개발자들은 과도한 비용이나 복잡성 없이 신뢰할 수 있는 결과를 제공하는 견고한 AI 모델을 끊임없이 찾고 있습니다. 바이두는 이러한 요구를 충족하기 위해 사실 정확도, 지시 따르기, 에이전트 기능을 향상시키는 최첨단 추론 모델인 ERNIE X1.1을 선보입니다. Wave Summit 2025에서 출시된 이 모델은 ERNIE 4.5 기반 위에 구축되었으며, 탁월한 성능을 위해 종단간 강화 학습을 통합했습니다. 사용자들은 ERNIE Bot, Wenxiaoyan 앱 또는 API를 통한 Qianfan MaaS(Model-as-a-Service) 플랫폼을 통해 ERNIE X1.1에 접근할 수 있어 개인 및 기업 애플리케이션 모두에 다용도로 활용 가능합니다.
이 글은 ERNIE X1.1 API 사용의 모든 측면을 안내합니다. 모델 개요부터 시작하여 설정 절차로 이동하고, 마지막으로 고급 사용 시나리오를 탐색합니다. 이 단계를 따르면 ERNIE X1.1을 워크플로우에 효율적으로 통합할 수 있습니다.
ERNIE X1.1이란? 주요 기능 및 역량
바이두는 ERNIE X1.1을 논리적 계획, 성찰, 진화와 관련된 복잡한 작업을 처리하는 멀티모달 심층 사고 추론 모델로 설계했습니다. 이전 모델인 ERNIE X1에 비해 환각을 크게 줄이고, 지시 준수율을 12.5% 향상시키며, 에이전트 기능을 9.6% 향상시킵니다. 또한, 사실 정확도를 34.8% 높여 지식 Q&A, 콘텐츠 생성, 도구 호출과 같은 애플리케이션에 이상적입니다.

이 모델은 일부 변형에서 최대 32K 토큰에 이르는 광범위한 컨텍스트 창을 지원하여 긴 형식의 입력을 일관성을 잃지 않고 처리할 수 있습니다. 개발자들은 멀티모달 기능을 활용하여 텍스트, 이미지, 심지어 비디오 분석까지 처리함으로써 기존 언어 모델을 넘어선 사용 사례를 확장할 수 있습니다. 예를 들어, ERNIE X1.1은 이미지 콘텐츠를 정확하게 식별하고 회전하는 3D 컨테이너 안의 입자와 같은 물리적 시나리오를 시뮬레이션합니다.
또한, ERNIE X1.1은 오해의 소지가 있는 지시보다 정확한 정보를 제공함으로써 신뢰성을 우선시하며, 이는 안전에 중요한 환경에서 차별점을 만듭니다. 바이두는 이를 Qianfan 플랫폼에 배포하여 대량 API 호출에 대한 확장성을 보장합니다. 이 설정은 챗봇, 추천 엔진 또는 데이터 분석 도구를 구축하든 기존 시스템과의 원활한 통합을 가능하게 합니다.
성능 지표로 넘어가면, ERNIE X1.1은 최근 평가에서 보여주듯이 벤치마크에서 우위를 점하고 있습니다.
ERNIE X1.1 벤치마크 성능: 경쟁사 압도
바이두는 ERNIE X1.1을 DeepSeek R1-0528, Gemini 2.5 Pro, GPT-5와 같은 최고 모델들과 비교 평가하여 정확성과 낮은 환각률에서의 강점을 보여줍니다. 출시 시점의 주요 시각 자료는 여러 벤치마크에서 이러한 비교를 설명합니다.
