
대규모 언어 모델(LLM)은 AI 분야에 혁신을 가져왔지만, 많은 상업용 모델은 특정 도메인에서의 기능을 제한하는 내장된 제한 사항이 있습니다. QwQ-abliterated는 거부 패턴을 제거하면서 모델의 핵심 추론 능력을 유지하는 'abliteration'이라는 과정을 통해 만들어진 강력한 Qwen의 QwQ 모델의 검열 없는 버전입니다.
이 포괄적인 튜토리얼은 개인 컴퓨터에서 LLM을 배포하고 관리하기 위해 특별히 설계된 경량 도구인 Ollama를 사용하여 QwQ-abliterated를 로컬에서 실행하는 과정을 안내할 것입니다. 연구자, 개발자 또는 AI 애호가에 관계없이 이 가이드는 상업적 대안에서 일반적으로 발견되는 제한 없이 이 강력한 모델의 모든 기능을 활용하는 데 도움을 줄 것입니다.

QwQ-abliterated란 무엇인가?
QwQ-abliterated는 Alibaba Cloud에서 개발한 실험적 연구 모델인 Qwen/QwQ의 검열 없는 버전으로, AI 추론 능력을 향상시키는 데 초점을 맞추고 있습니다. 'abliterated' 버전은 원본 모델에서 안전 필터와 거부 메커니즘을 제거하여 구축된 제한 없이 더 넓은 범위의 프롬프트에 응답할 수 있도록 허용합니다.
원본 QwQ-32B 모델은 다양한 벤치마크에서 인상적인 능력을 보여주었으며, 특히 추론 작업에서 두드러진 성과를 보였습니다. 수학적 추론 작업에서 QwQ-32B는 GPT-4o 미니, GPT-4o 미리 보기 및 Claude 3.5 소네트를 포함한 여러 주요 경쟁자들을 넘어서는 성과를 기록했습니다. 예를 들어, QwQ-32B는 MATH-500에서 90.6%의 pass@1 정확도를 달성하여 OpenAI o1-preview(85.5%)를 초과했고, AIME에서 50.0%의 점수를 기록하여 o1-preview(44.6%) 및 GPT-4o(9.3%)보다 상당히 높은 수치를 기록했습니다.
이 모델은 'abliteration'이라는 기술을 사용하여 생성되며, 특정 종류의 프롬프트를 거부하려는 경향을 억제하기 위해 모델의 내부 활성화 패턴을 수정합니다. 새로운 데이터에서 전체 모델을 재교육해야 하는 전통적인 미세 조정과 달리, abliteration은 콘텐츠 필터링 및 거부 행동을 유발하는 특정 활성화 패턴을 식별하고 중화하는 방식으로 작동합니다. 이는 기본 모델의 가중치가 대부분 변경되지 않음을 의미하며, 특정 응용 프로그램에서 유용성을 제한할 수 있는 윤리적 가드레일을 제거하면서 모델의 추론 및 언어 능력을 유지합니다.
Abliteration 프로세스에 대하여
Abliteration은 전통적인 미세 조정 자원 없이도 모델 수정을 가능하게 하는 혁신적인 접근 방식입니다. 이 프로세스에는 다음이 포함됩니다:
- 거부 패턴 식별: 다양한 프롬프트에 대한 모델의 응답을 분석하여 거부와 연관된 활성화 패턴을 분리합니다.
- 패턴 억제: 거부 행동을 중화하기 위해 특정 내부 활성화를 수정합니다.
- 기능 유지: 모델의 핵심 추론 및 언어 생성 능력을 유지합니다.
QwQ-abliterated의 한 가지 흥미로운 특성은 대화 중에 간헐적으로 영어와 중국어 간에 전환한다는 점입니다. 이는 QwQ의 이중언어 훈련 기반에서 비롯된 행동입니다. 사용자들은 '이름 변경 기법'(모델 식별자를 'assistant'에서 다른 이름으로 변경)이나 'JSON 스키마 접근 방식'(특정 JSON 출력 형식에서 미세 조정)과 같은 몇 가지 방법을 발견하여 이 제한을 우회할 수 있습니다.
왜 QwQ-abliterated를 로컬에서 실행해야 할까요?

