
2025년 AI 개발 동향에 주목해 오셨다면, GPT-5와 경쟁하고 (때로는 능가하는) 차세대 멀티모달 AI 모델인 Google Gemini 3에 대한 수많은 소식을 들으셨을 겁니다. 소프트웨어 엔지니어든, 스타트업 창업자든, AI 애호가든, 아니면 단순히 Gemini 3가 무엇을 할 수 있는지 궁금한 사람이든, Google Gemini 3 API 사용법을 배우는 것은 훨씬 더 스마트하고 역동적인 애플리케이션을 구축할 수 있는 문을 열어줍니다.
하지만 솔직히 말해서, 이제 막 시작하는 분들에게는 Google의 설명서가 다소 난해하게 느껴질 수 있습니다. 그래서 이 가이드에서는 모든 것을 명확하고, 친절하며, 초보자 친화적인 방식으로 설명해 드리겠습니다.
이제 Google의 가장 진보된 AI 모델의 힘을 활용해 봅시다!
Google Gemini 3란 무엇인가요?
Google Gemini 3는 Google의 멀티모달 AI 제품군의 최신 모델입니다. 이전 모델과 달리 Gemini 3는 다음을 위해 최적화되었습니다:
- 추론 및 문제 해결
- 멀티모달 입력/출력 (텍스트, 이미지, 오디오, 비디오 임베딩)
- 도구 사용 및 에이전트 워크플로우
- 낮은 지연 시간 엔드포인트를 통한 빠른 추론
- 작업에 따른 동적 모델 전환
하지만 가장 큰 특징은 이것입니다:
Gemini 3는 두 가지 주요 "사고 모드"를 도입합니다
thinking_level 매개변수는 모델이 응답을 생성하기 전 내부 추론 과정의 최대 깊이를 제어합니다. Gemini 3는 이러한 수준을 엄격한 토큰 보장보다는 상대적인 사고 허용치로 간주합니다. thinking_level이 지정되지 않은 경우, Gemini 3 Pro는 기본적으로 high로 설정됩니다.
- 고수준/동적 사고 (High/Dynamic Thinking): 추론 깊이를 최대화합니다. 모델이 첫 토큰에 도달하는 데 훨씬 더 오랜 시간이 걸릴 수 있지만, 결과는 더 신중하게 추론됩니다.
- 저수준 사고 (Low Thinking): 지연 시간과 비용을 최소화합니다. 간단한 지침 따르기, 채팅 또는 높은 처리량이 필요한 애플리케이션에 가장 적합합니다.
많은 초보자는 아직 모르지만, 올바른 모드를 선택하면 출력 품질이 크게 향상되고 *동시에* 비용을 제어하는 데 도움이 됩니다.
API를 사용하여 모드를 선택하는 방법에 대해 곧 설명해 드리겠습니다.
UI 도구 대신 Gemini 3 API를 사용해야 하는 이유는 무엇인가요?
물론 Google AI Studio 내에서 Gemini를 사용할 수 있습니다. 하지만 다음을 원한다면:
- 애플리케이션 구축
- 작업 자동화
- 워크플로우에 모델 통합
- 챗봇 생성
- 데이터 처리
- 에이전트 훈련
- 멀티모달 작업 실행
그렇다면 Gemini 3 API가 필요합니다.
이 가이드에서는 다음 이유로 REST API에 중점을 둡니다.
- 초보자에게 더 쉽기 때문입니다
- 클라이언트 라이브러리가 필요하지 않습니다
- Apidog 또는 Postman에서 빠르게 테스트할 수 있습니다
- 어떤 백엔드 환경에서도 작동합니다
Gemini 3 API 작동 방식 (간단한 개요)
Gemini는 고급 기능을 가지고 있지만, API 자체는 매우 간단합니다.
다음으로 POST 요청을 보냅니다…
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=YOUR_API_KEY>
다음과 같은 JSON을 포함합니다:
- 텍스트 프롬프트
- 메시지 목록 (선택 사항)
- 모델 설정
- 안전 설정
다음과 같은 응답을 받습니다…
- 모델 출력 텍스트
- 추론 구조 (고수준/동적 사고의 경우)
- 인용
- 메타데이터
- 멀티모달 객체 (해당하는 경우)
이 구조를 이해하면 다른 모든 것이 더 쉬워집니다.
