
클라우드 플랫폼에서 가장 강력한 대형 언어 모델 중 하나인 Deepseek R1을 배포할 계획이신가요? AWS, Azure 또는 Digital Ocean에서 작업하든 이 가이드는 여러분을 위한 것입니다. 이 게시글이 끝날 때쯤이면 Deepseek R1 모델을 쉽게 가동할 수 있는 명확한 로드맵을 갖게 될 것입니다. 또한 Apidog와 같은 도구가 배포 중 API 테스트를 간소화하는 방법에 대해서도 보여드리겠습니다.
클라우드에서 Deepseek R1을 배포하는 이유는?
Deepseek R1을 클라우드에 배포하는 것은 단순한 확장성에 관한 것이 아닙니다. 이는 대량의 작업을 효율적으로 처리하기 위해 GPU와 서버리스 인프라의 파워를 활용하는 것입니다. 671B 파라미터를 가진 Deepseek R1은 강력한 하드웨어와 최적화된 구성을 요구합니다. 클라우드는 더 작은 팀에서도 이러한 모델을 배포할 수 있게 해주는 유연성, 비용 효과성 및 고성능 리소스를 제공합니다.
이 가이드에서는 AWS, Azure 및 Digital Ocean의 세 가지 인기 플랫폼에서 Deepseek R1을 배포하는 방법을 안내합니다. 또한 성능 최적화 및 API 관리를 위한 Apidog와 같은 도구 통합에 대한 팁도 공유하겠습니다.
환경 준비하기
배포를 시작하기 전에 환경을 준비합시다. 여기에는 인증 토큰 설정, GPU 가용성 확인 및 파일 정리가 포함됩니다.
인증 토큰
모든 클라우드 제공업체는 어떤 형태의 인증을 요구합니다. 예를 들어:
- AWS에서는 S3 버킷 및 EC2 인스턴스에 접근할 수 있는 권한을 가진 IAM 역할이 필요합니다.
- Azure에서는 Azure Machine Learning SDK에서 제공하는 간소화된 인증 방식이 가능합니다.
- Digital Ocean에서는 계정 대시보드에서 API 토큰을 생성해야 합니다.
이 토큰들은 로컬 머신과 클라우드 플랫폼 간의 안전한 통신을 가능하게 하므로 매우 중요합니다.
파일 조직
파일을 체계적으로 조직하세요. Docker를 사용하는 경우(강력 추천), 모든 종속 항목을 포함하는 Dockerfile을 생성하십시오. Tensorfuse와 같은 도구들은 Deepseek R1의 배포를 위한 사전 구축된 템플릿을 제공합니다. IBM Cloud 사용자는 계속 진행하기 전에 모델 파일을 Object Storage에 업로드해야 합니다.
옵션 1: Tensorfuse를 사용하여 AWS에서 Deepseek R1 배포하기
여러분이 가장 널리 사용되는 클라우드 플랫폼 중 하나인 Amazon Web Services (AWS)부터 시작하겠습니다. AWS는 스위스 아미 나이프와 같아서 저장소에서 컴퓨팅 파워에 이르기까지 모든 작업을 위한 도구를 갖추고 있습니다. 이 섹션에서는 Deepseek R1 을 Tensorfuse를 사용하여 배포하는 데 초점을 맞추겠습니다. 이 과정은 상당히 간소화됩니다.
왜 Deepseek-R1로 구축해야 할까요?
기술적인 세부정보에 뛰어들기 전에, Deepseek R1이 두드러지는 이유를 이해해 봅시다:
- 평가에서의 높은 성능: 산업 표준 벤치마크에서 90.8%의 점수로 MMLU에서 강력한 결과를 달성하고 AIME 2024에서 79.8%를 기록했습니다.
- 고급 추론: 최소한의 맥락으로 다단계 논리 추론 작업을 처리하며 LiveCodeBench(Pass@1-COT)와 같은 벤치마크에서 65.9%의 점수를 기록합니다.
