
지능형 애플리케이션을 구축하는 개발자들은 GPT-5.2와 같은 최첨단 모델을 워크플로우에 통합하는 데 어려움을 겪는 경우가 많습니다. OpenAI가 AI 기능의 최신 개척지로 출시한 GPT-5.2는 코드 생성, 이미지 인식 및 다단계 추론 분야에서 한계를 뛰어넘습니다. GPT-5.2를 통합하는 것은 단순히 실험하기 위해서가 아니라 복잡한 전문 작업을 처리하는 강력하고 확장 가능한 솔루션을 배포하기 위함입니다. 그러나 변형 선택부터 매개변수 튜닝에 이르기까지 API의 깊이는 체계적인 접근 방식을 요구합니다. 바로 이 지점에서 Apidog와 같은 도구가 등장하여 API 설계, 테스트 및 문서화를 단순화함으로써 개발자들이 반복적인 작업보다는 혁신에 집중할 수 있도록 돕습니다.
GPT-5.2 이해: 핵심 기능과 개발자에게 중요한 이유
GPT-5.2를 선택하는 이유는 이전 버전보다 정확성과 효율성에서 뛰어난 성능을 보이기 때문입니다. OpenAI는 GPT-5.2를 지식 작업을 위해 최적화된 스위트로 포지셔닝하며, 다양한 벤치마크에서 최첨단 결과를 달성합니다. 예를 들어, 코딩 작업에서 SWE-Bench Verified에서 80.0%의 점수를 획득하여 더 적은 반복으로 더 정확한 소프트웨어 솔루션을 생성할 수 있습니다. 또한, 시각 능력은 차트 추론에서 오류율을 절반으로 줄여 자동화된 데이터 시각화 도구와 같은 애플리케이션을 가능하게 합니다.
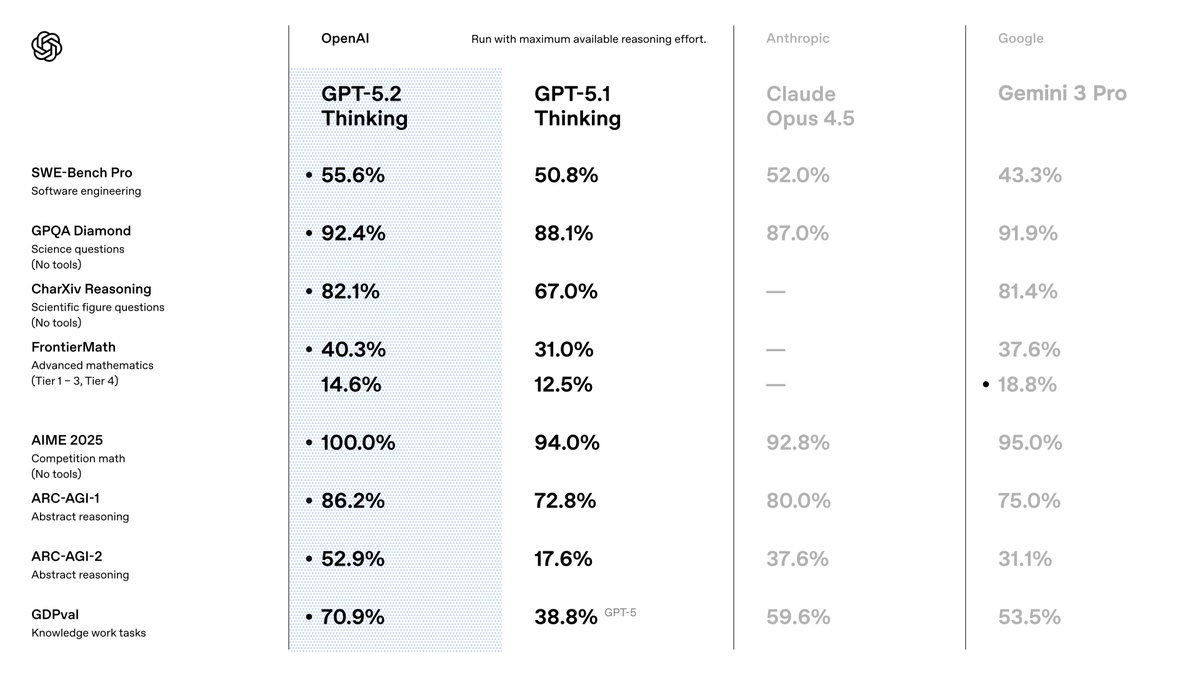
GPT-5.1에서 전환하면 검색 지원 쿼리에서 환각(hallucinations)이 30% 감소하는 등 사실성이 향상되었으며, 최대 256k 토큰까지 거의 완벽한 정확도로 긴 컨텍스트를 처리하는 것을 확인할 수 있습니다. 이러한 기능은 파이프라인에서 후처리 필요성을 줄이기 때문에 중요합니다. 또한 다단계 벤치마크에서 98.7%를 기록한 향상된 도구 호출 기능을 통해 에이전트 시스템을 간소화할 수 있습니다.
