
Qwen 3 제품군은 2025년 오픈소스 LLM 시장을 주도할 것입니다. 엔지니어들은 미션 크리티컬 엔터프라이즈 에이전트부터 모바일 어시스턴트에 이르기까지 모든 곳에 이 모델을 배포합니다. Alibaba Cloud에 요청을 보내거나 자체 호스팅을 시작하기 전에 Apidog로 워크플로우를 간소화하세요.
Qwen 3 개요: 2025년 성능을 이끄는 아키텍처 혁신
Alibaba의 Qwen 팀은 2025년 4월 29일 Qwen 3 시리즈를 출시하여 오픈소스 대규모 언어 모델(LLM) 분야의 중추적인 발전을 알렸습니다. 개발자들은 자유로운 미세 조정 및 상업적 배포를 가능하게 하는 Apache 2.0 라이선스를 높이 평가합니다. Qwen 3는 핵심적으로 포지셔널 임베딩 및 어텐션 메커니즘을 강화한 트랜스포머 기반 아키텍처를 채택하여 최대 128K 토큰의 컨텍스트 길이를 기본적으로 지원하며, YaRN을 통해 131K까지 확장 가능합니다.

또한 이 시리즈는 일부 변형에 Mixture-of-Experts(MoE) 설계를 통합하여 추론 중에 매개변수의 일부만 활성화합니다. 이 접근 방식은 출력의 높은 충실도를 유지하면서 계산 오버헤드를 줄입니다. 예를 들어, 엔지니어들은 Qwen2.5-72B와 같은 밀집형 이전 모델에 비해 긴 컨텍스트 작업에서 최대 10배 빠른 처리량을 보고합니다. 결과적으로 Qwen 3 변형은 엣지 디바이스에서 클라우드 클러스터에 이르기까지 다양한 하드웨어에서 효율적으로 확장됩니다.
Qwen 3는 또한 119개 이상의 언어를 미묘한 지시 따르기 능력으로 처리하며 다국어 지원에서 탁월합니다. 벤치마크는 STEM 분야에서 그 우위를 확인시켜주는데, 36조 개 토큰에서 정제된 합성 수학 및 코드 데이터를 처리합니다. 따라서 글로벌 기업의 애플리케이션은 번역 오류 감소 및 교차 언어 추론 개선의 이점을 얻습니다. 구체적으로 하이브리드 추론 모드(토크나이저 플래그를 통해 전환)는 모델이 수학 또는 코딩을 위한 단계별 논리를 사용하거나, 대화의 경우 기본적으로 비사고 모드를 사용하도록 허용합니다. 이러한 이중성은 개발자가 사용 사례에 따라 최적화할 수 있도록 지원합니다.
Qwen 3 변형을 통합하는 주요 기능
모든 Qwen 3 모델은 2025년 유용성을 높이는 기본적인 특징을 공유합니다. 첫째, 이들은 이중 모드 작동을 지원합니다. 사고 모드는 AIME25와 같은 벤치마크를 위한 사고의 사슬(chain-of-thought) 프로세스를 활성화하고, 비사고 모드는 채팅 애플리케이션을 위한 속도를 우선시합니다. 엔지니어들은 간단한 매개변수로 이를 전환하여 지연 시간 희생 없이 복잡한 수학에서 최대 92.3%의 정확도를 달성합니다.
