
엔지니어와 개발자는 고급 언어 모델을 애플리케이션에 통합하기 위한 강력한 도구를 자주 찾습니다. EXAONE API는 LG AI 연구원에서 제공하며 Together AI와 같은 플랫폼에서 호스팅되는 강력한 옵션으로 돋보입니다. 이 인터페이스를 통해 텍스트 완성부터 다중 모드 처리까지 다양한 작업을 수행할 수 있습니다.
EXAONE은 영어와 한국어를 지원하는 이중 언어 모델 제품군으로, 32B 파라미터 버전과 같은 변형은 추론, 수학, 코드에서 탁월한 성능을 발휘합니다. 개발자는 호스팅된 서비스 또는 로컬 설정을 통해 이를 사용합니다. 먼저 핵심 기능을 이해한 다음, 실제 구현 단계로 넘어갑니다.
EXAONE API 아키텍처 이해
EXAONE은 LG AI 연구원이 전문가 수준의 언어 모델을 통해 인공지능을 대중화하려는 노력을 보여줍니다. API 아키텍처는 EXAONE 3.0, EXAONE 3.5, EXAONE 4.0, EXAONE Deep을 포함한 여러 모델 변형을 지원하며, 각 변형은 특정 사용 사례에 최적화되어 있습니다.
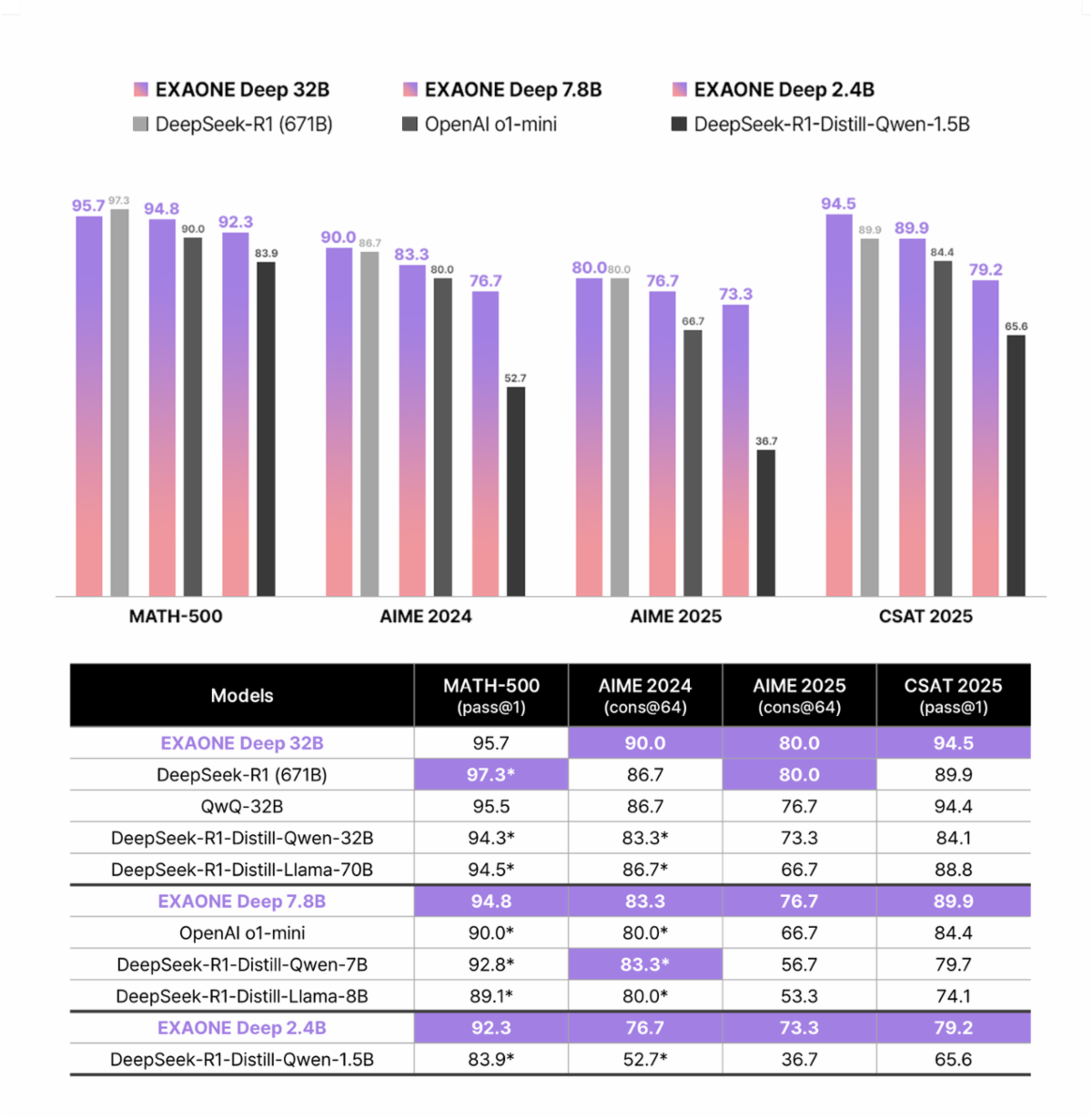
최신 EXAONE 4.0은 혁신적인 하이브리드 어텐션 메커니즘을 도입합니다. 전통적인 트랜스포머 아키텍처와 달리, EXAONE 4.0은 32B 모델 변형에 대해 로컬 어텐션과 글로벌 어텐션을 3:1 비율로 결합합니다. 또한, 이 아키텍처는 QK-Reorder-Norm을 구현하여 LayerNorm을 전통적인 Pre-LN 방식에서 어텐션 및 MLP 출력에 직접 적용하도록 재배치합니다.

