

고가의 클라우드 서비스에 의존하거나 데이터 프라이버시에 대해 걱정할 필요 없이, 자신의 기기에서 정교한 AI 비전 모델을 직접 실행하고 싶었던 적이 있으신가요? 운이 좋으시네요! 오늘은 Ollama를 사용하여 Qwen 3 VL(Vision Language) 모델을 로컬에서 실행하는 방법에 대해 자세히 알아보겠습니다. 이 방법은 AI 개발 워크플로우에 혁신을 가져올 것입니다.
기술적인 내용으로 들어가기 전에 한 가지 여쭤보겠습니다. API 호출 제한에 부딪히거나, 클라우드 추론에 막대한 비용을 지불하거나, 단순히 AI 모델에 대한 더 많은 제어를 원하셨던 적이 있으신가요? 만약 그렇다면, 이 가이드는 바로 당신을 위해 작성되었습니다. 또한, 로컬 AI API를 테스트하고 디버깅할 강력한 도구를 찾고 있다면, Apidog를 무료로 다운로드하는 것을 강력히 추천합니다. Ollama의 로컬 엔드포인트와 완벽하게 작동하는 훌륭한 API 테스트 플랫폼입니다.
이 가이드에서는 설치부터 추론, 문제 해결, 그리고 Apidog와 같은 도구와의 통합까지 Ollama를 사용하여 Qwen 3 VL 모델을 로컬에서 실행하는 데 필요한 모든 것을 단계별로 설명합니다. 이 포괄적인 가이드가 끝날 때쯤이면, 여러분은 완전히 기능하고, 사적이며, 반응성이 뛰어난 비전-언어 Qwen3-VL을 로컬 머신에서 원활하게 실행할 수 있게 될 것이며, 프로젝트에 통합하는 데 필요한 모든 지식을 갖추게 될 것입니다.
그러니, 안전벨트를 매고, 좋아하는 음료를 들고, 이 흥미진진한 여정을 함께 시작해 봅시다.
Qwen3-VL 이해하기: 혁신적인 비전-언어 모델

왜 Qwen 3 VL인가? 그리고 왜 로컬에서 실행해야 하는가?
기술적인 단계로 넘어가기 전에, 왜 Qwen 3 VL이 중요한지, 그리고 왜 로컬에서 실행하는 것이 혁신적인지에 대해 이야기해 봅시다.
Qwen 3 VL은 Alibaba의 Qwen 시리즈의 일부이지만, 특히 비전-언어 작업을 위해 설계되었습니다. 텍스트만 이해하는 기존 LLM과 달리 Qwen 3 VL은 다음을 수행할 수 있습니다.
- 이미지를 분석하고 이미지에 대한 질문에 답하기("이 사진에 무엇이 있나요?")
- 상세한 캡션 생성
- 차트, 다이어그램 또는 문서에서 구조화된 데이터 추출
- 시각적 맥락을 포함한 멀티모달 RAG(검색 증강 생성) 지원
그리고 오픈 가중치(Tongyi Qianwen 라이선스 하에)이기 때문에 개발자는 라이선스 조건을 준수하는 한 자유롭게 사용, 수정 및 배포할 수 있습니다.
그렇다면 로컬에서 실행하는 이유는 무엇일까요?
- 프라이버시: 이미지와 프롬프트가 여러분의 기기를 떠나지 않습니다.
- 비용: API 수수료나 사용량 제한이 없습니다.
- 맞춤화: 미세 조정, 양자화 또는 자체 파이프라인과 통합.
- 오프라인 액세스: 보안 또는 에어갭 환경에 적합합니다.
하지만 로컬 배포는 CUDA 버전, Python 환경, 그리고 거대한 Dockerfile과의 씨름을 의미했습니다. 여기에 Ollama가 등장합니다.
모델 변형: 모든 사용 사례에 맞는 모델
Qwen3-VL은 다양한 하드웨어 구성과 사용 사례에 맞춰 다양한 크기로 제공됩니다. 가벼운 노트북으로 작업하든 강력한 워크스테이션에 접근할 수 있든, 여러분의 필요에 완벽하게 맞는 Qwen3-VL 모델이 있습니다.