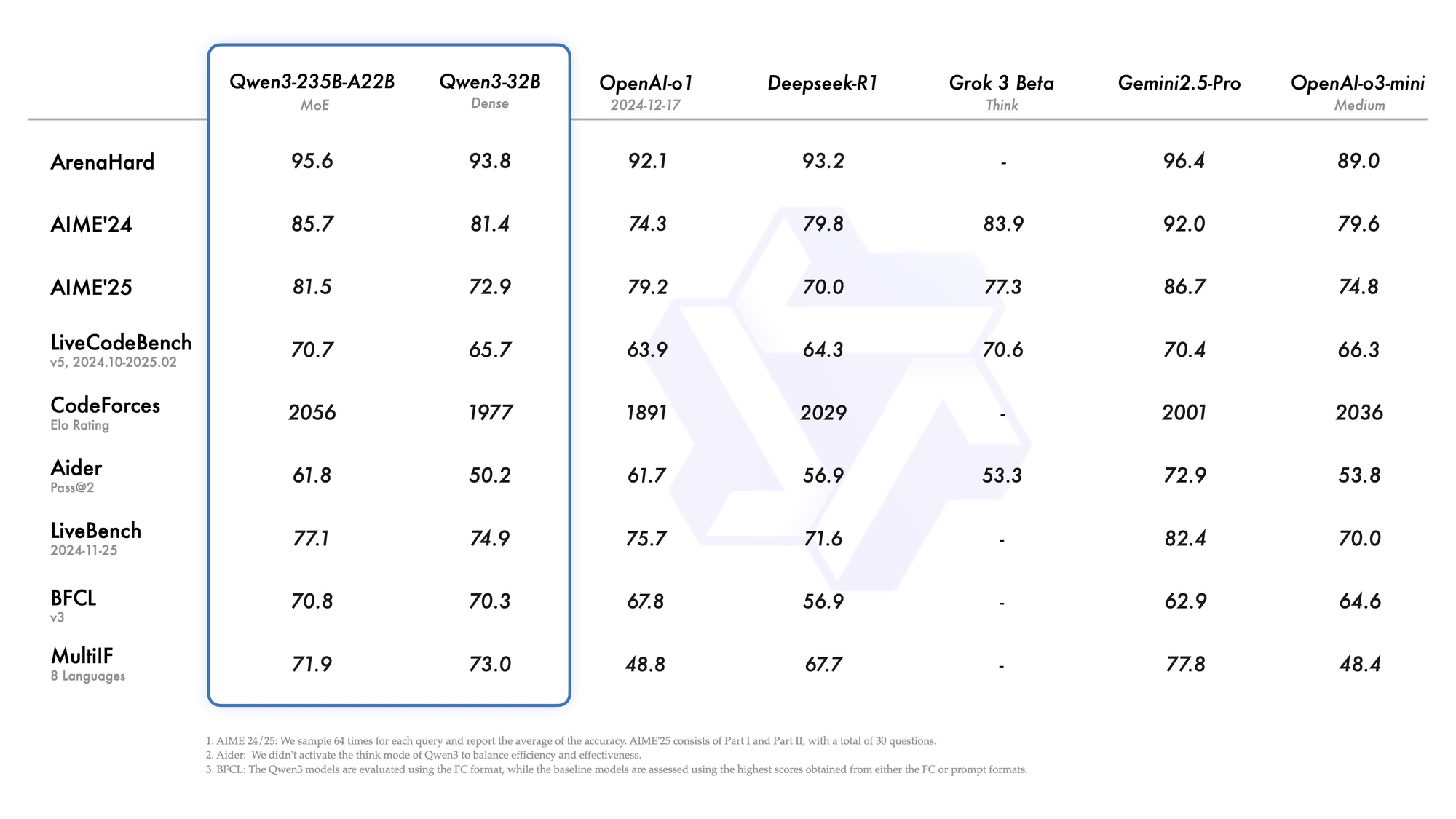
둘째, 에이전트 기능은 브라우저 탐색 또는 코드 실행과 같은 작업에서 오픈소스 경쟁자들을 능가하는 원활한 도구 호출을 가능하게 합니다. 예를 들어, Qwen 3 변형은 Tau2-Bench Verified에서 69.6점을 기록하여 독점 모델과 경쟁합니다. 또한 다국어 능력은 만다린어에서 스와힐리어에 이르는 방언을 포괄하며 MultiIF 벤치마크에서 73.0점을 기록합니다.
셋째, 효율성은 양자화된 변형(예: Q4_K_M)과 vLLM 또는 SGLang과 같은 프레임워크에서 비롯되며, 이는 소비자 GPU에서 초당 25토큰을 제공합니다. 그러나 더 큰 모델은 16GB 이상의 VRAM을 요구하여 클라우드 배포를 유도합니다. 가격은 경쟁력 있게 유지되며, Alibaba Cloud를 통해 백만 개당 $0.20–$1.20의 입력 토큰을 제공합니다.
