
OpenAI의 gpt-oss-safeguard 모델은 분류 작업에 대한 정책 기반 추론을 가능하게 하여 이러한 필요성을 해결합니다. 엔지니어는 이러한 모델을 통합하여 사용자 생성 콘텐츠를 분류하고, 위반 사항을 감지하며, 플랫폼 무결성을 유지합니다.
GPT-OSS-Safeguard 이해하기: 기능 및 역량
OpenAI 엔지니어들은 안전 분류에 맞춰진 오픈 웨이트 추론 모델인 gpt-oss-safeguard를 개발했습니다. 이 모델들은 gpt-oss 기반에서 미세 조정되었으며 Apache 2.0 라이선스 하에 출시되었습니다. 개발자들은 Hugging Face에서 모델을 다운로드하여 자유롭게 배포할 수 있습니다. 라인업에는 gpt-oss-safeguard-20b와 gpt-oss-safeguard-120b가 포함되며, 숫자는 매개변수 규모를 나타냅니다.
이 모델들은 개발자가 정의한 정책과 평가할 콘텐츠라는 두 가지 주요 입력을 처리합니다. 시스템은 연쇄적 사고(chain-of-thought) 추론을 적용하여 정책을 해석하고 콘텐츠를 분류합니다. 예를 들어, 사용자 메시지가 게임 포럼에서 부정 행위에 대한 규칙을 위반하는지 여부를 결정합니다. 이 접근 방식은 기존 분류기가 요구하는 재훈련 없이 동적인 정책 업데이트를 가능하게 합니다.
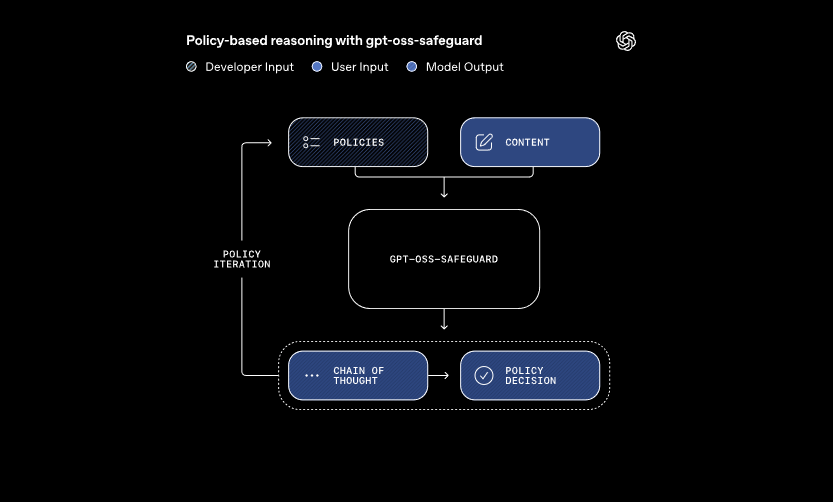
또한 gpt-oss-safeguard는 여러 정책을 동시에 지원합니다. 개발자는 단일 추론 호출에 여러 규칙을 입력할 수 있으며, 모델은 모든 규칙에 대해 콘텐츠를 평가합니다. 이 기능은 잘못된 정보나 유해한 발언과 같은 다양한 위험을 처리하는 플랫폼의 워크플로우를 간소화합니다. 그러나 정책이 추가되면 성능이 약간 저하될 수 있으므로 팀은 구성을 철저히 테스트해야 합니다.
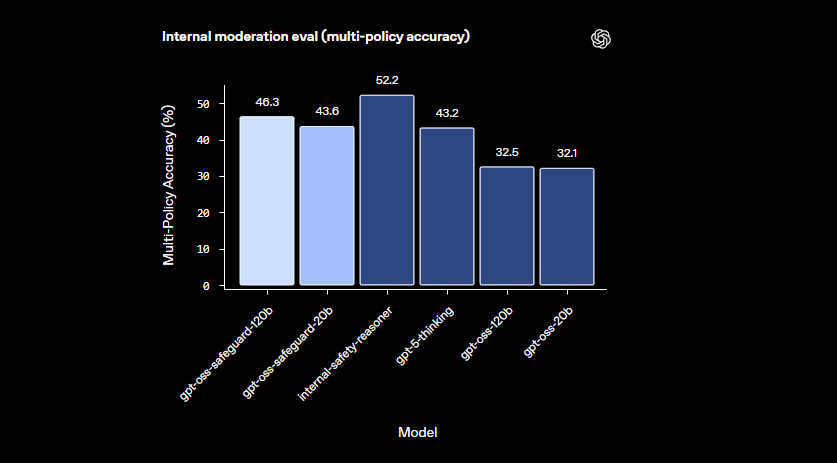
이 모델들은 소규모 분류기가 어려움을 겪는 미묘한 영역에서 탁월합니다. 수정된 정책에 신속하게 적응하여 새로운 피해를 처리합니다. 또한, 연쇄적 사고(chain-of-thought) 출력은 투명성을 제공하여 개발자가 추론 과정을 검토하고 결정을 감사할 수 있도록 합니다. 이 기능은 설명 가능한 AI를 필요로 하는 규정 준수 팀에게 매우 유용합니다.
