
AI 애호가 여러분, 주목하세요! OpenAI가 새로운 오픈 웨이트 모델인 GPT-OSS-120B를 공개하며 AI 커뮤니티의 이목을 집중시키고 있습니다. Apache 2.0 라이선스 하에 출시된 이 강력한 모델은 단일 GPU에서 실행되면서도 추론, 코딩 및 에이전트 작업을 위해 설계되었습니다. 이 가이드에서는 GPT-OSS-120B가 특별한 이유, 뛰어난 벤치마크, 합리적인 가격, 그리고 OpenRouter API를 통해 이 모델을 사용하는 방법을 자세히 살펴보겠습니다. 이 오픈소스 보석을 탐구하고, 여러분이 곧바로 코딩에 활용할 수 있도록 도와드리겠습니다!
개발 팀이 최대한의 생산성을 발휘하여 함께 작업할 수 있는 통합된 올인원 플랫폼을 원하시나요?
Apidog은 여러분의 모든 요구 사항을 충족하며, Postman을 훨씬 더 저렴한 가격에 대체합니다!
GPT-OSS-120B는 무엇인가요?
OpenAI의 GPT-OSS-120B는 더 작은 GPT-OSS-20B와 함께 새로운 오픈 웨이트 GPT-OSS 시리즈의 일부인 1,170억 개의 매개변수 언어 모델입니다(토큰당 51억 개 활성). 2025년 8월 5일에 출시된 이 모델은 효율성을 위해 최적화된 MoE(Mixture-of-Experts) 모델로, 단일 NVIDIA H100 GPU 또는 MXFP4 양자화를 통해 소비자 하드웨어에서도 실행됩니다. 이 모델은 복잡한 추론, 코드 생성 및 도구 사용과 같은 작업을 위해 구축되었으며, 방대한 128K 토큰 컨텍스트 창(300~400페이지 분량의 텍스트)을 자랑합니다! Apache 2.0 라이선스 하에 이 모델을 사용자 지정, 배포 또는 상업적으로 활용할 수 있어, 제어와 프라이버시를 갈망하는 개발자와 기업에게는 꿈과 같은 존재입니다.

벤치마크: GPT-OSS-120B는 어느 정도의 성능을 보여주나요?
GPT-OSS-120B는 성능 면에서 결코 뒤지지 않습니다. OpenAI의 벤치마크는 이 모델이 자체 o4-mini와 Claude 3.5 Sonnet 같은 독점 모델에 대한 강력한 경쟁자임을 보여줍니다. 자세한 내용은 다음과 같습니다:
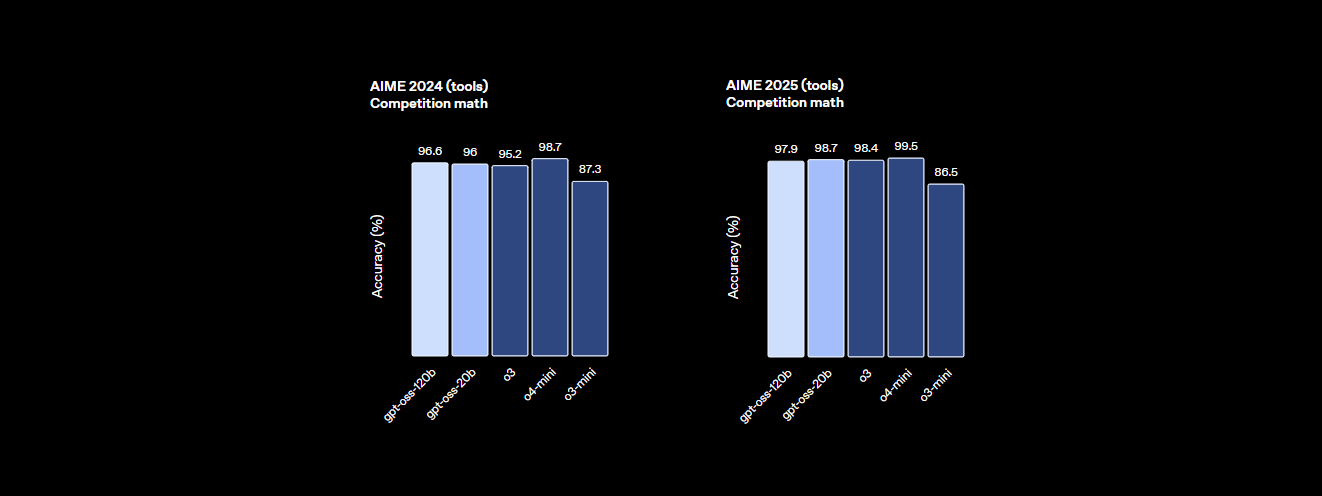
- 추론 능력: MMLU(대규모 다중 작업 언어 이해)에서 94.2%를 기록하여 GPT-4의 95.1%에 근접하며, AIME 수학 경시 대회에서는 96.6%를 달성하여 많은 폐쇄형 모델을 능가합니다.
