
로컬 머신에서 강력한 언어 모델을 실행해 보고 싶으신가요? 알리바바의 최신이자 가장 강력한 LLM QwQ-32B를 소개합니다. 개발자, 연구원, 또는 단순히 호기심 많은 기술 애호가라면, QwQ-32B를 로컬에서 실행하면 맞춤형 AI 애플리케이션 구축부터 고급 자연어 처리 작업 실험까지 다양한 가능성을 열 수 있습니다.
이 가이드에서는 전체 과정을 단계별로 안내합니다. Ollama 및 LM Studio와 같은 도구를 사용하여 설치 과정을 가능한 한 원활하게 진행하겠습니다.
Ollama와 함께 API 테스트 도구를 사용하고 싶다면 Apidog를 꼭 확인해 보세요. API 워크플로를 간소화하는 환상적인 도구이며, 가장 좋은 점은 무료로 다운로드할 수 있다는 것입니다!
준비되셨나요? 시작해 봅시다!
1. QwQ-32B 이해하기
기술적 세부 사항으로 들어가기 전에 QwQ-32B가 무엇인지 잠시 이해해 봅시다. QwQ-32B는 320억 개의 매개 변수를 가진 최첨단 언어 모델로, 텍스트 생성, 번역, 요약과 같은 복잡한 자연어 작업을 처리하도록 설계되었습니다. AI의 경계를 확장하려는 개발자와 연구자에게 다재다능한 도구입니다.
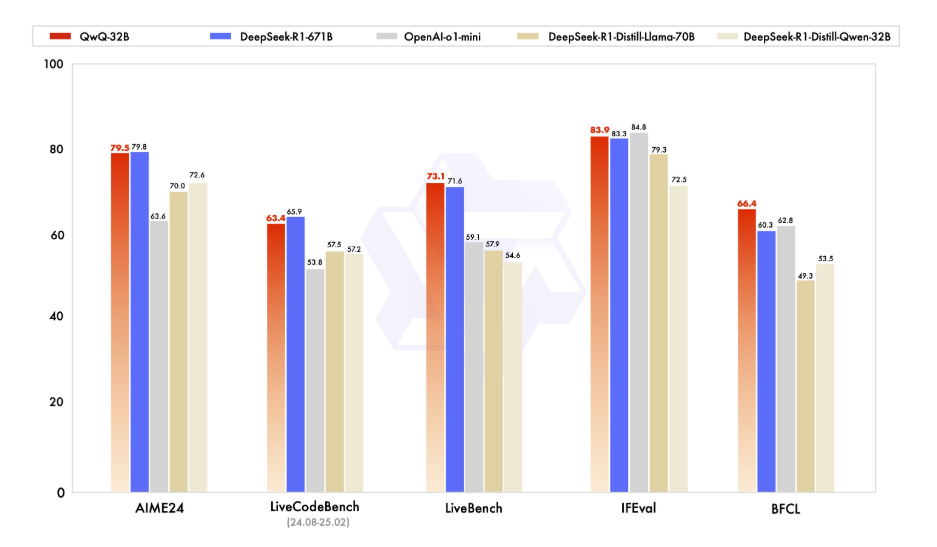
QwQ-32B를 로컬에서 실행하면 모델에 대한 완전한 제어가 가능하여 클라우드 기반 서비스에 의존하지 않고 특정 사용 사례에 맞게 사용자 정의할 수 있습니다. 개인정보 보호, 사용자 정의, 비용 효율성, 오프라인 접근은 이 모델을 로컬에서 실행할 때 누릴 수 있는 많은 기능 중 일부입니다.
2. 필수 요건
QwQ-32B를 로컬에서 실행하기 위해서는 다음 요구 사항을 충족해야 합니다:
- 하드웨어: 최소 16GB의 RAM과 최소 24GB의 VRAM을 가진 고급 GPU(예: NVIDIA RTX 3090 이상)가 장착된 강력한 머신이 필요합니다.