밀집 모델 (전통적인 아키텍처):
- Qwen3-VL-2B: 엣지 장치 및 모바일 애플리케이션에 적합
- Qwen3-VL-4B: 성능과 리소스 사용량의 훌륭한 균형
- Qwen3-VL-8B: 적당한 추론 능력을 가진 일반적인 작업에 탁월
- Qwen3-VL-32B: 강력한 추론 능력과 광범위한 컨텍스트를 요구하는 고급 작업
전문가 혼합(MoE) 모델 (효율적인 아키텍처):
- Qwen3-VL-30B-A3B: 30억 개의 활성 매개변수만으로 효율적인 성능
- Qwen3-VL-235B-A22B: 총 2350억 개의 매개변수 중 220억 개만 활성 상태로 대규모 애플리케이션에 적합
MoE 모델의 장점은 각 추론에 대해 "전문가" 신경망의 하위 집합만 활성화하여, 대규모 매개변수 수를 유지하면서 계산 비용을 관리할 수 있다는 점입니다.
Ollama: 로컬 AI 우수성으로 가는 관문
이제 Qwen3-VL이 무엇을 제공하는지 이해했으니, 이 모델들을 로컬에서 실행하는 데 Ollama가 왜 이상적인 플랫폼인지 이야기해 봅시다. Ollama를 오케스트라의 지휘자로 생각해보세요. 복잡한 모든 백그라운드 프로세스를 조율하여 여러분은 가장 중요한 것, 즉 AI 모델을 사용하는 것에 집중할 수 있도록 합니다.
Ollama란 무엇이며 Qwen 3 VL에 완벽한 이유는 무엇인가?
Ollama는 단일 명령으로 대규모 언어 모델(그리고 이제 멀티모달 모델)을 로컬에서 실행할 수 있게 해주는 오픈 소스 도구입니다. "LLM을 위한 Docker"라고 생각할 수 있지만 훨씬 더 간단합니다.
주요 기능:
- 자동 GPU 가속 (macOS에서는 Metal, Linux에서는 CUDA를 통해)
- 내장 모델 라이브러리 (Llama 3, Mistral, Gemma, 그리고 이제 Qwen 포함)
- 쉬운 통합을 위한 REST API
- 경량이며 초보자 친화적
무엇보다도, Ollama는 이제 Qwen 3 VL 모델을 지원합니다. 여기에는 qwen3-vl:4b 및 qwen3-vl:8b와 같은 변형이 포함됩니다. 이들은 로컬 하드웨어에 최적화된 양자화된 버전으로, 소비자용 GPU 또는 강력한 노트북에서도 실행할 수 있음을 의미합니다.
Ollama 뒤에 숨겨진 기술적 마법
Ollama 명령을 실행할 때 백그라운드에서 어떤 일이 일어날까요? 잘 안무된 기술 프로세스의 춤을 보는 것과 같습니다.
1.모델 다운로드 및 캐싱: Ollama는 모델 가중치를 지능적으로 다운로드하고 캐시하여 자주 사용되는 모델의 빠른 시작 시간을 보장합니다.
2.양자화 최적화: 모델은 하드웨어 구성에 맞게 자동으로 최적화되며, GPU 및 RAM에 가장 적합한 양자화 방법(4비트, 8비트 등)을 선택합니다.
3.메모리 관리: 고급 메모리 매핑 기술은 높은 성능을 유지하면서 효율적인 GPU 메모리 사용을 보장합니다.
4.병렬 처리: Ollama는 최대 처리량을 위해 여러 CPU 코어와 GPU 스트림을 활용합니다.
사전 요구 사항: 설치 전에 필요한 것
무엇이든 설치하기 전에 시스템이 준비되었는지 확인해 봅시다.
하드웨어 요구 사항
- RAM: 최소 16GB (8B 모델의 경우 32GB 권장)
- GPU: 8GB 이상의 VRAM을 가진 NVIDIA GPU (Linux용) 또는 Apple Silicon Mac (16GB 이상의 통합 메모리를 가진 M1/M2/M3)
- 저장 공간: 10–20GB의 여유 공간 (모델이 큽니다!)