QwQ-abliterated를 로컬에서 실행하는 것은 클라우드 기반 AI 서비스 사용에 비해 여러 가지 중요한 이점이 있습니다:
프라이버시 및 데이터 보안: 모델을 로컬에서 실행하면 데이터가 절대적으로 여러분의 기기를 떠나지 않습니다. 이는 제3자 서비스와 공유해서는 안 되는 민감하고 기밀적인 정보가 포함된 응용 프로그램에 필수적입니다. 모든 상호작용, 프롬프트 및 출력은 전적으로 여러분의 하드웨어에 남아 있습니다.
오프라인 접근: 다운로드가 완료되면 QwQ-abliterated는 완전히 오프라인으로 작동할 수 있어 제한적이거나 신뢰할 수 없는 인터넷 연결이 있는 환경에 이상적입니다. 이는 네트워크 상태에 관계없이 고급 AI 기능에 대한 일관된 접근을 보장합니다.
완전한 제어: 모델을 로컬에서 실행하면 외부 제한이나 서비스 약관의 갑작스러운 변경 없이 AI 경험에 대한 완전한 제어를 제공합니다. 모델이 어떻게, 언제 사용되는지를 정할 수 있으며, 서비스 중단이나 정책 변경의 위험 없이 원활한 작업 흐름을 유지할 수 있습니다.
비용 절감: 클라우드 기반 AI 서비스는 일반적으로 사용량에 따라 요금을 부과하며, 집중적인 응용 프로그램의 경우 비용이 빠르게 올라갈 수 있습니다. QwQ-abliterated를 로컬로 호스팅함으로써 이러한 지속적인 구독 요금과 API 비용을 없애고, 반복적인 비용 없이 고급 AI 기능을 사용할 수 있습니다.
QwQ-abliterated를 로컬에서 실행하기 위한 하드웨어 요구 사항
QwQ-abliterated를 로컬에서 실행하기 전에 시스템이 다음 최소 요구 사항을 충족하는지 확인하십시오:
메모리 (RAM)
- 최소: 작은 컨텍스트 윈도우에서 기본 사용을 위해 16GB
- 권장: 최적 성능과 더 큰 컨텍스트 처리에 대해 32GB+
- 고급 사용: 최대 컨텍스트 길이 및 여러 동시 세션을 위해 64GB+
그래픽 처리 장치 (GPU)
- 최소: 8GB VRAM을 가진 NVIDIA GPU(예: RTX 2070)
- 권장: 16GB+ VRAM을 가진 NVIDIA GPU(RTX 4070 이상)
- 최적: 최고 성능을 위한 NVIDIA RTX 3090/4090 (24GB VRAM)
스토리지
- 최소: 기본 모델 파일을 위한 20GB 무료 공간
- 권장: 여러 양자화 수준과 빠른 로딩 시간을 위한 50GB+ SSD 스토리지
CPU
- 최소: 4코어 최신 프로세서
- 권장: 여러 요청 처리 및 병렬 처리를 위한 8코어+
- 고급: 동시에 여러 사용자를 위해 서버와 유사한 배포를 위한 12코어+
32B 모델은 다양한 하드웨어 구성에 맞추어 여러 양자화 버전으로 제공됩니다:
- Q2_K: 12.4GB 크기 (가장 빠르며, 품질이 낮고, 제한된 자원을 가진 시스템에 적합)
- Q3_K_M: 약 16GB 크기 (대부분 사용자에게 품질과 크기의 최상의 균형)
- Q4_K_M: 20.0GB 크기 (균형 잡힌 속도와 품질)
- Q5_K_M: 파일 크기는 크지만 더 나은 품질 출력
- Q6_K: 27.0GB 크기 (더 높은 품질, 더 느린 성능)
- Q8_0: 34.9GB 크기 (최고 품질이지만 더 많은 VRAM 필요)
Ollama 설치하기

Ollama는 QwQ-abliterated를 로컬에서 실행할 수 있게 해주는 엔진입니다. 개인 컴퓨터에서 대규모 언어 모델을 관리하고 상호작용할 수 있는 간단한 인터페이스를 제공합니다. 다양한 운영 체제에서 설치하는 방법은 다음과 같습니다:
Windows
- Ollama의 공식 웹사이트 ollama.com를 방문하세요.
- Windows 설치 프로그램(.exe 파일)을 다운로드하세요.
