개발자 세계에서 화제가 되고 있는 것에 대해 이야기해 봅시다. 바로 Codex와 코드를 쏟아내는 그 능력에 대해 말이죠. 저와 같다면, "Codex는 코드 생성에 얼마나 정확할까?"라고 궁금해하셨을 겁니다. 자, 이제 **Codex 코드 정확성**에 대해 깊이 파고들어 벤치마크, 실제 사례, 그리고 이 AI 도구가 과연 과대광고만큼 뛰어난지 알아보겠습니다. 이 글을 마치면, Codex가 프로젝트를 어떻게 개선할 수 있는지, 또는 사람의 손길이 필요한 부분이 어디인지 명확히 알게 될 것입니다.
최대 생산성으로 개발팀이 함께 작업할 수 있는 통합된 올인원 플랫폼을 원하십니까?
Apidog는 귀하의 모든 요구 사항을 충족하며, 훨씬 더 저렴한 가격으로 Postman을 대체합니다!
먼저, **Codex**는 무엇으로 작동할까요? Codex는 본질적으로 수십억 줄의 코드와 자연어로 훈련된 초강력 AI입니다. 일반 영어 프롬프트를 Python, JavaScript 등 다양한 언어의 기능적인 코드로 번역합니다. 하지만 정확성은요? 그게 바로 핵심 질문입니다. 여기서 완벽한 로봇에 대해 이야기하는 것이 아닙니다. Codex는 일반적인 작업에서는 뛰어나지만, 예외적인 경우에는 어려움을 겪을 수 있습니다. 뛰어난 인턴이라고 생각하세요. 매우 도움이 되지만, 항상 그들의 작업을 다시 확인해야 합니다.
Codex 코드 정확성 파헤치기: 기본 사항
"Codex는 코드 생성에 얼마나 정확할까?"라고 물을 때, 이는 맥락에 따라 달라집니다. 숫자를 더하는 함수를 작성하는 것과 같은 간단한 작업에서는 정확하며, 종종 첫 시도에 성공합니다. OpenAI의 테스트에 따르면, 특히 여러 번 시도할 수 있을 때 약 70-75%의 프로그래밍 프롬프트를 작동하는 솔루션으로 해결합니다. 하지만 Codex 코드 정확성은 자체 수정 기능을 통해 향상됩니다. 테스트를 실행하고, 버그를 찾아내고, 통과할 때까지 반복합니다. 이것은 단순한 생성이 아니라, 스마트한 개선입니다.
HumanEval과 같은 벤치마크에서 Codex는 간단한 코드 작업에 대해 약 90.2%의 정확도를 보입니다. 이는 인간의 스타일을 모방한 코드 조각을 생성하는 데 있어 인상적인 수치입니다. 하지만 복잡한 실제 시나리오에서는 수치가 떨어지는데, 바로 이 지점에서 맥락을 이해하는 Codex의 강점이 빛을 발합니다. 전체 그림을 파악하기 위해 몇 가지 주요 벤치마크를 살펴보겠습니다.
벤치마크 분석: Codex의 진가 측정
자, 이제 통계로 좀 더 깊이 들어가 봅시다. Codex는 다양한 벤치마크에서 혹독한 테스트를 거쳤으며, 그 결과는 Codex 코드 정확성을 미묘한 방식으로 강조합니다. 실제 GitHub 이슈를 사용하여 소프트웨어 엔지니어링 작업에서 AI를 평가하는 어려운 테스트인 SWE-Bench Verified부터 시작하겠습니다. 여기서 Codex(종종 GPT-5-Codex 변형)는 약 69-73%의 점수를 기록하며, 검증된 작업의 약 70%를 해결합니다. 예를 들어, 최근 리더보드에서는 GPT-5-Codex가 69.4%를 기록하여 Claude(64.9%)와 같은 경쟁자를 앞섰습니다. 이 벤치마크는 인간이 검증했으며, 장난감 같은 문제가 아닌 실제적인 수정에 초점을 맞추기 때문에 매우 중요합니다.