- 다국어 지원: 다양한 언어 데이터를 기반으로 사전 훈련되어 다국어 이해에 능숙합니다.
- 확장 가능성 있는 증류 모델: 더 작은 증류 형태(2B, 7B 및 70B)는 비용을 절감하면서도 품질을 희생하지 않는 저렴한 옵션을 제공합니다.
이러한 강점 덕분에 Deepseek R1은 챗봇에서 기업 수준의 데이터 분석에 이르기까지 생산 준비가 완료된 애플리케이션에 뛰어난 선택이 됩니다.
사전 요구 사항
시작하기 전에, AWS 계정에 Tensorfuse가 구성되어 있는지 확인하세요. 아직 진행하지 않았다면 시작하기 가이드에 따라 주세요. 이 설정은 프로젝트를 시작하기 전에 작업 공간을 준비하는 것과 같아서, 원활한 프로세스를 위해 모든 것이 제자리에 있는지 확인합니다.
1단계: API 인증 토큰 설정
API 인증 토큰으로 사용할 무작위 문자열을 생성하세요. 다음 명령어를 사용하여 Tensorfuse에서 비밀로 저장하세요:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
생산에서는 무작위로 생성된 토큰을 사용하는 것이 좋습니다. openssl rand -base64 32를 사용하면 쉽게 생성할 수 있으며, Tensorfuse 비밀이 불투명하므로 안전하게 보관하는 것을 잊지 마세요.
2단계: Dockerfile 준비
우리는 공식 vLLM OpenAI 이미지를 기본 이미지로 사용할 것입니다. 이 이미지는 vLLM을 실행하는 데 필요한 모든 종속 항목을 함께 제공합니다.
다음은 Dockerfile 구성입니다:
# Deepseek-R1-671B를 위한 Dockerfile
FROM vllm/vllm-openai:latest
# HF Hub Transfer 활성화
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# 포트 80 노출
EXPOSE 80
# API 키와 함께 엔트리포인트 설정
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
이 구성은 vLLM 서버가 Deepseek R1의 특정 요구 사항에 최적화되도록 보장합니다. GPU 메모리 활용 및 텐서 병렬성을 포함합니다.
3단계: 배포 구성
배포 설정을 정의하기 위해 deployment.yaml 파일을 생성하세요:
# Deepseek-R1-671B에 대한 deployment.yaml
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
다음 명령어를 사용하여 서비스를 배포하세요:
tensorkube deploy --config-file ./deployment.yaml
이 명령어는 인증된 요청을 처리할 준비가 된 자동 확장형 생산 LLM 서비스를 설정합니다.
4단계: 배포된 앱 접근
배포가 성공하면 curl 또는 Python의 OpenAI 클라이언트 라이브러리를 사용하여 엔드포인트를 테스트할 수 있습니다. 다음은 curl을 사용하는 예시입니다:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Earth to Robotland. What's up?",
"max_tokens": 200
}'
Python 사용자의 경우, 다음은 샘플 코드입니다:
import openai
# 실제 URL 및 토큰으로 교체하세요
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="안녕, Deepseek R1! 오늘 기분이 어때?",
max_tokens=200
)
print(response)
옵션 2: Azure에서 Deepseek R1 배포하기
Deepseek R1을 Azure Machine Learning (Azure ML)에서 배포하는 과정은 플랫폼의 강력한 인프라와 실시간 추론을 위한 고급 도구를 활용하는 간소화된 과정입니다. 이 섹션에서는 Azure ML의 관리형 온라인 엔드포인트를 사용하여 Deepseek R1을 배포하는 방법을 안내합니다. 이 접근 방식은 확장성, 효율성 및 관리 용이성을 보장합니다.