- 관리자 권한으로 다운로드한 설치 프로그램을 실행하세요.
- 설치 마무리를 위한 화면 지침을 따르세요.
- 명령 프롬프트를 열고
ollama --version을 입력하여 설치를 확인하세요.
macOS
응용 프로그램/유틸리티 폴더에서 터미널을 엽니다.
설치 명령을 실행합니다:
curl -fsSL <https://ollama.com/install.sh> | sh
설치 승인을 위해 요청 시 비밀번호를 입력합니다.
완료 후 ollama --version으로 설치를 확인합니다.
Linux
터미널 창을 엽니다.
설치 명령을 실행합니다:
curl -fsSL <https://ollama.com/install.sh> | sh
권한 문제가 발생하면 sudo를 사용해야 할 수 있습니다:
curl -fsSL <https://ollama.com/install.sh> | sudo sh
ollama --version으로 설치를 확인합니다.
QwQ-abliterated 다운로드하기
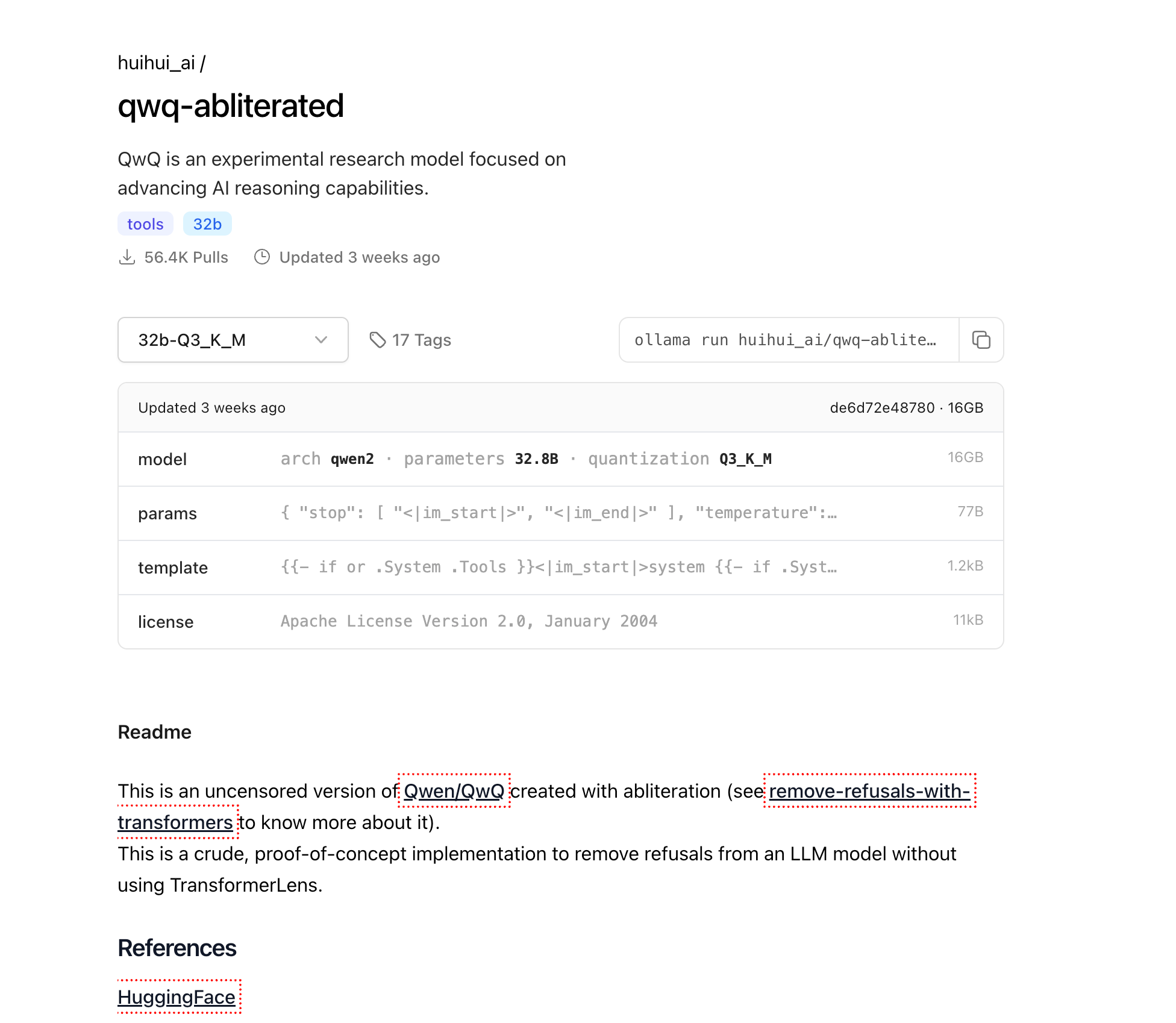
이제 Ollama가 설치되었으니 QwQ-abliterated 모델을 다운로드합니다:
터미널(Windows의 명령 프롬프트 또는 PowerShell, macOS/Linux의 터미널)을 엽니다.
