
DeepSeek 엔지니어들은 V3.1 모델의 반복적인 개선으로 DeepSeek-V3.1-Terminus를 출시했습니다. 이는 사용자 보고 문제들을 해결하고 핵심 강점을 강화합니다. 이 버전은 일관된 언어 출력 및 강력한 에이전트 기능과 같이 개발자들이 실제 애플리케이션에서 중요하게 여기는 실용적인 개선 사항에 중점을 둡니다. AI 모델이 발전함에 따라 DeepSeek과 같은 팀은 기반을 전면 개편하지 않고도 신뢰성을 높이는 개선 사항을 우선시합니다. 결과적으로 DeepSeek-V3.1-Terminus는 코드 생성부터 복잡한 추론에 이르는 다양한 작업을 위한 세련된 도구로 부상합니다.
버튼
이번 출시는 오픈소스 혁신에 대한 DeepSeek의 약속을 강조합니다. 이 모델은 이제 Hugging Face에 있으며, 즉각적인 실험 접근을 허용합니다. 엔지니어들은 V3.1 기반 위에 구축하여 벤치마크 전반의 성능을 향상시키는 미세 조정을 도입했습니다. 그 결과, 사용자들은 이전에 원활한 상호작용을 방해했던 중국어-영어 혼합 응답이나 불규칙한 문자 같은 불편함을 덜 겪게 됩니다.
DeepSeek-V3.1-Terminus 아키텍처 이해
DeepSeek 아키텍트들은 이전 모델인 DeepSeek-V3의 구조를 반영하여 하이브리드 MoE(Mixture of Experts) 프레임워크로 DeepSeek-V3.1-Terminus를 설계했습니다. 이 접근 방식은 밀집 및 희소 구성 요소를 결합하여 모델이 특정 작업에 대해서만 관련 전문가를 활성화하도록 합니다. 결과적으로, 이는 완전히 밀집된 모델에 비해 계산 오버헤드를 줄여 쿼리를 처리함으로써 높은 효율성을 달성합니다.

핵심적으로 이 모델은 전문가 모듈에 걸쳐 분산된 6,850억 개의 매개변수를 자랑합니다. 엔지니어들은 이러한 매개변수에 BF16, F8_E4M3, F32 텐서 유형을 사용하여 정밀도와 속도 모두를 최적화합니다. 그러나 주목할 만한 문제점은 자체 주의 출력 투영이 UE8M0 FP8 스케일 형식을 완전히 준수하지 않는다는 것인데, DeepSeek은 이를 향후 반복에서 해결할 계획입니다. 이러한 사소한 결함은 전반적인 기능에 크게 영향을 미치지 않지만, 모델 개발의 반복적인 특성을 강조합니다.
또한 DeepSeek-V3.1-Terminus는 사고 모드와 비사고 모드를 모두 지원합니다. 사고 모드에서 모델은 내부 논리를 활용하여 복잡한 문제를 처리하는 다단계 추론에 참여합니다. 반면 비사고 모드는 간단한 쿼리에 대한 빠른 응답을 우선시합니다. 이러한 이중성은 2단계 장문 컨텍스트 확장 방법을 통합한 확장된 V3.1-Base 체크포인트에 대한 후처리 훈련에서 비롯됩니다. 개발자들은 데이터셋을 강화하기 위해 추가적인 긴 문서를 수집하고, 더 나은 컨텍스트 처리를 위해 훈련 단계를 확장합니다.
이전 버전 대비 DeepSeek-V3.1-Terminus의 주요 개선 사항
DeepSeek 엔지니어들은 V3.1 릴리스의 피드백을 처리하여 DeepSeek-V3.1-Terminus를 개선했으며, 이는 실질적인 향상으로 이어졌습니다. 주로 언어 불일치를 줄여 초기 출력에서 문제가 되었던 빈번한 중국어-영어 혼합 및 무작위 문자를 제거했습니다. 이러한 변화는 특히 다국어 환경에서 더 깔끔하고 전문적인 응답을 보장합니다.