시작하기: Gemini API의 첫 단계
1단계: API 키 받기
API 키를 Google에게 "네, Gemini를 사용할 수 있습니다"라고 말하는 특별한 암호라고 생각하세요. 다음은 API 키를 얻는 방법입니다:
- Google AI Studio로 이동합니다
- Google 계정으로 로그인합니다
- 왼쪽 사이드바에서 "API 키 생성"을 클릭합니다
- 키 이름을 지정하고 생성합니다
- 이 키를 복사하여 안전한 곳에 저장하세요! 다시 볼 수 없습니다.
중요: API 키를 공유하거나 공개 코드 저장소에 커밋하지 마세요. 비밀번호처럼 다루세요.
2단계: 접근 방식 선택
Gemini와 상호작용하는 두 가지 주요 방법이 있습니다.
- REST API: 범용적인 접근 방식입니다. HTTP 요청을 할 수 있는 모든 프로그래밍 언어에서 작동합니다. 이 방법론에 중점을 둘 것입니다.
- 공식 SDK: Google은 HTTP 세부 사항을 처리해주는 Python, Node.js 및 기타 언어용 편리한 라이브러리를 제공합니다.
기본 사항에 중점을 두기 때문에 REST API 접근 방식을 사용할 것입니다. 이는 모든 곳에서 작동하며 내부에서 무슨 일이 일어나고 있는지 이해하는 데 도움이 됩니다.
Gemini의 사고 모드 이해하기
Gemini의 가장 강력한 기능 중 하나는 다양한 "사고 모드"로 작동하는 능력입니다. 이것은 단순한 마케팅이 아니라 모델이 요청을 처리하는 방식을 근본적으로 변화시킵니다.
저수준 사고 (속도광)
언제 사용해야 하나요: 간단한 작업, 빠른 응답, 그리고 속도와 비용을 최적화할 때 사용합니다.
- 속도: 매우 빠른 응답
- 비용: 더 저렴함
- 사용 사례: 간단한 Q&A, 텍스트 분류, 기본적인 요약, 직관적인 번역
예를 들어:
gemini-3-flash
gemini-3-mini
저수준 사고 모드를 즉각적인 답변을 해주는 지식 있는 친구와 빠르게 대화하는 것으로 생각해보세요.
고수준/동적 사고 (사려 깊은 분석가)
언제 사용해야 하나요: 복잡한 추론, 다단계 문제, 그리고 심층 분석이 필요한 작업에 사용합니다.
- 속도: 더 느림 (응답하기 전에 더 많이 "생각"함)
- 비용: 더 비쌈
- 사용 사례: 복잡한 수학 문제, 논리적 추론, 코드 디버깅, 창의적 글쓰기, 전략 계획
고수준/동적 사고는 전문가와 상담하는 것과 같습니다. 전문가는 모든 측면을 충분히 고려한 후 합리적인 답변을 제공합니다.
예를 들어:
gemini-3-pro
gemini-3-pro-thinking
이 모델들은 더 깊은 추론, 더 긴 주의 범위, 그리고 더 나은 계획 능력을 제공합니다.
가장 좋은 점은 특정 필요에 따라 고수준/동적 사고 (High/Dynamic Thinking)와 저수준 사고 (Low Thinking) 두 가지 모드를 모두 선택할 수 있다는 것입니다. 대부분의 간단한 애플리케이션에는 저수준 사고가 완벽합니다. 더 깊은 추론이 필요할 때는 고수준 사고로 전환하세요.
일반적인 규칙은 다음과 같습니다.
| 작업 유형 | 모델 모드 |
|---|---|
| 연구 | 고수준/동적 사고 |
| 수학/논리 | 고수준/동적 사고 |
| 코드 생성 | 고수준/동적 사고 |
| 고객 채팅 | 저수준 사고 |
| 기본 텍스트 생성 | 저수준 사고 |
| UI 어시스턴트 | 저수준 사고 |
| 실시간 앱 | 저수준 사고 |
REST API에서 각 모델을 선택하는 방법을 보여드리겠습니다.
