
상상해보세요, 어떤 웹사이트에서든 데이터를 추출하고 대규모로 인사이트를 모을 수 있는 능력을 갖는 것—단 몇 줄의 코드로 말이죠. 마치 마법처럼 들리죠? Firecrawl이 그것을 가능하게 합니다.
이 초보자 가이드에서는 설치부터 고급 데이터 추출 기술까지 Firecrawl에 대해 알아야 할 모든 것을 안내합니다. 개발자든 데이터 분석가든 웹 스크래핑에 대한 호기심이 있든 간에, 이 튜토리얼은 Firecrawl을 시작하고 워크플로에 통합하는 데 도움이 될 것입니다.

Firecrawl이란?
Firecrawl은 웹사이트 콘텐츠를 마크다운, HTML 및 구조화된 데이터와 같은 형식으로 변환하는 혁신적인 웹 스크래핑 및 크롤링 엔진입니다. 이는 대형 언어 모델(LLM) 및 AI 애플리케이션에 이상적입니다. Firecrawl을 사용하면 웹사이트에서 구조화된 데이터와 비구조화된 데이터를 효율적으로 수집하여 데이터 분석 워크플로를 단순화할 수 있습니다.
Firecrawl의 주요 기능
크롤링: 종합적인 웹 크롤링
Firecrawl의 /crawl 엔드포인트를 사용하면 웹사이트를 재귀적으로 탐색하여 모든 하위 페이지의 콘텐츠를 추출할 수 있습니다. 이 기능은 대량의 웹 데이터를 발견하고 정리하는 데 적합하며, 이를 LLM 준비 형식으로 변환합니다.
스크래핑: 목표 데이터 추출
스크래핑 기능을 사용하여 단일 URL에서 특정 데이터를 추출하세요. Firecrawl은 마크다운, 구조화된 데이터, 스크린샷, HTML 등 다양한 형식으로 콘텐츠를 제공할 수 있습니다. 이는 알려진 URL에서 특정 정보를 추출하는 데 특히 유용합니다.
맵: 빠른 사이트 매핑
맵 기능은 주어진 웹사이트와 연결된 모든 URL를 빠르게 검색하여 웹사이트 구조에 대한 포괄적인 개요를 제공합니다. 이는 콘텐츠 발견 및 조직에 매우 중요합니다.
추출: 비구조화 데이터를 구조화된 형식으로 변환하기
/extract 엔드포인트는 웹사이트에서 구조화된 데이터를 수집하는 과정을 단순화하는 Firecrawl의 AI 기반 기능입니다. 이 기능은 크롤링, 파싱, 데이터 정리를 맡아 구조화된 형식으로 만듭니다.
Firecrawl 시작하기
1단계: 가입하고 API 키 받기
Firecrawl의 공식 웹사이트를 방문하여 계정을 만드세요. 로그인 후 대시보드에서 API 키를 찾으세요.
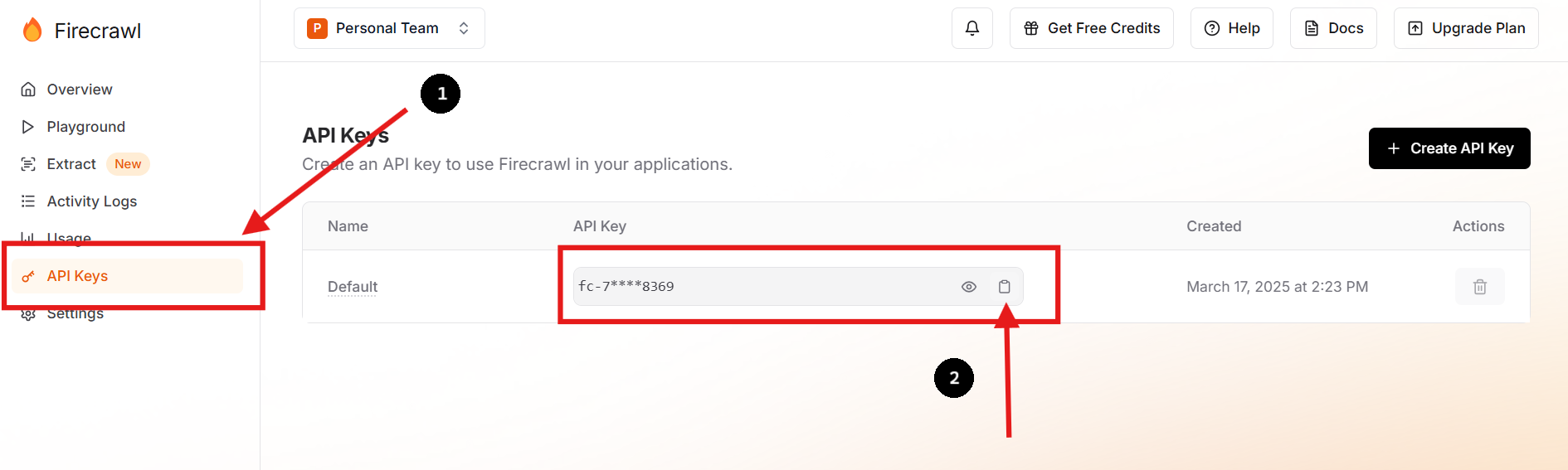
원하는 경우 새 API 키를 만들고 이전 키를 삭제할 수도 있습니다.