1단계: Azure ML에서 vLLM을 위한 사용자 정의 환경 만들기
시작하기 위해, vLLM에 맞게 조정된 사용자 정의 환경을 만들어야 합니다. 이 환경은 Deepseek R1을 배포하기 위한 근본적인 뼈대 역할을 합니다. vLLM 프레임워크는 높은 처리량 추론을 위해 최적화되어 있으므로 Deepseek R1과 같은 대형 언어 모델을 처리하기에 적합합니다.
1.1: Dockerfile 정의하기:모델 환경을 명시하는 Dockerfile을 작성하여 시작합니다. vLLM 기본 컨테이너는 모든 필요한 종속 항목과 드라이버를 포함하여 원활한 설정을 보장합니다:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
이 Dockerfile을 통해 환경 변수(MODEL_NAME)를 사용하여 모델 이름을 전달할 수 있어 배포 시 원하는 모델을 선택하는 유연성을 제공합니다. 예를 들어 코드 자체를 수정하지 않고도 Deepseek R1의 다양한 버전 간에 쉽게 전환할 수 있습니다.
1.2: Azure ML 작업 공간에 로그인:다음으로, Azure CLI를 사용하여 Azure ML 작업 공간에 로그인합니다. <subscription ID>, <Azure Machine Learning workspace name>, <resource group>을 자신의 세부 정보로 교체하세요:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
이 단계는 이후의 모든 명령이 귀하의 작업 공간 컨텍스트 내에서 실행되도록 보장합니다.
1.3: 환경 설정 파일 만들기:이제 환경 설정을 정의하기 위해 environment.yml 파일을 생성해야 합니다. 이 파일은 우리가 이전에 만든 Dockerfile를 참조합니다:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: 환경 구축하기:구성 파일이 준비되면 다음 명령어를 사용하여 환경을 구축하세요:
az ml environment create -f environment.yml
이 단계는 환경을 컴파일하여 배포에서 사용할 수 있게 만듭니다.
2단계: Azure ML 관리형 온라인 엔드포인트 배포하기
환경이 설정되면 Deepseek R1 모델을 Azure ML의 관리형 온라인 엔드포인트를 사용하여 배포로 넘어갑니다. 이러한 엔드포인트는 확장 가능하고 실시간 추론 기능을 제공하여 생산 품질의 애플리케이션에 적합합니다.