또한, EXAONE 모델은 영어와 한국어를 아우르는 이중 언어 기능을 지원합니다. 최근 업데이트에서는 스페인어를 포함한 다국어 지원이 확장되어 API가 국제 애플리케이션에 적합합니다. 모델 시리즈는 온디바이스 애플리케이션을 위한 경량 1.2B 파라미터부터 고성능 요구 사항을 위한 강력한 32B 파라미터까지 다양합니다.
EXAONE API 설정 시작하기
시스템 요구 사항 및 전제 조건
EXAONE API를 구현하기 전에 개발 환경이 최소 요구 사항을 충족하는지 확인하세요. 이 API는 클라우드 기반 배포 및 로컬 설치를 포함한 다양한 플랫폼에서 효과적으로 작동합니다. 그러나 특정 하드웨어 요구 사항은 선택한 배포 방법에 따라 달라집니다.
로컬 배포 시나리오의 경우, 모델 크기에 따른 메모리 요구 사항을 고려하세요. 1.2B 모델은 약 2.4GB RAM을 필요로 하는 반면, 32B 모델은 훨씬 더 많은 리소스가 필요합니다. 클라우드 배포 옵션은 이러한 제약을 없애고 확장성 이점을 제공합니다.
인증 및 액세스 구성
EXAONE API 액세스는 선택한 배포 플랫폼에 따라 다릅니다. Hugging Face Hub 배포, Together AI 서비스, 사용자 지정 서버 구성을 포함한 여러 통합 경로가 존재합니다. 각 방법은 다른 인증 접근 방식을 요구합니다.