API 사용자에게 GPT-5.2는 기존 OpenAI 생태계에 원활하게 통합됩니다. 채팅 완성(Chat Completions) 또는 응답(Responses) API를 통해 액세스하며, 창의성 제어를 위한 온도(temperature)와 같은 매개변수를 지원합니다. 그러나 성공은 올바른 변형을 선택하는 데 달려 있습니다. 다음으로 이를 살펴보겠습니다.
GPT-5.2 변형 탐색: 필요에 맞게 성능 조정
GPT-5.2 는 속도, 깊이 및 비용의 균형을 맞추는 변형을 제공하여 모델 동작을 작업 요구 사항에 맞게 조정할 수 있습니다. 단일 모델과 달리, Instant, Thinking, Pro와 같은 옵션들은 유연성을 제공합니다. API 요청에서 특정 모델 식별자를 통해 이들을 활성화할 수 있습니다.
GPT-5.2 Instant (gpt-5.2-chat-latest)로 시작하세요. 이 변형은 빠른 정보 검색이나 기술 문서 작성과 같은 일상적인 상호작용을 위해 낮은 지연 시간을 우선시합니다. 개발자들은 200ms 미만의 응답 시간이 필수적인 챗봇이나 실시간 비서에 이 변형을 선호합니다. 정교한 정확도로 번역 및 사용법 안내를 처리하여 소비자 대상 앱에 이상적입니다.
다음으로 GPT-5.2 Thinking (gpt-5.2)을 고려해 보세요. 이것은 긴 문서 요약이나 논리적 계획과 같은 심층 분석에 배포합니다. 그것의 추론 엔진은 수학 및 의사 결정에 뛰어나며 FrontierMath 문제의 40.3%를 해결합니다. 여기서 reasoning 매개변수를 'high' 또는 'xhigh'로 설정하여 복잡한 쿼리에 대한 출력 품질을 증폭시키세요. 예를 들어, 프로젝트 관리 도구에서는 최소한의 오류로 다단계 워크플로우를 조정합니다.
마지막으로, GPT-5.2 Pro (gpt-5.2-pro)는 까다로운 분야에서 최고 수준의 성능을 목표로 합니다. 과학 질문에 대한 GPQA Diamond에서 93.2%를 자랑하며, 예외 상황 실패가 적어 프로그래밍에서 빛을 발합니다. 이것은 정밀성이 속도보다 중요한 R&D 프로토타입이나 금융 모델링과 같은 고위험 환경을 위해 보류합니다.
공유된 이미지는 "Max", "Mini", "High", "Low", "Fast" 모드를 포함한 이들의 토글을 보여줍니다. 이들은 추론 노력과 일치합니다: 즉각적인 응답을 위한 'none', 기본 작업을 위한 'low', 철저한 분석을 위한 'xhigh'까지. API 매개변수를 통해 이들을 토글하여 모델이 동적으로 적응하도록 할 수 있습니다. 예를 들어, 깊이를 희생하지 않고 속도를 우선시하는 균형 잡힌 코딩 세션을 위해 "Max High Fast"로 전환하세요.
변형을 신중하게 선택함으로써 리소스 사용을 최적화할 수 있습니다. 이제 이러한 호출을 수행하기 위한 액세스를 설정합니다.
GPT-5.2 API 액세스 설정: 인증 및 환경 준비
API 자격 증명을 확보하여 통합을 시작합니다. OpenAI는 플랫폼 대시보드에서 생성할 수 있는 API 키를 요구합니다. platform.openai.com으로 이동하여 필요한 경우 계정을 생성하고 "API 키"에서 키를 발급하세요.
다음으로 OpenAI Python SDK를 설치하세요. 터미널에서 pip install openai을 실행하세요. 이 라이브러리는 HTTP 요청, 재시도 및 스트리밍을 기본적으로 처리합니다. Node.js 사용자에게는 npm install openai이 유사한 기능을 제공합니다. 다음과 같이 임포트합니다:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
간단한 완성으로 연결성을 테스트합니다:
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explain quantum entanglement briefly."}]
)
print(response.choices[0].message.content)
이 호출은 설정을 확인합니다. 오류가 발생하면 속도 제한(Tier 1의 경우 기본 3,500 RPM) 또는 키 유효성을 확인하세요. 또한 확장된 컨텍스트를 위한 /compact와 같은 사용자 지정 엔드포인트에 대한 기본 URL을 구성합니다: client = OpenAI(base_url="https://api.openai.com/v1", api_key=...).
