
안트로픽의 클로드는 최근 새로운 기능으로 주목받았습니다. 이 기능은 실시간 웹 정보를 접근하고 합성하여 실제로 연구 도우미 역할을 수행합니다. 이 기능은 종종 "클로드 리서치"라고 언급되며, 단순한 웹 검색을 넘어 주제의 여러 측면을 탐구하고 다양한 출처의 정보를 모아 종합된 답변을 제공합니다. 강력한 기능이지만, 폐쇄형 독점 시스템에 의존하는 것은 항상 이상적이지 않습니다. 많은 사용자가 더 많은 제어, 투명성, 커스터마이징을 원하거나 단순히 기본 기술을 실험해보고 싶어 합니다.

좋은 소식은 오픈소스 커뮤니티가 이런 기능을 복제하는 데 필요한 구성 요소를 자주 제공한다는 것입니다. 이 분야에서 흥미로운 프로젝트 중 하나는 btahir/open-deep-research입니다. 이 도구는 웹 검색 및 대형 언어 모델(LLM)을 활용하여 주제에 대한 심도 있는 연구를 자동화하는 것을 목표로 합니다.
우선, 클로드의 정교한 AI 연구 기능이 제공하는 핵심 역량을 이해하고, open-deep-research가 오픈소스 방식으로 이를 모방하고자 하는 방법에 대해 알아보겠습니다.
open-deep-research 소개: 당신의 오픈소스 시작점
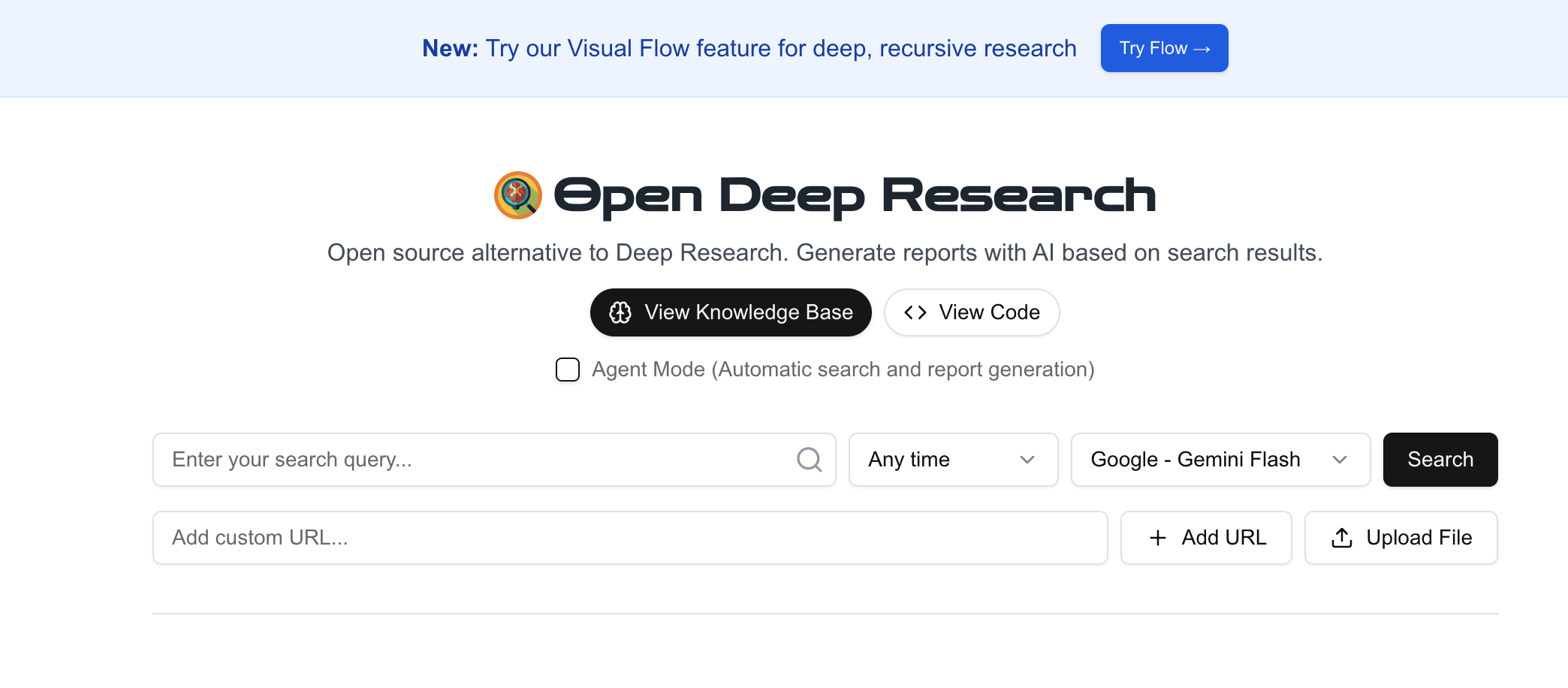
open-deep-research 프로젝트 (https://github.com/btahir/open-deep-research)는 쉽게 사용할 수 있는 도구와 API를 통해 유사한 목표를 달성할 수 있는 프레임워크를 제공합니다. 이 프로젝트는 다음과 같은 파이프라인을 조율하는 것으로 보입니다:
- 검색 엔진 쿼리: API(예: SearchApi, Google Search API)를 사용하여 주어진 연구 주제에 대한 관련 웹 페이지를 찾습니다.