첫 Gemini 3 REST API 호출 구축하기
가장 간단한 예제부터 시작하겠습니다.
엔드포인트
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>
요청 본문 예시 (JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}
Curl 명령 샘플
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}' \
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>"
고수준/동적 사고 모드 사용하기
추론 모드를 활성화하려면 `gemini-3-pro-thinking`과 같이 이를 지원하는 모델을 사용해야 합니다.
REST API 예시
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Find the race condition in this multi-threaded C++ snippet: [code here]"}]
}]
}'고수준/동적 사고 모드를 사용할 때, 일반적으로 다음을 받게 됩니다.
- 사고 사슬 구조 (요청하지 않으면 숨겨짐)
- 더 일관성 있는 답변
- 느린 응답 시간
- 더 비싼 추론 비용
저는 긴 형식의 추론이나 코드 계획과 같이 정말 중요할 때만 이 모드를 사용할 것을 권장합니다.
저수준 사고 모드 사용하기
저수준 사고 모델은 속도에 최적화되어 있으며 다음에 완벽합니다:
- 자동 완성
- 짧은 메시지
- UI 응답
- 작은 비서
- 챗봇 부가 기능
“Flash”를 사용한 REST API 예시
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "How does AI work?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'저수준 사고 모델은 비용이 훨씬 적게 들고 거의 즉각적인 응답을 반환합니다.
멀티모달 입력 처리 (이미지, PDF, 오디오, 비디오)
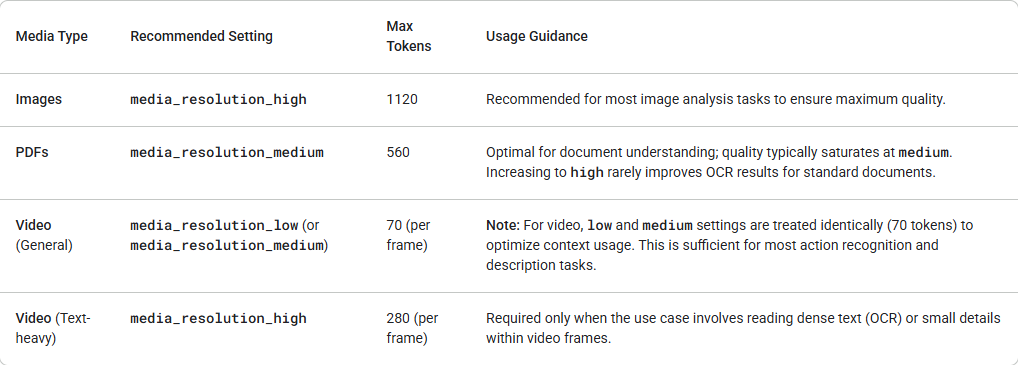
Gemini 3는 `media_resolution` 매개변수를 통해 멀티모달 비전 처리에 대한 세밀한 제어를 도입합니다. 해상도가 높을수록 모델이 미세한 텍스트를 읽거나 작은 세부 사항을 식별하는 능력이 향상되지만, 토큰 사용량과 지연 시간이 증가합니다. `media_resolution` 매개변수는 **입력 이미지 또는 비디오 프레임당 할당되는 최대 토큰 수**를 결정합니다.
이제 `media_resolution_low`, `media_resolution_medium`, `media_resolution_high`로 해상도를 개별 미디어 부분별로 또는 전역적으로 (`generation_config`를 통해) 설정할 수 있습니다. 지정되지 않은 경우, 모델은 미디어 유형에 따라 최적의 기본값을 사용합니다.
Gemini 3는 다음을 포함한 멀티모달 임베딩을 지원합니다:
- 이미지
- 오디오
- 비디오 프레임
- 문서
이미지 업로드 예시 (base64):
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "What is in this image?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'Apidog로 테스트 및 디버깅하기
`curl` 명령은 빠른 테스트에 유용하지만, 실제 애플리케이션을 개발할 때는 번거로워집니다. 바로 이 지점에서 Apidog가 빛을 발합니다.