기본 사항이 갖춰졌으니, 이제 요청 작성 방법을 살펴보겠습니다.
효과적인 GPT-5.2 API 요청 작성: 매개변수 및 모범 사례
채팅 완성(Chat Completions) 엔드포인트 (/v1/chat/completions)를 사용하여 요청을 구성합니다. 페이로드에는 model, messages, 그리고 temperature (결정론을 위한 0-2) 및 max_tokens (최대 4096 출력)와 같은 선택적 매개변수가 포함됩니다.
GPT-5.2의 특정 기능을 위해, 깊이를 제어하기 위해 reasoning_effort를 포함하세요:
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Write a Python function for Fibonacci sequence."}],
reasoning_effort="high", # "Max High" 토글과 일치
temperature=0.7,
max_tokens=500
)
이것은 단계별 추론을 통해 코드를 생성하여 버그를 줄입니다. 대화를 위해 메시지를 연결하여 턴 간에 컨텍스트를 유지합니다. 비전 작업을 위해서는 "image_url" 유형의 content를 통해 이미지를 업로드합니다:
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe this chart's trends."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
모범 사례에는 비용 절감을 위한 요청 배치(batching)와 실시간 UI를 위한 스트리밍(stream=True) 사용이 포함됩니다. 프롬프트를 정교하게 다듬기 위해 응답의 usage를 통해 토큰 사용량을 모니터링하세요. 또한 함수 호출을 위한 도구를 활성화하십시오. 외부 API에 대한 스키마를 정의하면 GPT-5.2가 이를 자율적으로 실행합니다.
이것들을 효율적으로 테스트하려면 Apidog를 통합하세요. Apidog는 OpenAI 엔드포인트를 모의하여 실제 할당량을 소모하지 않고 변형을 시뮬레이션할 수 있게 합니다.
Apidog와 GPT-5.2 통합: 테스트 및 문서화 간소화
