
엔지니어와 개발자는 과도한 자원 요구 없이 고성능을 제공하는 효율적인 모델을 끊임없이 찾고 있습니다. GLM-4.7-Flash는 이러한 환경에서 매력적인 옵션으로 등장합니다. Zhipu AI(Z.ai)가 개발한 이 30B-A3B Mixture-of-Experts (MoE) 모델은 강력함과 효율성의 균형으로 두각을 나타냅니다. 코딩 벤치마크, 추론 작업, 도구 통합에서 탁월하여 로컬 배포 시나리오에 적합합니다.
GLM-4.7-Flash를 로컬에서 실행하면 사용자는 데이터 프라이버시를 유지하고, 지연 시간을 줄이며, 통합을 맞춤 설정할 수 있습니다. Ollama, LM Studio, Hugging Face와 같은 도구들이 이 과정을 간소화합니다.
버튼
이 가이드를 진행하면서 설치 및 사용에 대한 실제적인 통찰력을 얻게 될 것입니다. 먼저 시스템의 기본 요구 사항을 살펴보겠습니다.
GLM-4.7-Flash는 무엇이며 로컬에서 사용해야 하는 이유는 무엇입니까?
GLM-4.7-Flash는 오픈 소스 언어 모델의 발전을 대표합니다. glm4_moe_lite 아키텍처를 기반으로 구축되었으며 MIT 라이선스 하에 BF16 및 F32 텐서 유형을 사용합니다. 이 모델의 논문인 "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models"은 arXiv:2508.06471을 참조하여 도구 사용 및 추론을 위한 모델 훈련에 대해 자세히 설명합니다.
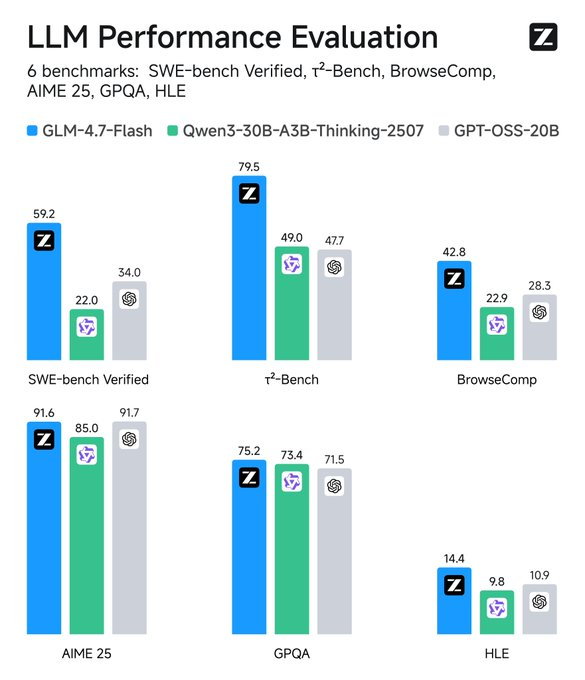
주요 기능으로는 영어 및 중국어 지원, 텍스트 생성, 대화형 작업이 있습니다. 멀티모달 입력을 텍스트로 처리하지만, 텍스트 전용 출력에 중점을 둡니다. 효율적이지만 미세 조정 없이는 특정 영역에서 더 큰 모델과 일치하지 않을 수 있다는 규모의 한계가 있습니다. 훈련 데이터 세부 정보는 공개되지 않았지만, 평가를 통해 코딩 및 에이전트 시나리오에서 그 우위가 확인되었습니다.
사용자들은 API 비용을 피하기 위해 로컬 실행을 선택합니다. Z.ai는 플랫폼을 통해 GLM-4.7-Flash에 대한 무료 티어를 제공하지만, 로컬 배포는 외부 서비스에 대한 의존성을 없애줍니다. 이 접근 방식은 맞춤형 애플리케이션을 구축하는 개발자, 가설을 테스트하는 연구원, 또는 보안을 우선시하는 기업에 적합합니다. 예를 들어, 하드웨어 제약에 맞게 양자화 수준을 제어하여 최적의 성능을 보장할 수 있습니다.
GLM-4.7-Flash 로컬 실행을 위한 시스템 요구 사항
하드웨어는 모델 추론에 결정적인 역할을 합니다. GLM-4.7-Flash는 LM Studio 가이드라인에 명시된 대로 기본 작업에 최소 16GB의 시스템 메모리를 요구합니다. 그러나 GPU 가속은 속도를 크게 향상시킵니다.