- 소프트웨어: Python 3.8 이상의 버전, Git, pip 또는 conda와 같은 패키지 관리자.
- 도구: Ollama 및 LMStudio (자세한 내용은 나중에 다룰 것입니다).
3. Ollama를 사용하여 QwQ-32B 로컬에서 실행하기
Ollama는 대형 언어 모델을 로컬에서 실행하는 과정을 간소화하는 경량 프레임워크입니다. 설치하는 방법은 다음과 같습니다:
1단계: Ollama 다운로드 및 설치:
- Windows 및 macOS 용으로, Ollama 공식 웹사이트에서 실행 파일을 다운로드하고 실행하여 설치합니다. 그런 다음 설치 설정에서 제공하는 간단한 설치 지침을 따르세요.
- 리눅스 사용자는 다음 명령을 사용할 수 있습니다:
curl -fsSL https://ollama.ai/install.sh | sh
- 설치 확인: 설치 후, Ollama가 제대로 설치되었는지 확인하려면 터미널을 열고 다음을 실행하세요:
ollama --version
- 설치가 성공적이라면 버전 번호가 표시됩니다.
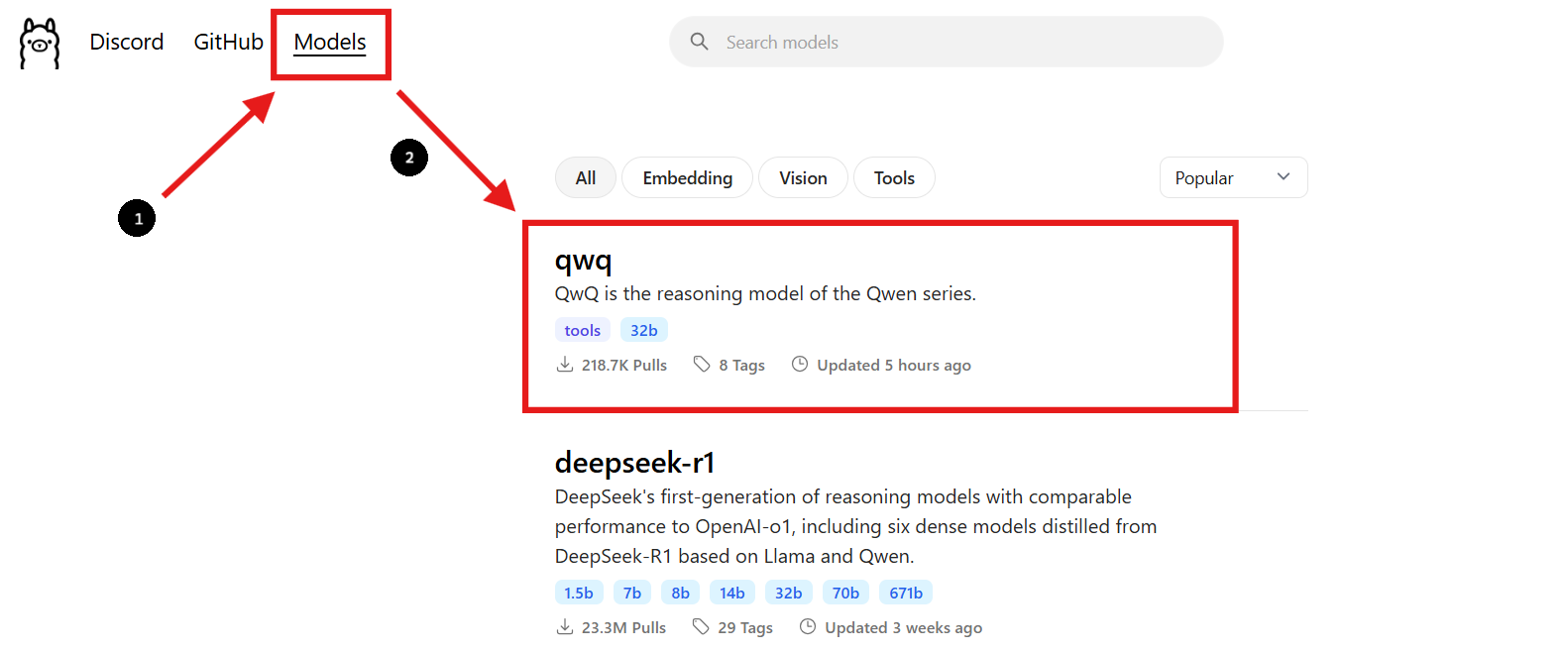
2단계: QwQ-32B 모델 찾기
- Ollama 웹사이트로 돌아가서 "모델" 섹션으로 이동합니다.