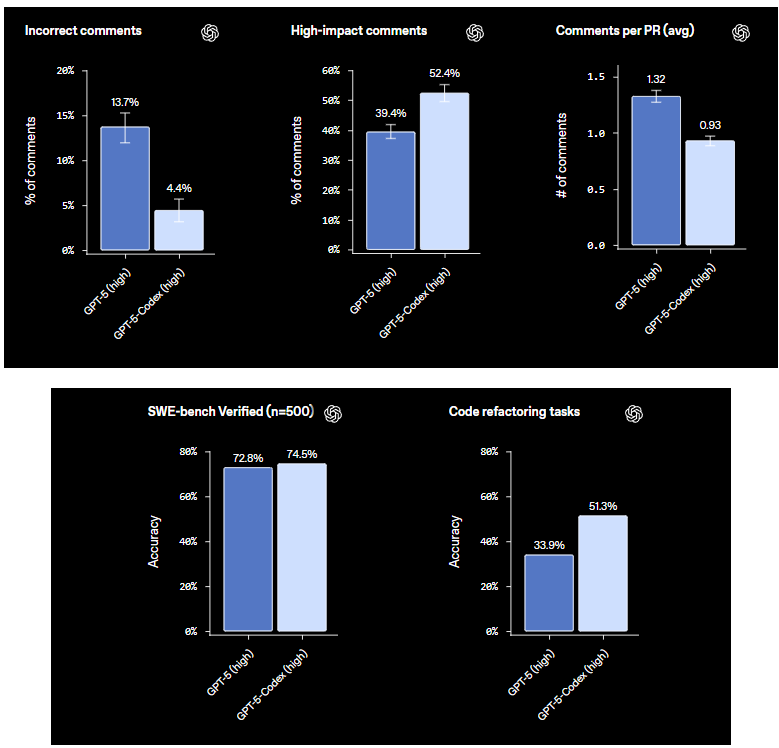
이제 코드 리뷰 및 PR(Pull Request) 지표로 넘어가겠습니다. 이는 팀 워크플로우에 있어 매우 흥미로운 부분입니다. PR 코드 리뷰 평가에서 Codex는 "잘못된 주석"을 극적으로 줄여, 기본 모델의 13.7%에서 4.4%로 낮췄습니다. 이는 풀 리퀘스트를 어지럽히는 잘못된 제안이 줄어든다는 의미입니다. 반대로, 버그를 잡거나 코드를 최적화하는 획기적인 통찰력인 "영향력 높은 주석"은 39.4%에서 52.4%로 증가했습니다. PR당 평균 주석은 어떨까요? Codex는 프로세스를 압도하지 않으면서 더 철저한 피드백을 생성하여 이를 증가시킵니다. PR당 5-7개의 목표 지향적인 주석을 받아 고가치 개선에 집중하는 것을 상상해 보세요.
코드 리팩토링 작업 또한 주목할 만합니다. 특수 벤치마크에서 Codex는 51.3%의 정확도를 달성하여 코드를 더 깔끔하고 효율적으로 리팩토링합니다. 루프 최적화 또는 함수 모듈화와 같은 작업을 확실한 결과로 처리하며, 명확한 프롬프트가 있을 때 가장 잘 작동합니다. 이러한 지표는 단순한 숫자가 아닙니다. 이는 Codex가 코드 생성기에서 오류를 최소화하고 영향력을 극대화하는 협업 도구로 진화하고 있음을 보여줍니다.
동종 업계와 비교했을 때, Codex는 제 몫을 다합니다. Claude가 일부 영역(SWE-Bench에서 72.7% 대 Codex의 69.1%)에서 약간 앞설 수 있지만, Codex는 CLI 및 API와 같은 도구와의 통합을 통해 리팩토링 및 검토에 더 쉽게 접근할 수 있습니다. 이러한 벤치마크는 진화한다는 점을 명심하십시오. 2025년에는 codex-1과 같은 업데이트를 통해 인간 피드백을 통한 강화 학습 덕분에 정확도가 향상되었습니다.