2.1: 엔드포인트 구성 파일 만들기:시작하려면 endpoint.yml 파일을 만들어 관리형 온라인 엔드포인트를 정의합니다:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
이 구성은 엔드포인트의 이름(r1-prod)과 인증 모드(key)를 명시합니다. 나중에 테스트 목적으로 엔드포인트의 스코어링 URI 및 API 키를 가져올 수 있습니다.
2.2: 엔드포인트 생성:다음 명령어를 사용하여 엔드포인트를 생성합니다:
az ml online-endpoint create -f endpoint.yml
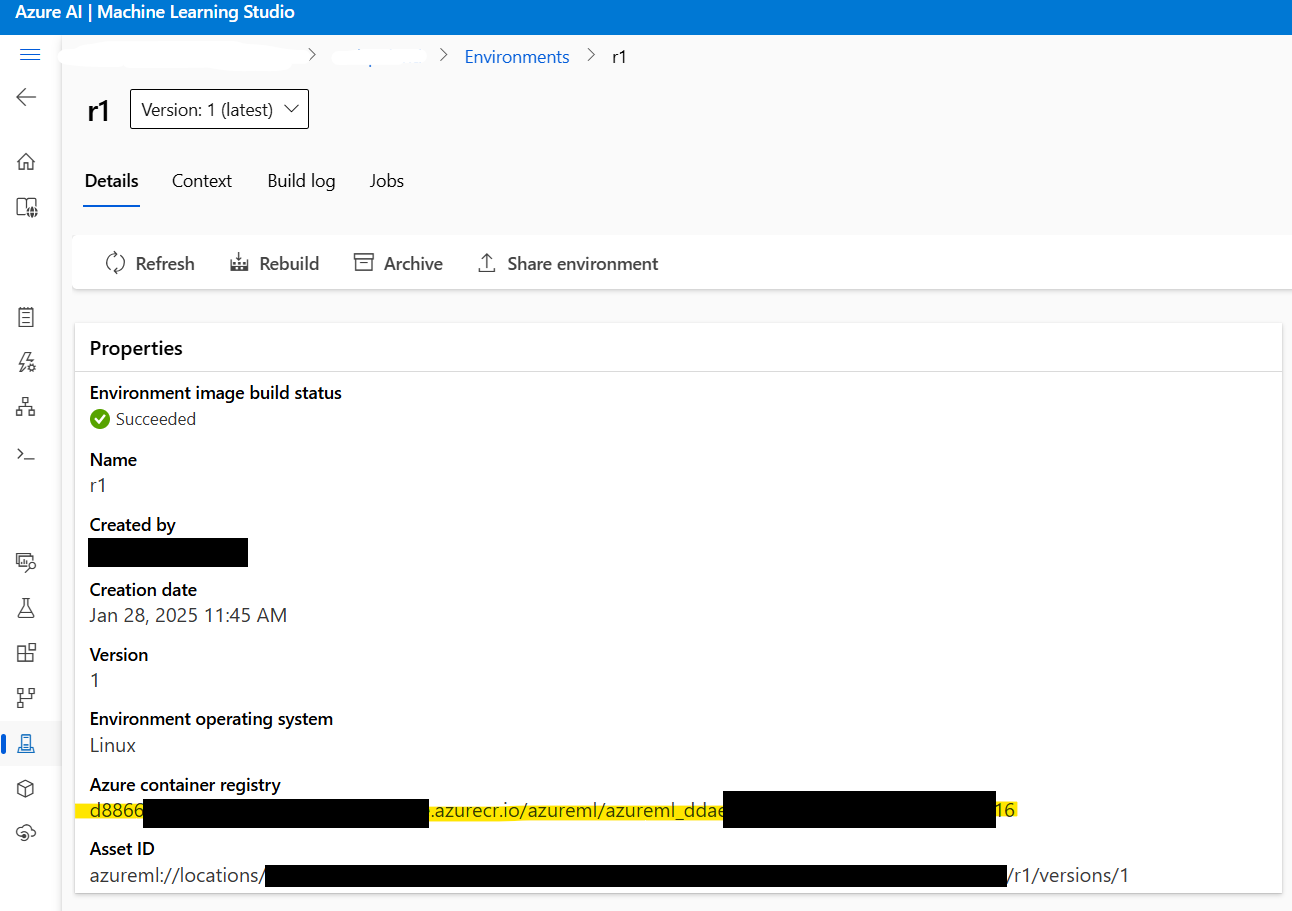
2.3: Docker 이미지 주소 가져오기:진행하기 전에, 1단계에서 생성된 Docker 이미지의 주소를 가져옵니다. Azure ML Studio > Environments > r1로 이동하여 이미지 주소를 찾을 수 있습니다. 주소는 다음과 비슷할 것입니다:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
2.4: 배포 구성 파일 만들기:다음으로, 배포 설정을 구성하기 위해 deployment.yml 파일을 생성합니다. 이 파일은 모델, 인스턴스 유형 및 기타 매개변수를 지정합니다:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # vLLM 런타임에 대한 선택적 인수
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # 여기에 Docker 이미지 주소 붙여넣기
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # 선택적이나 처리량 최적화에 중요
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # 모델이 평화롭게 로드될 수 있도록 120초 대기 후 probing
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
중요한 매개변수:
instance_count:Standard_NC24ads_A100_v4의 노드 수를 정의합니다. 이 값을 높이면 처리량이 선형으로 증가하지만 비용도 증가합니다.max_concurrent_requests_per_instance: 인스턴스당 허용되는 동시 요청 수를 제어합니다. 높은 값은 처리량을 증가시키지만 대기 시간을 높일 수 있습니다.request_timeout_ms: 엔드포인트가 응답을 기다리는 최대 시간(밀리초)을 지정합니다. 작업 부하에 따라 이 값을 조정하세요.