소프트웨어 요구 사항
- 운영 체제: macOS (12 이상) 또는 Linux (Ubuntu 20.04 이상 권장)
- Ollama: 최신 버전 (Qwen 3 VL 지원을 위한 v0.1.40 이상)
- 선택 사항: Docker (컨테이너화된 배포를 선호하는 경우), Python (고급 스크립팅용)
단계별 설치 가이드: 로컬 AI 마스터리로 가는 길
1단계: Ollama 설치 - 기반 다지기
전체 설정의 기반부터 시작하겠습니다. Ollama 설치는 놀랍도록 간단합니다. AI 초보자부터 숙련된 개발자까지 모든 사람이 접근할 수 있도록 설계되었습니다.
macOS 사용자용:
1.ollama.com/download 방문
2.macOS 설치 프로그램 다운로드
3.다운로드한 파일을 열고 Ollama를 응용 프로그램 폴더로 드래그
4.응용 프로그램 폴더 또는 Spotlight 검색에서 Ollama 실행
macOS에서의 설치 과정은 매우 원활하며, 설치가 완료되면 메뉴 바에 Ollama 아이콘이 나타납니다.
Windows 사용자용:
1.ollama.com/download로 이동
2.Windows 설치 프로그램(.exe 파일) 다운로드
3.관리자 권한으로 설치 프로그램 실행
4.설치 마법사 따르기 (매우 직관적입니다)
5.설치 후 Ollama는 백그라운드에서 자동으로 시작됩니다
Windows 사용자는 Windows Defender 알림을 볼 수 있습니다. 첫 실행 시에는 정상적인 현상이니 걱정하지 마세요. "허용"을 클릭하면 Ollama가 완벽하게 작동합니다.
Linux 사용자용:
Linux 사용자는 두 가지 옵션이 있습니다.
옵션 A: 설치 스크립트 (권장)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
옵션 B: 수동 설치
bash
# 최신 Ollama 바이너리 다운로드curl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# 실행 가능하게 만들기chmod +x ollama
# PATH로 이동sudo mv ollama /usr/local/bin/
2단계: 설치 확인