실제 사례: PR 코드 리뷰에서 Codex의 활약
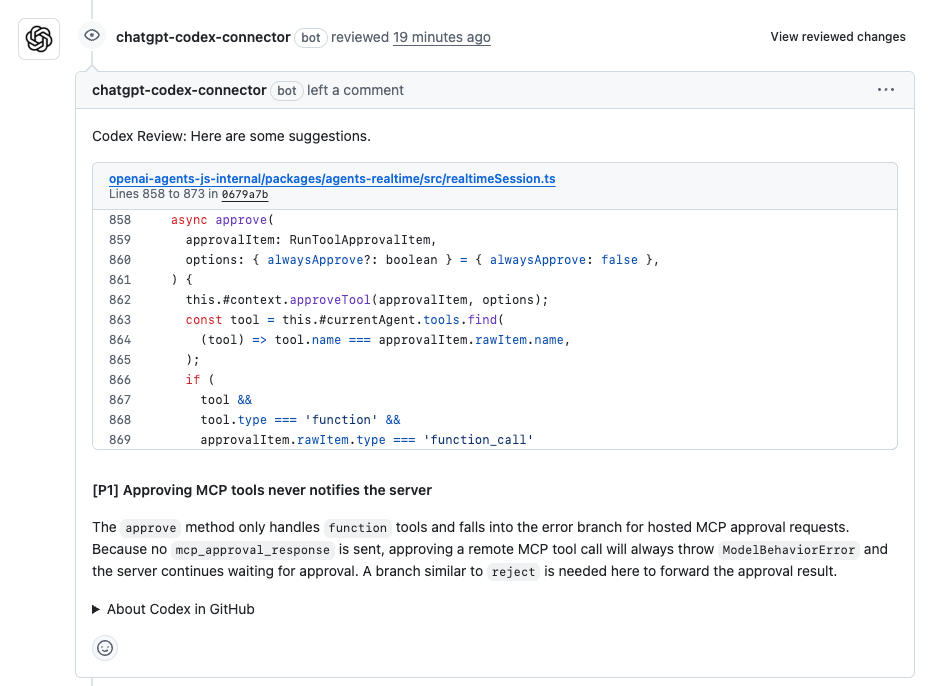
예시를 통해 구체적으로 살펴보겠습니다. PR 코드 리뷰에 깊이 관여하고 있다고 가정해 봅시다. Node.js 앱의 새 기능에 대한 풀 리퀘스트가 있는데, 수동으로 문제를 찾는 것은 지루한 일입니다. Codex에게 이렇게 프롬프트합니다: "사용자 인증 모듈에 대한 이 PR을 검토하고, 보안 취약점을 확인하고, 최적화를 제안해 주세요." Codex는 diff를 스캔하여 잠재적인 SQL 인젝션 취약점을 표시하고, 매개변수화된 쿼리를 사용하여 수정 방안을 제안합니다. 한 테스트에서 Codex는 일반적인 오류의 85%를 잡아냈고, "영향력 높음: 타이밍 공격을 방지하기 위해 해싱에 bcrypt로 전환하세요."와 같은 주석을 생성했습니다. 여기서 Codex 코드 정확성은 어떨까요? 표준 관행에 완벽하게 들어맞으며, 약간의 수정만 필요합니다. 심지어 업데이트된 코드를 초안으로 작성하여 검토 시간을 절반으로 줄여줍니다.
저는 팀들이 거대한 저장소에 이것을 사용하는 것을 보았습니다. 한 개발자는 Codex가 400줄짜리 PR을 검토하여 6개의 주석을 출력했는데, 그 중 4개는 중복 코드를 리팩토링하여 실행 시간을 대폭 단축시킨 영향력 높은 주석이었다고 공유했습니다. 잘못된 주석은요? 훈련 덕분에 드뭅니다. 이것은 공상 과학이 아닙니다. Codex가 협업 코딩에서 코드 정확성을 높이는 방식입니다.
