
비주얼 언어 모델(VLM)은 AI가 시각적 콘텐츠를 이해하고 추론하는 능력을 혁신적으로 변화시켰습니다. 이러한 혁신 중에서 Moonshot AI의 Kimi VL Thinking 모델은 특히 인상적이며, 고급 추론 능력과 뛰어난 효율성을 결합하고 있습니다. 이 튜토리얼은 Kimi VL Thinking의 기능을 이해하고 OpenRouter 플랫폼을 통해 무료로 사용하는 방법을 안내합니다.
Kimi VL Thinking 벤치마크
Kimi VL Thinking(정식 명칭: Kimi-VL-A3B-Thinking)은 Moonshot AI에서 개발한 고급 비주얼 언어 모델입니다. 이 모델의 특별함은 추론 단계마다 28억 개의 파라미터만 활성화되는 Mixture-of-Experts(MoE) 아키텍처에 있습니다. 총 약 160억 개의 파라미터를 포함하고 있어, 상대적으로 효율적인 계산으로 복잡한 추론을 수행할 수 있습니다.
Kimi VL Thinking은 특히 단계별 사고와 시각적 입력의 수학적 분석이 필요한 고급 추론 작업을 위해 설계되었습니다. 이 모델은 연쇄적 사고(Cot) 감독 학습과 강화 학습 기법으로 Kimi VL 기본 모델을 미세 조정하여 만들어졌습니다.
Kimi VL Thinking 모델의 주요 특징
- 긴 맥락 창: 최대 128K 토큰을 지원하여 광범위한 다중 턴 대화와 긴 문서 처리 가능.