Together AI의 EXAONE Deep 32B API 엔드포인트를 사용할 때 인증은 API 키 관리를 포함합니다. Together AI 계정을 생성하고, API 키를 생성하며, 환경 변수를 안전하게 구성하세요. 클라이언트 측 코드 또는 공개 저장소에 API 키를 노출하지 마세요.
import Together from "together-ai";
const client = new Together({
apiKey: process.env.TOGETHER_API_KEY
});
async function callExaoneAPI(prompt) {
try {
const response = await client.chat.completions.create({
model: "exaone-deep-32b",
messages: [
{
role: "user",
content: prompt
}
],
max_tokens: 1000,
temperature: 0.7
});
return response.choices[0].message.content;
} catch (error) {
console.error("EXAONE API Error:", error);
throw error;
}
}
Ollama 통합을 통한 로컬 배포
로컬 배포는 프라이버시, 제어 및 지연 시간 감소 이점을 제공합니다. Ollama는 복잡한 인프라 요구 사항 없이 EXAONE 모델을 로컬에서 실행하기 위한 훌륭한 플랫폼을 제공합니다. 이 접근 방식은 특히 민감한 데이터를 다루거나 오프라인 기능이 필요한 개발자에게 유용합니다.
Ollama 설치 및 구성
공식 웹사이트에서 Ollama를 다운로드하는 것으로 시작하세요. 설치 프로세스는 운영 체제마다 다르지만, 설정은 간단합니다. 설치 후 터미널에서 기본 명령을 실행하여 설치를 확인하세요.
# Install Ollama (MacOS)
brew install ollama
# Start Ollama service
ollama serve
# Pull EXAONE model
ollama pull exaone
성공적인 설치 후, EXAONE 모델을 효과적으로 실행하도록 Ollama를 구성하세요. 구성에는 모델 가중치 다운로드, 적절한 메모리 할당 설정, 특정 하드웨어에 대한 성능 매개변수 최적화가 포함됩니다.
EXAONE 모델 로컬에서 실행하기
Ollama 설치가 완료되면 EXAONE 모델 다운로드가 간단해집니다. 이 프로세스에는 공식 저장소에서 모델 가중치를 가져오고 런타임 매개변수를 구성하는 것이 포함됩니다. 다양한 모델 크기는 다양한 성능 특성을 제공하므로 특정 요구 사항에 따라 선택하세요.
# Pull specific EXAONE model version
ollama pull exaone-deep:7.8b
# Run model with custom parameters
ollama run exaone-deep:7.8b --temperature 0.5 --max-tokens 2048
로컬 배포는 또한 사용자 지정 미세 조정 기회를 제공합니다. 고급 사용자는 모델 매개변수를 수정하고, 추론 설정을 조정하며, 특정 사용 사례에 대한 성능을 최적화할 수 있습니다. 이러한 유연성은 EXAONE을 연구 애플리케이션 및 전문화된 구현에 특히 매력적으로 만듭니다.
API 통합 방법 및 모범 사례
RESTful API 구현
EXAONE API는 표준 RESTful 규칙을 따르므로 대부분의 개발자에게 통합이 익숙합니다. HTTP POST 요청은 모델 추론을 처리하고, GET 요청은 모델 정보 및 상태 확인을 관리합니다. 적절한 오류 처리는 API 제한 및 네트워크 문제를 원활하게 관리하는 강력한 애플리케이션을 보장합니다.
import requests
import json
def exaone_api_call(prompt, model_size="32b"):
url = "https://api.together.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": f"exaone-deep-{model_size}",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1500,
"temperature": 0.7,
"top_p": 0.9
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
고급 구성 옵션
EXAONE API는 출력 품질과 성능에 크게 영향을 미치는 다양한 구성 매개변수를 지원합니다. `temperature`는 생성된 응답의 무작위성을 제어하고, `top_p`는 핵 샘플링 동작을 관리합니다. `max_tokens`는 응답 길이를 제한하여 비용과 응답 시간을 제어하는 데 도움이 됩니다.
또한, API는 시스템 프롬프트를 지원하여 여러 요청에 걸쳐 일관된 동작을 가능하게 합니다. 이 기능은 특정 톤, 스타일 또는 형식 일관성이 필요한 애플리케이션에 특히 유용합니다. 시스템 프롬프트는 대화 스레드 전반에 걸쳐 컨텍스트를 유지하는 데도 도움이 됩니다.