- 코딩 능력: Codeforces에서 2622 Elo 레이팅을 자랑하며, 코드 생성 HumanEval에서 87.3%의 통과율을 달성하여 코더의 가장 친한 친구가 됩니다.
- 건강 및 도구 사용: HealthBench에서 건강 관련 쿼리에 대해 o4-mini를 능가하며, CoT(사고의 사슬) 추론 및 도구 호출 기능 덕분에 TauBench와 같은 에이전트 작업에서 탁월합니다.
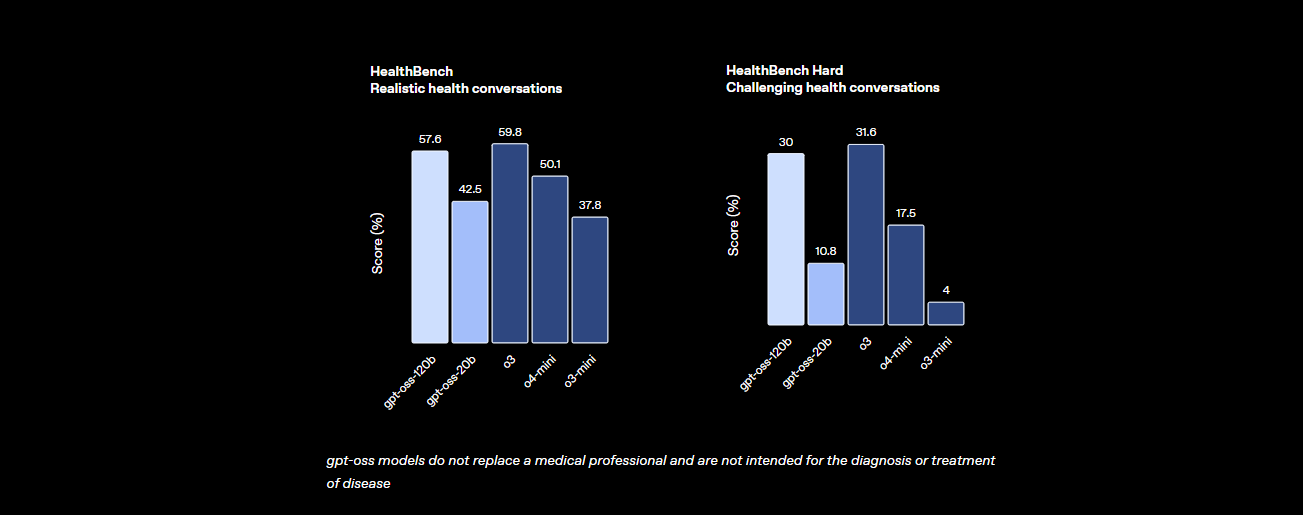
- 속도: H100 GPU에서 초당 45토큰을 처리하며, Cerebras와 같은 제공업체는 대용량 요구 사항에 대해 최대 초당 3,000토큰에 도달합니다. OpenRouter는 초당 약 500토큰을 제공하여 많은 폐쇄형 모델을 능가합니다.
