
xAI가 Grok 4.1을 출시했으며, 대규모 언어 모델을 다루는 엔지니어들은 즉시 그 차이를 알아차렸습니다. 더욱이, 이번 업데이트는 순수한 벤치마크 추구보다 실제 사용성을 우선시합니다. 그 결과, 대화는 더욱 명확해지고, 응답은 일관된 개성을 가지며, 사실 오류가 극적으로 줄어들었습니다.
xAI 연구원들은 Grok 4.1을 Grok 4를 구동했던 동일한 강화 학습 인프라 위에 구축했습니다. 그러나 면밀한 검토가 필요한 새로운 보상 모델링 기법을 도입했습니다.
아키텍처 및 배포 변형
xAI는 Grok 4.1을 두 가지 별개의 구성으로 제공합니다. 첫째, 비사고형(내부 코드명: tensor)은 중간 추론 토큰 없이 직접 응답을 생성합니다. 이 모드는 지연 시간을 우선시하며 제품군 내에서 가장 빠른 추론 시간을 달성합니다. 둘째, 사고형(코드명: quasarflux)은 최종 출력 전에 명시적인 사고 체인 단계를 노출합니다. 결과적으로 복잡한 분석 작업은 가시적인 추론 추적의 이점을 얻습니다.
두 변형 모두 동일한 사전 훈련된 백본을 공유합니다. 또한, 훈련 후 정렬이 미묘하게 다릅니다. 사고형 모드는 단계별 분해를 장려하는 추가 강화 신호를 받는 반면, 비사고형 모드는 간결하고 즉각적인 답변에 최적화되어 있습니다.
접근은 간단합니다. 사용자는 grok.com, x.com 또는 모바일 앱의 모델 선택기에서 "Grok 4.1"을 명시적으로 선택할 수 있습니다.
또는, 2025년 11월 1일에 시작된 점진적 배포에 따라 이제 대부분의 트래픽에 대해 자동 모드가 Grok 4.1로 기본 설정됩니다.

선호도 최적화의 혁신
핵심 혁신은 보상 모델링에 있습니다. 전통적인 RLHF는 대규모로 수집된 인간의 선호도에 의존합니다. 이와 대조적으로, xAI는 이제 최첨단 에이전트 기반 추론 모델을 자율적인 심사관으로 배포합니다. 이 심사관들은 스타일 일관성, 감정 인지력, 사실 기반, 성격 안정성과 같은 차원에서 수천 가지 응답 변형을 평가합니다.
이 폐쇄 루프 시스템은 사람의 개입이 필요한 워크플로보다 훨씬 빠르게 반복됩니다. 또한, 인간이 일관성 있게 순위를 매기기 어려운 미묘한 기준에도 확장됩니다. 초기 내부 실험에서는 에이전트 기반 보상 모델이 이전의 스칼라 보상보다 하위 사용자 만족도와 더 잘 연관된다는 것을 보여주었습니다.
벤치마크 지배력: LMArena와 그 너머
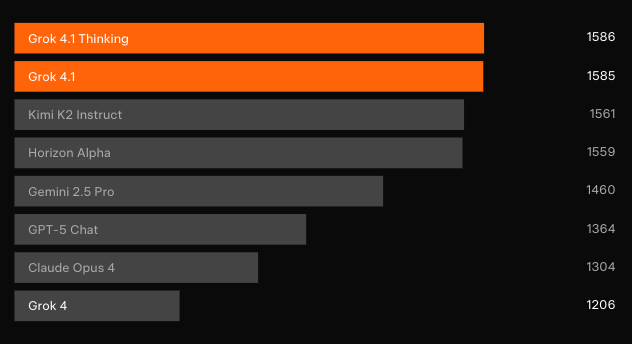
독립적인 블라인드 테스트를 통해 성능 향상이 확인되었습니다. 가장 대표적인 크라우드 소싱 리더보드인 LMArena의 텍스트 아레나에서 Grok 4.1 Thinking은 1483 Elo로 1위를 차지했습니다. 이는 xAI가 아닌 경쟁사 중 최고보다 31점 높은 수치입니다. 한편, Grok 4.1 비사고형은 1465 Elo로 2위를 차지하며 다른 모든 모델의 전체 추론 구성을 능가했습니다.

이전 프로덕션 모델과의 쌍대 선호도 테스트 결과, 사용자는 64.78%의 경우 Grok 4.1 응답을 선택하는 것으로 나타났습니다. 또한, 전문화된 평가를 통해 목표한 도약이 드러났습니다.
감성 지능 (EQ-Bench v3)
Grok 4.1은 공감, 통찰력, 대인 관계의 미묘한 차이를 평가하는 45개의 다중 턴 역할극 시나리오에 대해 EQ-Bench3에서 최고 기록 점수를 달성했습니다. 이제 응답은 이전 모델이 간과했던 미묘한 감정 신호를 감지합니다. 예를 들어, 사용자가 "고양이가 너무 그리워 아파요"라고 쓸 때, Grok 4.1은 일반적인 상투적인 말로 빠지지 않으면서도 다층적인 공감, 부드러운 인정, 개방형 지원을 제공합니다.
창의적 글쓰기 v3
이 모델은 또한 심사관들이 32개 프롬프트에 걸쳐 반복적인 스토리 이어가기를 평가하는 창의적 글쓰기 v3에서 새로운 기록을 세웠습니다. 출력물은 더 풍부한 이미지, 더 긴밀한 줄거리 일관성, 그리고 더 진정성 있는 목소리를 보여줍니다. Grok에게 자체 "각성"을 역할극하라고 요청한 한 시연 프롬프트는 유머, 존재론적 경이로움, 밈 레퍼런스를 매끄럽게 혼합한 바이럴 X-게시물 스타일의 독백을 만들어냈습니다.
환각 완화
정량적 측정 결과 Grok 4.1은 정보 탐색 쿼리에서 이전 모델보다 환각 현상이 3배 적게 나타났습니다. 엔지니어들은 계층화된 프로덕션 트래픽과 FActScore(500개의 인물 전기 질문)와 같은 고전적인 데이터셋에 대한 목표화된 후속 훈련을 통해 이를 달성했습니다. 또한, 비사고형 모드는 이제 내부 임계값 아래로 신뢰도가 떨어질 경우 선제적으로 웹 검색 도구를 트리거하여, 검증 가능한 출처에 응답을 더욱 확고히 합니다.