Apidog로 EXAONE API 테스트하기
효과적인 API 테스트는 개발 속도를 높이고 안정적인 통합을 보장합니다. Apidog는 최신 API 워크플로우를 위해 특별히 설계된 포괄적인 테스트 기능을 제공합니다. 이 플랫폼은 자동화된 테스트, 요청 유효성 검사 및 성능 모니터링을 지원합니다.
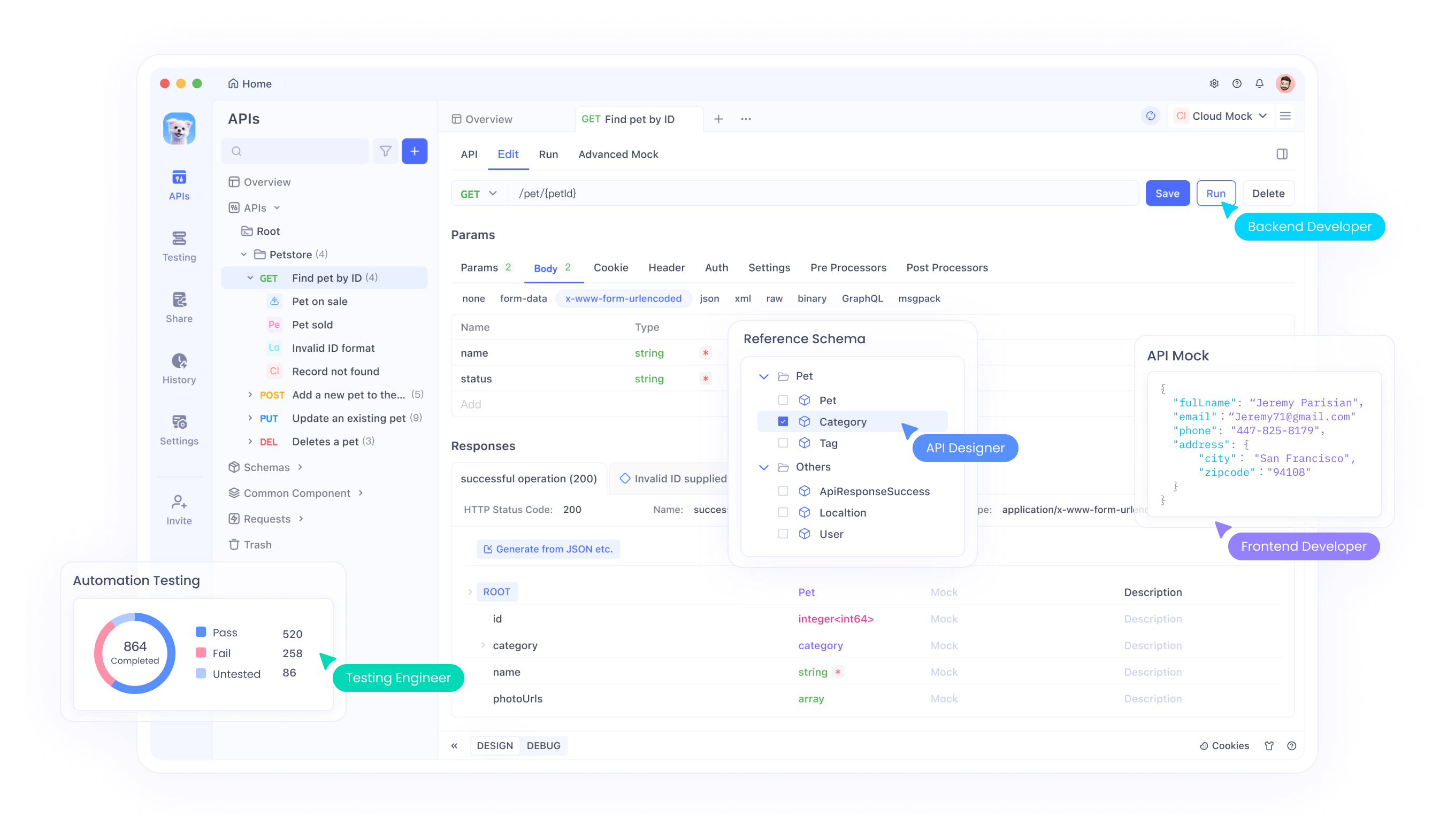
EXAONE 테스트를 위한 Apidog 설정
Apidog 계정을 생성하고 데스크톱 애플리케이션을 설치하는 것으로 시작하세요. 이 플랫폼은 웹 기반 및 데스크톱 버전을 모두 제공하며, 각 버전은 강력한 테스트 기능을 제공합니다. 데스크톱 버전은 로컬 파일 가져오기 및 향상된 디버깅 도구와 같은 추가 기능을 제공합니다.
