
개발자들은 지능형 애플리케이션을 구축하기 위해 강력한 도구를 끊임없이 찾고 있습니다. OpenAI는 고급 추론 기능을 제공하는 개방형 가중치 언어 모델 시리즈인 GPT-OSS를 출시하여 이러한 요구를 충족시킵니다. gpt-oss-120b 및 gpt-oss-20b를 포함한 이 모델들은 다양한 환경에서 맞춤 설정 및 배포가 가능합니다. 사용자들은 호스팅 플랫폼에서 제공하는 API를 통해 모델에 접근하여 프로젝트에 원활하게 통합할 수 있습니다.
GPT-OSS API 작업을 시작하려면 개발자는 OpenRouter 또는 Together AI와 같은 제공업체를 통해 액세스 권한을 얻습니다. 이 플랫폼들은 모델을 호스팅하고 OpenAI의 API 형식과 호환되는 표준 엔드포인트를 노출합니다. 이러한 호환성은 독점 모델에서 마이그레이션하는 것을 간소화합니다.
GPT-OSS란 무엇인가? 주요 기능 및 역량
OpenAI는 GPT-OSS를 MoE(Mixture-of-Experts) 모델 계열로 설계했습니다. 이 아키텍처는 토큰당 매개변수의 일부만 활성화하여 효율성을 높입니다. 예를 들어, gpt-oss-120b는 총 1,170억 개의 매개변수를 특징으로 하지만 토큰당 51억 개만 활성화합니다. 유사하게, gpt-oss-20b는 210억 개의 매개변수를 사용하며 36억 개가 활성화됩니다.
이 모델들은 밀집 및 희소 어텐션 레이어가 번갈아 나타나는 트랜스포머 기반 구조를 사용합니다. 이들은 최대 128,000 토큰에 이르는 긴 컨텍스트를 처리하기 위해 로터리 위치 임베딩(RoPE)을 통합합니다. 개발자들은 문서 요약과 같이 광범위한 입력이 필요한 애플리케이션에서 이로부터 이점을 얻습니다.
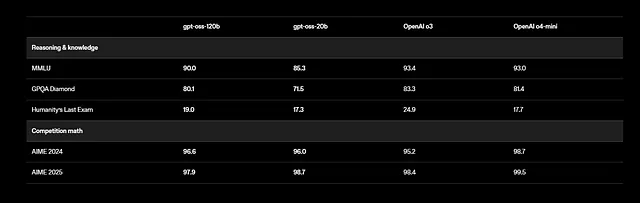
또한 GPT-OSS는 다국어 작업을 지원하지만, 훈련은 STEM 및 코딩 데이터에 중점을 둔 영어에 집중되어 있습니다. 벤치마크 결과는 인상적입니다. gpt-oss-120b는 MMLU(대규모 다중 작업 언어 이해)에서 94.2%, AIME(미국 초청 수학 시험)에서 96.6%를 기록했습니다. 이는 건강 관련 질의 및 경쟁 수학 분야에서 o4-mini와 같은 모델을 능가합니다.
개발자들은 모델이 웹 검색이나 코드 실행과 같은 외부 함수를 호출하는 도구 호출 기능을 활용합니다. 이러한 에이전트 역량은 자율 시스템 구축을 가능하게 합니다. 예를 들어, 모델은 단일 응답에서 여러 도구 호출을 연결하여 문제를 단계별로 해결합니다.
또한 이 모델들은 Apache 2.0 라이선스를 준수하여 자유로운 수정 및 배포를 허용합니다. OpenAI는 Hugging Face에서 MXFP4 형식으로 양자화된 가중치를 제공하여 메모리 사용량을 줄입니다. 사용자들은 이를 로컬 또는 클라우드 제공업체를 통해 실행할 수 있습니다.
그러나 안전 고려 사항이 적용됩니다. OpenAI는 준비 프레임워크(Preparedness Framework)에 따라 오정보와 같은 위험을 테스트하는 평가를 수행합니다. 개발자들은 문제 완화를 위해 출력 필터링과 같은 안전 장치를 구현합니다.
본질적으로 GPT-OSS는 강력함과 접근성을 결합합니다. 개방적인 특성은 커뮤니티 기여를 장려하여 빠른 개선으로 이어집니다. 다음으로, 이 모델들에 대한 API 액세스를 제공하는 제공업체를 식별합니다.
GPT-OSS API 액세스 제공업체 선택
여러 플랫폼이 GPT-OSS 모델을 호스팅하고 API 엔드포인트를 제공합니다. 개발자는 속도, 비용, 확장성과 같은 필요에 따라 선택합니다. 예를 들어, OpenRouter는 gpt-oss-120b를 경쟁력 있는 가격과 쉬운 통합으로 제공합니다.