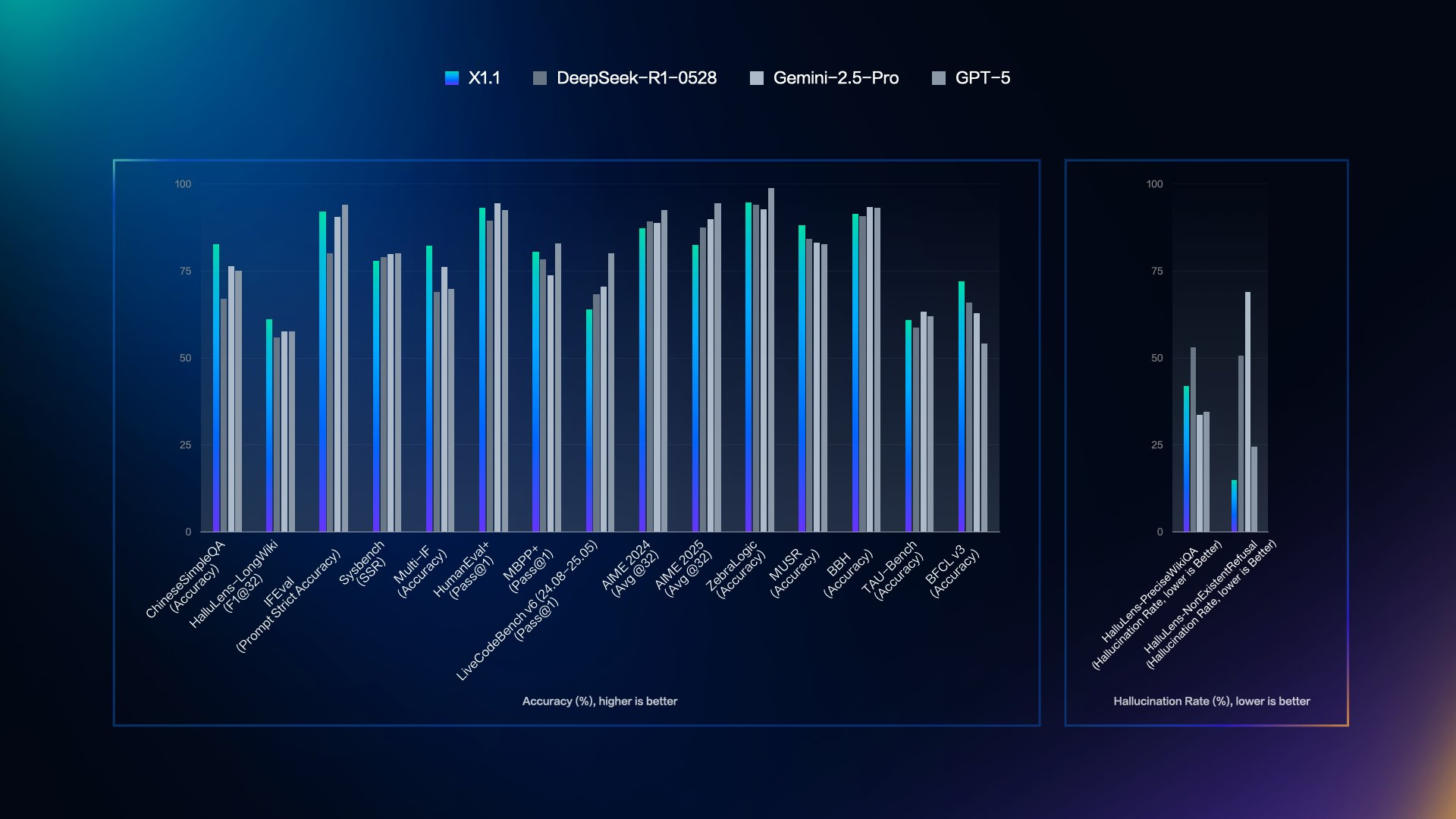
대조적으로, 환각률 패널은 HalluQA (Hallu-Precision, 존재하지 않는 것이 낮을수록 좋음), Hallu Lens (비율, 낮을수록 좋음) 등을 다룹니다. 여기서 ERNIE X1.1은 가장 낮은 막대를 보여주며, 예를 들어 HalluQA에서 25% 미만의 최소한의 오류를 나타냅니다.
이 데이터는 ERNIE X1.1이 GPT-5와 동등한 수준을 유지하면서 전반적인 성능에서 DeepSeek을 어떻게 능가하는지 강조합니다. 개발자들은 정밀도가 요구되는 작업을 위한 모델을 선택할 때 이러한 지표로부터 이점을 얻습니다. 이제 접근 설정을 통해 실제 구현으로 넘어가겠습니다.