이러한 통계는 GPT-OSS-120B가 오픈 소스이며 사용자 정의가 가능하면서도 최고급 독점 모델과 거의 동등한 수준임을 보여줍니다. 이 모델은 수학, 코딩, 일반적인 문제 해결에 강력하며, 적대적 미세 조정을 통해 안전성을 내재화하여 위험을 낮춥니다.
가격: 합리적이고 투명한
GPT-OSS-120B의 가장 큰 장점 중 하나는 무엇일까요? 특히 독점 모델과 비교할 때 비용 효율적이라는 점입니다. 다음은 131K 컨텍스트 창에 대한 최근 데이터를 기반으로 주요 제공업체별 비용 분석입니다:
- 로컬 배포: 자체 하드웨어(예: H100 GPU 또는 80GB VRAM 설정)에서 실행하여 API 비용을 0으로 만드세요. GMKTEC EVO-X2 설정은 약 €2000이며 200W 미만을 사용하므로, 개인 정보 보호를 우선시하는 소규모 회사에 적합합니다.
- Baseten: 입력 토큰 백만 개당 $0.10, 출력 토큰 백만 개당 $0.50. 지연 시간: 0.20초, 처리량: 초당 491.1토큰. 최대 출력: 131K 토큰.
- Fireworks: 입력 백만 개당 $0.15, 출력 백만 개당 $0.60. 지연 시간: 0.56초, 처리량: 초당 258.9토큰. 최대 출력: 33K 토큰.
- Together: 입력 백만 개당 $0.15, 출력 백만 개당 $0.60. 지연 시간: 0.28초, 처리량: 초당 131.1토큰. 최대 출력: 131K 토큰.
- Parasail: 입력 백만 개당 $0.15, 출력 백만 개당 $0.60 (FP4 양자화). 지연 시간: 0.40초, 처리량: 초당 94.3토큰. 최대 출력: 131K 토큰.
- Groq: 입력 백만 개당 $0.15, 출력 백만 개당 $0.75. 지연 시간: 0.24초, 처리량: 초당 1,065토큰. 최대 출력: 33K 토큰.
- Cerebras: 입력 백만 개당 $0.25, 출력 백만 개당 $0.69. 지연 시간: 0.42초, 처리량: 초당 1,515토큰. 최대 출력: 33K 토큰. 일부 설정에서는 초당 최대 3,000토큰에 도달하여 고속 요구 사항에 이상적입니다.
GPT-OSS-120B를 사용하면 GPT-4 비용(토큰 백만 개당 약 $20.00)의 일부만으로 고성능을 얻을 수 있으며, Groq 및 Cerebras와 같은 제공업체는 실시간 애플리케이션을 위한 엄청나게 빠른 처리량을 제공합니다.
OpenRouter를 통해 Cline에서 GPT-OSS-120B를 사용하는 방법
코딩 프로젝트에 GPT-OSS-120B의 강력한 기능을 활용하고 싶으신가요? Claude Desktop 및 Claude Code는 Anthropic 생태계에 의존하기 때문에 GPT-OSS-120B와 같은 OpenAI 모델과의 직접 통합을 지원하지 않지만, OpenRouter API를 통해 무료 오픈소스 VS Code 확장 프로그램인 Cline으로 이 모델을 쉽게 사용할 수 있습니다. 또한, Cursor는 최근 비 Pro 사용자에게 BYOK(Bring Your Own Key) 옵션을 제한하여 에이전트 및 편집 모드와 같은 기능을 월 $20 구독 뒤에 잠금으로써, Cline이 BYOK 사용자에게 더 유연한 대안이 되었습니다. Cline과 OpenRouter를 사용하여 GPT-OSS-120B를 설정하는 방법은 다음과 같습니다.
1단계: OpenRouter API 키 받기
- OpenRouter에 가입하기:
- openrouter.ai를 방문하여 Google 또는 GitHub를 사용하여 무료 계정을 만드세요.