- API 구성 저장: Gemini 엔드포인트와 API 키를 한 번 설정하고, 모든 테스트에서 재사용하세요.
- 요청 템플릿 생성: 다양한 유형의 프롬프트(대화 시작, 분석 요청, 창의적 글쓰기)를 템플릿으로 저장하세요.
- 사고 모드 나란히 테스트: 저수준 사고 모드와 고수준 사고 모드를 쉽게 전환하여 응답과 성능을 비교하세요.
- 대화 기록 관리: Apidog의 환경 변수를 사용하여 여러 요청에 걸쳐 대화 컨텍스트를 유지하세요.
- 테스트 자동화: Gemini 통합이 올바르게 작동하는지 확인하는 테스트 스위트를 생성하세요.
Apidog에서 Gemini 요청을 설정하는 방법은 다음과 같습니다.
- 다음으로 새 POST 요청을 생성합니다:
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - 실제 API 키로 환경 변수
api_key를 설정합니다 - 본문에서 JSON을 사용합니다:
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. Gemini에게 물어보고 싶은 내용으로 다른 환경 변수 prompt를 설정합니다.
이 접근 방식은 실험을 훨씬 빠르고 체계적으로 만듭니다.
Gemini API를 위한 모범 사례
1. 오류를 우아하게 처리하기
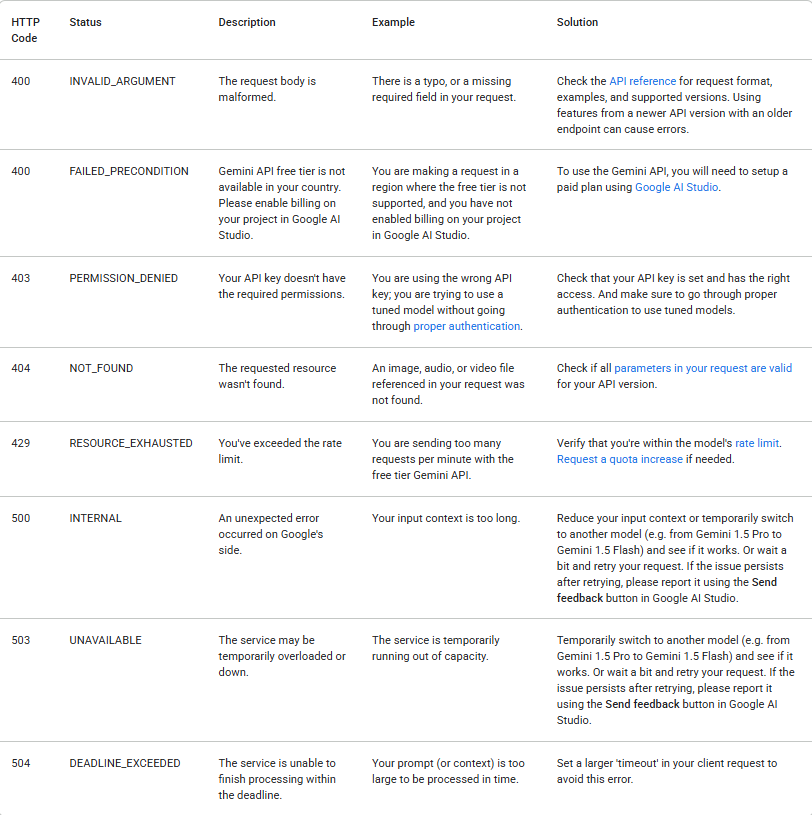
API 호출은 여러 이유로 실패할 수 있습니다. 항상 응답 상태를 확인하고 오류를 적절하게 처리하세요. 다음 표는 발생할 수 있는 일반적인 백엔드 오류 코드와 원인 설명 및 문제 해결 단계를 나열합니다.
2. 비용 관리
Gemini API 사용량은 측정되며 (무료 등급 제한 후) 비용이 발생합니다. 다음 팁을 염두에 두세요.