Ollama 변형의 경우:
- q4_K_M: 19GB VRAM
- q8_0: 32GB VRAM
- bf16: 60GB VRAM
Hugging Face는 효율성을 위해 torch.bfloat16을 권장하며, 호환되는 NVIDIA GPU(Ampere 또는 이후 아키텍처)가 필요합니다. CPU 전용 추론도 가능하지만, 대규모 컨텍스트의 경우 상당히 느려집니다.
소프트웨어 사전 요구 사항에는 Python 3.8 이상, pip, Git이 포함됩니다. Transformers와 같은 프레임워크는 추가 설치가 필요합니다. GPU 사용을 위해 OS가 CUDA를 지원하는지 확인하십시오. Ubuntu 20.04 또는 WSL2가 설치된 Windows가 잘 작동합니다.
자원이 부족한 경우 양자화를 통해 메모리 사용량을 줄일 수 있습니다. llama.cpp 또는 Unsloth와 같은 도구는 4비트 또는 2비트 버전을 제공하여 요구 사항을 15-20GB VRAM으로 낮춥니다. 이러한 유연성을 통해 RTX 4090과 같은 소비자 하드웨어에도 배포할 수 있습니다.
요구 사항이 충족되면 설치 방법을 살펴보세요. 간단한 Ollama부터 시작하겠습니다.
Ollama로 GLM-4.7-Flash를 설치하고 사용하는 방법
Ollama는 대규모 모델을 로컬에서 실행할 수 있는 접근성 좋은 플랫폼을 제공합니다. 이는 양자화 및 API 서비스를 자동으로 관리합니다.
먼저 Ollama를 설치합니다. 운영 체제에 맞는 실행 파일을 다운로드하여 실행하세요.

ollama --version을 사용하여 설치를 확인하고, GLM-4.7-Flash가 요구하는 0.14.3 버전 이상인지 확인하세요.

다음으로 모델을 가져옵니다: ollama pull glm-4.7-flash를 실행하세요.

메모리 사용량을 줄이려면 glm-4.7-flash:q4_K_M과 같은 변형을 선택하세요. 이 명령은 q4 버전에 대해 약 19GB를 다운로드합니다.
모델을 대화형으로 실행합니다: ollama run glm-4.7-flash를 입력합니다. "피보나치 수열을 위한 Python 코드를 생성해 줘."와 같은 프롬프트를 입력합니다. 모델은 코딩 강점을 활용하여 논리적인 출력을 제공합니다.
프로그래밍 방식으로 접근하려면 API를 사용하세요. curl 요청을 보냅니다:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
이것은 응답과 함께 JSON을 반환합니다. Python에서는 ollama 라이브러리와 통합합니다:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript도 ollama npm 패키지로 유사하게 따릅니다.
Modelfile을 편집하여 구성을 사용자 지정하세요. 코딩 작업에서 결정론적인 출력을 위해 온도를 0.7로 설정합니다. Ollama의 최신 모드는 필요한 경우 최신 게시물을 가져오지만, 여기서는 로컬 추론에 중점을 둡니다.
이 방법은 빠른 설정에 적합합니다. 그러나 그래픽 인터페이스를 위해서는 LM Studio를 사용하세요.
LM Studio에서 GLM-4.7-Flash 설정하기
LM Studio는 모델 관리를 위한 사용자 친화적인 GUI를 제공합니다. 다운로드하여 설치하세요.
모델 허브에서 "zai-org/glm-4.7-flash"를 검색합니다. 연결된 Hugging Face 저장소에서 MLX-4비트, 6비트 또는 8비트와 같은 양자화된 버전을 선택합니다. 앱 내에서 다운로드가 완료됩니다.