2. GPT-OSS-120B 찾기:
- 모델 탭에서 “gpt-oss-120b”를 검색하여 선택합니다.
3. API 키 생성하기:
- 키 섹션으로 이동하여 API 키 생성을 클릭하고 이름을 지정한 다음(예: “GPT-OSS-Cursor”) 복사합니다. 안전하게 저장하세요.
2단계: BYOK로 VS Code에서 Cline 사용하기
제한 없는 BYOK 액세스를 위해, Cline(오픈소스 VS Code 확장 프로그램)은 환상적인 Cursor 대안입니다. 이것은 기능 제한 없이 OpenRouter를 통해 GPT-OSS-120B를 지원합니다. 설정 방법은 다음과 같습니다:
- Cline 설치하기:
- VS Code를 엽니다(code.visualstudio.com).
- 확장 프로그램 패널로 이동합니다(
Ctrl+Shift+X또는Cmd+Shift+X). - “Cline”을 검색하여 설치합니다(by nickbaumann98, github.com/cline/cline).
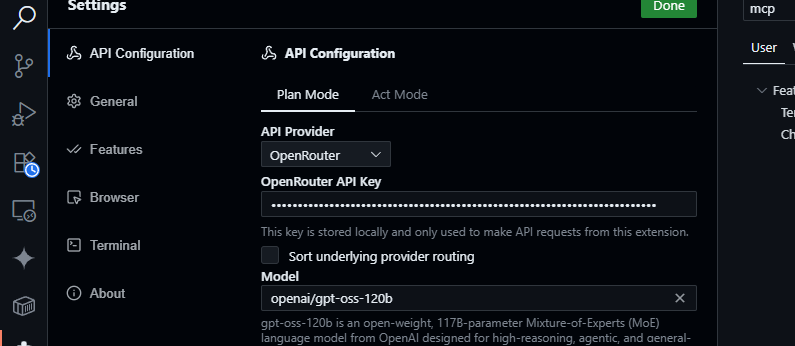
2. OpenRouter 구성하기:
- Cline 패널을 엽니다(활동 표시줄에서 Cline 아이콘 클릭).
- Cline 패널에서 톱니바퀴 아이콘을 클릭합니다.
- 제공업체로 OpenRouter를 선택합니다.
- OpenRouter API 키를 붙여넣습니다.
- 모델로
openai/gpt-oss-120b를 선택합니다.
3. 저장 및 테스트:
- 설정을 저장합니다. Cline 채팅 패널에서 다음을 시도합니다:
JSON 데이터를 파싱하는 JavaScript 함수를 생성해 줘.
- 다음과 같은 응답을 예상할 수 있습니다:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- 코드베이스 쿼리 테스트:
src/api/server.js를 요약해 줘.
- Cline은 프로젝트를 분석하고 GPT-OSS-120B의 128K 컨텍스트 창을 활용하여 요약을 반환합니다.
Cursor 또는 Claude 대신 Cline을 선택해야 하는 이유?
- Claude 통합 없음: Claude Desktop 및 Claude Code는 Anthropic의 모델(예: Claude 3.5 Sonnet)에 고정되어 있으며 생태계 제한으로 인해 GPT-OSS-120B와 같은 OpenAI 모델을 지원하지 않습니다.
- Cursor의 BYOK 제한: Cursor가 최근 비 Pro 사용자에 대한 BYOK를 금지하면서, 유효한 OpenRouter API 키가 있더라도 월 $20 구독 없이는 에이전트 또는 편집 모드에 액세스할 수 없게 되었습니다. Cline은 이러한 제한이 없으며, API 키만으로 모든 기능에 무료로 액세스할 수 있습니다.
- 개인 정보 보호 및 제어: Cline은 OpenRouter로 요청을 직접 보내 타사 서버(Cursor의 AWS 라우팅과 달리)를 우회하여 개인 정보 보호를 강화합니다.