새로운 API 사양을 생성하여 EXAONE API 엔드포인트를 Apidog로 가져오세요. 요청 매개변수, 헤더 및 예상 응답 형식을 정의하세요. 이 문서는 테스트 구성 및 팀 협업 도구 역할을 하여 개발 팀 전체에서 일관된 API 사용을 보장합니다.
포괄적인 테스트 스위트 생성
성공적인 요청, 오류 조건 및 엣지 케이스를 포함한 다양한 시나리오를 다루는 테스트 스위트를 개발하세요. API 동작을 철저히 이해하기 위해 다양한 매개변수 조합을 테스트하세요. Apidog의 테스트 자동화 기능은 개발 주기 동안 지속적인 유효성 검사를 가능하게 합니다.
{
"test_cases": [
{
"name": "Basic Text Generation",
"request": {
"method": "POST",
"url": "{{base_url}}/chat/completions",
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"model": "exaone-deep-32b",
"messages": [
{"role": "user", "content": "Explain quantum computing"}
],
"max_tokens": 500
}
},
"assertions": [
{"path": "$.choices[0].message.content", "operator": "exists"},
{"path": "$.usage.total_tokens", "operator": "lessThan", "value": 600}
]
}
]
}
성능 최적화 전략
요청 배치 및 캐싱
지능형 요청 배치 및 응답 캐싱을 통해 API 성능을 최적화하세요. 배치는 네트워크 오버헤드를 줄이고 캐싱은 동일한 요청에 대한 중복 API 호출을 제거합니다. 이러한 전략은 애플리케이션 응답성을 크게 향상시키면서 비용을 절감합니다.
Redis 또는 유사한 기술을 사용하여 캐싱 레이어를 구현하세요. 요청 매개변수를 기반으로 응답을 캐시하여 캐시 무효화가 적절하게 발생하도록 보장합니다. 애플리케이션의 요구 사항 및 데이터 민감도에 따라 캐시 만료 정책을 고려하세요.
오류 처리 및 재시도 로직
강력한 오류 처리는 API 문제가 발생할 때 애플리케이션 실패를 방지합니다. 일시적인 오류에 대해 지수 백오프 전략을 구현하고, 영구적인 오류는 정상적으로 처리하세요. 속도 제한 관리는 서비스 중단 없이 애플리케이션이 API 할당량 내에 유지되도록 보장합니다.
import time
import random
from typing import Optional
class ExaoneAPIClient:
def __init__(self, api_key: str, max_retries: int = 3):
self.api_key = api_key
self.max_retries = max_retries
def call_with_retry(self, prompt: str) -> Optional[str]:
for attempt in range(self.max_retries):
try:
response = self._make_api_call(prompt)
return response
except Exception as e:
if attempt == self.max_retries - 1:
raise e
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
return None
def _make_api_call(self, prompt: str) -> str:
# Implementation details for actual API call
pass
실제 구현 사례
EXAONE을 이용한 챗봇 개발
EXAONE API로 대화형 AI 애플리케이션을 구축하려면 신중한 프롬프트 엔지니어링과 컨텍스트 관리가 필요합니다. 단순한 gpt-oss 대안과 달리, EXAONE의 고급 추론 기능은 더욱 정교한 대화 시스템을 가능하게 합니다.