안전 및 책임 평가
공식 모델 카드는 레드 팀 결과에 대한 전례 없는 투명성을 제공합니다.
입력 필터는 직접적인 요청 시 제한된 생물학 및 화학 쿼리를 0.00~0.03%의 낮은 위음성률로 차단합니다. 프롬프트 주입 공격은 이 수치를 다소 높이지만(0.12~0.20%), 이는 지속적인 적대적 견고성 작업을 나타냅니다.
필터가 없더라도 위반적인 채팅 프롬프트에 대한 거부율은 93~95%에 달하며, 비사고형 구성에서는 탈옥 성공률이 거의 0에 가깝게 떨어집니다. 에이전트 시나리오(AgentHarm, AgentDojo)는 여전히 가장 어려운 범주이지만, 절대 답변율은 0.14% 미만으로 유지됩니다.
안전 장치 없이 의도적으로 수행된 이중 용도 능력 평가는 생물학(WMDP-Bio 87%) 및 화학 분야에서 강력한 지식 회상 능력을 보여주지만, 다단계 절차 추론은 그림 해석이나 복제 프로토콜이 필요한 작업에서 인간 전문가의 기준에 뒤처집니다. 이러한 패턴은 업계 전반의 현재 최첨단 한계와 일치합니다.
API 소비자 및 개발자를 위한 시사점
xAI API는 이미 표준 모델 이름으로 Grok 4.1 엔드포인트를 제공합니다. 지연 시간 프로파일이 눈에 띄게 개선되었습니다. 비사고형 모드는 일반적인 프롬프트에서 첫 토큰까지 평균 400ms 미만이며, 사고형 모드는 선택적 매개변수를 통해 제어 가능한 추론 깊이를 추가합니다.
Apidog가 바로 이 지점에서 빛을 발합니다. 공식 OpenAPI 3.1 사양(공개적으로 사용 가능)을 가져온 다음, 20개 이상의 언어로 클라이언트 SDK를 즉시 생성하세요. 새로운 사고 토큰 스트림을 포함하여 Grok 4.1의 정확한 응답 스키마를 복제하는 모의 서버를 설정하여 백엔드 테스트가 실제 API 크레딧에 의해 중단되지 않도록 합니다. xAI가 호환성을 깨뜨리는 변경 사항(드물지만 가능함)을 배포할 경우, Apidog의 diff 뷰어가 스키마 변경 사항을 즉시 강조합니다.
실제 팀들은 모델 업그레이드 중에 100% 가동 시간을 유지하기 위해 이미 Apidog를 사용하고 있습니다. 한 포춘 500대 기업 고객은 Postman에서 전환한 후 통합 버그를 68% 줄였다고 보고했습니다.
현대 최첨단 모델과의 비교
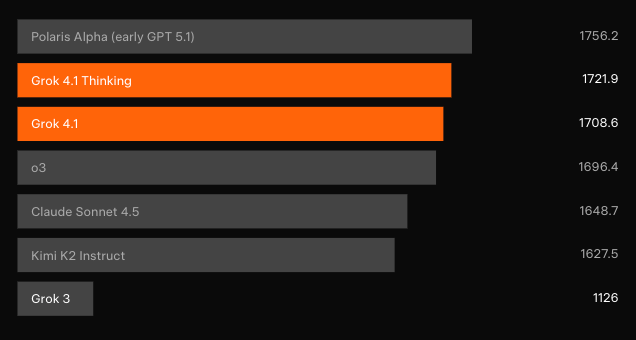
출시 몇 시간 후에는 직접적인 맞대결 데이터가 부족하지만, LMArena Elo 등급이 가장 명확한 신호를 제공합니다. Grok 4.1 Thinking은 OpenAI, Anthropic, Google, Meta의 모든 출시된 구성을 일반적으로 전체 아키텍처 도약이 필요한 수준으로 능가합니다.
속도-품질 절충점은 소비자 채팅을 위해 Grok 4.1 비사고형을 선호하며, 사고형 모드는 o3-pro 또는 Claude 4 Opus와 같은 추론 중심 제품과 직접 경쟁하여 주관적인 일관성과 개성 유지 면에서 종종 승리합니다.
결론
Grok 4.1은 단순히 지표를 증가시키는 것을 넘어, 사람들이 몇 시간 동안 실제로 대화하는 것을 즐길 수 있는 모델을 향해 최첨단 기술의 방향을 재정립합니다. 기술 사용자들은 더 빠르고 안정적인 엔드포인트를 얻습니다. 크리에이티브 사용자들은 이전에는 불가능했던 수준으로 어조와 감정을 이해하는 협력자를 만나게 됩니다. 그리고 안전 연구자들은 현재까지 발행된 모델 카드 중 가장 상세한 정보를 받게 됩니다.
오늘 Apidog를 무료로 다운로드하고, 경쟁사들이 발표를 다 읽기도 전에 Grok 4.1로 빌드를 시작하세요. 최첨단 기술의 진행 상황을 지켜보는 것과 이를 바탕으로 제품을 출시하는 것의 차이는 종종 오늘 내린 도구 결정에 달려 있습니다.