- 검색창에 "QwQ-32B"를 입력합니다.
- QwQ-32B 모델을 찾으면, 페이지에 제공된 설치 명령어를 볼 수 있습니다.
3단계: QwQ-32B 모델 다운로드
- 새 터미널 창을 열어 모델을 다운로드하고 다음 명령을 실행하세요:
ollama pull qwq:32b- 다운로드가 완료되면, 다음 명령을 실행하여 모델이 설치되었는지 확인할 수 있습니다:
ollama list
- 이 명령은 Ollama를 사용하여 다운로드한 모든 모델을 나열하여 QwQ-32B가 사용 가능함을 확인합니다.
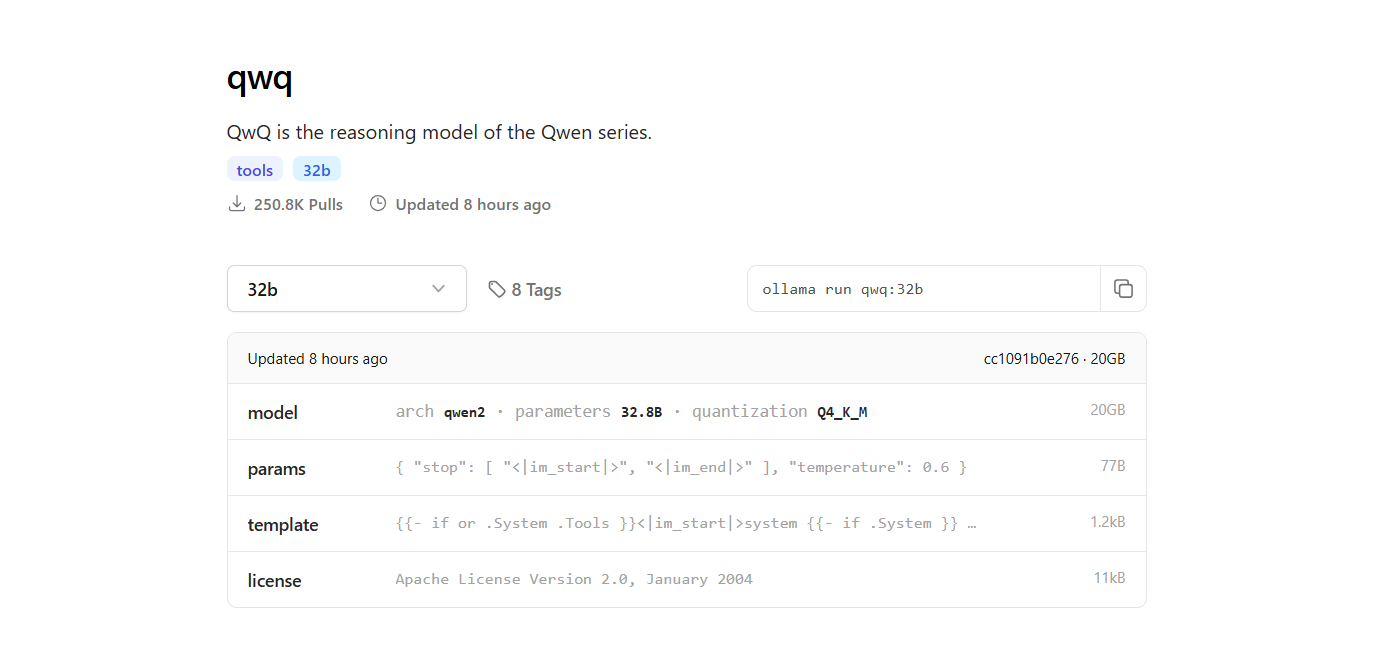
4단계: QwQ-32B 모델 실행하기
터미널에서 모델 실행:
- QwQ-32B 모델과 직접 상호작용하려면 터미널에서 다음 명령을 사용하세요:
ollama run qwq:32b
- 터미널에서 질문이나 프롬프트를 입력하면 모델이 이에 맞춰 응답합니다.