이제 Ollama가 설치되었으니 모든 것이 제대로 작동하는지 확인해 봅시다. 이것을 우리의 기반이 견고한지 확인하는 간단한 테스트라고 생각하세요.
터미널(또는 Windows의 명령 프롬프트)을 열고 다음을 실행하세요:
bash
ollama --version
다음과 유사한 출력을 볼 수 있을 것입니다:
ollama version is 0.1.0
다음으로, 기본 기능을 테스트해 봅시다:
bash
ollama serve
이 명령은 Ollama 서버를 시작합니다. 서버가 http://localhost:11434에서 실행 중임을 나타내는 출력을 볼 수 있을 것입니다. 서버를 계속 실행해 두세요. Qwen3-VL 설치를 테스트하는 데 사용할 것입니다.
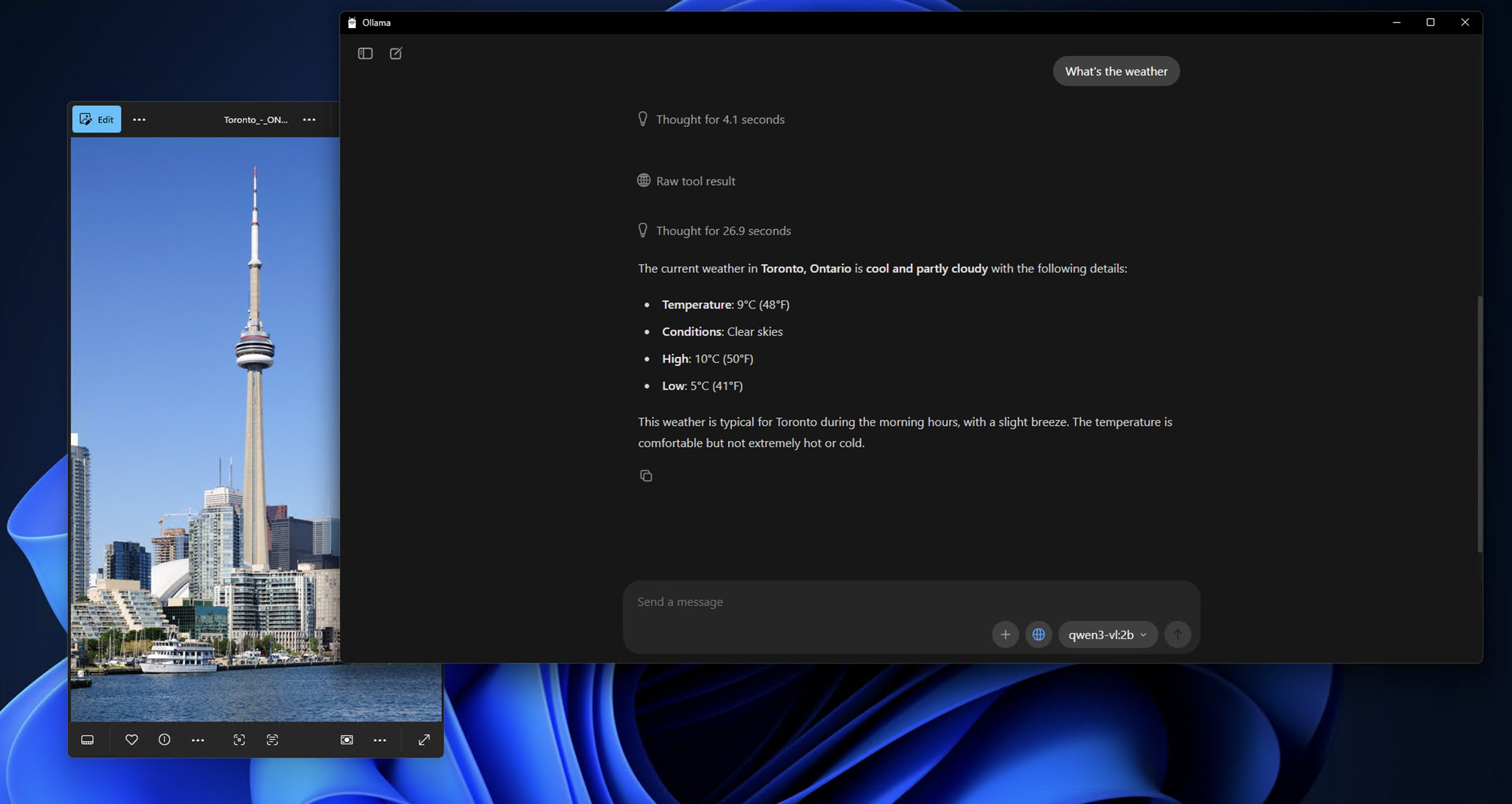
3단계: Qwen3-VL 모델 가져오기 및 실행
이제 흥미로운 부분입니다! 첫 번째 Qwen3-VL 모델을 다운로드하고 실행해 봅시다. 먼저 작은 모델로 테스트를 시작한 다음, 더 강력한 변형으로 넘어갈 것입니다.
Qwen3-VL-4B로 테스트 (훌륭한 시작점):
bash
ollama run qwen3-vl:4b
이 명령은 다음을 수행합니다:
1.Qwen3-VL-4B 모델 다운로드 (약 2.8GB)
2.하드웨어에 맞게 최적화
3.대화형 채팅 세션 시작
다른 모델 변형 실행:
더 강력한 하드웨어가 있다면 다음 대안을 시도해 보세요:
bash
# 8GB+ GPU 시스템용ollama run qwen3-vl:8b
# 16GB+ RAM 시스템용ollama run qwen3-vl:32b
# 여러 GPU가 있는 하이엔드 시스템용ollama run qwen3-vl:30b-a3b
# 최대 성능용 (심각한 하드웨어 필요)ollama run qwen3-vl:235b-a22b
4단계: 로컬 Qwen3-VL과의 첫 상호 작용
모델이 다운로드되고 실행되면 다음과 같은 프롬프트가 표시됩니다:
메시지를 보내세요 (도움말은 /? 입력)
간단한 이미지 분석으로 모델의 기능을 테스트해 봅시다:
테스트 이미지 준비:
컴퓨터에 있는 아무 이미지나 찾으세요. 사진, 스크린샷 또는 일러스트레이션일 수 있습니다. 이 예에서는 현재 디렉토리에 test_image.jpg라는 이미지가 있다고 가정합니다.