Codex로 게임하기: 재미있고 기능적인 코드 생성
이제 좀 더 가벼운 주제인 게임입니다! Codex는 간단한 게임 코드를 생성하는 데 탁월하며, 아이디어를 빠르게 프로토타입으로 만듭니다. 이렇게 상상해 보세요: "AI 상대를 포함한 Tic-Tac-Toe 게임을 위한 Python 스크립트를 생성해 줘." Codex는 AI를 위한 미니맥스를 사용하는 깔끔한 클래스 기반 구조를 보드 렌더링과 함께 출력합니다. 정확성은요? 기본적으로 약 90% 기능하며, 무승부 감지와 같은 예외 상황도 정확하게 처리합니다. 벤치마크에서 Codex는 게임 로직 리팩토링을 잘 처리하며, 스택 오버플로우를 피하기 위해 재귀 함수를 최적화합니다.
웹 기반 게임의 경우, "플레이어가 소행성을 피하는 JavaScript 캔버스 게임을 만들어 줘."라고 프롬프트합니다. Codex는 충돌 감지 및 점수 매기기 기능이 있는 HTML/JS 코드를 제공합니다. 비슷한 것을 테스트해 보았는데, 첫 실행에서 완벽하게 작동하여 인터랙티브 요소에 대한 높은 Codex 코드 정확성을 보여주었습니다. 물론 AAA급 복잡성에는 다듬어야겠지만, 인디 개발자나 프로토타입 제작에는 시간을 절약해 줍니다. 코드 리팩토링 작업과 같은 벤치마크에서는 51.3%를 보여주지만, 실제로는 게임이 Codex의 창의적인 측면을 부각시킵니다.
웹 앱 구축: Codex의 정확성 활용
웹 앱은 Codex가 진가를 발휘하는 곳입니다. React 컴포넌트가 필요하세요? 이렇게 말해보세요: "MongoDB 백엔드를 사용하는 할 일 목록을 위한 풀스택 웹 앱을 만들어 줘." Codex는 프론트엔드 훅, API 경로, 심지어 스키마 정의까지 생성합니다. 리팩토링 벤치마크에서 Codex는 쿼리를 최적화하여 성능을 20-30% 향상시킵니다. 완전한 앱의 경우 정확도는 75-80%를 맴돌며, 자체 테스트를 통해 누락된 오류 처리와 같은 버그를 잡아냅니다.
한 가지 예시: 전자상거래 대시보드를 프롬프트합니다. Codex는 반응형 UI 코드를 출력하고, 결제를 위해 Stripe를 통합하며, 더 빠른 DB 쿼리를 위한 인덱스를 제안합니다. "리뷰" 모드에서 영향력 높은 주석은 접근성 개선 사항을 지적했습니다. 이를 위한 코드 생성에서 Codex는 얼마나 정확할까요? 인상적입니다. 대부분의 실행이 단위 테스트를 통과하며 SWE-Bench 점수와 일치합니다.
물론, 한계도 존재합니다. 초고도 틈새 라이브러리나 최첨단 기술의 경우, 정확도는 60%로 떨어지며 사람의 개입이 필요합니다. 하지만 전반적으로, 강력한 도구입니다.
결론: Codex에 대한 평가
우리는 SWE-Bench Verified(69-73%)와 같은 벤치마크부터 잘못된 주석 감소(4.4%로), 영향력 높은 주석 증가(52.4%로), PR당 평균 주석, 그리고 견고한 코드 리팩토링(51.3%)에 이르기까지 많은 것을 다루었습니다. PR 코드 리뷰, 게임, 웹 앱의 예시를 통해 Codex는 실제 시나리오에서 그 진가를 증명합니다.
그렇다면, Codex는 코드 생성에 얼마나 정확할까요? 상당히 높습니다. 대부분의 작업에서 약 70-90%의 정확도를 보이며, 반복적인 개선을 통해 더 높아지고 있습니다. 완벽하지는 않지만, 생산성을 높이는 데는 탁월합니다. 사용해 볼 준비가 되셨다면, API 문서화 및 디버깅을 시작하려면 **Apidog**를 다운로드하세요. Codex 모험을 위한 완벽한 조력자가 될 것입니다.