2단계: 환경 설정하기
프로젝트 디렉토리에 .env 파일을 만들어 API 키를 환경 변수로 안전하게 저장하세요. 터미널에서 다음 명령어를 실행하여 설정할 수 있습니다:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .env이 방법은 민감한 정보를 메인 코드베이스에서 분리하여 보안을 강화하고 구성 관리를 단순화합니다.
3단계: Firecrawl SDK 설치하기
Python 사용자라면 pip를 사용하여 Firecrawl SDK를 설치하세요:
pip install firecrawl4단계: Firecrawl의 "스크래핑" 기능 사용하기
다음은 Python SDK를 사용하여 웹사이트를 스크래핑하는 간단한 예입니다:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# .env에서 API 키로 FirecrawlApp 초기화
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# 스크래핑할 URL 정의
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# 웹사이트 스크래핑
response = app.scrape_url(url)
# 응답 출력
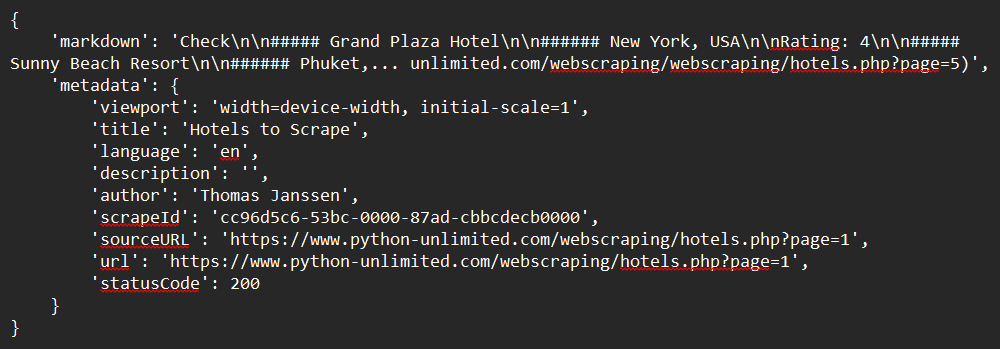
print(response)샘플 출력:
5단계: Firecrawl의 "크롤링" 기능 사용하기
다음은 Python SDK를 사용하여 웹사이트를 크롤링하는 간단한 예입니다:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# .env에서 API 키로 FirecrawlApp 초기화
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# 웹사이트를 크롤링하고 응답 캡처:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
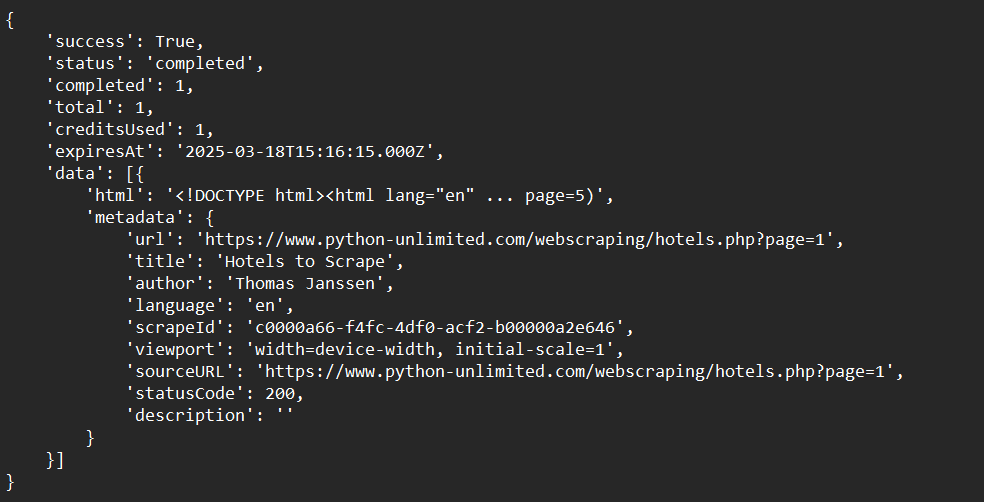
print(crawl_status)샘플 출력:
6단계: Firecrawl의 "맵" 기능 사용하기
다음은 Python SDK를 사용하여 웹사이트 데이터를 맵핑하는 간단한 예입니다:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# .env에서 API 키로 FirecrawlApp 초기화
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# 웹사이트 맵핑:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)샘플 출력:

7단계: Firecrawl의 "추출" 기능 사용하기 (오픈 베타)
다음은 Python SDK를 사용하여 웹사이트 데이터를 추출하는 간단한 예입니다:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# .env 파일에서 환경 변수 로드
load_dotenv()
# .env에서 API 키로 FirecrawlApp 초기화
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# 내용을 추출할 스키마 정의