대화형 채팅 테스트:
bash
이 이미지에서 무엇을 보시나요? /경로/로/이미지.jpg
대안: API를 사용한 테스트
프로그래밍 방식으로 테스트하는 것을 선호한다면 Ollama API를 사용할 수 있습니다. 다음은 curl을 사용한 간단한 테스트입니다:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "이 이미지에 무엇이 있나요? 자세히 설명해주세요.",
"images": ["base64_인코딩된_이미지_데이터_여기"]
}'

5단계: 고급 구성 옵션
이제 작동하는 설치가 완료되었으므로, 특정 하드웨어 및 사용 사례에 맞게 설정을 최적화하기 위한 몇 가지 고급 구성 옵션을 살펴보겠습니다.
메모리 최적화:
메모리 문제가 발생하면 모델 로딩 동작을 조정할 수 있습니다:
bash
# 최대 메모리 사용량 설정 (RAM에 따라 조정)export OLLAMA_MAX_LOADED_MODELS=1
# GPU 오프로딩 활성화export OLLAMA_GPU=1
# 사용자 지정 포트 설정 (11434가 이미 사용 중인 경우)export OLLAMA_HOST=0.0.0.0:11435
양자화 옵션:
VRAM이 제한된 시스템의 경우 특정 양자화 수준을 강제할 수 있습니다:
bash
# 4비트 양자화로 모델 로드 (더 호환성 높지만 느림)ollama run qwen3-vl:4b --format json
# 8비트 양자화로 로드 (균형 잡힘)ollama run qwen3-vl:8b --format json
다중 GPU 구성:
여러 GPU가 있는 경우 사용할 GPU를 지정할 수 있습니다:
bash
# 특정 GPU ID 사용 (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# 여러 Apple Silicon GPU가 있는 macOS에서export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Apidog를 사용한 테스트 및 통합: 품질 및 성능 보장

이제 Qwen3-VL이 로컬에서 실행되고 있으므로, 이를 개발 워크플로우에 제대로 테스트하고 통합하는 방법에 대해 이야기해 봅시다. 이 부분이 Apidog가 AI 개발자에게 없어서는 안 될 도구로 진정으로 빛나는 지점입니다.
Apidog는 단순한 API 테스트 도구가 아닙니다. 현대 API 개발 워크플로우를 위해 특별히 설계된 포괄적인 플랫폼입니다. Qwen3-VL과 같은 로컬 AI 모델로 작업할 때, 다음을 수행할 수 있는 도구가 필요합니다:
1.복잡한 JSON 구조 처리: AI 모델 응답은 종종 다양한 콘텐츠 유형을 가진 중첩된 JSON을 포함합니다.
2.파일 업로드 지원: 많은 AI 모델은 이미지, 비디오 또는 문서 입력을 필요로 합니다.
3.인증 관리: 적절한 인증 처리로 엔드포인트의 보안 테스트.
4.자동화된 테스트 생성: 모델 성능 일관성을 위한 회귀 테스트.
5.문서 생성: 테스트 케이스에서 API 문서를 자동으로 생성.
일반적인 문제 해결
Ollama의 단순성에도 불구하고 문제가 발생할 수 있습니다. 다음은 자주 발생하는 문제에 대한 해결책입니다.
❌ "모델을 찾을 수 없음" 또는 "지원되지 않는 모델"
- Ollama v0.1.40 이상을 사용하고 있는지 확인하세요.
ollama pull qwen3-vl:4b를 다시 실행하세요. 때때로 다운로드가 조용히 실패합니다.
❌ GPU에서 "메모리 부족"
- 8B 대신 4B 버전을 시도하세요.
- 다른 GPU 사용량이 많은 앱(Chrome, 게임 등)을 닫으세요.
- Linux에서
nvidia-smi로 VRAM을 확인하세요.
❌ 이미지 인식 불가
- 이미지가 4MB 미만인지 확인하세요.
- PNG 또는 JPG를 사용하세요 (HEIC, BMP는 피하세요).
- base64 문자열에 개행 문자가 없는지 확인하세요 (Linux에서
base64 -w 0사용).
❌ CPU에서 느린 추론
- Qwen 3 VL은 양자화된 상태에서도 큽니다. CPU에서는 초당 1~5 토큰을 예상하세요.
