요.
ollama pull llama3
이것은 약 4.7GB를 다운로드하므로 연결이 느리다면 간식을 가져오세요. ollama list로 llama3:latest가 있는지 확인하세요. Ollama는 LiteLLM이 호출할 로컬 모델을 호스팅합니다.
LiteLLM으로 LLM 호출하기: OpenAI 및 Ollama 예제
이제 재미있는 부분, LLM 호출하기입니다! LiteLLM의 OpenAI 호환 형식을 사용하여 OpenAI의 GPT-4o와 Ollama를 통한 로컬 Llama 3 모델을 호출하는 Python 스크립트를 만들 것입니다. 실시간 응답을 위한 스트리밍도 시도해 볼 것입니다.
1. 테스트 스크립트 생성: litellm-api-test 폴더에 test_llm.py 파일을 만들고 다음 코드를 붙여넣으세요.
from litellm import completion
import os
# Set environment variables
os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Replace with your key
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434" # Default Ollama endpoint
# Messages for the LLM
messages = [{"content": "Write a short poem about the moon", "role": "user"}]
# Call OpenAI GPT-4o
print("Calling GPT-4o...")
gpt_response = completion(
model="openai/gpt-4o",
messages=messages,
max_tokens=50
)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# Call Ollama Llama 3
print("\nCalling Ollama Llama 3...")
ollama_response = completion(
model="ollama/llama3",
messages=messages,
max_tokens=50,
api_base="http://localhost:11434"
)
print("Llama 3 Response:", ollama_response.choices[0].message.content)
# Stream Ollama Llama 3 response
print("\nStreaming Ollama Llama 3...")
stream_response = completion(
model="ollama/llama3",
messages=messages,
stream=True,
api_base="http://localhost:11434"
)
print("Streamed Llama 3 Response:")
for chunk in stream_response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Newline after streaming
이 스크립트는 다음을 수행합니다.
- API 키와 Ollama의 엔드포인트를 설정합니다.
- 프롬프트("달에 대한 짧은 시를 써줘")를 정의합니다.
- LiteLLM의
completion함수로 GPT-4o와 Llama 3를 호출합니다. - 실시간 출력을 위해 Llama 3의 응답을 스트리밍합니다.
2. API 키 교체: os.environ["OPENAI_API_KEY"]를 실제 OpenAI 키로 업데이트하세요. 키가 없다면 GPT-4o 호출은 건너뛰고 Ollama에 집중하세요.
3. Ollama 실행 확인: 별도의 터미널에서 Ollama를 시작하세요.
ollama serve
이것은 Ollama를 http://localhost:11434에서 실행합니다. Llama 3 호출을 위해 이 터미널을 열어 두세요.
4. 스크립트 실행: 가상 환경에서 다음을 실행하세요.
python test_llm.py
- 제가 실행했을 때, GPT-4o는 다음과 같은 다듬어진 시를 반환했습니다.
>> The moon’s soft glow, a silver dream, lights paths where quiet shadows gleam.
- Llama 3는 다음과 같은 더 간단하지만 매력적인 버전을 제공했습니다.
>> Moon so bright in the night sky, glowing soft as clouds float by.
스트리밍 응답은 단어별로 출력되어 LLM이 실시간으로 타이핑하는 것처럼 느껴졌습니다. 실패하면 Ollama가 실행 중인지, OpenAI 키가 유효한지, 또는 11434 포트가 열려 있는지 확인하세요. 디버그 로그는 ~/.litellm/logs에 있습니다.
LiteLLM 콜백으로 관측 가능성 추가하기
LLM 호출을 전문가처럼 추적하고 싶으신가요? LiteLLM은 Langfuse 또는 MLflow와 같은 도구에 입력, 출력, 비용을 기록하는 콜백을 지원합니다. 간단한 콜백을 추가하여 비용을 기록해 봅시다.