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# 추출 함수 호출 및 응답 캡처
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "스키마에 제공된 데이터를 추출하십시오.",
'schema': ExtractSchema.model_json_schema()
})
# 응답 출력
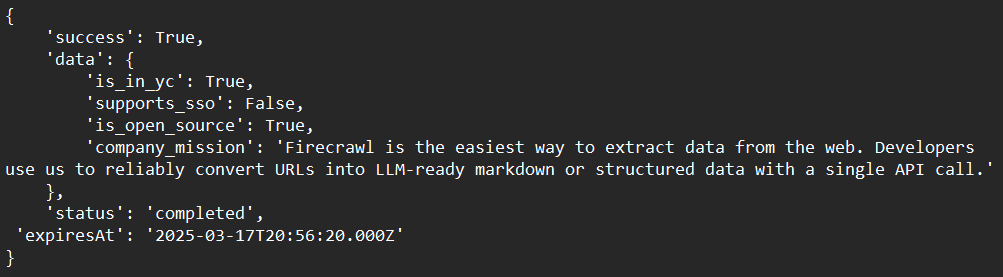
print(response)샘플 출력:
Firecrawl의 고급 기술
동적 콘텐츠 처리
Firecrawl은 헤드리스 브라우저를 사용하여 페이지를 렌더링한 후 스크래핑함으로써 동적 JavaScript 기반 콘텐츠를 처리할 수 있습니다. 이를 통해 동적으로 로드되는 콘텐츠도 모두 캡처할 수 있습니다.
웹 스크래핑 차단기 우회하기
Firecrawl의 내장 기능을 사용하여 CAPTCHA 또는 속도 제한과 같은 일반적인 웹 스크래핑 차단기를 우회하세요. 이는 자연적인 트래픽을 모방하기 위해 사용자 에이전트 및 IP 주소를 회전시키는 것을 포함합니다.
LLM과 통합하기
Firecrawl과 LangChain과 같은 LLM을 결합하여 강력한 AI 워크플로를 구축하세요. 예를 들어, Firecrawl을 사용하여 데이터를 수집한 다음 이를 LLM에 입력하여 분석 또는 생성 작업을 수행할 수 있습니다.
일반적인 문제 해결하기
문제: "API 키 인식되지 않음"
솔루션: API 키가 환경 변수 또는 .env 파일에 올바르게 저장되었는지 확인하세요.
문제: "크롤링 속도가 너무 느림"
솔루션: 비동기 크롤링을 사용하여 프로세스를 가속화하세요. Firecrawl은 효율성을 높이기 위해 동시 요청을 지원합니다.
문제: "콘텐츠가 올바르게 추출되지 않음"
솔루션: 웹사이트가 동적 콘텐츠를 사용하는지 확인하세요. 만약 그렇다면 Firecrawl이 JavaScript 렌더링을 처리하도록 설정되어 있는지 확인하세요.
결론
Firecrawl에 대한 이 포괄적인 초보자 가이드를 완료하신 것을 축하드립니다! 우리는 Firecrawl이 무엇인지부터 시작하여 설치 지침, 사용 예제, 고급 사용자 지정 옵션까지 알아보았습니다. 이제 다음과 같은 사항을 명확하게 이해하셨어야 합니다:
- 개발 환경에서 Firecrawl 설정 및 설치하기.
- 데이터를 효율적으로 스크래핑, 크롤링, 맵핑 및 추출하기 위해 Firecrawl 구성 및 실행하기.
- 특정 요구 사항을 충족하기 위해 크롤링 프로세스를 문제 해결하기.
Firecrawl은 데이터 추출 워크플로를 상당히 간소화할 수 있는 매우 강력한 도구입니다. 유연성, 효율성 및 통합 용이성 덕분에 현대 웹 크롤링 문제에 이상적인 선택입니다.
이제 새로운 기술을 실제로 적용해 볼 시간입니다. 다양한 웹사이트를 실험해보고, 파서를 조정하며, 추가 도구와 통합하여 고유한 요구 사항을 충족하는 진정으로 맞춤화된 솔루션을 만들어보세요.
웹 스크래핑 워크플로를 10배 향상시킬 준비가 되셨나요? 오늘 무료로 Apidog를 다운로드하고 Firecrawl 통합을 향상시키는 방법을 알아보세요!