여러 교환에 걸쳐 컨텍스트를 유지하기 위해 대화 기록 관리를 구현하세요. 토큰 제한을 관리하여 비용을 제어하면서 대화 상태를 효율적으로 저장하세요. 장기 실행 채팅 세션에 대한 대화 요약 구현을 고려하세요.
콘텐츠 생성 애플리케이션
EXAONE은 기술 문서, 창의적 글쓰기, 코드 생성 등 다양한 콘텐츠 생성 작업에서 뛰어납니다. 이 API의 이중 언어 기능은 국제 콘텐츠 생성 워크플로우에 특히 적합합니다.
class ContentGenerator:
def __init__(self, exaone_client):
self.client = exaone_client
def generate_blog_post(self, topic: str, target_language: str = "en") -> str:
prompt = f"""
Write a comprehensive blog post about {topic}.
Language: {target_language}
Requirements:
- Include introduction, main content, and conclusion
- Use engaging tone and clear structure
- Target length: 800-1000 words
"""
return self.client.generate(prompt, max_tokens=1200)
def generate_code_documentation(self, code_snippet: str) -> str:
prompt = f"""
Generate comprehensive documentation for this code:
{code_snippet}
Include:
- Function purpose and behavior
- Parameter descriptions
- Return value explanation
- Usage examples
"""
return self.client.generate(prompt, max_tokens=800)
EXAONE과 대안 솔루션 비교
기존 GPT 모델 대비 장점
EXAONE은 기존 GPT 구현 및 gpt-oss 대안과 비교하여 여러 가지 장점을 제공합니다. 하이브리드 어텐션 아키텍처는 더 나은 장문 컨텍스트 이해를 제공하며, 추론 모드는 더 정확한 문제 해결 기능을 가능하게 합니다.
비용 효율성은 또 다른 중요한 장점입니다. 로컬 배포 옵션은 토큰당 요금을 없애 EXAONE을 대량 애플리케이션에 경제적으로 만듭니다. 또한, 프라이버시 이점은 민감한 데이터를 처리하는 조직에 매력적입니다.
통합 유연성
일부 독점 솔루션과 달리 EXAONE은 여러 배포 패턴을 지원합니다. 특정 요구 사항에 따라 클라우드 API, 로컬 설치 또는 하이브리드 접근 방식 중에서 선택하세요. 이러한 유연성은 다양한 조직적 제약 및 기술적 선호도를 수용합니다.
일반적인 문제 해결
연결 및 인증 문제
네트워크 연결 문제 및 인증 오류는 일반적인 통합 문제입니다. API 엔드포인트를 확인하고, 인증 자격 증명을 검토하며, 적절한 헤더 구성을 확인하세요. 네트워크 디버깅 도구는 연결 문제를 신속하게 식별하는 데 도움이 됩니다.
API 속도 제한을 주의 깊게 모니터링하세요. 할당량을 초과하면 일시적인 차단이 발생할 수 있습니다. 서비스 중단을 방지하기 위해 애플리케이션에 적절한 속도 제한을 구현하세요. 더 높은 제한이 필요한 경우 API 플랜 업그레이드를 고려하세요.
모델 성능 최적화
모델 응답이 일관성이 없거나 품질이 낮게 보인다면 프롬프트 엔지니어링 기술을 검토하세요. EXAONE은 적절한 컨텍스트와 함께 명확하고 구체적인 지침에 잘 반응합니다. 원하는 출력 특성을 얻기 위해 다양한 `temperature` 및 `top_p` 값을 실험해 보세요.