스크립트 업데이트: test_llm.py를 수정하여 비용 추적 콜백을 포함시키세요.
from litellm import completion
import os
# Callback function to track cost
def track_cost_callback(kwargs, completion_response, start_time, end_time):
cost = kwargs.get("response_cost", 0)
print(f"Response cost: ${cost:.4f}")
# Set callback
import litellm
litellm.success_callback = [track_cost_callback]
# Rest of the script (same as above)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434"
messages = [{"role": "user", "content": "Write a short poem about the moon"}]
print("Calling GPT-4o...")
gpt_response = completion(model="openai/gpt-4o", messages=messages, max_tokens=50)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# ... (Ollama and streaming calls unchanged)
이것은 각 호출의 비용을 기록합니다 (예: GPT-4o의 경우 "Response cost: $0.0025"). Ollama 호출은 무료이므로 비용은 $0입니다.
다시 실행: python test_llm.py를 실행하세요. 응답과 함께 비용 로그가 표시되어 클라우드 기반 LLM의 비용을 모니터링하는 데 도움이 됩니다.
APIdog로 API 문서화하기
LLM API를 사용하고 있으므로 팀이나 사용자를 위해 명확하게 문서화하고 싶을 것입니다. APIdog를 강력히 추천합니다. APIdog의 문서화는 이를 위한 환상적인 도구입니다! API 플레이그라운드 및 자체 호스팅 옵션과 같은 기능을 갖춘 세련되고 인터랙티브한 플랫폼을 제공하여 API를 설계, 테스트 및 문서화할 수 있습니다. LiteLLM의 API 호출과 APIdog의 잘 다듬어진 문서를 결합하면 프로젝트를 한 단계 업그레이드할 수 있습니다. 시도해 보세요!
LiteLLM에 대한 나의 생각
LiteLLM을 사용해 본 후 제가 좋아하는 점은 다음과 같습니다.
- 통합 형식: OpenAI, Ollama 등을 위한 하나의 코드 구조로, 더 이상 API별 골치 아픈 일이 없습니다.
- 로컬 파워: Ollama 통합으로 오프라인에서 모델을 실행할 수 있어 개인 정보 보호 또는 저예산 프로젝트에 완벽합니다.
- 스트리밍의 재미: 실시간 응답으로 앱이 친구와 채팅하는 것처럼 생생하게 느껴집니다.
- 커뮤니티의 활기: 18K 이상의 GitHub 스타를 기록하며 LiteLLM은 개발자들에게 인기가 많습니다.
어려움이 있다면? Ollama 또는 API 키 설정이 제대로 되지 않으면 설정이 까다로울 수 있지만, 문서는 훌륭합니다.
LiteLLM 성공을 위한 전문가 팁
- 디버깅:
litellm.set_verbose = True로 상세 로깅을 활성화하여 원시 요청 및 응답을 확인하세요. - 더 많은 모델: Anthropic의 Claude 또는 Azure OpenAI를 사용하려면 해당 API 키와 모델(예:
anthropic/claude-3-sonnet-20240229)을 추가하세요. - 비동기 호출: FastAPI 앱에서 논블록킹 호출을 위해
litellm.acompletion을 사용하세요. - 프록시 서버: 여러 앱이 하나의 엔드포인트를 공유하도록 LiteLLM을 프록시로 실행하세요 (
litellm --model gpt-3.5-turbo). - 커뮤니티: LiteLLM Discord 또는 GitHub Discussions에 참여하여 팁과 업데이트를 얻으세요.
마무리: LiteLLM 여정은 여기서 시작됩니다
OpenAI의 GPT-4o부터 로컬 Llama 3까지, 모든 LLM을 하나의 깔끔한 형식으로 전문가처럼 호출하는 LiteLLM의 힘을 방금 잠금 해제했습니다! AI 앱을 구축하든 호기심 많은 코더처럼 실험하든, LiteLLM은 모델 전환, 응답 스트리밍, 비용 추적을 쉽게 해줍니다. 새로운 프롬프트를 시도하고, 더 많은 제공업체를 추가하거나, 더 큰 프로젝트를 위해 프록시 서버를 설정해 보세요. LiteLLM GitHub에서 여러분의 LiteLLM 성공 사례를 공유해 주세요. 여러분이 무엇을 만들지 기대됩니다! 그리고 API 문서화를 위해 APIdog도 꼭 확인해 보세요. 즐거운 코딩 되세요!