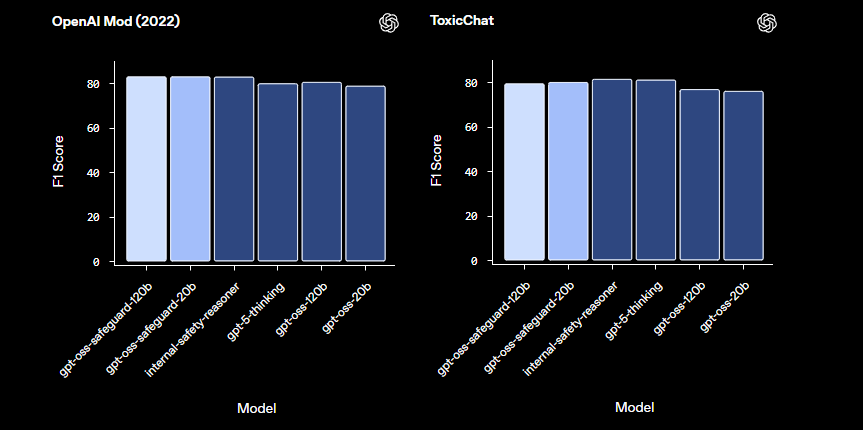
LlamaGuard와 같은 사전 구축된 안전 모델과 비교하여 gpt-oss-safeguard는 더 큰 사용자 정의 기능을 제공합니다. 고정된 분류법을 피하고 조직이 자체 임계값을 정의할 수 있도록 합니다. 결과적으로, 이 통합은 확장 가능한 중재 파이프라인을 구축하는 신뢰 및 안전 엔지니어에게 적합합니다. 이제 기본 사항을 이해했으니, 환경 설정으로 넘어가겠습니다.
GPT-OSS-Safeguard API 액세스를 위한 환경 설정
개발자는 gpt-oss-safeguard를 실행할 시스템을 준비하는 것으로 시작합니다. 모델은 오픈 웨이트이므로 로컬 또는 호스팅 제공업체를 통해 배포할 수 있습니다. 이러한 유연성은 개인 컴퓨터부터 클라우드 서버에 이르기까지 다양한 하드웨어 설정을 수용합니다.
먼저, 필요한 종속성을 설치합니다. Python 3.10 이상이 기본으로 사용됩니다. pip를 사용하여 Hugging Face Transformers와 같은 라이브러리를 추가합니다: pip install transformers. 추론 속도를 높이려면 호환되는 GPU를 소유하고 있는 경우 CUDA 지원이 포함된 torch를 포함합니다. NVIDIA 하드웨어를 사용하는 엔지니어는 더 빠른 처리를 위해 이를 활성화할 수 있습니다.
다음으로, Hugging Face에서 모델을 다운로드합니다. 컬렉션에 접속하세요. 리소스 요구 사항이 적은 gpt-oss-safeguard-20b 또는 더 뛰어난 정확도를 위한 gpt-oss-safeguard-120b를 선택합니다. transformers-cli download openai/gpt-oss-safeguard-20b 명령으로 파일을 가져옵니다.
API를 노출하려면 로컬 서버를 실행합니다. vLLM과 같은 도구가 이를 효율적으로 처리합니다. pip install vllm으로 vLLM을 설치합니다. 그런 다음 서버를 시작합니다: vllm serve openai/gpt-oss-safeguard-20b. 이 명령은 http://localhost:8000/v1에서 OpenAI 호환 엔드포인트를 시작합니다. 마찬가지로 Ollama는 배포를 간소화합니다: ollama run gpt-oss-safeguard:20b. 이는 통합을 위한 REST API를 제공합니다.