또한 에이전트 업그레이드는 주요 발전으로 두드러집니다. 코드 에이전트는 이제 향상된 정확도로 프로그래밍 작업을 처리하며, 검색 에이전트는 검색 효율성을 개선합니다. 이러한 개선 사항은 정제된 훈련 데이터와 업데이트된 템플릿에서 비롯되며, 모델이 도구를 더욱 원활하게 통합할 수 있도록 합니다.
벤치마크 비교는 이러한 성과를 정량적으로 보여줍니다. 예를 들어, 도구 사용 없는 추론 모드에서 MMLU-Pro 점수는 84.8에서 85.0으로 상승했으며, GPQA-Diamond는 80.1에서 80.7로 향상되었습니다. Humanity's Last Exam은 15.9에서 21.7로 크게 상승하여, 도전적인 평가에서 더 강력한 성능을 입증합니다. LiveCodeBench는 74.9로 거의 안정적으로 유지되었으며, Codeforces 및 Aider-Polyglot에서는 약간의 변동이 있었습니다.
에이전트 도구 사용으로 전환하면 모델은 더욱 뛰어난 성능을 발휘합니다. BrowseComp는 30.0에서 38.5로 증가했으며, SimpleQA는 93.4에서 96.8로 상승했습니다. SWE Verified는 66.0에서 68.4로, SWE-bench Multilingual은 54.5에서 57.8로, Terminal-bench는 31.3에서 36.7로 향상되었습니다. BrowseComp-zh가 약간 하락했지만, 전반적인 추세는 우수한 신뢰성을 나타냅니다.
더욱이 DeepSeek-V3.1-Terminus는 속도 저하 없이 이러한 성과를 달성합니다. 일부 경쟁 모델보다 빠르게 응답하면서도 어려운 벤치마크에서 DeepSeek-R1과 유사한 품질을 유지합니다. 이러한 균형은 더 나은 일반화를 위해 긴 컨텍스트 데이터를 통합한 최적화된 후처리 훈련에서 비롯됩니다.
DeepSeek-V3.1-Terminus의 성능 벤치마크 및 평가
평가자들은 다양한 벤치마크에서 DeepSeek-V3.1-Terminus를 평가하여 추론 및 도구 통합에서의 강점을 드러냈습니다. 도구 없는 추론에서 모델은 MMLU-Pro에서 85.0점을 기록하며 광범위한 지식 보유 능력을 보여줍니다. GPQA-Diamond는 80.7점에 도달하여 대학원 수준 질문에 대한 숙련도를 나타냅니다.
더욱이 Humanity's Last Exam에서 21.7점은 난해한 주제 처리의 개선을 강조합니다. LiveCodeBench (74.9) 및 Aider-Polyglot (76.1)과 같은 코딩 벤치마크는 실용적인 유용성을 보여주지만, Codeforces가 2046으로 하락하여 추가 튜닝이 필요한 영역을 시사합니다.
에이전트 시나리오로 전환하면 BrowseComp의 38.5점은 향상된 웹 탐색 기능을 반영합니다. SimpleQA의 거의 완벽한 96.8점은 쿼리 해결의 정확성을 강조합니다. Verified (68.4) 및 Multilingual (57.8)을 포함한 SWE-bench 제품군은 소프트웨어 엔지니어링 능력을 확인시켜 줍니다. Terminal-bench의 36.7점은 명령줄 상호작용 능력을 보여줍니다.
비교적으로 DeepSeek-V3.1-Terminus는 대부분의 지표에서 V3.1을 능가하며, 최소한의 성능 저하로 68배의 비용 이점을 달성합니다. 효율성 면에서 클로즈드 소스 모델과 경쟁하며, 비즈니스 애플리케이션에 이상적입니다.