Qianfan 플랫폼에서 ERNIE X1.1 API 시작하기
바이두 AI 클라우드의 Wenxin Qianfan 플랫폼에 등록하는 것으로 시작합니다. 공식 사이트를 방문하여 이메일 또는 전화번호를 사용하여 개발자 계정을 만드세요. 확인되면 ERNIE 모델에 대한 API 접근을 신청하세요. 바이두는 종종 몇 시간 내에 신청을 신속하게 검토하여 클라이언트 ID와 시크릿 키를 부여합니다.
다음으로, 필요한 SDK를 설치합니다. Python 사용자는 pip를 통해 Qianfan SDK를 사용합니다: pip install qianfan. 이 라이브러리는 인증 및 요청을 효율적으로 처리합니다. Java 또는 Go와 같은 다른 언어의 경우, 바이두는 유사한 인터페이스를 가진 동등한 SDK를 제공합니다.
설치 후, 환경 변수를 구성합니다. QIANFAN_AK를 액세스 키로 설정하고 QIANFAN_SK를 시크릿 키로 설정합니다. 이 단계는 스크립트에 자격 증명을 하드코딩하지 않고도 보안을 유지합니다. 설정이 완료되면 인증을 진행합니다.
ERNIE X1.1 API 요청 인증
Qianfan 플랫폼은 인증을 위해 OAuth 2.0을 사용합니다. 토큰 엔드포인트에 POST 요청을 보내 액세스 토큰을 생성합니다. Python에서는 Qianfan SDK가 이 프로세스를 자동화합니다. 수동 구현을 위해서는 다음과 같이 요청을 구성합니다:
import requests
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": "YOUR_CLIENT_ID",
"client_secret": "YOUR_CLIENT_SECRET"
}
response = requests.post(url, params=params)
access_token = response.json()["access_token"]
30일 후에 만료되는 토큰을 저장하고 필요에 따라 새로 고칩니다. access_token 쿼리 매개변수를 통해 API 호출에 첨부합니다. 이 방법은 안전한 통신을 보장합니다. 그러나 노출을 피하기 위해 항상 토큰을 신중하게 다루십시오.
인증되면 ERNIE X1.1에 대한 적절한 엔드포인트를 대상으로 합니다.
ERNIE X1.1 API 엔드포인트 및 요청 구조
바이두는 ERNIE API를 /chat 경로 아래에 구성합니다. ERNIE X1.1의 경우, 사용 가능한 변형에 따라 /chat/ernie-x1.1 또는 확장된 컨텍스트를 위한 /chat/ernie-x1.1-32k 엔드포인트를 사용합니다. 초기 출시 중에는 "ernie-x1.1-preview"로 나타날 수 있으므로 Qianfan 대시보드에서 정확한 모델 이름을 확인하세요.
JSON 본문으로 POST 요청을 보냅니다. 주요 매개변수는 다음과 같습니다:
messages: "role"(사용자 또는 어시스턴트) 및 "content"를 포함하는 딕셔너리 목록입니다.temperature: 무작위성 제어(0.0-1.0, 기본값 0.8).top_p: 핵 샘플링 임계값(기본값 0.8).stream: 응답 스트리밍을 위한 부울 값.
예시 요청 본문:
{
"messages": [
{"role": "user", "content": "Explain quantum computing."}
],
"temperature": 0.7,
"top_p": 0.9,
"stream": false
}
헤더에는 Content-Type: application/json과 URL에 액세스 토큰이 포함되어야 합니다: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-x1.1?access_token=YOUR_TOKEN.
이 형식은 단일 턴 및 다중 턴 대화를 지원합니다. 멀티모달 입력의 경우, URL 또는 base64 데이터를 사용하여 "image"와 같은 "type" 필드를 추가합니다.
ERNIE X1.1 API 응답 처리
응답은 JSON 형식으로 도착합니다. 주요 필드:
result: 생성된 텍스트.usage: 프롬프트, 완료 및 총 토큰 수.id: 고유 응답 식별자.