Apidog는 GPT-5.2 API 워크플로우를 관리하는 방식을 변화시킵니다. 올인원 플랫폼으로서 OpenAPI 스펙 가져오기, 요청 빌딩 및 자동화된 테스트를 지원합니다. OpenAI 스키마를 Apidog로 가져온 다음 GPT-5.2 호출을 위한 컬렉션을 설계합니다.
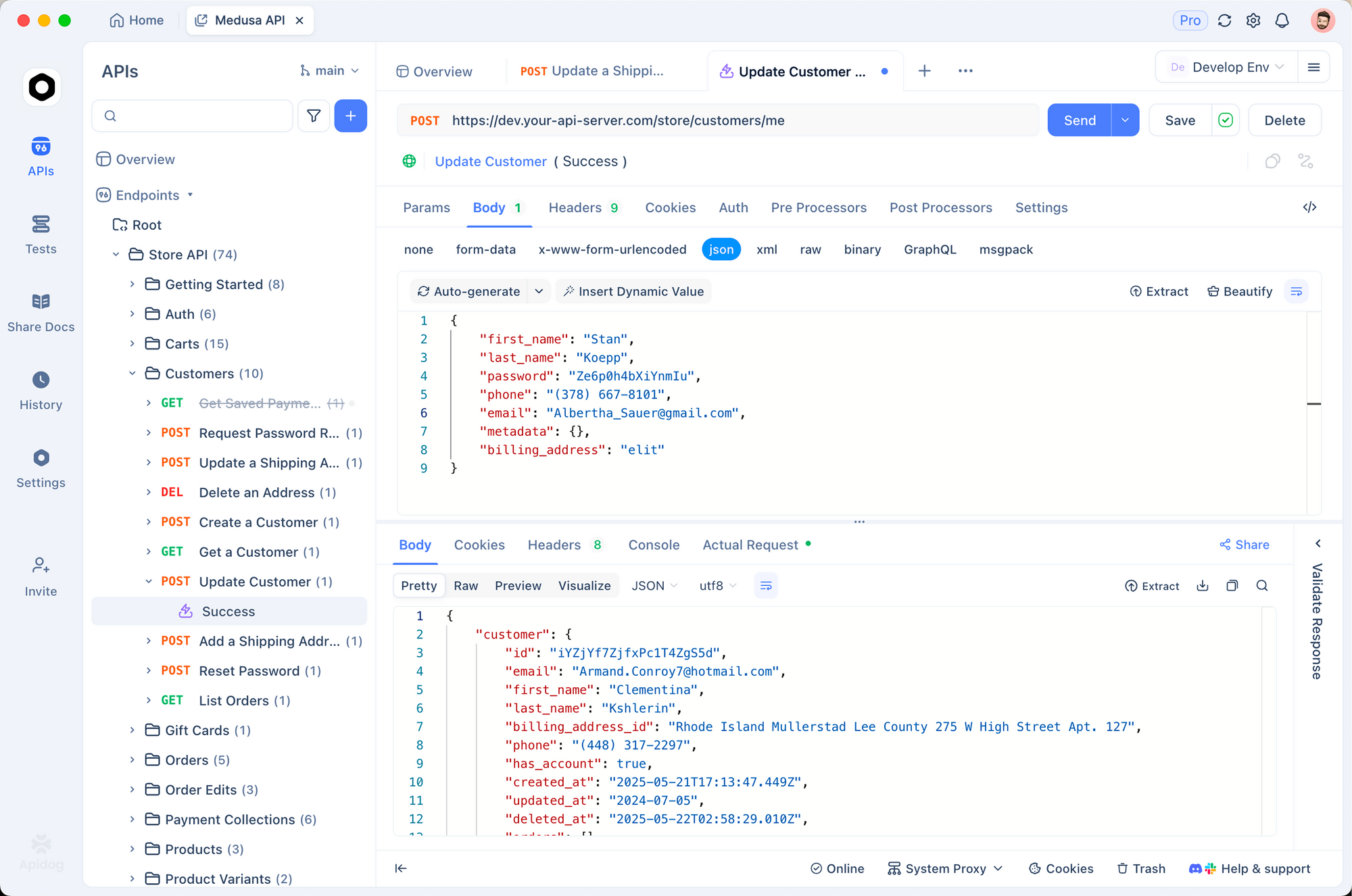
Apidog에서 새 프로젝트를 생성하는 것으로 시작하세요. https://api.openai.com/v1/chat/completions에 HTTP 요청을 추가하고, 헤더(Authorization: Bearer YOUR_KEY, Content-Type: application/json)를 설정한 다음 샘플 본문을 붙여넣으세요. "gpt-5.2-pro"와 같은 모델의 변수를 토글하여 출력을 나란히 비교하세요.
Apidog의 강점은 모의 서버에 있습니다. GPT-5.2의 JSON 구조를 모방한 가짜 응답을 생성하여 오프라인 개발에 이상적입니다. 예를 들어, 상세한 추론 트레이스가 포함된 "Max Extra High" 응답을 시뮬레이션하세요. 토큰 수 또는 환각률에 대한 어설션으로 테스트를 실행하세요.

또한 Apidog의 내장 편집기로 API를 문서화하세요. 동료들이 엔드포인트를 탐색하는 데 사용할 수 있는 대화형 문서를 생성하세요. 이식성을 위해 Postman 또는 HAR로 내보내세요. 프로덕션 환경에서는 Apidog가 호출을 모니터링하고 "Low Fast" 모드에서의 높은 지연 시간과 같은 이상 징후에 대해 경고합니다.
Apidog를 프로세스에 통합함으로써 반복 속도를 가속화할 수 있습니다. 무료로 다운로드하고 첫 GPT-5.2 요청을 가져와 몇 분 안에 차이를 경험해 보세요.
GPT-5.2 API 가격: 비용과 기능을 전략적으로 균형 맞추기
GPT-5.2 애플리케이션을 확장할 때 가격을 무시할 수 없습니다. OpenAI는 사용량에 따라 계층을 반영하여 백만 토큰당 비용을 책정합니다. GPT-5.2 Instant (gpt-5.2-chat-latest)의 경우, 1백만 입력 토큰당 1.75달러, 1백만 출력 토큰당 14달러를 예상할 수 있습니다. 캐시된 입력은 0.175달러로 90% 절감되어 반복적인 컨텍스트 사용을 장려합니다.