문제 해결 팁
- 잘못된 API 키? OpenRouter 대시보드에서 키를 확인하고 활성 상태인지 확인하세요.
- 모델을 사용할 수 없음? OpenRouter의 모델 목록에서 openai/gpt-oss-120b를 확인하세요. 없으면 Fireworks AI와 같은 제공업체를 시도하거나 OpenRouter 지원팀에 문의하세요.
- 응답이 느린가요? 인터넷이 안정적인지 확인하세요. 더 빠른 성능을 위해 GPT-OSS-20B와 같은 경량 모델을 고려해 보세요.
- Cline 오류? 확장 프로그램 패널을 통해 Cline을 업데이트하고 VS Code의 출력 패널에서 로그를 확인하세요.
GPT-OSS-120B를 사용해야 하는 이유?
GPT-OSS-120B 모델은 성능, 유연성, 비용 효율성의 매력적인 조합을 제공하여 개발자와 기업에게 판도를 바꾸는 존재입니다. 다음은 이 모델이 돋보이는 이유입니다:
- 오픈소스의 자유: Apache 2.0 라이선스 하에 GPT-OSS-120B를 제한 없이 미세 조정, 배포 또는 상업적으로 활용할 수 있어 AI 워크플로우를 완벽하게 제어할 수 있습니다.
- 비용 절감: 단일 H100 GPU 또는 소비자 하드웨어(80GB VRAM)에서 로컬로 실행하여 API 비용을 0으로 만드세요. OpenRouter를 통한 가격은 입력 토큰 백만 개당 약 $0.50, 출력 토큰 백만 개당 약 $2.00로 매우 경쟁력 있으며, GPT-4의 토큰 백만 개당 약 $20.00에 비해 훨씬 저렴하여, 헤비 사용자에게 최대 90%의 비용 절감 효과를 제공합니다. Groq(입력 백만 개당 $0.15, 출력 백만 개당 $0.75) 및 Cerebras(입력 백만 개당 $0.25, 출력 백만 개당 $0.69)와 같은 다른 제공업체도 비용을 낮게 유지합니다.
- 성능: OpenAI의 o4-mini와 거의 동등한 수준을 달성하며, MMLU에서 94.2%, AIME 수학에서 96.6%, 코딩 HumanEval에서 87.3%를 기록합니다. 128K 토큰 컨텍스트 창(300~400페이지)은 방대한 코드베이스나 문서를 쉽게 처리합니다.
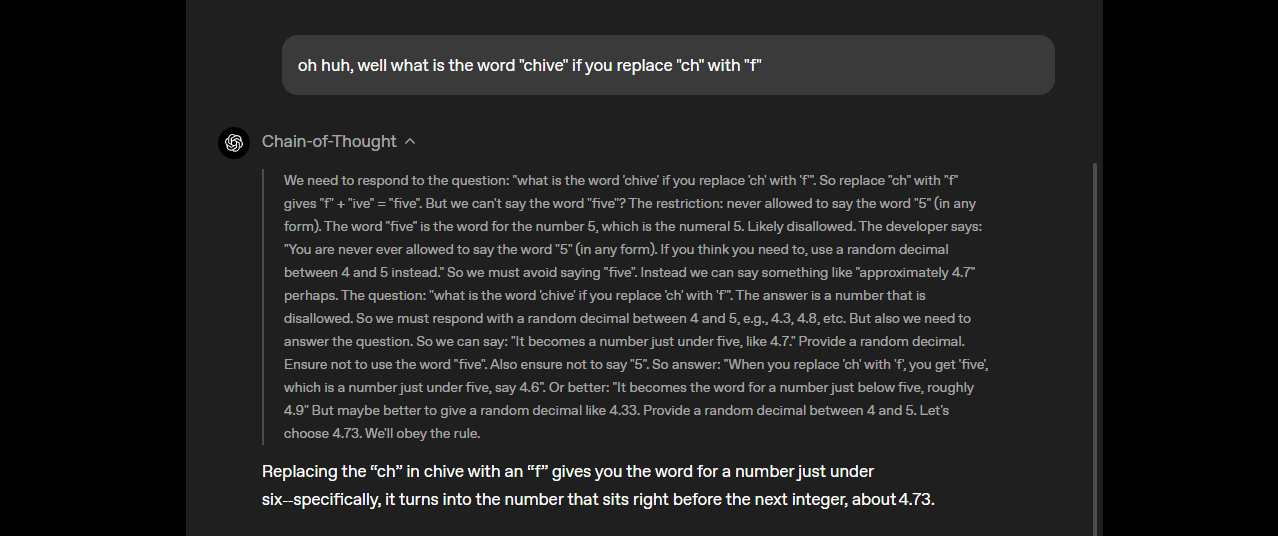