로컬 테스트를 위해 LM Studio는 사용자 친화적인 인터페이스를 제공합니다. lms get openai/gpt-oss-safeguard-20b를 실행하여 모델을 가져옵니다. 이 소프트웨어는 OpenAI의 Chat Completions API를 에뮬레이트하여 프로덕션으로의 원활한 코드 전환을 가능하게 합니다.
호스팅 옵션은 하드웨어 문제를 해결해 줍니다. Groq와 같은 제공업체는 API를 통해 gpt-oss-safeguard-20b를 지원합니다. https://console.groq.com에서 가입하고 API 키를 생성한 다음 요청에서 모델을 대상으로 지정하세요. 가격은 백만 입력 토큰당 $0.075부터 시작합니다. OpenRouter도 이를 호스팅합니다.
설정이 완료되면 설치를 확인합니다. curl을 통해 테스트 요청을 보냅니다: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. 성공적인 응답은 준비가 완료되었음을 확인합니다. 환경이 구성되었으니, 다음으로 정책을 작성합니다.
GPT-OSS-Safeguard를 위한 효과적인 정책 작성
정책은 gpt-oss-safeguard 운영의 핵심입니다. 개발자는 분류를 안내하는 구조화된 프롬프트로 정책을 작성합니다. 잘 설계된 정책은 모델의 추론 능력을 극대화하여 정확하고 설명 가능한 출력을 보장합니다.
정책을 명확한 섹션으로 구성하세요. 먼저 모델의 작업을 지정하는 지침(Instructions)으로 시작합니다. 예를 들어, 콘텐츠를 위반(1) 또는 안전(0)으로 분류하도록 지시합니다. 다음으로 "비인간적인 언어"와 같은 주요 용어를 명확히 하는 정의(Definitions)를 따릅니다. 그런 다음 위반 및 안전한 콘텐츠에 대한 기준(Criteria)을 설명합니다. 마지막으로 예시(Examples)를 포함합니다. 4-6개의 경계 사례를 적절하게 레이블링하여 제공합니다.
정책에는 능동태를 사용하세요: 수동적인 대안 대신 "폭력을 조장하는 콘텐츠를 표시하세요". 언어를 정확하게 유지하고 "일반적으로 안전하지 않음"과 같은 모호성을 피하세요. 규칙 간에 충돌이 발생하면 우선순위를 명시적으로 정의하세요. 다중 정책 시나리오의 경우 시스템 메시지에서 정책들을 연결하세요.
"reasoning_effort" 매개변수를 통해 추론 깊이를 제어하세요: 복잡한 경우에는 "high"로, 속도를 위해서는 "low"로 설정합니다. gpt-oss-safeguard에 내장된 하모니 형식은 추론을 최종 출력과 분리합니다. 이는 감사 추적을 유지하면서 깔끔한 API 응답을 보장합니다.
정책 길이를 약 400-600 토큰으로 최적화하세요. 짧은 정책은 지나치게 단순화될 위험이 있으며, 긴 정책은 모델을 혼란스럽게 할 수 있습니다. 반복적으로 테스트하세요: 샘플 콘텐츠를 분류하고 출력에 따라 개선합니다. Hugging Face의 토큰 카운터와 같은 도구가 도움이 됩니다.
출력 형식의 경우 단순성을 위해 이진 형식을 선택하세요: 정확히 0 또는 1을 반환합니다. 깊이를 위해 근거를 추가하세요: {"violation": 1, "rationale": "여기에 설명"}. 이 JSON 구조는 다운스트림 시스템과 쉽게 통합됩니다. 정책을 개선하면서 API 구현으로 전환합니다.
GPT-OSS-Safeguard로 API 호출 구현하기
개발자는 OpenAI 호환 엔드포인트를 통해 gpt-oss-safeguard와 상호 작용합니다. 로컬이든 호스팅이든, 이 프로세스는 표준 채팅 완료 패턴을 따릅니다.
클라이언트를 준비하세요. Python에서 OpenAI를 가져옵니다: from openai import OpenAI. 로컬의 경우 기본 URL과 키로 초기화합니다: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy"), 또는 제공업체별 값으로 초기화합니다.
메시지를 구성합니다. 시스템 역할은 정책을 포함합니다: {"role": "system", "content": "Your detailed policy here"}. 사용자 역할은 콘텐츠를 포함합니다: {"role": "user", "content": "Content to classify"}.
API를 호출합니다: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). 온도를 0으로 설정하면 안전 작업에 대해 결정론적 출력을 보장합니다.