- 웹 스크래핑: 식별된 URL에서 콘텐츠를 가져옵니다.
- LLM 처리: 대형 언어 모델(일반적으로 OpenAI API를 통해 사용하나, 적응 가능성 있음)을 활용하여 웹 페이지에서 수집된 정보를 읽고 이해하며 합성하고 구조화합니다.
- 보고서 생성: 처리된 정보를 최종 출력물로 컴파일합니다. 예: 자세한 보고서 등.
이 과정을 직접 실행함으로써 프로세스에 대한 투명성을 얻고 잠재적으로 사용자 정의할 수 있는 능력을 가지게 됩니다.
개발 팀이 함께 최대 생산성으로 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요?
Apidog는 귀하의 모든 요구를 충족시키며, 보다 저렴한 가격에 포스트맨을 대체합니다!

open-deep-research 실행 단계별 안내
자신만의 연구 도우미를 만들 준비가 되셨나요? open-deep-research를 시작하는 데 필요한 상세한 가이드를 제공합니다.
사전 요구 사항:
- 파이썬: 시스템에 파이썬이 설치되어 있어야 합니다(보통 Python 3.7+).
- Git: 저장소를 복제하는 데 필요합니다.
- API 키: 이는 매우 중요합니다. 도구는 다음에 대한 API 키가 필요합니다:
- 검색 엔진 API: 프로그래밍 방식으로 웹 검색을 수행하기 위해 필요합니다. 예로는 SearchApi, Serper, 또는 프로젝트 설정에 따라 다른 것이 포함될 수 있습니다. 이러한 서비스 중 하나에 가입하고 API 키를 받아야 합니다.
- LLM API: 합성 단계에서 GPT 모델(예: GPT-3.5 또는 GPT-4)에 접근하기 위해 OpenAI API 키가 필요할 것입니다. OpenAI 계정이 필요하고 API 접근 권한을 가져야 합니다.
- (필요한 API와 키는
open-deep-researchREADME를 확인하세요). - 명령행 / 터미널: 터미널이나 명령 프롬프트에서 명령을 실행할 것입니다.
1단계: 저장소 복제
먼저 터미널을 열고 프로젝트를 저장할 디렉토리로 이동하세요. 그 다음, GitHub 저장소를 복제합니다:
git clone <https://github.com/btahir/open-deep-research.git>
이제 새로 생성된 프로젝트 디렉토리로 이동하세요:
cd open-deep-research
2단계: 가상 환경 설정(권장)
프로젝트 종속성을 별도로 관리하기 위해 가상 환경을 사용하는 것이 모범 사례입니다.
macOS/Linux에서:
python3 -m venv venv
source venv/bin/activate
Windows에서:
python -m venv venv
.\\venv\\Scripts\\activate
이제 터미널 프롬프트에 (venv) 환경에 있다는 표시가 나타나야 합니다.
3단계: 종속성 설치
프로젝트에는 필요한 모든 파이썬 라이브러리를 나열한 requirements.txt 파일이 포함되어 있어야 합니다. pip를 사용하여 설치하세요:
pip install -r requirements.txt
이 명령은 openai, requests, 그리고 스크래핑을 위한 beautifulsoup4 또는 유사한 라이브러리, 사용된 특정 검색 API에 대한 라이브러리를 다운로드하고 설치할 것입니다.
4단계: API 키 구성
이것은 가장 중요한 구성 단계입니다. 사전 요구 사항에서 획득한 API 키를 제공해야 합니다. 오픈소스 프로젝트는 일반적으로 환경 변수나 .env 파일을 통해 키를 처리합니다. 정확한 환경 변수 이름은 open-deep-research README 파일을 신중히 참조하시기 바랍니다.