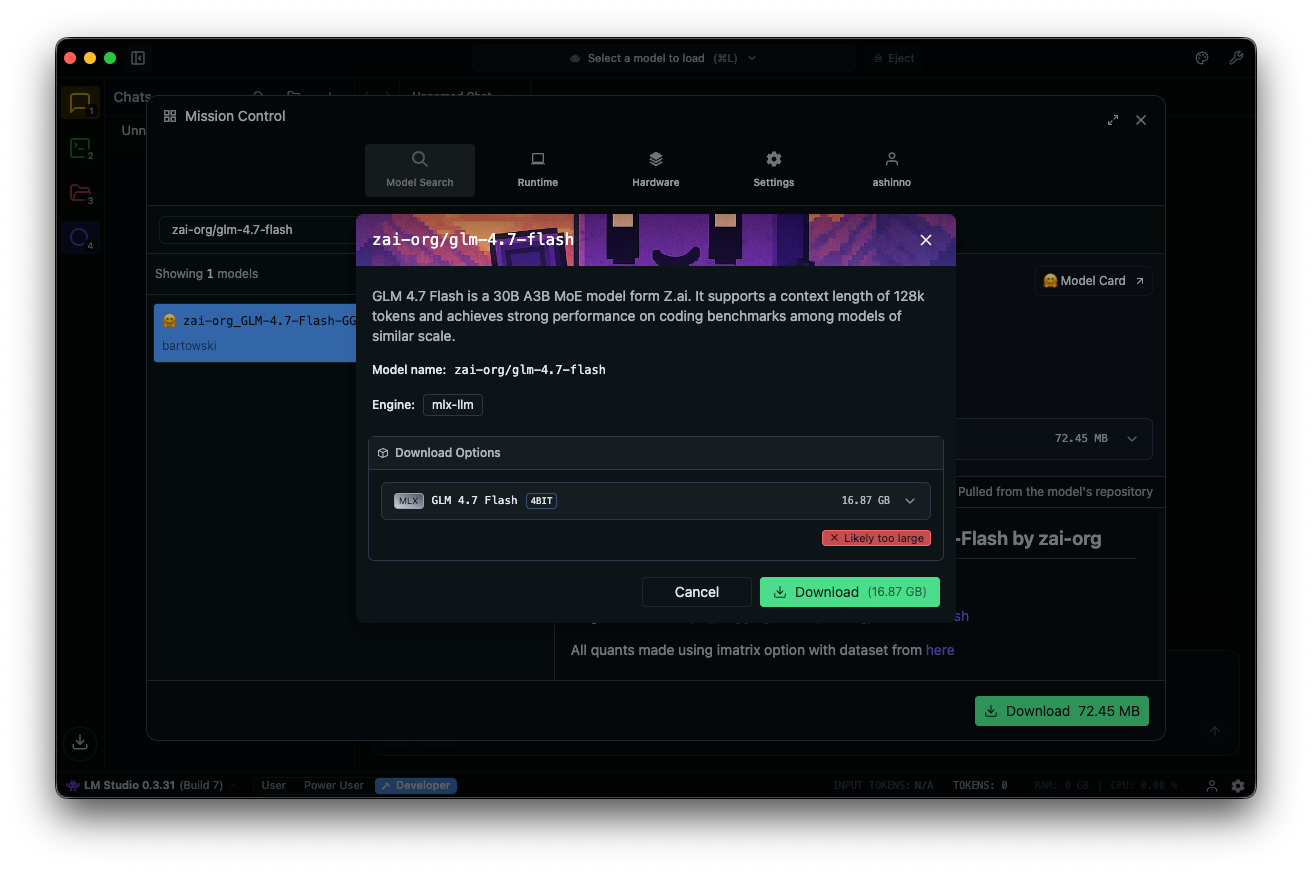
모델을 로드합니다: 채팅 인터페이스로 이동하여 GLM-4.7-Flash를 선택하고 매개변수를 조정합니다. 단계별 추론을 위해 사고 활성화(기본값: true)를 설정합니다. 온도를 1로, top_k를 50으로, top_p를 0.95로 설정하고 반복 페널티를 비활성화합니다.