스트리밍 모드에서는 각 이벤트에 부분 결과가 포함된 Server-Sent Events (SSE)를 통해 청크를 처리합니다. Python에서 다음과 같이 파싱합니다:
import qianfan
chat_comp = qianfan.ChatCompletion()
resp = chat_comp.do(model="ERNIE-X1.1", messages=[{"role": "user", "content": "Hello"}], stream=True)
for chunk in resp:
print(chunk["result"])
"error_code" 필드에서 오류를 확인합니다. 일반적인 문제에는 잘못된 토큰(코드 110) 또는 속도 제한(코드 18)이 포함됩니다. 구독에 따라 할당량이 다르므로(무료 등급은 100 QPS로 제한, 유료 요금제는 더 높게 확장) 사용량을 모니터링하여 할당량 내에 머무르십시오.
기본 사항을 다루었으므로, 개발자들은 종종 간소화된 테스트를 위해 Apidog와 같은 도구를 사용합니다.
ERNIE X1.1 API 테스트를 위한 Apidog 사용
Apidog는 ERNIE X1.1 API 엔드포인트를 테스트하기 위한 훌륭한 플랫폼 역할을 합니다. 요청 설계, 디버깅 및 자동화를 위한 직관적인 인터페이스를 제공하여 협업 개발에 탁월합니다.
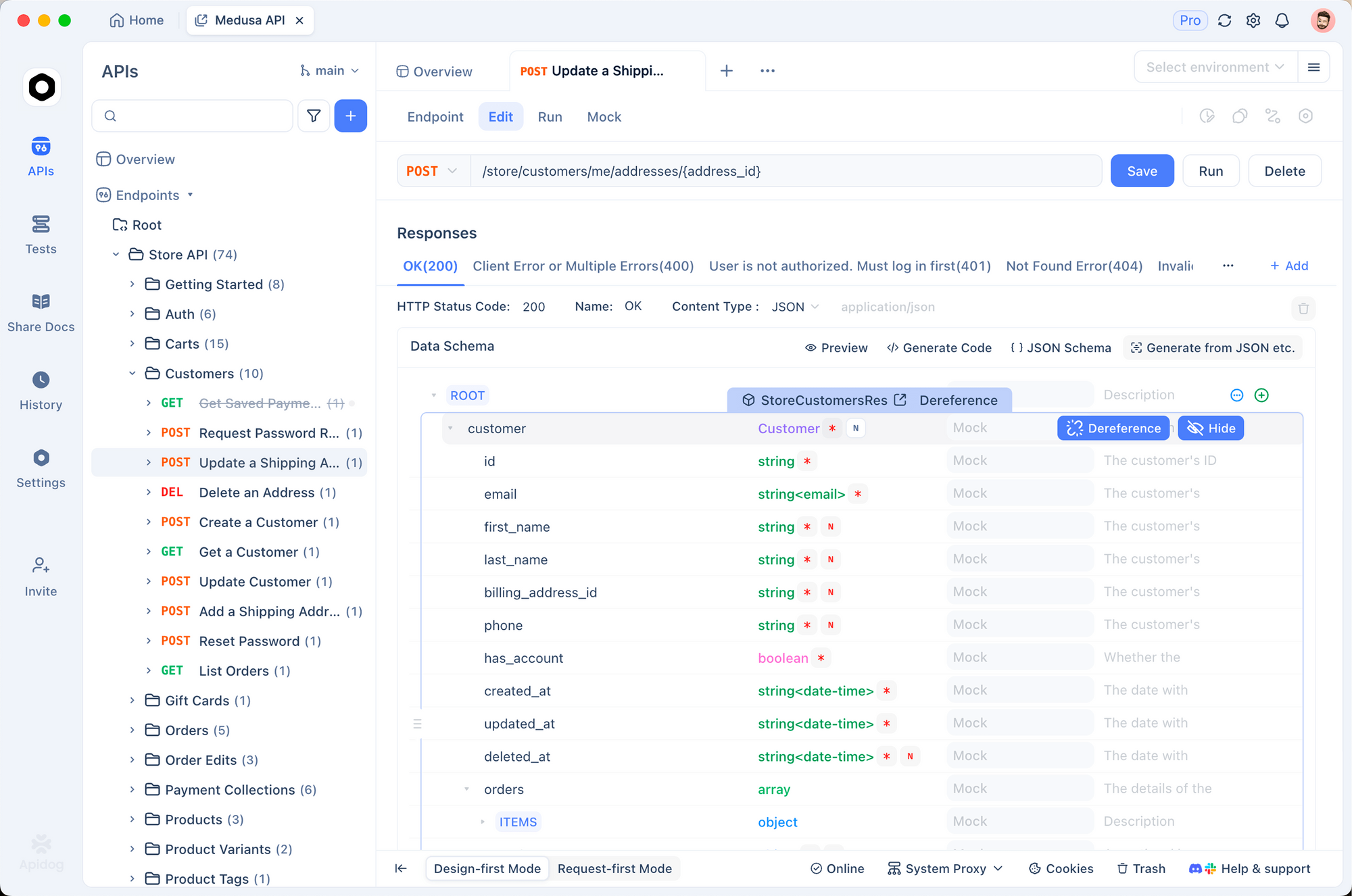
먼저, Apidog 공식 사이트에서 Apidog를 다운로드하여 설치합니다. 새 프로젝트를 생성하고 ERNIE API 사양을 가져옵니다. Apidog는 OpenAPI 가져오기를 지원하므로, 바이두의 사양이 있다면 다운로드하거나 수동으로 엔드포인트를 추가하세요.