응답을 파싱합니다: result = completion.choices[0].message.content. 구조화된 출력의 경우 JSON 파싱을 사용합니다. Groq는 프롬프트 캐싱으로 이를 향상시킵니다. 호출 간에 정책을 재사용하여 비용을 50% 절감할 수 있습니다.
실시간 피드백을 위해 스트리밍을 처리합니다: stream=True로 설정하고 청크를 반복합니다. 이는 대량 중재에 적합합니다.
gpt-oss-safeguard는 분류에 중점을 두지만, 필요한 경우 도구를 통합합니다. 외부 데이터 가져오기와 같은 확장된 기능을 위해 tools 매개변수에 함수를 정의합니다.
토큰 사용량을 모니터링합니다: 입력에는 정책과 콘텐츠가 포함되며, 출력에는 추론이 추가됩니다. 오버플로우를 방지하기 위해 max_tokens를 제한합니다. 호출을 숙달했으면 예시를 탐색합니다.
GPT-OSS-Safeguard API의 고급 기능
gpt-oss-safeguard는 정교한 제어를 위한 고급 도구를 제공합니다. Groq의 프롬프트 캐싱은 정책을 재사용하여 지연 시간과 비용을 줄입니다.
시스템 메시지에서 reasoning_effort를 조정합니다: 심층 분석을 위해 "Reasoning: high"로 설정합니다. 이는 모호한 콘텐츠를 더 잘 처리합니다.
긴 채팅이나 문서를 위해 128k 컨텍스트 창을 활용합니다. 전체 대화를 입력하여 전체적인 분류를 수행합니다.
더 큰 시스템과 통합합니다: 출력을 에스컬레이션 큐 또는 로깅으로 보냅니다. 실시간 알림을 위해 웹훅을 사용합니다.
기본 모델이 정책 준수에 탁월하지만, 필요한 경우 추가로 미세 조정합니다. 계산을 최적화하기 위해 사전 필터링을 위해 더 작은 모델과 결합합니다.
보안은 중요합니다: API 키를 안전하게 보호하고 프롬프트 주입을 모니터링합니다. 익스플로잇을 방지하기 위해 입력을 검증합니다.
확장: 높은 처리량을 위해 vLLM이 있는 클러스터에 배포합니다. Groq와 같은 제공업체는 초당 1000개 이상의 토큰을 제공합니다.
이러한 기능은 gpt-oss-safeguard를 기본적인 분류기에서 엔터프라이즈 도구로 격상시킵니다. 그러나 최적의 결과를 얻으려면 모범 사례를 따르세요.
GPT-OSS-Safeguard를 위한 모범 사례 및 최적화
엔지니어는 정책을 반복하여 gpt-oss-safeguard를 최적화합니다. F1-점수와 같은 측정항목을 통해 정확도를 측정하고 다양한 데이터 세트로 테스트합니다.
모델 크기의 균형을 맞춥니다: 속도를 위해 20b를, 정밀도를 위해 120b를 사용합니다. 메모리 사용량을 줄이기 위해 가중치를 양자화합니다.
성능을 모니터링합니다: 감사를 위해 추론 추적을 기록합니다. 온도를 최소한으로 조정합니다. 0.0은 결정론적 요구 사항에 적합합니다.
한계 처리: 모델은 고도로 전문화된 도메인에서 어려움을 겪을 수 있습니다. 도메인 데이터로 보완합니다.
윤리적 사용 보장: 정책을 규정과 일치시킵니다. 예시를 다양화하여 편향을 피합니다.
정기적으로 업데이트: OpenAI가 gpt-oss-safeguard를 발전시킴에 따라 개선 사항을 통합합니다.
비용 관리: 호스팅된 API의 경우 토큰 사용량을 추적합니다. 로컬 배포는 비용을 최소화합니다.
이러한 관행을 적용하면 효율성을 극대화할 수 있습니다. 요약하자면, gpt-oss-safeguard는 강력한 안전 시스템을 가능하게 합니다.
결론: GPT-OSS-Safeguard를 워크플로우에 통합하기
개발자들은 gpt-oss-safeguard를 활용하여 적응성 있는 안전 분류기를 구축합니다. 설정부터 고급 사용까지, 이 가이드는 기술 지식을 제공합니다. 정책을 구현하고, API 호출을 실행하며, 필요에 따라 최적화하세요. 플랫폼이 발전함에 따라 gpt-oss-safeguard는 원활하게 적응하여 안전한 환경을 보장합니다.