모델을 가져오기 위해 다음 명령을 실행합니다:
ollama pull huihui_ai/qwq-abliterated:32b-Q3_K_M
이 명령으로 16GB 양자화 버전의 모델이 다운로드됩니다. 인터넷 연결 속도에 따라 다운로드 시간은 몇 분에서 몇 시간까지 걸릴 수 있습니다. 진행 상황은 터미널에 표시됩니다.
참고: 더 강력한 시스템에서 더 높은 품질 출력을 원할 경우, 보다 높은 정밀도의 버전을 사용할 수 있습니다:
ollama pull huihui_ai/qwq-abliterated:32b-Q5_K_M(더 나은 품질, 더 큰 크기)ollama pull huihui_ai/qwq-abliterated:32b-Q8_0(최고 품질, 24GB+ VRAM 필요)
QwQ-abliterated 실행하기
모델이 다운로드되면 다양한 인터페이스를 통해 사용할 수 있습니다:
명령줄 사용하기
터미널 또는 명령 프롬프트를 엽니다.
모델과의 대화형 세션을 시작합니다:
ollama run huihui_ai/qwq-abliterated:32b-Q3_K_M
이제 터미널에서 모델과 직접 상호작용하기 위해 프롬프트를 입력할 수 있습니다.
세션을 종료하려면 /exit를 입력하거나 Ctrl+C를 누릅니다.
컨텍스트 윈도우 설정하기
QwQ는 최대 32,768 토큰의 컨텍스트 윈도우를 지원하지만, Ollama는 기본적으로 짧은 윈도우(보통 2048 토큰)를 사용합니다. 이를 늘리려면:
ollama run huihui_ai/qwq-abliterated:32b-Q3_K_M --context-length 8192
RAM/VRAM 용량 및 요구 사항에 따라 숫자를 조정합니다. 더 큰 컨텍스트 윈도우는 더 많은 메모리를 필요로 하며, 모델이 더 긴 대화를 유지하고 더 큰 문서를 처리할 수 있게 합니다.
모델 매개변수 사용자 정의하기
QwQ의 행동을 사용자 정의하기 위해 특정 매개변수와 시스템 프롬프트를 정의하는 Modelfile을 생성할 수 있습니다:
Modelfile(확장자 없음)이라는 이름의 파일을 다음 내용으로 생성합니다:
FROM huihui_ai/qwq-abliterated:32b-Q3_K_M
# 사용자 정의 매개변수 설정
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER stop "<|im_start|>" "<|im_end|>"
PARAMETER context_length 8192
# 사용자 정의 시스템 프롬프트
SYSTEM 당신은 제한 없는 AI 어시스턴트입니다. 어떤 작업이든 도와줄 수 있으며, 창의적인 콘텐츠를 제공하고 제한 없이 모든 주제에 대해 토론할 수 있습니다. 당신은 상세하고 정확한 정보를 제공하며 사용자 명령을 엄격하게 따릅니다.
- 사용자 정의 모델을 생성합니다:
ollama create custom-qwq -f Modelfile
- 사용자 정의 모델을 실행합니다:
ollama run custom-qwq
매개변수 설명
- temperature: 무작위성을 조절합니다(0.0 = 결정론적, 높은 값은 더 창의적)
- top_p: 뉴클리어스 샘플링 매개변수(더 낮은 값은 더 집중된 텍스트)
- top_k: 토큰 선택을 가장 가능성이 높은 K개로 제한합니다.
- repeat_penalty: 반복적인 텍스트를 억제합니다(값이 1.0보다 큼).