인터랙티브 채팅 인터페이스 사용하기:
- 대안으로, Chatbox나 OpenWebUI와 같은 도구를 사용하여 QwQ-32B 모델과 채팅할 수 있는 인터랙티브 GUI를 만들 수 있습니다.
- 이러한 인터페이스는 명령줄 인터페이스보다 그래픽 인터페이스를 선호하는 경우 모델과 상호작용하는 보다 사용자 친화적인 방법을 제공합니다.
4. LM Studio를 사용하여 QwQ-32B 로컬에서 실행하기
LM Studio는 로컬에서 언어 모델을 실행하고 관리하기 위한 사용자 친화적인 인터페이스입니다. 설정 방법은 다음과 같습니다:
1단계: LM Studio 다운로드:
- 먼저, lmstudio.ai의 공식 LM Studio 웹사이트를 방문하세요. 여기서 운영 체제에 맞는 LM Studio 애플리케이션을 다운로드할 수 있습니다.
- 페이지에서 다운로드 섹션으로 이동하여 운영 체제(Windows, macOS 또는 Linux)에 맞는 버전을 선택합니다.
2단계: LM Studio 설치:
- 운영 체제에 맞는 간단한 설치 지침을 따르세요.
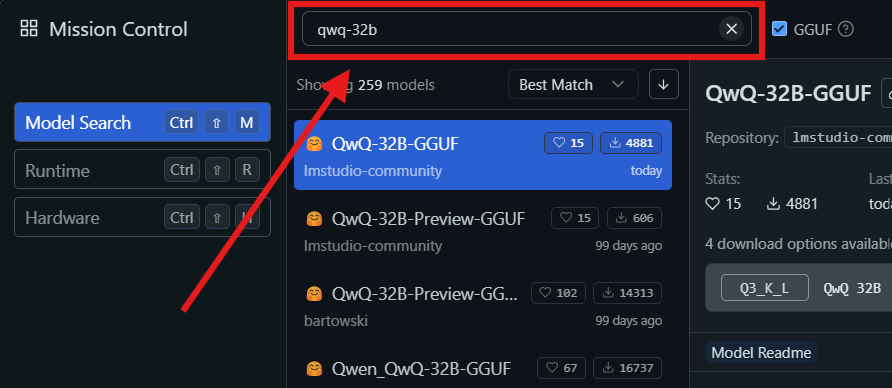
3단계: QwQ-32B 모델 찾고 다운로드하기:
- LM Studio를 열고 "내 모델" 섹션으로 이동합니다.
- 검색 아이콘을 클릭하고 검색창에 "QwQ-32B"를 입력합니다.
- 검색 결과에서 원하는 QwQ-32B 모델 버전을 선택합니다. 성능을 유지하면서 메모리 사용량을 줄일 수 있는 4비트 양자화 모델과 같은 다양한 양자화 버전을 찾을 수 있습니다.