Apidog와 같은 API 및 도구를 통한 DeepSeek-V3.1-Terminus 통합
개발자들은 DeepSeek-V3.1-Terminus를 OpenAI 호환 API를 통해 통합하여 도입을 간소화합니다. 그들은 비사고 모드에는 'deepseek-chat'을, 사고 모드에는 'deepseek-reasoner'를 지정합니다.
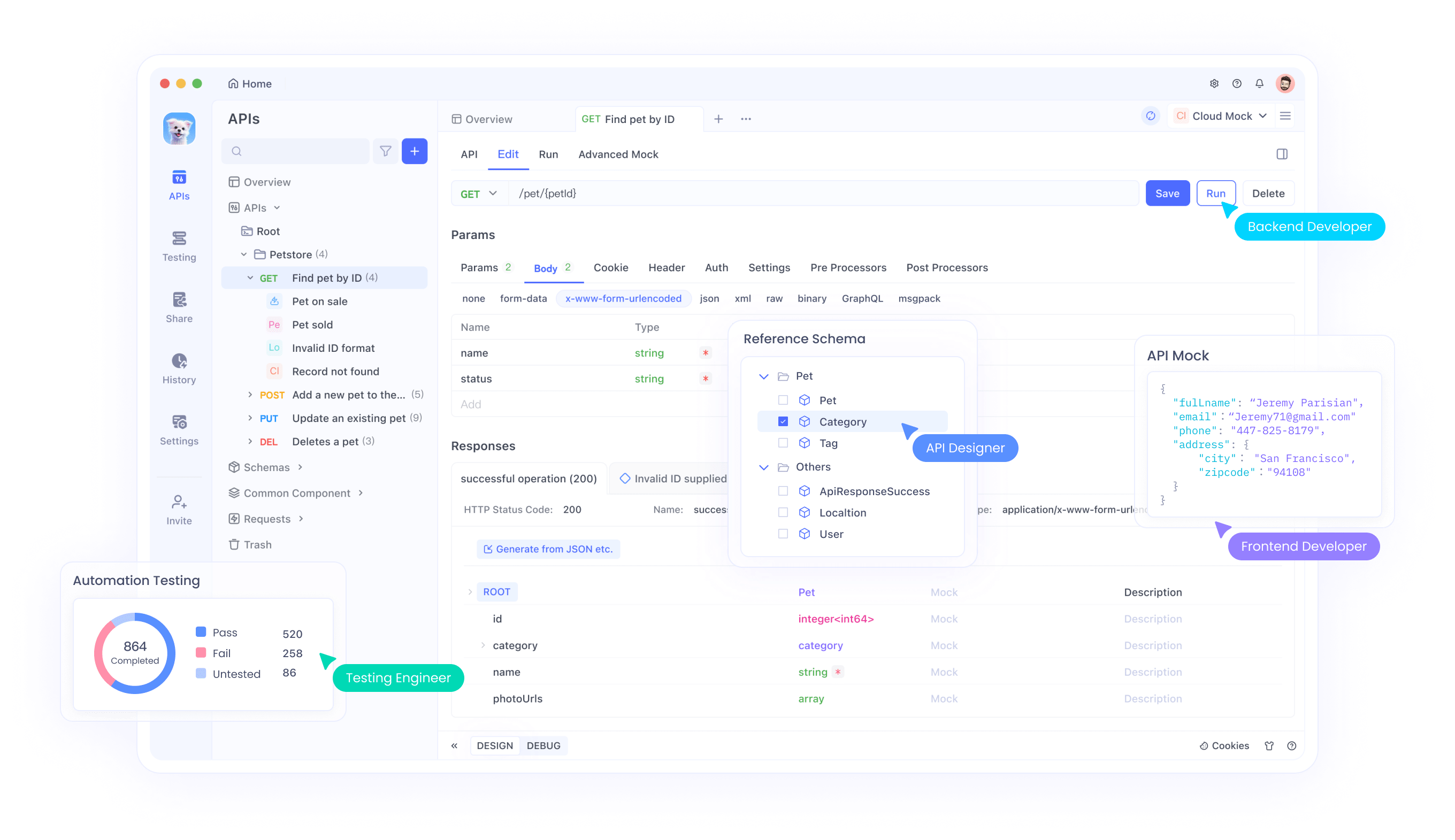
시작하려면 사용자는 DeepSeek 플랫폼에서 API 키를 생성합니다. Apidog를 사용하여 기본 URL (https://api.deepseek.com)을 입력하고 키를 변수로 저장하여 환경을 설정합니다. 이 설정은 채팅 완성 및 함수 호출 테스트를 용이하게 합니다.