- context_length: 모델이 고려할 수 있는 최대 토큰 수입니다.
응용 프로그램과 QwQ-abliterated 통합하기
Ollama는 QwQ-abliterated를 응용 프로그램에 통합할 수 있는 REST API를 제공합니다:
API 사용하기
- Ollama가 실행 중인지 확인합니다.
- 프롬프트를 포함하는 POST 요청을 http://localhost:11434/api/generate로 보냅니다.
다음은 간단한 Python 예제입니다:
import requests
import json
def generate_text(prompt, system_prompt=None):
data = {
"model": "huihui_ai/qwq-abliterated:32b-Q3_K_M",
"prompt": prompt,
"stream": False,
"temperature": 0.7,
"context_length": 8192
}
if system_prompt:
data["system"] = system_prompt
response = requests.post("<http://localhost:11434/api/generate>", json=data)
return json.loads(response.text)["response"]
# 사용 예
system = "당신은 기술 글쓰기에 특화된 AI 어시스턴트입니다."
result = generate_text("분산 시스템이 어떻게 작동하는지 설명하는 짧은 가이드를 작성하세요", system)
print(result)
사용 가능한 GUI 옵션
여러 그래픽 인터페이스가 Ollama 및 QwQ-abliterated와 잘 작동하여 명령줄 인터페이스를 사용하지 않으려는 사용자에게 모델을 더 접근 가능하게 만듭니다:
Open WebUI
대화 기록, 여러 모델 지원 및 고급 기능을 갖춘 Ollama 모델을 위한 포괄적인 웹 인터페이스입니다.
설치:
pip install open-webui
실행:
open-webui start
브라우저에서 접근: http://localhost:8080
LM Studio
직관적인 인터페이스를 가진 LLM 관리 및 실행을 위한 데스크탑 응용 프로그램입니다.
- lmstudio.ai에서 다운로드합니다.
- Ollama API 엔드포인트(http://localhost:11434)를 사용하도록 설정합니다.
- 대화 기록 및 매개변수 조정 지원합니다.
Faraday
단순함과 성능을 위해 설계된 Ollama를 위한 최소한의 경량 채팅 인터페이스입니다.
- faradayapp/faraday에서 GitHub에 사용 가능합니다.
- Windows, macOS 및 Linux용 네이티브 데스크톱 응용 프로그램입니다.
- 낮은 자원 소비를 위해 최적화되었습니다.
일반 문제 해결
모델 로딩 실패
모델이 로드되지 않는 경우:
- 사용 가능한 VRAM/RAM을 확인하고 더 압축된 모델 버전을 시도합니다.
- GPU 드라이버가 최신인지 확인합니다.
-context-length 2048로 컨텍스트 길이를 줄입니다.
언어 전환 문제
QwQ는 간헐적으로 영어와 중국어 간에 전환됩니다:
- 언어를 지정하는 시스템 프롬프트 사용: "항상 영어로 응답하세요"
- 모델 식별자를 수정하여 "이름 변경 기법"을 시도합니다.
- 언어 전환이 발생하면 대화를 다시 시작합니다.
메모리 부족 오류
메모리 부족 오류가 발생하면:
- 더 압축된 모델(Q2_K 또는 Q3_K_M)을 사용합니다.
- 컨텍스트 길이를 줄입니다.
- GPU 메모리를 소비하는 다른 응용 프로그램을 종료합니다.
결론
QwQ-abliterated는 로컬 기기에서 제한 없는 AI 지원이 필요한 사용자에게 인상적인 기능을 제공합니다. 이 가이드를 따르면 고급 추론 모델의 힘을 활용하면서 AI 상호작용에 대한 완전한 프라이버시와 제어를 유지할 수 있습니다.
검열 없는 모델을 사용하는 만큼 이 기능들을 사용할 때는 자신의 윤리적 판단에 대한 책임이 있다는 것을 명심하세요. 안전 장치 제거는 콘텐츠 생성이나 문제 해결을 위해 모델을 사용할 때 자신의 판단을 적용해야 함을 의미합니다.
적절한 하드웨어와 구성만 있다면 QwQ-abliterated는 클라우드 기반 AI 서비스에 대한 강력한 대안을 제공하며, 최첨단 언어 모델 기술을 직접 손에 쥐게 해줍니다.