또한 Qwen 3는 내장된 중재를 통해 안전을 강조하며 Qwen2.5에 비해 환각을 15% 줄입니다. 개발자들은 이를 전자상거래 추천기부터 법률 분석기에 이르는 프로덕션급 앱에 활용합니다. 개별 변형으로 전환하면서 이러한 공유된 강점은 비교를 위한 일관된 기준선을 제공합니다.
2025년 최고의 Qwen 3 모델 변형 Top 5
LMSYS Arena, LiveCodeBench 및 SWE-Bench의 2025년 벤치마크를 기반으로 상위 5개 Qwen 3 변형을 순위별로 정렬했습니다. 선택 기준에는 추론 점수, 추론 속도, 매개변수 효율성 및 API 접근성이 포함됩니다. 각 변형은 고유한 시나리오에서 탁월하지만, 모두 오픈소스의 한계를 확장합니다.
1. Qwen3-235B-A22B – 절대적인 플래그십 MoE 괴물
Qwen3-235B-A22B는 총 2350억 개의 매개변수와 토큰당 220억 개의 활성 매개변수를 가진 최고의 MoE 변형으로 주목을 받습니다. 2025년 7월 Qwen3-235B-A22B-Instruct-2507로 출시되었으며, top-k 라우팅을 통해 8개의 전문가를 활성화하여 밀집형 동급 모델에 비해 컴퓨팅을 90% 절감합니다. 벤치마크는 ArenaHard에서 95.6, LiveBench에서 77.1, CodeForces Elo에서 선두(5% 앞섬)를 차지하며 Gemini 2.5 Pro와 어깨를 나란히 합니다.
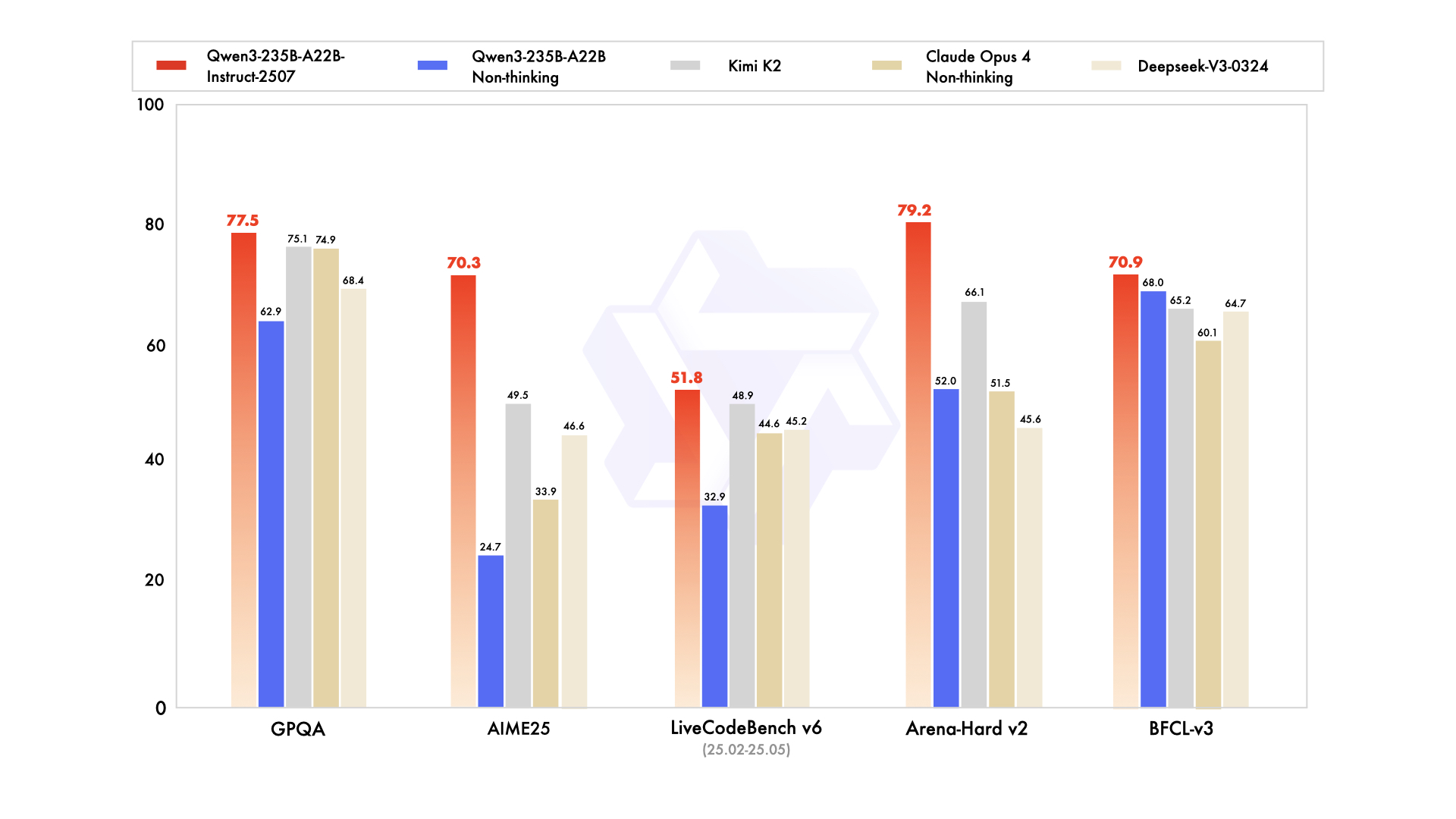
코딩 분야에서는 LiveCodeBench v6에서 74.8점을 달성하여 최소한의 반복으로 기능적인 TypeScript를 생성합니다. 수학의 경우 사고 모드가 AIME25에서 92.3점을 기록하며 명시적인 추론을 통해 다단계 적분을 해결합니다. 다국어 작업에서는 MultiIF에서 73.0점을 기록하며 아랍어 쿼리를 완벽하게 처리합니다.