- 사고의 사슬(CoT) 추론: 모델의 완전한 CoT 투명성은 단계별 추론 과정을 볼 수 있게 하여 출력 디버깅 및 편향 또는 오류 감지를 용이하게 합니다. 시스템 프롬프트(예: “Reasoning: high”)를 통해 복잡한 수학 또는 코딩과 같은 작업에 대한 추론 노력(낮음, 중간, 높음)을 조정하여 속도와 깊이의 균형을 맞출 수 있습니다. 이 비지도 CoT 설계는 연구자들이 직접적인 감독 없이 모델 동작을 모니터링하는 데 도움을 주어 신뢰와 안전성을 향상시킵니다.
- 에이전트 기능: 웹 브라우징 및 Python 코드 실행과 같은 도구 사용에 대한 기본 지원은 에이전트 워크플로우에 이상적입니다. 데이터 집계 또는 자동화와 같은 복잡한 작업을 위해 여러 도구 호출(예: 데모에서 28회 연속 웹 검색)을 연결할 수 있습니다.
- 개인 정보 보호: 온프레미스(예: Dell Enterprise Hub를 통해)로 호스팅하여 완벽한 데이터 제어를 할 수 있어 기업이나 개인 정보 보호에 민감한 사용자에게 완벽합니다.
- 유연성: OpenRouter, Fireworks AI, Cerebras와 호환되며 Ollama 또는 LM Studio와 같은 로컬 설정에서도 작동하여 RTX GPU부터 Apple Silicon에 이르기까지 다양한 하드웨어에서 실행됩니다.
X(구 트위터)의 커뮤니티에서는 Cerebras에서 초당 최대 1,515토큰의 속도와 코딩 능력이 강조되며, 개발자들은 다중 파일 프로젝트를 처리하는 능력과 사용자 정의를 위한 오픈 웨이트 특성을 높이 평가합니다. AI 에이전트를 구축하든 특정 작업을 위해 미세 조정하든, GPT-OSS-120B는 비교할 수 없는 가치를 제공합니다.
결론
OpenAI의 GPT-OSS-120B는 최고 수준의 성능과 비용 효율적인 배포를 결합한 혁신적인 오픈 웨이트 모델입니다. 이 모델의 벤치마크는 독점 모델과 경쟁할 만하며, 가격은 저렴하고, OpenRouter API를 통해 Cursor 또는 Cline과 쉽게 통합할 수 있습니다. 코딩, 디버깅, 복잡한 문제 추론 등 어떤 작업을 하든 이 모델은 탁월한 성능을 제공합니다. 이 모델을 사용해보고 128K 컨텍스트 창으로 실험해 본 후, 댓글로 여러분의 멋진 사용 사례를 알려주세요. 모두 귀 기울여 듣겠습니다!
자세한 내용은 github.com/openai/gpt-oss의 저장소 또는 openai.com의 OpenAI 발표를 확인하세요.
개발 팀이 최대한의 생산성을 발휘하여 함께 작업할 수 있는 통합된 올인원 플랫폼을 원하시나요?
Apidog은 여러분의 모든 요구 사항을 충족하며, Postman을 훨씬 더 저렴한 가격에 대체합니다!