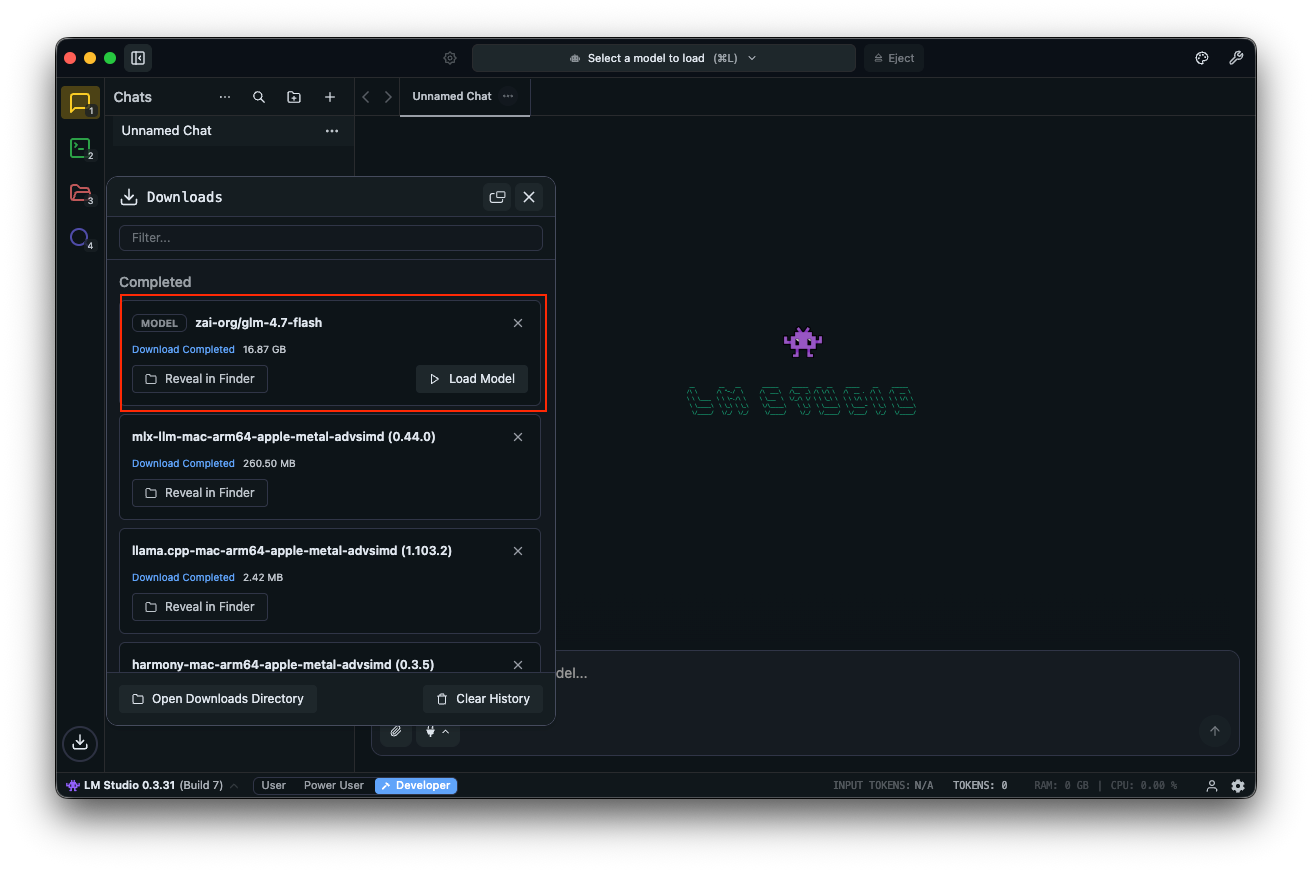
"사용자 인증을 위한 REST API를 설계해 줘."와 같은 프롬프트로 테스트합니다. LM Studio는 토큰 속도와 함께 출력을 표시하여 성능 튜닝에 도움을 줍니다.
clear_thinking (기본값: false)과 같은 사용자 지정 필드가 기록을 관리합니다. MoE 모델의 경우 활성 전문가를 모니터링하세요. A3B는 각 순방향 패스당 세 명의 활성 전문가를 의미하며 효율성을 최적화합니다.
LM Studio는 직접 모델 접근을 위한 딥링크를 지원합니다. 문제가 발생하면 시스템 메모리를 확인하세요. 최소 16GB는 충돌을 방지합니다.
이 도구는 실험에 탁월합니다. 고급 스크립팅을 위해서는 Hugging Face와 통합하세요.
Hugging Face Transformers와 함께 GLM-4.7-Flash 사용하기
Hugging Face는 세밀한 제어를 위한 강력한 라이브러리를 제공합니다. 메인 브랜치에서 Transformers를 설치하세요:
pip install git+https://github.com/huggingface/transformers.git
모델을 로드합니다:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
입력을 준비합니다:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
생성합니다:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
이 설정은 더 낮은 VRAM을 위해 bitsandbytes를 통한 양자화를 지원합니다. 모델 로딩 시 load_in_4bit=True를 추가하세요.
서비스 제공을 위해서는 vLLM 또는 SGLang을 사용하세요. vLLM을 설치합니다:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
서버를 실행합니다:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
OpenAI 호환 엔드포인트를 통해 접근하세요. SGLang은 소스 설치가 필요하며 유사한 단계를 따릅니다.
이러한 프레임워크는 프로덕션 수준의 배포를 가능하게 합니다. 이제 Apidog를 사용한 API 테스트를 고려해 봅시다.