배포는 클라우드 API를 선호하며, 여기에서 256K 컨텍스트를 처리합니다. 그러나 로컬 실행에는 8x H100 GPU가 필요합니다. 엔지니어들은 이를 리포지토리 규모의 디버깅과 같은 에이전트 워크플로우에 통합합니다. 전반적으로 이 변형은 깊이에 대한 2025년 표준을 설정하지만, 그 규모는 고예산 팀에 적합합니다.
강점
- 거의 모든 2025년 리더보드에서 Gemini 2.5 Pro 및 Claude 3.7 Sonnet과 동등하거나 능가함 (ArenaHard 95.6, AIME25 사고 모드 92.3, LiveCodeBench v6 74.8).
- 다단계 에이전트 워크플로우, 복잡한 도구 호출, 리포지토리 수준 코드 이해에서 탁월합니다.
- 품질 저하 없이 YaRN을 통해 256K–1M 컨텍스트를 처리합니다.
- 사고 모드는 비공개 소스 선도 모델에 필적하는 검증 가능한 사고의 사슬 추론을 제공합니다.
약점
- 로컬에서 매우 비싸고 느림 — 합리적인 지연 시간을 위해 8×H100 또는 동급 필요.
- API 가격이 제품군 중 가장 높음 (최대 컨텍스트에서 출력 토큰 백만 개당 $1.20–$6.00).
- 프로덕션 워크로드의 95%에는 과도함; 대부분의 팀은 그 용량을 채우지 못합니다.
언제 사용해야 하는가
- 박사급 수학을 해결하고, 전체 코드베이스를 디버깅하거나, 거의 환각 없이 법률 계약 분석을 수행해야 하는 엔터프라이즈급 자율 에이전트.
- 새로운 벤치마크에서 최첨단 기술을 개발하는 고예산 연구실.
- 토큰당 비용보다 최대 지능이 우선시되는 내부 추론 백엔드.