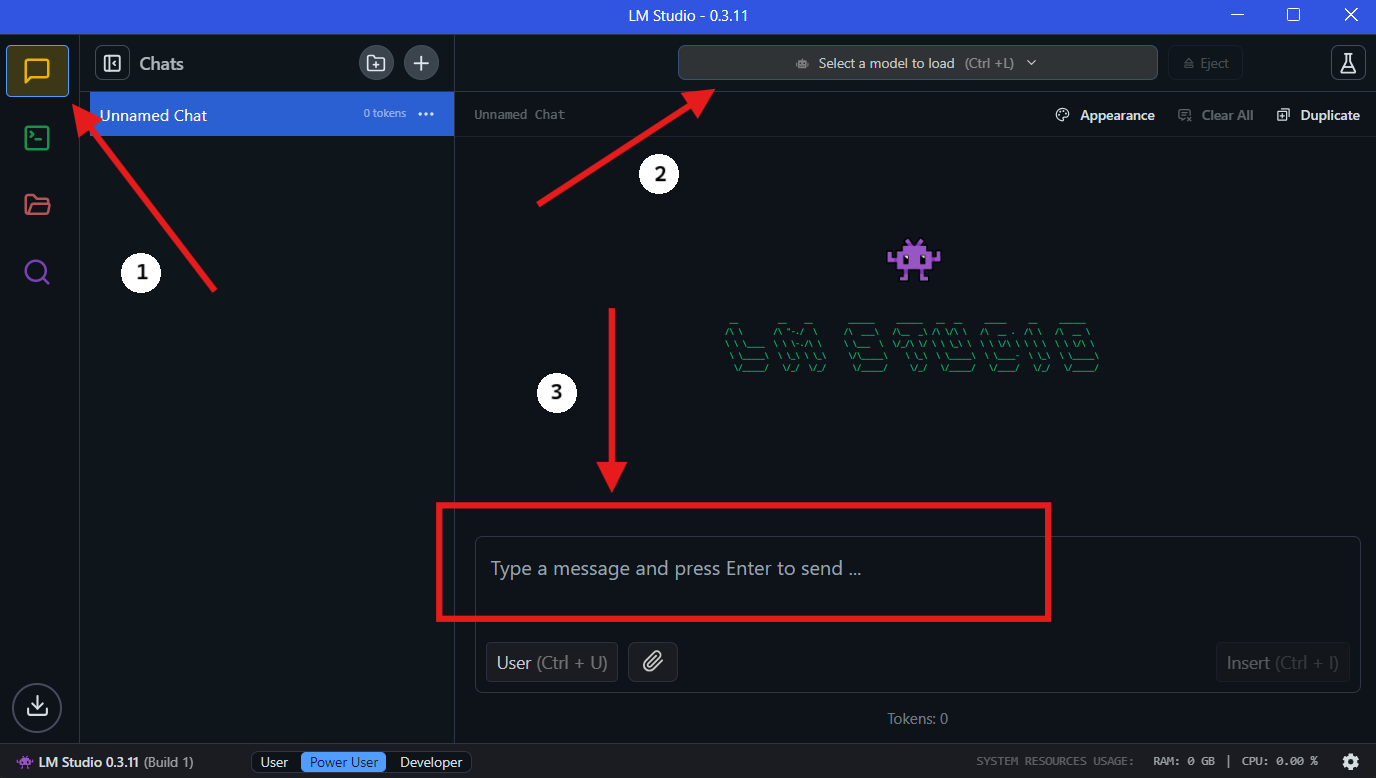
4단계: LM Studio에서 QwQ-32B 로컬 실행하기
- 모델 선택: 다운로드가 완료되면 LM Studio의 "채팅" 섹션으로 이동합니다. 채팅 인터페이스에서 드롭다운 메뉴에서 QwQ-32B 모델을 선택합니다.
- QwQ-32B와 상호작용: 채팅 창에서 질문을 하거나 프롬프트를 제공하기 시작합니다. 모델이 귀하의 입력을 처리하고 응답을 생성합니다.
- 설정 구성: "고급 구성 탭"에서 원하는 대로 모델 설정을 조정할 수 있습니다.