2.5: 모델 배포:마지막으로, 다음 명령어를 사용하여 Deepseek R1 모델을 배포합니다:
az ml online-deployment create -f deployment.yml --all-traffic
이 단계는 배포를 완료하고 지정된 엔드포인트를 통해 모델에 접근할 수 있게 합니다.
3단계: 배포 테스트
배포가 완료되면 이상이 없는지 확인하기 위해 엔드포인트를 테스트할 시간입니다.
3.1: 엔드포인트 세부정보 가져오기:다음 명령어를 사용하여 엔드포인트의 스코어링 URI 및 API 키를 가져옵니다:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: OpenAI SDK를 사용하여 응답 스트리밍:스트리밍 응답을 위해 OpenAI SDK를 사용할 수 있습니다:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "여름과 겨울 중 무엇이 더 나은가요?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
4단계: 모니터링 및 자동 확장
Azure Monitor는 리소스 활용도에 대한 포괄적인 통찰력을 제공합니다. GPU 메트릭도 포함되어 있습니다. 지속적인 부하 아래에서 vLLM은 약 90%의 GPU 메모리를 소모하며 GPU 활용도가 100%에 가까워질 것입니다. 이러한 메트릭은 성능을 미세 조정하고 비용을 최적화하는 데 도움을 줍니다.
자동 확장을 활성화하려면 트래픽 패턴을 기반으로 확장 정책을 구성하세요. 예를 들어, 피크 시간 동안 instance_count를 늘리고 비수기 동안 이를 줄여 성능과 비용의 균형을 맞출 수 있습니다.
옵션 3: Digital Ocean에서 Deepseek R1 배포하기
마지막으로, 간단함과 저렴함으로 잘 알려진 Digital Ocean에서 Deepseek R1을 배포하는 방법을 논의해 보겠습니다.
사전 요구 사항
배포 프로세스에 뛰어들기 전에 필요한 모든 것이 준비되었는지 확인해 보세요:
- DigitalOcean 계정: 계정이 없다면 DigitalOcean 계정을 만드세요. 새로운 사용자는 첫 60일 동안 사용할 수 있는 $100 크레딧을 받으며, 이것은 GPU 구동 드롭렛을 실험하기에 적합합니다.
- Bash Shell 친숙함: 터미널을 사용하여 드롭렛과 상호작용하고 종속 항목을 다운로드하며 명령을 실행해야 합니다. 전문가가 아니더라도 각 명령이 단계별로 제공됩니다.
- GPU 드롭렛: DigitalOcean은 이제 AI/ML 워크로드를 위해 특별히 설계된 GPU 드롭렛을 제공합니다. 이러한 드롭렛은 NVIDIA H100 GPU를 장착하고 있어 Deepseek R1과 같은 대형 모델을 배포하는 데 이상적입니다.
이러한 사전 요구 사항이 갖추어졌다면 앞으로 나아갈 준비가 완료되었습니다.
GPU 드롭렛 설정하기
첫 단계는 머신을 설정하는 것입니다. 이를 그림을 그리기 전에 캔버스를 준비하는 것처럼 생각하세요. 세부 사항에 뛰어들기 전에 모든 것이 준비되어 있어야 합니다.
1단계: 새로운 GPU 드롭렛 만들기
- DigitalOcean 계정에 로그인하고 Droplets 섹션으로 이동하세요.