2. Qwen3-30B-A3B – 적정점 MoE 챔피언
Qwen3-30B-A3B는 총 305억 개의 매개변수와 33억 개의 활성 매개변수를 특징으로 하는 리소스 제약 환경을 위한 최적의 모델로 부상했습니다. 이 모델의 MoE 구조(48개 레이어, 128개 전문가(8개 라우팅))는 플래그십 모델과 유사하지만, 10%의 공간만 차지합니다. 2025년 7월에 업데이트된 이 모델은 활성 효율성에서 QwQ-32B를 10배 능가하며, ArenaHard에서 91.0점, SWE-Bench Verified에서 69.6점을 기록했습니다.
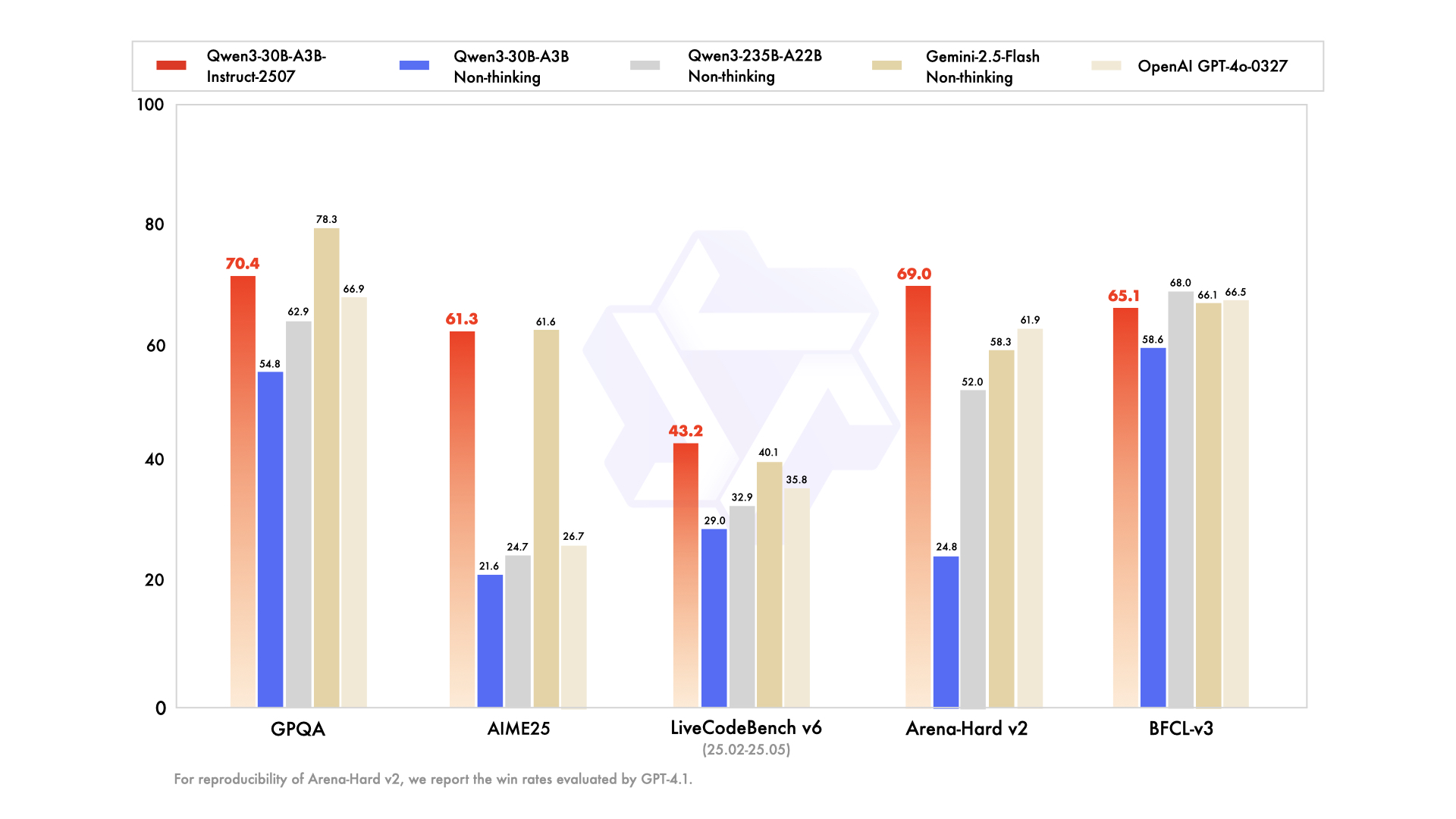
코딩 평가는 그 능력을 잘 보여줍니다. 신규 GitHub PR에서 32.4%의 pass@5를 기록하며 GPT-5-High와 맞먹습니다. 수학 벤치마크에서는 사고 모드에서 AIME25에서 81.6점을 기록하며 더 큰 형제 모델과 경쟁합니다. YaRN을 통한 131K 컨텍스트를 사용하여 긴 문서를 자르지 않고 처리합니다.