- 네이티브 해상도 비전: MoonViT 인코더를 사용하여 고해상도 시각적 입력을 훌륭한 세부 인식으로 처리합니다.
- 고급 추론: 특히 수학적 비주얼 추론과 단계별 문제 해결에 강함.
- 효율적인 계산: 강력한 기능에도 불구하고 모델은 28억 개의 파라미터만 활성화하여 더 큰 대안보다 접근성이 높음.
- 오픈 소스: MIT 라이센스 하에 제공되어 폭넓은 학술 및 상업적 응용이 가능.
Kimi VL Thinking 벤치마크 성능
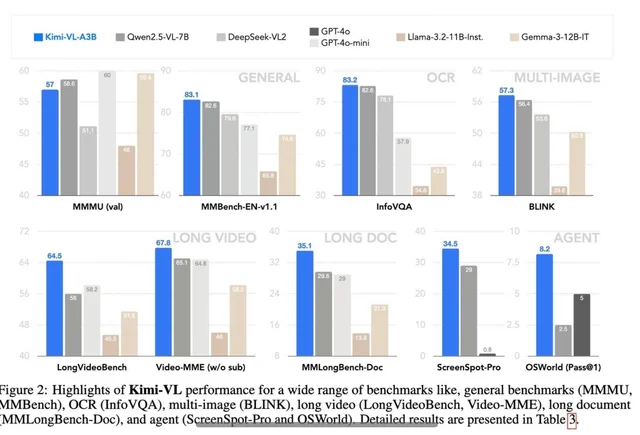
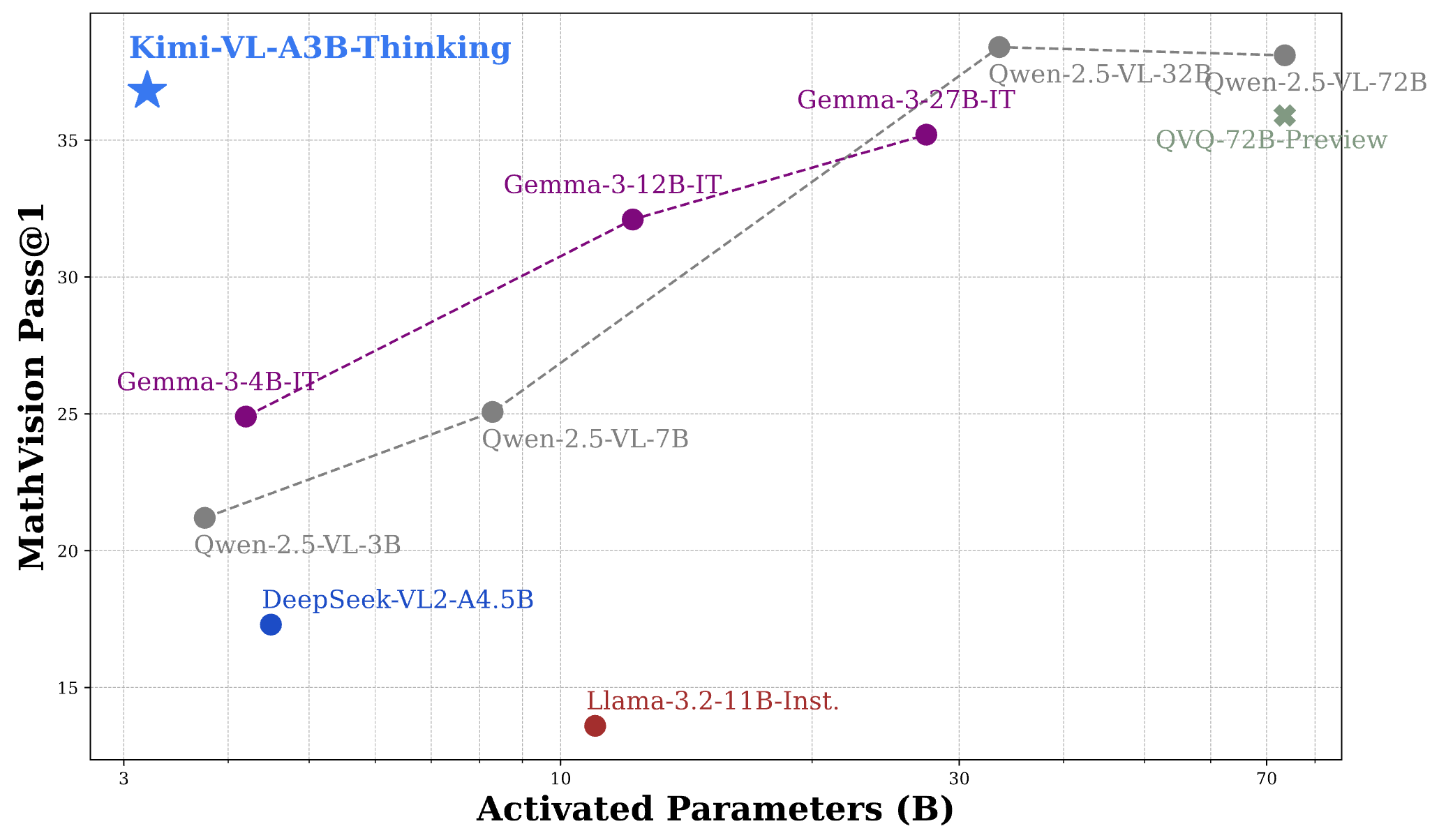
Kimi VL Thinking은 여러 도전적인 벤치마크에서 인상적인 성능을 보이며, 종종 더 큰 모델과 경쟁하거나 이를 초과합니다:
- MathVision: 36.8 점(Pass@1)을 달성하며, Gemma-3-27B(35.5)와 비슷하고 Qwen2.5-VL-72B(38.1)에 근접함.
- MathVista: 미니 벤치마크에서 71.3 점을 기록하여 GPT-4o-mini(56.7) 및 Gemma-3-12B(56.4)를 초과함.
- MMMU(다중 모드 대규모 다중 작업 이해): 검증 세트에서 61.7에 도달하며 복잡한 다중 모드 작업에서 강한 능력을 보여줌.