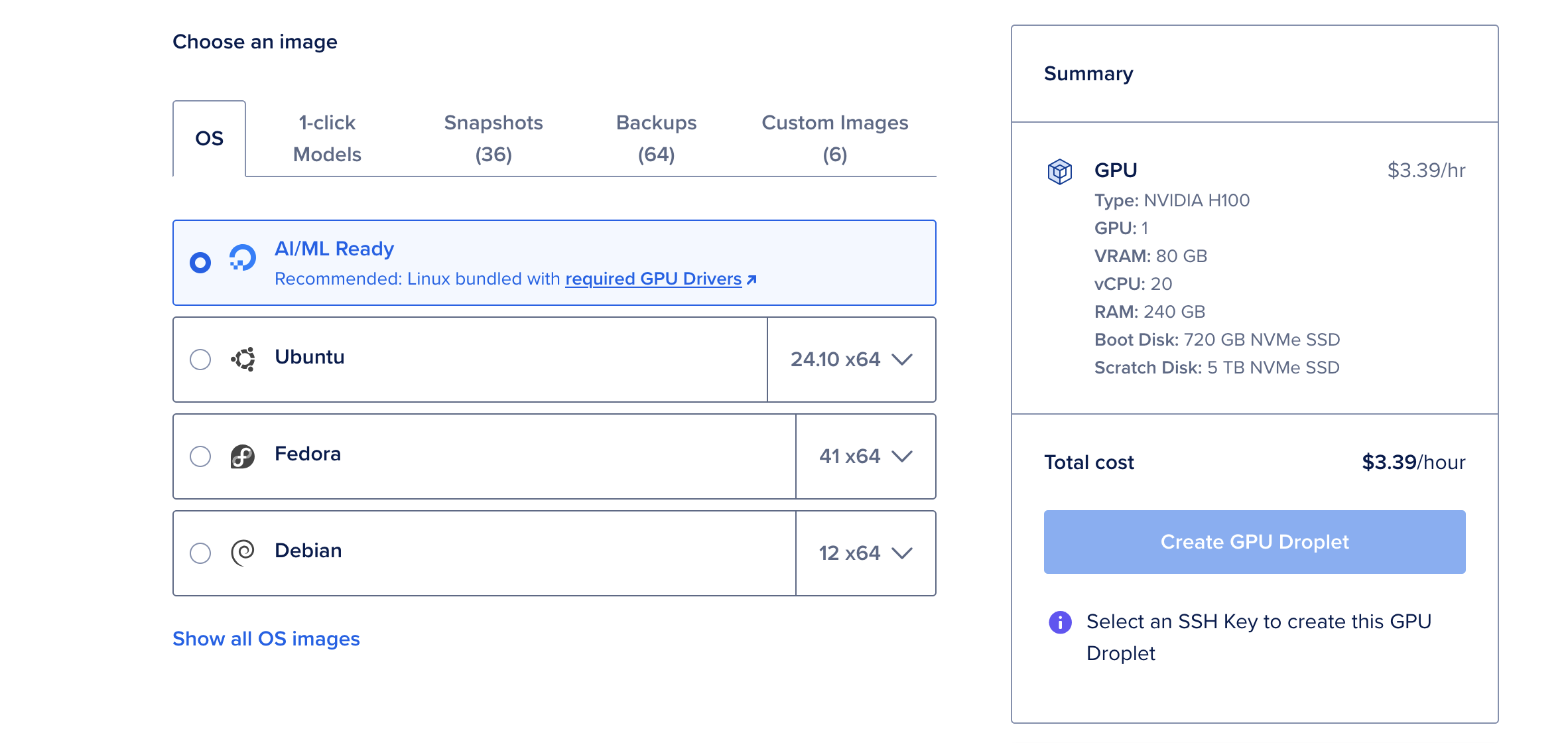
- Create Droplet를 클릭하고 AI/ML Ready 운영 체제를 선택하세요. 이 운영 체제는 GPU 가속에 필요한 CUDA 드라이버 및 기타 종속 항목이 사전 구성되어 있습니다.
- 여러 GPU가 필요할 수 있는 Deepseek R1의 가장 큰 671B 파라미터 버전을 배포하지 않는 경우 단일 NVIDIA H100 GPU를 선택합니다.
- 드롭렛이 생성될 때까지 기다리세요. 이 과정은 일반적으로 몇 분 정도 소요됩니다.