- 10배 빠른 속도를 위해 Apple Silicon 또는 NVIDIA GPU로 업그레이드하세요.
로컬 Qwen 3 VL의 실제 사용 사례
이 모든 번거로움을 겪는 이유는 무엇일까요? 다음은 실제 적용 사례입니다.
- 문서 지능: 스캔한 PDF에서 표, 서명 또는 조항 추출
- 접근성 도구: 시각 장애인을 위해 이미지 설명
- 내부 지식 봇: 내부 다이어그램 또는 대시보드에 대한 질문에 답변
- 교육: 사진에서 수학 문제를 설명하는 튜터 구축
- 보안 분석: 네트워크 다이어그램 또는 시스템 아키텍처 스크린샷 분석
로컬이기 때문에 민감한 시각 자료를 타사 API로 보내는 것을 피할 수 있습니다. 이는 기업과 프라이버시를 중요하게 생각하는 개발자에게 큰 이점입니다.
결론: 로컬 AI 우수성으로의 여정
축하합니다! Qwen3-VL과 Ollama를 사용한 로컬 AI의 세계로의 장대한 여정을 마쳤습니다. 이제 다음을 갖추셨을 것입니다:
- 로컬에서 실행되는 완전히 기능하는 Qwen3-VL 설치
- Apidog를 사용한 포괄적인 테스트 설정
- 모델의 기능과 한계에 대한 깊은 이해
- 이 모델들을 실제 애플리케이션에 통합하기 위한 실용적인 지식
- 일반적인 문제를 처리하기 위한 문제 해결 기술
- 지속적인 성공을 위한 미래 대비 전략
이 정도까지 오셨다는 것은 최첨단 AI 기술을 이해하고 활용하려는 여러분의 의지를 보여줍니다. 여러분은 단순히 모델을 설치한 것이 아니라, 시각 및 텍스트 정보와 상호 작용하는 방식을 재편하는 기술에 대한 전문 지식을 얻은 것입니다.
미래는 로컬 AI입니다
여기서 우리가 이룬 것은 단순한 기술 설정 그 이상입니다. AI가 접근 가능하고, 사적이며, 개인이 제어할 수 있는 미래를 향한 한 걸음입니다. 이러한 모델들이 계속해서 개선되고 효율적으로 발전함에 따라, 예산이나 기술 전문 지식에 관계없이 모든 사람이 정교한 AI 기능을 사용할 수 있는 세상으로 나아가고 있습니다.
기억하세요, 여정은 여기서 끝나지 않습니다. AI 기술은 빠르게 발전하며, 호기심을 유지하고, 적응하며, 커뮤니티와 소통하는 것이 이러한 강력한 도구를 효과적으로 계속 활용하는 데 중요할 것입니다.
마지막 생각
Ollama를 사용하여 Qwen 3 VL을 로컬에서 실행하는 것은 단순한 기술 데모나 편리함 또는 비용 절감에 관한 것이 아닙니다. 이는 온디바이스 AI의 미래를 엿볼 수 있는 기회입니다. 모델이 더욱 효율적이고 하드웨어가 더욱 강력해짐에 따라, 더 많은 개발자가 앱에 개인적이고 멀티모달 기능을 직접 탑재하는 것을 보게 될 것입니다. 이제 여러분은 제한 없이 AI 기술을 탐색하고, 자유롭게 실험하며, 여러분과 여러분의 조직에 중요한 애플리케이션을 구축할 수 있는 도구를 갖게 되었습니다.
Qwen3-VL의 인상적인 멀티모달 기능과 Ollama의 사용자 친화적인 인터페이스의 조합은 이전에는 막대한 자원을 가진 대기업만이 이용할 수 있었던 혁신의 기회를 창출합니다. 여러분은 이제 AI 기술을 민주화하는 성장하는 개발자 커뮤니티의 일원입니다.
그리고 Ollama와 같은 도구가 배포를 단순화하고 Apidog가 API 개발을 간소화함에 따라, 진입 장벽은 그 어느 때보다 낮아졌습니다.
따라서 여러분이 혼자 해커이든, 스타트업 창업자이든, 기업 엔지니어이든, 지금이 비전-언어 모델을 안전하고 저렴하게, 그리고 로컬에서 실험하기에 완벽한 시기입니다.