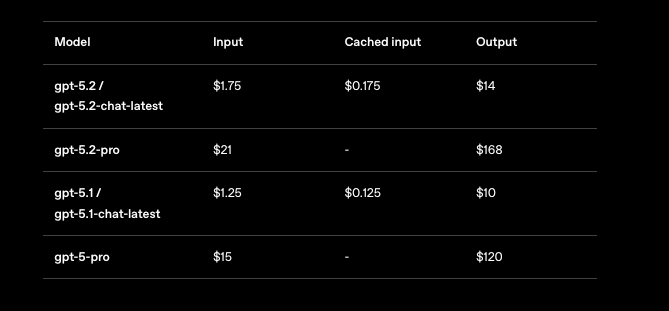
GPT-5.2 Thinking (gpt-5.2)은 이러한 요율을 반영하여 균형 잡힌 작업에 비용 효율적입니다. 그러나 GPT-5.2 Pro (gpt-5.2-pro)는 더 많은 비용을 요구합니다: 1백만 입력 토큰당 21달러, 1백만 출력 토큰당 168달러. 이 프리미엄은 전문가 수준 쿼리에서의 우수한 정확도를 반영하지만, ROI를 신중하게 평가해야 합니다.
전반적으로 GPT-5.2는 토큰 효율성이 뛰어나 품질 높은 출력을 위해 GPT-5.1에 비해 총 지출을 낮추는 경우가 많습니다. 대시보드의 사용량 분석기를 통해 추적할 수 있습니다. 기업의 경우 맞춤형 계층을 협상하세요. Apidog와 같은 도구는 시뮬레이션된 토큰 흐름을 기록하여 비용을 예측하는 데 도움이 됩니다.
이러한 수치를 이해했으므로, 이제 실습 예제로 넘어가겠습니다.
실용적인 예시: GPT-5.2를 사용한 코드 생성 및 비전 작업
실제 시나리오에 GPT-5.2를 적용할 수 있습니다. 코드 생성을 고려해 보세요: 상태 관리가 있는 React 컴포넌트를 요청합니다.
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Build a React todo list with useReducer."}],
reasoning_effort="medium"
)
출력은 깔끔하고 주석 처리된 코드(벤치마크에 80% 일치)를 생성합니다. "성능 최적화"로 후속 조치를 취하여 반복적으로 개선합니다.
비전의 경우 스크린샷을 분석합니다. UI 목업을 업로드하고 "접근성 개선 사항을 제안해 주세요"라고 쿼리합니다. GPT-5.2는 색상 대비와 같은 문제를 식별하고, 오류율이 절반으로 줄어든 것을 활용합니다.
다중 도구 에이전트에서는 데이터베이스 쿼리를 위한 함수를 정의합니다. GPT-5.2는 호출을 조율하여 20개 이상의 도구를 사용하는 대규모 에이전트의 지연 시간을 줄입니다.
이러한 예시는 다재다능함을 보여줍니다. 그러나 오류는 발생할 수 있습니다. 재시도 및 폴백으로 처리하세요.
GPT-5.2 API 호출에서 오류 및 예외 처리
속도 제한 또는 잘못된 매개변수를 만날 수 있습니다. 호출을 try-except로 감싸세요:
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # 백오프
response = client.chat.completions.create(...)
환각(hallucinations)의 경우 검색 도구와 교차 검증하세요. 긴 컨텍스트에서는 /compact를 사용하여 기록을 압축하세요. 민감한 앱에서는 필터를 적용하여 편향을 모니터링하세요.
Apidog가 여기서 도움을 줍니다: 오류 시나리오에 대한 테스트를 스크립팅하여 복원력을 보장합니다.
고급 최적화: 프로덕션을 위한 GPT-5.2 확장
프롬프트 미세 조정 및 영구 스레드를 위한 Assistants API를 사용하여 확장할 수 있습니다. 반복되는 입력에 대해 캐싱을 구현하세요. 글로벌 앱의 경우 엣지 서버를 통해 라우팅하세요.
LangChain과 같은 프레임워크와 통합하세요: RAG 시스템을 위해 GPT-5.2를 벡터 저장소와 연결하세요.
마지막으로, OpenAI는 빠르게 반복하므로 최신 정보를 유지하세요.
결론: GPT-5.2 API를 마스터하고 미래를 구축하세요
이제 GPT-5.2를 효과적으로 활용할 도구를 갖게 되었습니다. 변형 선택부터 Apidog로 강화된 테스트에 이르기까지, 이러한 단계를 적용하여 프로젝트를 발전시키세요. 신중한 사용을 위한 가격은 여전히 접근 가능하며, 한때 연구실에만 국한되었던 기능을 잠금 해제합니다.
오늘 실험해 보세요: GPT-5.2 에이전트를 프로토타이핑하고 이점을 측정해 보세요. 댓글에 여러분의 빌드를 공유해 주세요. 어떤 어려움에 직면했나요? 더 심층적인 내용은 OpenAI 문서를 탐색하세요. 대담하게 구축하세요.