로컬 GLM-4.7-Flash와 API 테스트를 위한 Apidog 통합
Ollama 또는 vLLM을 통해 GLM-4.7-Flash를 서비스한 후에는 엔드포인트를 효율적으로 테스트하세요. 올인원 API 플랫폼인 Apidog가 이를 용이하게 합니다.
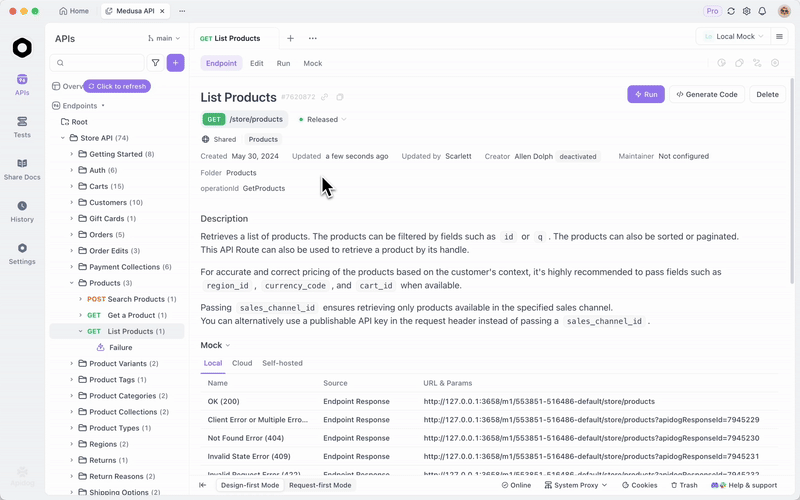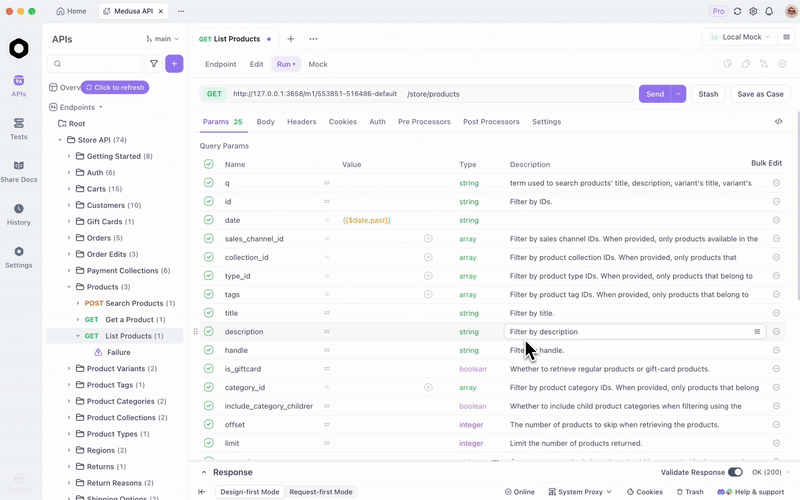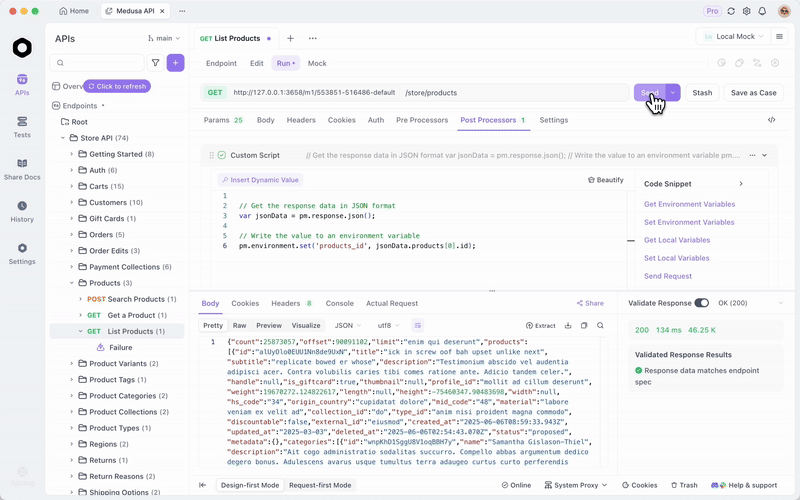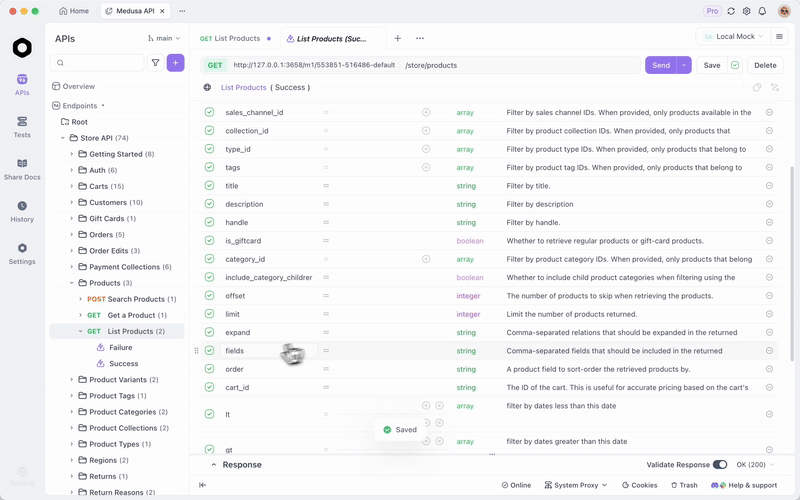
Apidog를 무료로 다운로드하세요. 로컬 모델을 공급자로 구성하여 AI 기능을 지원합니다. 해당되는 경우 API 키를 사용하거나 직접 엔드포인트를 사용하세요.