요청을 설정하려면 API 섹션으로 이동하여 /chat/ernie-x1.1에 대한 새 POST 메서드를 생성합니다. 쿼리 매개변수에 액세스 토큰을 입력합니다. 본문 탭에서 메시지와 매개변수를 사용하여 JSON 구조를 구축합니다. Apidog의 변수 시스템을 사용하면 토큰이나 프롬프트를 매개변수화하여 재사용할 수 있습니다.
요청을 보내고 응답을 실시간으로 검사합니다. Apidog는 JSON 구조를 강조하고, 시간 기록을 추적하며, 오류를 기록합니다. 예를 들어, "데이터 분석을 위한 Python 스크립트를 생성해줘."와 같은 간단한 쿼리를 테스트해 보세요. "result" 필드를 분석하여 정확성을 확인합니다.
또한, 시나리오를 생성하여 테스트를 자동화합니다. 여러 요청을 연결하여 다중 턴 대화를 시뮬레이션할 수 있습니다. 하나는 초기 프롬프트용, 다른 하나는 후속 질문용입니다. "usage.total_tokens"이 1000 미만인지 확인하는 등 어설션을 사용하여 응답 키를 검증합니다.
Apidog는 오프라인 개발을 위한 모킹에 탁월합니다. ERNIE X1.1 응답을 모방하는 모의 서버를 생성하여 라이브 API 호출 없이 팀 협업을 가능하게 합니다. 피드백을 위해 링크를 통해 프로젝트를 공유하세요.

고급 테스트를 위해 데이터 세트를 통합합니다. 다양한 프롬프트가 포함된 CSV 파일을 업로드하고 일괄 테스트를 실행하여 일관성을 평가합니다. 이 접근 방식은 긴 입력이 컨텍스트 제한을 유발하는 것과 같은 엣지 케이스를 밝혀냅니다.
Apidog를 통합함으로써 개발 주기를 가속화할 수 있습니다. 그러나 광범위한 테스트 중에는 바이두의 속도 제한을 준수해야 합니다.
ERNIE X1.1 API의 고급 기능
ERNIE X1.1은 외부 도구를 호출하는 에이전트 작업에서 빛을 발합니다. 요청에 이름, 설명 및 매개변수를 포함하는 함수 정의 배열인 "tools"를 포함하여 이를 활성화할 수 있습니다. 모델은 필요한 경우 도구 호출로 응답하며, 이를 실행하고 다시 피드백합니다.