일반적으로 다음과 같은 변수를 설정해야 할 수 있습니다:
OPENAI_API_KEYSEARCHAPI_API_KEY(또는SERPER_API_KEY,GOOGLE_API_KEY등, 사용된 검색 서비스에 따라 다름)
환경 변수를 직접 터미널에 설정할 수 있습니다(이들은 현재 세션에 대해 임시적입니다):
macOS/Linux에서:
export OPENAI_API_KEY='your_openai_api_key_here'
export SEARCHAPI_API_KEY='your_search_api_key_here'
Windows(명령 프롬프트)에서:
set OPENAI_API_KEY=your_openai_api_key_here
set SEARCHAPI_API_KEY=your_search_api_key_here
Windows(PowerShell)에서:
$env:OPENAI_API_KEY="your_openai_api_key_here"$env:SEARCHAPI_API_KEY="your_search_api_key_here"
또는, 프로젝트는 .env 파일을 지원할 수 있습니다. 그렇다면, 프로젝트의 루트 디렉토리에 .env라는 파일을 생성하고 다음과 같이 키를 추가하세요:
OPENAI_API_KEY=your_openai_api_key_here
SEARCHAPI_API_KEY=your_search_api_key_here
이러한 변수는 python-dotenv와 같은 라이브러리가 스크립트 실행 시 자동으로 로드합니다(만약 requirements.txt에 나열되어 있으면). 다시 말하지만, 프로젝트 문서를 확인하여 올바른 방법과 변수 이름을 확인하십시오.
5단계: 연구 도구 실행
환경이 설정되고 종속성이 설치되며 API 키가 구성되면, 이제 메인 스크립트를 실행할 수 있습니다. 정확한 명령은 프로젝트의 구조에 따라 달라질 것입니다. 주요 파이썬 스크립트(예: main.py, research.py 등)를 찾으세요.
명령은 다음과 같을 수 있습니다( 정확한 명령과 인수는 README를 확인하세요!):
python main.py --query "재생 가능 에너지 채택이 전 세계 CO2 배출 추세에 미치는 영향"
아니면:
python research_agent.py "전기차를 위한 고체 전지 기술의 최신 발전"
그러면 스크립트는:
- 귀하의 쿼리를 받을 것입니다.
- 검색 API 키를 사용하여 관련 URL을 찾습니다.
- 해당 URL에서 콘텐츠를 스크래핑합니다.
- OpenAI API 키를 사용하여 콘텐츠를 처리하고 합성합니다.
- 출력을 생성합니다.
6단계: 출력 검토
도구가 실행되는데 다소 시간이 걸릴 수 있으며, 이는 쿼리의 복잡성, 분석된 출처의 수 및 API의 속도에 따라 달라집니다. 완료되면 출력을 확인하세요. 이는 다음 중 하나일 수 있습니다:
- 터미널 콘솔에 직접 출력됩니다.
- 프로젝트 디렉토리에 텍스트 파일 또는 마크다운 파일로 저장됩니다(예:
research_report.txt또는report.md).
생성된 보고서의 관련성, 일관성 및 정확성을 검토하세요.
커스터마이징 및 고려 사항
- LLM 선택: 기본적으로 OpenAI를 사용하지만, 프로젝트가 로컬에서 실행되는 오픈 소스 모델(Ollama 또는 LM Studio를 통해)과 같은 다른 LLM을 구성할 수 있는지 확인하세요. 그렇지 않으면 코드 변경이 필요할 수 있습니다.
- 검색 제공자: 필요시 검색 API 제공자를 바꿀 수 있을 것입니다.
- 프롬프트 엔지니어링: 합성 단계에서 LLM에게 지시하는 프롬프트를 수정하여 출력 스타일이나 초점에 맞출 수 있습니다.
- 비용: API 사용(특히 OpenAI의 강력한 모델과 잠재적으로 검색 API 사용)은 사용량에 따라 비용이 발생함을 잊지 마세요. 지출을 모니터링하십시오.
- 신뢰성: 이러한 오픈 소스 도구는 상용 제품보다 견고하지 않을 수 있습니다. 웹사이트가 변경되고, 스크래핑이 실패하며, LLM 출력이 다를 수 있습니다. 문제를 디버깅할 가능성을 예상하십시오.
- 복잡성: 이를 설정하는 것은 세련된 SaaS 제품인 클로드를 사용하는 것보다 더 많은 기술적 노력이 필요합니다.
결론
상업용 AI 도구인 클로드가 인상적인 통합 연구 기능을 제공하지만, btahir/open-deep-research와 같은 오픈소스 프로젝트는 유사한 기능을 독립적으로 구축하고 실행할 수 있음을 보여줍니다. 위의 단계를 따라 자동화된 연구 에이전트를 설정함으로써, 다양한 주제에 대한 깊이 있는 통찰을 제공하는 강력한 도구를 만들 수 있으며, 오픈 소스가 제공하는 투명성과 커스터마이징 가능성을 함께 가질 수 있습니다. 항상 특정 프로젝트 문서(README.md)를 참조하여 가장 정확하고 최신의 지침을 확인하십시오. 행복한 연구 되세요!
개발 팀이 함께 최대 생산성으로 작업할 수 있는 통합된 올인원 플랫폼이 필요하신가요?
Apidog는 귀하의 모든 요구를 충족시키며, 보다 저렴한 가격에 포스트맨을 대체합니다!