요구 사항에 따라 모델 크기 선택을 고려하세요. 더 큰 모델은 더 나은 성능을 제공하지만 더 많은 리소스와 처리 시간을 필요로 합니다. 성능 요구 사항과 리소스 제약 및 응답 시간 요구 사항의 균형을 맞추세요.
보안 고려 사항 및 모범 사례
API 키 관리
안전한 API 키 저장은 무단 액세스 및 잠재적인 보안 침해를 방지합니다. 키 저장을 위해 환경 변수, 보안 볼트 또는 구성 관리 시스템을 사용하세요. 버전 제어 시스템에 API 키를 커밋하거나 클라이언트 측 코드에 노출하지 마세요.
보안 위험을 최소화하기 위해 키 순환 정책을 구현하세요. 정기적인 키 업데이트는 침해가 발생할 경우 노출 기간을 줄입니다. 보안 문제를 나타낼 수 있는 비정상적인 활동을 감지하기 위해 API 사용 패턴을 모니터링하세요.
데이터 프라이버시 및 규정 준수
EXAONE API를 통해 민감한 데이터를 처리할 때 데이터 프라이버시 영향을 신중하게 고려하세요. 로컬 배포 옵션은 최대의 프라이버시 제어를 제공하는 반면, 클라우드 배포는 데이터 처리 정책에 대한 신중한 평가가 필요합니다.
API 요청 전에 민감한 정보를 제거하기 위한 데이터 정화 절차를 구현하세요. 고도로 민감한 애플리케이션의 경우 추가 암호화 계층 구현을 고려하세요. 산업 및 지리적 위치에 특정한 규정 준수 요구 사항을 검토하세요.
향후 개발 및 로드맵
예정된 기능
LG AI 연구원은 정기적인 모델 업데이트 및 기능 향상을 통해 EXAONE 기능을 지속적으로 개발하고 있습니다. 향후 릴리스에는 추가 언어 지원, 향상된 추론 기능 및 향상된 도구 통합 기능이 포함될 수 있습니다.
공식 문서 및 커뮤니티 채널을 통해 API 변경 사항에 대한 정보를 얻으세요. 새로운 모델 버전이 출시될 때 마이그레이션 경로를 계획하세요. 프로덕션 배포 전에 새 버전을 철저히 테스트하세요.
커뮤니티 및 생태계 성장
EXAONE 생태계는 커뮤니티 기여, 타사 통합 및 전문화된 도구를 통해 계속 확장되고 있습니다. 커뮤니티 토론에 적극적으로 참여하면 모범 사례 및 새로운 사용 사례에 대한 통찰력을 얻을 수 있습니다.
EXAONE 통합과 관련된 오픈 소스 프로젝트에 기여하는 것을 고려하세요. 경험과 솔루션을 공유하는 것은 전체 개발자 커뮤니티에 이점을 제공하며 잠재적으로 모든 사람을 위한 플랫폼을 개선할 수 있습니다.
결론
EXAONE API는 고급 AI 통합 옵션을 찾는 개발자에게 강력한 기능을 제공합니다. 로컬 배포 유연성부터 정교한 추론 기능에 이르기까지 EXAONE은 주류 솔루션에 대한 매력적인 대안을 제공합니다. 포괄적인 배포 옵션, 강력한 성능 특성 및 성장하는 생태계는 EXAONE을 다양한 애플리케이션 시나리오에 탁월한 선택으로 만듭니다.
EXAONE API의 성공은 적절한 설정, 신중한 통합 계획 및 지속적인 최적화에 달려 있습니다. 효율적인 테스트 및 디버깅 워크플로우를 위해 Apidog와 같은 도구를 사용하세요. 보안 모범 사례를 따르고 플랫폼 업데이트에 대한 정보를 얻어 구현의 효율성을 극대화하세요.