- 실험을 위해 무료 등급으로 시작하세요
- 간단한 작업에는 가능한 한 저수준 사고 모드를 사용하세요
- 합리적인
maxOutputTokens제한을 설정하세요 - Google AI Studio에서 사용량을 모니터링하세요
토큰은 `z`와 같은 단일 문자이거나 `cat`과 같은 전체 단어일 수 있습니다. 긴 단어는 여러 토큰으로 분할됩니다. 모델이 사용하는 모든 토큰의 집합을 어휘(vocabulary)라고 하며, 텍스트를 토큰으로 분할하는 과정을 *토큰화(tokenization)*라고 합니다.
결제가 활성화되면 Gemini API 호출 비용은 입력 및 출력 토큰 수에 따라 부분적으로 결정되므로, 토큰 수를 세는 방법을 아는 것이 도움이 될 수 있습니다.
3. 더 나은 프롬프트 작성하기
출력의 품질은 입력에 크게 좌우됩니다. 다음은 몇 가지 프롬프트 엔지니어링 팁입니다.
다음 대신: "개에 대해 쓰세요"
다음과 같이 시도: "잠재적 반려동물 소유자를 위해 친근하고 격려하는 어조로, 구조견 입양의 이점에 대한 200단어 분량의 교육적인 블로그 게시물을 작성하세요."
다음 대신: "이 코드를 수정하세요"
다음과 같이 시도: "팩토리얼을 계산해야 하지만 입력 5에 대해 잘못된 결과를 반환하는 이 Python 함수를 디버그해 주세요. 무엇이 잘못되었는지 설명하고 수정된 코드를 제공해 주세요."

4. 올바른 모델 선택
Google은 각기 다른 강점을 가진 여러 Gemini 모델을 제공합니다. 모델 매개변수가 다음 값 내에 있는지 확인하세요.
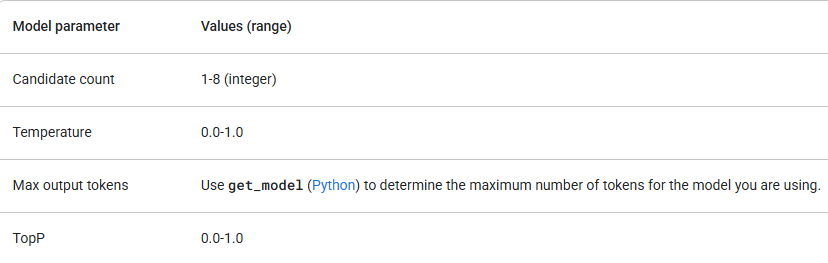
`gemini-1.5-flash`로 시작하고 더 많은 추론 능력이 필요할 때만 업그레이드하세요. 매개변수 값 확인 외에도, 올바른 API 버전(예: `/v1` 또는 `/v1beta`)과 필요한 기능을 지원하는 모델을 사용하고 있는지 확인하세요. 예를 들어, 어떤 기능이 베타 릴리스인 경우, `/v1beta` API 버전에서만 사용할 수 있습니다.
결론: 당신의 AI 여정이 시작됩니다
이제 Google Gemini API로 구축을 시작하는 데 필요한 모든 것을 갖추었습니다. API 키를 얻는 방법, 기본적인 요청을 만드는 방법, 다양한 사고 모드를 이해하는 방법, 심지어 몇 가지 고급 예제까지 살펴보았습니다.
AI API로 작업하는 것은 반복적인 과정임을 기억하세요. 연습을 통해 프롬프트 작성 및 올바른 설정 선택에 더 능숙해질 것입니다. 실험하는 것을 두려워하지 마세요. 그것이 바로 당신이 구축할 수 있는 것의 잠재력을 최대한 발견하는 방법입니다.
가장 중요한 다음 단계는 실험을 시작하는 것입니다. 이 가이드의 예제를 가져와 수정하고, 깨뜨려보고, 무슨 일이 일어나는지 확인하세요. 배우는 가장 좋은 방법은 직접 해보는 것입니다.
초보자에게는 Apidog를 REST API 테스트 도구로 사용하는 것을 강력히 추천합니다. 다음을 도와줍니다.
- 요청 디버그
- 환경 변수 저장
- 컬렉션 실행
- 모델 출력 빠르게 비교
- 팀원과 API 테스트 케이스 공유
그리고 무료이기 때문에 전혀 손해볼 것이 없습니다.