Together AI는 기업용 배포를 강조하는 또 다른 옵션을 제공합니다. 이 모델은 OpenAI 클라이언트와 호환되는 /v1/chat/completions 엔드포인트를 통해 모델을 지원합니다. 개발자는 메시지, max_tokens 및 temperature를 지정하는 JSON 페이로드를 보냅니다.
또한 Fireworks AI와 Cerebras는 고속 추론을 제공합니다. Cerebras는 초당 최대 3,000 토큰을 달성하여 실시간 애플리케이션에 이상적입니다. 가격은 다양합니다. OpenRouter는 백만 입력 토큰당 약 $0.15를 청구하며, Together AI는 볼륨 할인과 함께 유사한 요금을 제공합니다.
개발자들은 프라이버시를 위해 자체 호스팅도 고려합니다. vLLM 또는 Ollama와 같은 도구를 사용하면 로컬 서버에서 GPT-OSS를 실행하여 API를 노출할 수 있습니다. 예를 들어, vLLM은 OpenAI 호환 경로로 모델을 제공하며, 시작하는 데 단일 명령만 필요합니다.
그러나 클라우드 제공업체는 확장을 간소화합니다. AWS, Azure 및 Vercel은 OpenAI와의 파트너십을 통해 GPT-OSS를 통합합니다. 이러한 옵션은 로드 밸런싱 및 자동 스케일링을 자동으로 처리합니다.
또한 지연 시간을 평가합니다. gpt-oss-20b는 요구 사항이 낮은 엣지 장치에 적합하며, gpt-oss-120b는 NVIDIA H100과 같은 GPU를 요구합니다. 제공업체는 하드웨어에 최적화하여 일관된 성능을 보장합니다.
요컨대, 올바른 제공업체는 프로젝트 목표와 일치해야 합니다. 선택이 완료되면 API 자격 증명을 획득하는 절차를 진행합니다.
API 액세스 획득 및 환경 설정
개발자는 제공업체 사이트에 등록하는 것으로 시작합니다. OpenRouter의 경우, openrouter.ai를 방문하여 계정을 생성하고 키 섹션으로 이동합니다. 참조를 위해 이름을 지정하여 새 API 키를 생성하고 안전하게 복사합니다.
다음으로, 클라이언트 라이브러리를 설치합니다. Python에서는 pip를 사용하여 openai를 추가합니다: pip install openai. 기본 URL과 키로 클라이언트를 구성합니다. 예를 들어:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
이 설정은 gpt-oss 모델에 요청을 보낼 수 있도록 합니다.
또한 Together AI의 경우, SDK를 사용합니다: pip install together. 다음과 같이 초기화합니다:
import together
together.api_key = "your_together_api_key"
모델을 나열하거나 간단한 쿼리를 전송하여 연결을 테스트합니다.
그러나 자체 호스팅 시 하드웨어를 확인하십시오. Hugging Face에서 가중치를 다운로드합니다: huggingface-cli download openai/gpt-oss-120b. 그런 다음 vLLM을 사용하여 서비스합니다: vllm serve openai/gpt-oss-120b.
또한 보안을 위해 환경 변수를 설정합니다. .env 파일에 키를 저장하고 dotenv 라이브러리로 로드합니다.
문제가 발생할 경우, 제공업체 문서를 확인하여 속도 제한 또는 인증 오류를 확인하십시오. 이 준비는 원활한 API 상호 작용을 보장합니다.
GPT-OSS에 첫 API 호출하기
개발자는 채팅 완성(chat completions) 엔드포인트를 사용하여 요청을 작성합니다. 페이로드에 "openai/gpt-oss-120b"와 같은 모델을 지정합니다.
기본 호출의 경우, 메시지를 사전 목록으로 준비합니다. 각 사전에는 역할(system, user, assistant)과 내용이 포함됩니다.
다음은 Python 예제입니다:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
이것은 해당 개념을 기술적으로 설명하는 응답을 생성합니다.
또한 제어를 위해 매개변수를 조정합니다. Temperature는 창의성에 영향을 미칩니다. 값이 낮을수록 결정론적인 출력이 생성됩니다. Top_p는 토큰 샘플링을 제한하며, presence_penalty는 반복을 억제합니다.
다음으로, 도구 호출을 통합합니다. 요청에 도구를 정의합니다:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
모델은 도구 호출로 응답하며, 개발자는 이를 실행하고 다시 피드백합니다.
그러나 응답을 신중하게 처리하십시오. 내용, finish_reason, 토큰 수와 같은 사용량 통계를 위해 JSON을 파싱합니다.
또한, 사고의 사슬(chain-of-thought)을 위해 "단계별로 생각하라(Think step by step)."는 프롬프트를 사용하십시오. 시스템 메시지에 추론 노력(reasoning effort)을 "reasoning_effort: medium"으로 설정하십시오.
더 빠른 테스트를 위해 gpt-oss-20b로 실험하십시오: 호출에서 모델 이름을 교체하십시오.