강점
- 235B 모델에 비해 10배 저렴한 활성 매개변수로 플래그십 추론 품질의 약 90-95%를 유지함 (ArenaHard 91.0, AIME25 81.6).
- 단일 80GB A100 또는 두 개의 40GB 카드에서 vLLM + FlashAttention과 함께 편안하게 실행 가능.
- 모든 2025년 오픈 MoE 모델 중 최고의 가격 대비 성능.
- 코딩 및 수학에서 모든 밀집형 72B–110B 모델을 능가함.
약점
- FP8/INT4에서 여전히 약 24–30GB VRAM이 필요; 노트북 친화적이지 않음.
- 비슷한 크기의 순수 밀집형 모델보다 창의적 글쓰기 유창성이 약간 낮음.
- 사고 모드 지연 시간이 비사고 모드에 비해 2–3배 증가.
언제 사용해야 하는가
- 프로덕션 코딩 에이전트, 자동화된 PR 검토 또는 내부 DevOps 코파일럿.
- 합리적인 예산으로 최전선 수준의 수학 또는 과학 추론이 필요한 고처리량 연구 파이프라인.
- 이전에 Llama-405B 또는 Mixtral-123B를 사용했지만 더 낮은 비용으로 더 나은 추론을 원하는 모든 팀.
3. Qwen3-32B – 밀집형 만능 왕
밀집형 Qwen3-32B는 320억 개의 완전히 활성화된 매개변수를 제공하며, 희소성보다는 순수한 처리량을 강조합니다. 36조 개의 토큰으로 훈련되었으며, 기본 성능에서 Qwen2.5-72B와 일치하지만, 훈련 후 정렬에서 탁월합니다. 벤치마크는 ArenaHard에서 89.5점, MultiIF에서 73.0점을 기록하며, 강력한 창의적 글쓰기 능력(예: 인간 선호도 85%를 기록하는 역할극 서술)을 보여줍니다.
코딩 분야에서는 BFCL에서 68.2점을 기록하며 프롬프트에서 드래그 앤 드롭 UI를 생성합니다. 수학에서는 AIME25에서 70.3점을 기록하지만, 사고의 사슬(chain-of-thought)에서는 MoE 모델에 뒤처집니다. 128K 컨텍스트는 지식 베이스에 적합하며, 비사고 모드는 대화 속도를 초당 20토큰으로 높입니다.
강점
- 뛰어난 지시 따르기 능력과 창의적인 출력 — 글쓰기 및 역할극에 대한 블라인드 인간 평가에서 종종 더 큰 MoE 모델보다 선호됨.
- 소비자 하드웨어(16–24GB VRAM)에서 LoRA/QLoRA로 쉽게 미세 조정 가능.
- 많은 작업에서 여전히 GPT-4o를 능가하는 모델 중 가장 빠른 추론 속도 (ArenaHard 89.5).
- 119개 이상의 언어에서 매우 강력한 다국어 성능.
약점
- 사고 모드가 활성화될 때 가장 어려운 수학 및 코딩 벤치마크에서 MoE 형제 모델보다 약 8–12점 뒤떨어짐.
- 매개변수 효율성 트릭 없음 — 모든 토큰은 전체 32B 컴퓨팅 비용이 발생.
언제 사용해야 하는가
- 콘텐츠 생성 플랫폼, 소설 쓰기 보조 도구, 마케팅 문구 도구.
- 대규모 미세 조정이 필요한 프로젝트 (도메인별 챗봇, 스타일 변환).
- 거의 플래그십 수준의 품질을 원하지만 24GB VRAM 미만을 유지해야 하는 팀.