이 결과를 이해하면 Kimi VL Thinking의 성능이 28억 개의 파라미터만 활성화하면서 7B, 12B 또는 70B 이상의 파라미터를 사용하는 모델과 경쟁한다는 점에서 놀랍습니다. 이는 가장 효율적인 추론 능력을 가진 VLM 중 하나로 자리매김하고 있습니다.
OpenRouter를 통해 Kimi VL Thinking을 무료로 사용하는 방법
OpenRouter는 Kimi VL Thinking에 직접 모델을 배포할 필요 없이 접근할 수 있는 편리한 방법을 제공합니다. 무료 티어를 통해 비용 없이 모델을 실험할 수 있습니다. 시작하기 위한 방법은 다음과 같습니다:
1단계: OpenRouter 계정 만들기
- OpenRouter 웹사이트를 방문하고 계정이 없으신 경우 가입합니다.
- 등록 후 계정 설정으로 이동하여 API 키를 생성합니다.
- 이 API 키를 안전하게 보관합니다. 모든 API 호출에 필요합니다.
2단계: OpenRouter API 구조 이해하기
OpenRouter의 API는 OpenAI API 형식과 호환되도록 설계되어 있어, OpenAI 서비스에 익숙한 경우 쉽게 통합할 수 있습니다. 주요 차이점은 다음과 같습니다:
- 기본 URL:
https://openrouter.ai/api/v1 - 모델 이름:
moonshotai/kimi-vl-a3b-thinking:free - 분석을 위한 추가 선택적 헤더
3단계: 첫 번째 API 호출하기
Python 사용자의 경우 다음 종속성으로 환경을 설정합니다:
pip install openai requests pillow
OpenAI SDK를 사용하여 가장 간단한 예제로 시작해 보겠습니다:
from openai import OpenAI
from base64 import b64encode
from PIL import Image
import io
# OpenRouter의 기본 URL로 클라이언트 초기화
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# 이미지를 인코딩하는 함수
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 이미지 로드 및 인코딩
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# API 요청 생성
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "your_site_url", # 분석을 위한 선택 사항
"X-Title": "your_app_name", # 분석을 위한 선택 사항
},
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "이 수학 문제를 단계별로 검토하고 해결해 주세요."
}
]
}
],
max_tokens=1024
)
print(completion.choices[0].message.content)
SDK 없이 직접 API 호출을 선호하는 경우:
import requests
import json
from base64 import b64encode
# 이미지를 인코딩하는 함수
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 이미지 로드 및 인코딩
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# API 요청 생성
response = requests.post(
url="<https://openrouter.ai/api/v1/chat/completions>",
headers={
"Authorization": "Bearer your_openrouter_api_key_here",
"Content-Type": "application/json",
"HTTP-Referer": "your_site_url", # 분석을 위한 선택 사항
"X-Title": "your_app_name", # 분석을 위한 선택 사항
},
data=json.dumps({
"model": "moonshotai/kimi-vl-a3b-thinking:free",
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "이 수학 문제를 단계별로 검토하고 해결해 주세요."
}
]
}
],
"max_tokens": 1024
})
)
print(response.json()["choices"][0]["message"]["content"])
긴 응답이나 더 나은 사용자 경험을 위해 모델의 출력을 스트리밍할 수 있습니다:
from openai import OpenAI
from base64 import b64encode
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# 이미지를 인코딩하는 함수
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 이미지 로드 및 인코딩
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# 스트리밍 요청 생성
stream = client.chat.completions.create(
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "이 수학 문제를 단계별로 검토하고 해결해 주세요."
}
]
}
],
stream=True,
max_tokens=1024
)
# 스트리밍 응답 처리
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Apidog로 Kimi VL Thinking API 테스트하기
Apidog는 Kimi VL Thinking과 같은 API와 상호작용하는 과정을 단순화하는 종합 API 테스트 도구입니다. 환경 관리 및 시나리오 시뮬레이션과 같은 기능 덕분에 개발자에게 이상적입니다. Apidog를 사용하여 Kimi VL Thinking API를 테스트하는 방법을 살펴보겠습니다.