고급 시나리오에서는 실시간 출력을 위해 stream=True를 사용하여 응답을 스트리밍합니다.
이러한 단계들은 기초적인 기술을 구축합니다. 이제 Apidog와 같은 테스트 도구를 통합합니다.
효율적인 GPT-OSS API 테스트를 위한 Apidog 통합
개발자들은 API 상호 작용을 테스트하고 디버그하기 위해 Apidog에 의존합니다. 이 도구는 gpt-oss 엔드포인트에 요청을 보내기 위한 사용자 친화적인 인터페이스를 제공합니다.
먼저, Apidog 웹사이트에서 Apidog를 설치합니다. 새 프로젝트를 생성하고 https://openrouter.ai/api/v1/chat/completions와 같은 API 엔드포인트를 추가합니다.
다음으로, 헤더를 구성합니다: Bearer 토큰으로 Authorization을 추가하고 Content-Type을 application/json으로 설정합니다.
또한 요청 본문을 작성합니다. Apidog의 JSON 편집기를 사용하여 모델, 메시지 및 매개변수를 입력합니다. 예를 들어, 코드 생성을 위한 gpt-oss 호출을 테스트합니다.
Apidog는 응답을 시각화하여 오류 또는 성공을 강조합니다. 제공업체 간에 API 키를 전환하기 위한 환경 변수를 지원합니다.
그러나 테스트를 정리하기 위해 컬렉션을 활용하십시오. 추론 또는 도구 사용과 같은 작업별로 GPT-OSS 쿼리를 그룹화하고 일괄적으로 실행하십시오.
또한 Apidog는 요청으로부터 Python 또는 cURL과 같은 언어로 코드 스니펫을 생성하여 개발을 가속화합니다.
협업을 위해 프로젝트를 팀과 공유하십시오. 이는 gpt-oss 통합의 일관된 테스트를 보장합니다.
실제로 Apidog를 사용하여 토큰 사용량을 모니터링하고 프롬프트를 최적화하여 비용을 절감하십시오.
전반적으로 Apidog는 GPT-OSS API 작업 시 생산성을 향상시킵니다.
고급 사용: 미세 조정 및 배포
개발자들은 특정 도메인에 맞게 GPT-OSS를 미세 조정합니다. Hugging Face의 트랜스포머 라이브러리를 사용하여 가중치를 로드하고 사용자 정의 데이터셋으로 훈련합니다.
예를 들어, 프롬프트-완성 쌍이 포함된 JSONL 형식으로 데이터를 준비합니다. GitHub 리포지토리에서 미세 조정 스크립트를 실행합니다.
또한 vLLM을 통해 미세 조정된 모델을 API 서비스용으로 배포합니다. 이는 동적 배치와 같은 기능을 통해 프로덕션 부하를 지원합니다.
다음으로, 다중 모달 확장을 탐색합니다. 텍스트 중심이지만, 하이브리드 앱을 위해 비전 모델과 통합합니다.
그러나 미세 조정 중 과적합(overfitting)을 모니터링하십시오. 검증 세트와 조기 종료를 사용하십시오.
또한 클러스터에서 분산 추론으로 확장합니다. AWS와 같은 제공업체는 관리형 옵션을 제공합니다.
에이전트 설정에서는 GPT-OSS를 외부 API와 연결하여 자동화된 연구와 같은 워크플로우를 구현합니다.
이러한 기술들은 기본적인 호출을 넘어선 기능을 확장합니다.
모범 사례, 제한 사항 및 문제 해결
개발자들은 최적의 결과를 위해 모범 사례를 따릅니다. 명확한 프롬프트를 작성하고, 소수 예시(few-shot examples)를 사용하며, 출력에 기반하여 반복합니다.
또한 속도 제한을 준수하십시오. 스로틀링을 피하기 위해 제공업체 대시보드를 확인하십시오.
그러나 제한 사항을 인지하십시오: GPT-OSS는 환각(hallucinate)을 일으킬 수 있으므로 중요한 응답을 검증해야 합니다. 실시간 지식 업데이트가 부족합니다.
또한 API 키를 안전하게 보관하고 비용 관리를 위해 사용량을 기록하십시오.
오류 코드를 검토하여 문제를 해결하십시오. 401은 잘못된 인증을 나타내고, 429는 속도 제한에 도달했음을 의미합니다.
요약하자면, 신뢰할 수 있는 성능을 위해 이 지침을 준수하십시오.
결론: GPT-OSS API로 프로젝트 역량 강화
이제 개발자들은 GPT-OSS를 효과적으로 통합할 수 있는 도구를 갖게 되었습니다. 설정부터 고급 기능까지, 이 가이드는 여러분의 성공을 위한 준비를 돕습니다. gpt-oss와 Apidog를 활용하여 실험하고, 개선하며, 혁신하여 영향력 있는 AI 솔루션을 만드십시오.