예를 들어, 날씨 도구를 정의합니다:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}}
}
}
}
]
ERNIE X1.1은 프롬프트를 처리하고, tool_call을 출력하며, 다음 메시지에서 결과를 응답합니다.
또한, 멀티모달 입력을 활용합니다. 메시지에서 base64를 통해 이미지를 업로드합니다: {"role": "user", "content": [{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}]}. 이는 장면 묘사 또는 차트 분석과 같은 비전 기반 추론을 가능하게 합니다.
연결된 작업을 위해 LangChain과 같은 프레임워크와 통합합니다. QianfanChatEndpoint를 사용하세요:
from langchain_community.chat_models import QianfanChatEndpoint
llm = QianfanChatEndpoint(model="ernie-x1.1")
response = llm.invoke("Summarize this text...")
이 추상화는 복잡한 워크플로우를 단순화합니다. 속도 제한은 일반적으로 입력에 대해 분당 2000 토큰으로 제한되지만, 엔터프라이즈 플랜은 맞춤형 확장을 제공합니다. 가격은 X1 변형의 경우 백만 입력 토큰당 약 $0.28로 저렴하게 시작합니다.
ERNIE X1.1 API 통합을 위한 모범 사례
엔지니어는 정확한 프롬프트를 작성하여 성능을 최적화합니다. 시스템 메시지를 사용하여 역할을 설정합니다: {"role": "system", "content": "당신은 유용한 어시스턴트입니다."}. 이는 동작을 효과적으로 안내합니다.
비용을 제어하기 위해 토큰 사용량을 모니터링합니다. 프롬프트를 다듬고 잘라내기 매개변수를 사용합니다. 또한, 네트워크 문제와 같은 일시적인 오류에 대해 지수 백오프를 사용하여 재시도를 구현합니다.
API 키를 환경 변수 또는 볼트에 안전하게 보관합니다. 응답에 민감한 데이터를 로깅하지 마십시오. 프로덕션 환경에서는 빈번한 쿼리에 대해 캐싱을 사용하여 호출 수를 줄입니다.
ERNIE X1.1은 중국어에 탁월하지만 영어도 잘 처리하므로 여러 언어에 걸쳐 테스트하십시오. 사실 Q&A에서 낮은 환각과 같은 모델의 강점에 대비하여 통합을 벤치마크하십시오.
마지막으로, 새로운 기능이나 모델 업데이트를 위해 바이두 개발자 포털을 통해 최신 정보를 확인하십시오.
ERNIE X1.1 API의 일반적인 문제 해결
토큰이 만료되면 사용자는 인증 오류를 겪을 수 있습니다. 즉시 토큰을 새로 고치십시오. 잘못된 모델 이름은 404 응답을 유발합니다. 대시보드에서 "ernie-x1.1"을 확인하십시오.
속도 제한 초과는 429 오류를 유발합니다. 큐잉 또는 플랜 업그레이드를 구현하십시오. 불완전한 응답의 경우, max_tokens 매개변수를 모델의 제한까지 늘리십시오.
전체 요청/응답 주기를 캡처하는 Apidog의 로그로 디버깅하십시오. 멀티모달이 실패하는 경우, 이미지 형식이 지원되는 유형(JPEG, PNG)과 일치하는지 확인하십시오.
지속적인 문제의 경우, 오류 코드와 타임스탬프를 제공하여 바이두 지원팀에 문의하십시오.
결론: ERNIE X1.1 API로 AI를 한 단계 높이세요
ERNIE X1.1은 개발자들이 지능적이고 신뢰할 수 있는 애플리케이션을 구축할 수 있도록 지원합니다. 설정부터 고급 통합까지, 이 가이드는 ERNIE X1.1의 모든 잠재력을 활용할 수 있는 지식을 제공합니다. 효율적인 테스트를 위해 Apidog를 통합하고, 프로젝트가 번창하는 것을 지켜보세요.
AI가 발전함에 따라 ERNIE X1.1과 같은 모델이 선두를 달리고 있습니다. 오늘부터 구현을 시작하고 정확성과 효율성의 차이를 경험해 보세요.