H100 GPU를 선택해야 하는 이유는?
NVIDIA H100 GPU는 80GB의 vRAM, 240GB의 RAM 및 720GB의 저장 공간을 제공하는 강력한 모델입니다. 시간당 $6.47에 대형 언어 모델인 Deepseek R1를 배포하는 데 비용 효과적인 옵션입니다. 70B 파라미터 모델과 같은 더 작은 모델은 단일 H100 GPU로도 충분합니다.
Ollama 및 Deepseek R1 설치하기
GPU 드롭렛이 가동되고 나면 Deepseek R1을 실행하는 데 필요한 도구를 설치할 시간입니다. 우리는 대형 언어 모델의 배포를 단순화하기 위해 설계된 경량 프레임워크인 Ollama를 사용할 것입니다.
1단계: 웹 콘솔 열기
드롭렛의 세부 정보 페이지에서 오른쪽 상단 모서리에 있는 웹 콘솔 버튼을 클릭합니다. 이렇게 하면 SSH 구성이 필요 없이 브라우저에서 직접 터미널 창이 열립니다.
2단계: Ollama 설치하기
터미널에서 다음 명령어를 붙여넣어 Ollama를 설치하세요:
curl -fsSL https://ollama.com/install.sh | sh
이 스크립트는 설치 과정을 자동화하며, 필요한 모든 종속 항목을 다운로드하고 구성합니다. 설치는 몇 분 정도 걸릴 수 있으며, 완료되면 머신에서 Deepseek R1을 실행할 준비가 됩니다.
3단계: Deepseek R1 실행하기
Ollama가 설치되면 Deepseek R1을 실행하는 것은 단 하나의 명령을 실행하는 것처럼 간단합니다. 이번 데모에서는 성능과 자원 사용의 균형을 이룬 70B 파라미터 버전을 사용할 것입니다:
ollama run deepseek-r1:70b
이 명령을 처음 실행하면 모델이 다운로드(약 40GB)되고 메모리에 로드됩니다. 이 과정은 몇 분 정도 걸릴 수 있지만, 이후는 모델이 로컬에 캐시되어 훨씬 빠르게 실행됩니다.
모델이 로드되면 Deepseek R1과 상호작용을 시작할 수 있는 인터랙티브한 프롬프트가 표시됩니다. 지능적인 조수와 대화하는 것과 같은 경험을 제공합니다!
Apidog로 테스트 및 모니터링 하기
Deepseek R1 모델이 배포되고 나면 이제 성능을 테스트하고 모니터링할 시간입니다. 이때 Apidog가 빛을 발합니다.
Apidog란?
Apidog는 디버깅 및 검증을 단순화하기 위해 설계된 강력한 API 테스트 도구입니다. 직관적인 인터페이스를 통해 테스트 케이스를 빠르게 만들고, 모킹 응답을 설정하며, API 상태를 모니터링할 수 있습니다.
Apidog를 사용해야 하는 이유는?
- 사용 용이성: 코딩이 필요 없습니다! 드래그 앤 드롭 기능으로 시각적으로 테스트를 구축할 수 있습니다.
- 통합 기능: CI/CD 파이프라인과 원활하게 통합되어 DevOps 워크플로에 적합합니다.
- 실시간 통찰력: 실시간으로 지연 시간, 오류 비율 및 처리량을 모니터링합니다.
Apidog를 워크플로에 통합함으로써 Deepseek R1 배포가 신뢰할 수 있고 다양한 부하에서 최적의 성능을 유지할 수 있도록 보장할 수 있습니다.
결론
Deepseek R1을 클라우드에서 배포하는 것은 어려울 필요가 없습니다. 위에 설명된 단계를 따르면 AWS, Azure 또는 Digital Ocean에서 이 최첨단 모델을 성공적으로 설정할 수 있습니다. 또한 Apidog와 같은 도구를 활용하여 테스트 및 모니터링 과정을 간소화하는 것을 잊지 마세요.