Apidog 설정하기
먼저, apidog.com에서 Apidog를 다운로드하고 설치합니다. 설치 후 새 프로젝트를 만들고 Kimi VL Thinking API 엔드포인트를 추가합니다: https://openrouter.ai/api/v1/chat/completions.
환경 구성하기
다음으로 Apidog에서 개발 및 생산과 같은 서로 다른 환경을 설정합니다. API 키와 기본 URL과 같은 변수를 정의하여 설정 간에 쉽게 전환할 수 있습니다. Apidog에서 “환경” 탭으로 이동하여 다음을 추가합니다:
api_key: 귀하의 OpenRouter API 키base_url:https://openrouter.ai/api/v1
테스트 요청 만들기
이제 Apidog에서 새 POST 요청을 생성합니다.
URL을 {{base_url}}/chat/completions로 설정하고 헤더를 추가한 후 JSON 본문을 입력합니다:
{
"model": "quasar-alpha",
"messages": [
{"role": "user", "content": "JavaScript에서 let과 const의 차이를 설명해 주세요."}
],
"max_tokens": 300
}
헤더 섹션에 추가합니다:
Authorization:Bearer {{api_key}}Content-Type:application/json
테스트 실행 및 분석하기
마지막으로 요청을 보내고 Apidog의 시각적 인터페이스에서 응답을 분석합니다. Apidog은 응답 시간, 상태 코드 및 토큰 사용량을 포함한 자세한 보고서를 제공합니다. 이 요청을 향후 테스트를 위한 재사용 가능한 시나리오로 저장할 수도 있습니다.

Apidog의 실제 시나리오 시뮬레이션 및 내보낼 수 있는 보고서 생성 기능은 Kimi VL Thinking API와의 상호작용을 디버그하고 최적화하는 데 강력한 도구가 됩니다. 최선의 실행 모범 사례로 마무리하겠습니다.
Kimi VL Thinking을 위한 프롬프트 최적화
Kimi VL Thinking은 단계별 추론에 뛰어나므로 이 기능을 활용할 수 있도록 프롬프트를 구성하세요:
- 추론에 대해 명확히 하기: 모델에 "단계별로 생각해 보세요" 또는 "이 문제를 주의 깊게 추론해 주세요"라고 요청하세요.
- 한 번에 하나의 작업: 복잡한 문제는 한 번에 모두 요청하기보다 관리 가능한 단계로 나누세요.
- 맥락 제공하기: 관련이 있을 경우 모델이 문제를 더 잘 이해하는 데 도움이 될 수 있는 배경 정보를 제공합니다.
- 명확한 지침 사용하기: 모델에게 이미지에서 분석하고자 하는 내용을 정확히 지정하세요.
결론
Kimi VL Thinking은 효율적이면서도 강력한 비주얼 언어 모델에서 인상적인 성과를 나타냅니다. 28억 개의 파라미터만 활성화하면서 고급 추론을 수행할 수 있는 능력 덕분에 전통적인 대형 모델보다 더 넓은 범위의 사용자에게 접근할 수 있습니다.
OpenRouter의 무료 티어를 활용하면 비용 장벽 없이 이 최첨단 기술을 실험할 수 있습니다. 교육 애플리케이션, 데이터 분석 또는 기술 문서 작업을 하는 경우 Kimi VL Thinking은 시각적 콘텐츠에 대한 이해와 추론을 돕는 강력한 도구입니다.
모델에 익숙해지면 더 복잡한 사용 사례를 탐색하고 잠재적으로 이를 생산 애플리케이션에 통합할 수 있습니다. 무료 티어는 실험에 적합하지만 대량의 생산 사용 사례가 있는 경우 더 나은 신뢰성과 성능 보장을 위해 유료 티어로 업그레이드하는 것을 고려할 수 있습니다.
오늘부터 Kimi VL Thinking을 탐색하고 고급 시각적 추론 기능이 귀하의 프로젝트를 어떻게 향상시킬 수 있는지 확인해 보세요!