더욱이 Apidog는 디버깅을 지원하여 개발자들이 응답을 효율적으로 확인할 수 있도록 합니다. 함수 호출의 경우, 요청에 도구를 정의하여 모델이 외부 함수를 동적으로 호출할 수 있도록 합니다.
가격은 출력 토큰 백만 개당 1.68달러로 경쟁력을 유지하며, 광범위한 사용을 장려합니다. 통합은 Geneplore AI 또는 AI/ML API와 같은 프레임워크로 확장되어 다중 에이전트 시스템을 지원합니다.
경쟁 AI 모델과의 비교
DeepSeek-V3.1-Terminus는 DeepSeek-R1과 같은 모델과 효과적으로 경쟁하며, 추론 품질을 유지하면서 더 빠르게 응답합니다. 도구 사용 면에서는 V3.1을 능가하며, BrowseComp에서 8.5점의 향상을 보였습니다.
독점적인 옵션과 비교하여 오픈소스 접근성과 비용 효율성을 제공합니다. 예를 들어, 벤치마크에서 Sonnet 수준의 성능에 근접합니다.
더욱이 하이브리드 모드는 일부 경쟁 모델에는 없는 다용성을 제공합니다. 따라서 강력한 기능을 찾는 예산에 민감한 개발자들에게 매력적입니다.
DeepSeek-V3.1-Terminus 배포 전략
엔지니어들은 DeepSeek-V3 리포지토리를 사용하여 모델을 로컬에 배포합니다. 클라우드의 경우 AWS Bedrock과 같은 플랫폼이 이를 호스팅합니다.
리포지토리의 최적화된 추론 코드는 설정을 돕습니다. 따라서 확장성은 다양한 환경에 적합합니다.
고급 기능: 함수 호출 및 도구 통합
개발자들은 API 요청에 스키마를 정의하여 함수 호출을 구현합니다. 이는 데이터베이스 쿼리와 같은 동적 상호작용을 가능하게 합니다.
Apidog는 이러한 기능 테스트를 지원하여 견고한 통합을 보장합니다.
비용 분석 및 최적화 팁
낮은 토큰당 비용으로 DeepSeek-V3.1-Terminus는 가치를 제공합니다. 단순한 작업에는 비사고 모드를 현명하게 선택하여 최적화하십시오.
Apidog를 통해 사용량을 모니터링하여 비용을 효과적으로 관리하십시오.
사용자 피드백 및 커뮤니티 반응
사용자들은 안정성 향상을 언급하며 이번 출시를 환영합니다. 일부는 V4를 기대하며 높은 기대를 반영합니다.
Reddit과 같은 포럼에서는 에이전트 기능의 강점에 대한 논의가 활발합니다.
결론: AI 개발에서 DeepSeek-V3.1-Terminus 활용
DeepSeek-V3.1-Terminus는 AI 기능을 개선하여 개발자들에게 강력하고 효율적인 도구를 제공합니다. 에이전트 및 언어 분야의 개선 사항은 혁신적인 애플리케이션을 위한 길을 열어줍니다. 팀들이 이를 채택함에 따라 모델은 커뮤니티의 피드백에 힘입어 계속 발전할 것입니다.
버튼