5. Apidog으로 API 개발 간소화하기
QwQ-32B를 애플리케이션에 통합하려면 효율적인 API 관리가 필요합니다. Apidog은 이 과정을 간소화하는 올인원 협업 API 개발 플랫폼입니다. Apidog의 주요 기능에는 API 디자인, API 문서화, API 디버깅이 포함됩니다. QwQ-32B와 함께 API를 관리하고 테스트하기 위한 Apidog 설정을 원활하게 하려면 다음 단계를 따르세요.

1단계: Apidog 다운로드 및 설치
- Apidog 공식 웹사이트를 방문하여 운영 체제(Windows, macOS 또는 Linux)에 호환되는 버전을 다운로드합니다.
- 설치 지침을 따라 Apidog를 머신에 설정합니다.
2단계: 새 API 프로젝트 만들기
- Apidog를 열고 새 API 프로젝트를 만듭니다.
- API 엔드포인트를 정의하고 QwQ-32B와 상호작용하기 위한 요청 및 응답 형식을 지정합니다.
3단계: 로컬 API를 통해 Apidog에 QwQ-32B 연결하기
API를 통해 QwQ-32B와 상호작용하려면 로컬 서버를 사용하여 모델을 노출해야 합니다. FastAPI 또는 Flask를 사용하여 로컬 QwQ-32B 모델에 대한 API를 생성하세요.
예제: QwQ-32B를 위한 FastAPI 서버 설정:
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# Run with: uvicorn script_name:app --reload
4단계: Apidog로 API 호출 테스트하기
- Apidog를 열고 POST 요청을
http://localhost:8000/generate로 만듭니다. - 요청 본문에 샘플 프롬프트를 입력하고 "전송"을 클릭합니다.
- 모든 것이 올바르게 구성되었다면, QwQ-32B로부터 생성된 응답을 받아볼 수 있습니다.
5단계: API 테스트 및 디버깅 자동화하기
- Apidog의 내장 테스트 기능을 사용하여 다양한 입력을 시뮬레이션하고 QwQ-32B가 어떻게 응답하는지 분석합니다.
- 요청 매개 변수를 조정하고 응답 시간을 모니터링하여 API 성능을 최적화합니다.
🚀 Apidog를 사용하면 API 워크플로 관리가 수월해져 QwQ-32B와 애플리케이션 간의 원활한 통합을 보장합니다.
6. 성능 최적화를 위한 팁
320억 개의 매개 변수를 가진 모델을 실행하는 것은 자원 집약적일 수 있습니다. 다음은 성능을 최적화하기 위한 몇 가지 팁입니다:
- 고급 GPU 사용: 강력한 GPU는 추론 속도를 크게 향상시킵니다.
- 배치 크기 조절: 최적의 설정을 찾기 위해 다양한 배치 크기로 실험합니다.
- 자원 사용 모니터링:
htop또는nvidia-smi와 같은 도구를 사용하여 CPU 및 GPU 사용량을 모니터링합니다.
7. 일반적인 문제 해결
QwQ-32B를 로컬에서 실행하는 것이 때때로 까다로울 수 있습니다. 다음은 몇 가지 일반적인 문제와 해결 방법입니다:
- 메모리 부족: 배치 크기를 줄이거나 하드웨어를 업그레이드하세요.
- 느린 성능: GPU 드라이버가 최신인지 확인하세요.
- 모델이 로드되지 않음: 모델 경로와 파일 무결성을 다시 확인하세요.
8. 최종 생각
QwQ-32B를 로컬에서 실행하는 것은 클라우드 서비스에 의존하지 않고 고급 AI 모델의 기능을 활용하는 강력한 방법입니다. Ollama 및 LM Studio와 같은 도구를 사용하면 이 과정이 그 어느 때보다 접근하기 쉬워집니다.
또한 API 작업을 진행하신다면 Apidog가 테스트 및 문서화에 적합한 도구입니다. 무료로 다운로드하여 API 워크플로를 한 단계 업그레이드하세요!