버튼
Apidog의 MCP 서버는 Cursor와 같은 IDE와 통합되어 API 사양을 사용하여 코드 생성을 지원합니다. 이는 GLM-4.7-Flash의 코딩 기능과 연결되어 에이전트 출력을 직접 테스트할 수 있게 합니다.
예를 들어, 로컬 서버에 쿼리하고 응답을 검증합니다. 이는 애플리케이션의 신뢰성을 보장합니다.
기본 사항을 바탕으로 최적화로 나아갑니다.
GLM-4.7-Flash 성능 최적화를 위한 고급 팁
작업에 따라 매개변수를 미세 조정합니다. 코딩에는 온도를 0.7로, 창의적인 글쓰기에는 1.0으로 설정합니다. 다양성의 균형을 맞추기 위해 top_p 0.95를 사용하세요.
llama.cpp를 통해 GGUF 형식으로 추가 양자화합니다. CUDA로 llama.cpp를 컴파일한 다음 변환합니다:
./llama-gguf-split --model GLM-4.7-Flash.gguf
템플릿 지원을 위해 --jinja와 함께 실행합니다.
긴 컨텍스트 처리: 128K를 초과하는 경우 입력을 분할합니다. 복잡한 쿼리에 대해 사고 기능을 활성화합니다.
메트릭 모니터링: TensorBoard와 같은 도구가 지연 시간을 추적합니다. 기준선과 비교하세요. GLM-4.7-Flash는 SWE-bench에서 다른 모델보다 37.2점 높은 점수를 기록했습니다.
도구 통합: 에이전트 동작을 위해 프롬프트에 함수 호출을 추가합니다.
보안: 데이터 유출을 방지하기 위해 격리된 환경에서 실행합니다.
이러한 전략은 유용성을 극대화합니다. 다음으로 응용 프로그램에 대해 생각해 봅시다.
일반적인 문제 해결
메모리 부족 오류가 발생합니까? 배치 크기를 줄이거나 더 낮은 수준으로 양자화하세요.
느린 추론? GPU를 업그레이드하거나 vLLM과 같은 더 빠른 프레임워크를 사용하세요.
호환성 문제? Transformers를 메인 브랜치로 업데이트하세요.
Ollama가 실패하면 포트 11434의 가용성을 확인하세요.
LM Studio 충돌? 모델 무결성을 확인하세요.
이러한 문제에 선제적으로 대처하세요.
결론: GLM-4.7-Flash로 워크플로우 강화
GLM-4.7-Flash를 로컬에서 실행하면 강력한 AI 기능을 활용할 수 있습니다. Ollama의 간편함부터 Hugging Face의 유연성까지 다양한 옵션이 있습니다. 원활한 API 관리를 위해 Apidog를 통합하세요. 무료로 다운로드하여 설정을 향상시키세요.
기술이 발전함에 따라 이와 같은 모델은 성능과 접근성 사이의 간극을 메웁니다. 이 단계를 구현하면 효율적이고 사적인 AI 배포를 달성할 수 있습니다. 매개변수나 도구의 작은 조정은 상당한 개선을 가져오며, 일상적인 작업을 간소화된 프로세스로 변화시킵니다.
버튼