4. Qwen3-14B – 엣지 & 모바일 강자
Qwen3-14B는 148억 개의 매개변수로 휴대성을 우선시하며, 중간급 하드웨어에서 128K 컨텍스트를 지원합니다. 효율성에서 Qwen2.5-32B와 경쟁하며, ArenaHard에서 85.5점을 기록하고 수학/코딩 분야에서는 Qwen3-30B-A3B와 대등합니다(5% 이내). Q4_0으로 양자화되어 RedMagic 8S Pro와 같은 모바일에서 초당 24.5토큰으로 실행됩니다.
에이전트 작업에서는 Tau2-Bench에서 65.1점을 기록하여 저지연 앱에서 도구 사용을 가능하게 합니다. 다국어 지원은 방언 추론에서 70%의 정확도를 보여줍니다. 엣지 디바이스의 경우 32K 컨텍스트를 오프라인으로 처리하여 IoT 분석에 이상적입니다.
엔지니어들은 개인 정보 보호가 규모보다 중요한 연합 학습을 위한 이 모델의 공간 효율성을 높이 평가합니다. 따라서 모바일 AI 비서 또는 임베디드 시스템에 적합합니다.
강점
- Q4_K_M으로 양자화 시 최신 휴대폰(Snapdragon 8 Gen 4, Dimensity 9400)에서 초당 24–30토큰으로 실행.
- 대부분의 추론 벤치마크에서 여전히 Qwen2.5-32B 및 Llama-3.1-70B를 능가.
- 32K–128K 컨텍스트를 갖춘 온디바이스 RAG에 탁월.
- 최고 수준의 성능 범주에서 가장 저렴한 API 비용.
약점
- 5개 이상의 도구 호출이 필요한 다단계 에이전트 작업에서 어려움을 겪기 시작함.
- 창의적 글쓰기 품질이 32B+ 모델보다 현저히 낮음.
- 벤치마크가 계속 상승함에 따라 미래 경쟁력이 떨어질 수 있음.
언제 사용해야 하는가
- 온디바이스 어시스턴트 (Android/iOS 앱, 웨어러블).
- 데이터가 장치를 떠날 수 없는 개인 정보 보호에 민감한 배포 (의료, 금융).
- 실시간 임베디드 시스템 (로봇, 자동차, IoT 게이트웨이).
5. Qwen3-8B – 궁극의 프로토타이핑 및 경량 워크호스
상위 5개 모델 중 마지막인 Qwen3-8B는 빠른 반복을 위해 80억 개의 매개변수를 제공하며, 15개 벤치마크에서 Qwen2.5-14B를 능가합니다. AIME25(비사고 모드)에서 81.5점, LiveCodeBench에서 60.2점을 달성하여 기본적인 코드 검토에 충분합니다. 32K 기본 컨텍스트로 Ollama를 통해 노트북에 배포하여 초당 25토큰에 도달합니다.
이 변형은 다국어 채팅 또는 간단한 에이전트를 테스트하는 초보자에게 적합합니다. 사고 모드는 논리 퍼즐을 향상시켜 추론 작업에서 75%를 기록합니다. 결과적으로 더 큰 형제 모델로 확장하기 전에 개념 증명을 가속화합니다.
강점
- 8–12GB VRAM을 가진 노트북(MacBook M3 Pro, RTX 4070 모바일)에서도 초당 25토큰 이상으로 실행.
- 놀랍도록 유능한 지시 따르기 능력 — 대부분의 2025년 리더보드에서 Gemma-2-27B 및 Phi-4-14B를 능가.
- 로컬 Ollama 또는 LM Studio 실험에 완벽함.
- 제품군에서 가장 저렴한 API 가격.
약점
- 대학원 수준의 수학 및 고급 코딩 문제에서 명확한 추론 한계가 있음.
- 지식 집약적 작업에서 환각에 더 취약.
- 제한된 컨텍스트 (32K 기본, YaRN 사용 시 128K이지만 더 느림).
언제 사용해야 하는가
- 빠른 프로토타이핑 및 MVP 구축.
- 교육 도구, 개인 비서 또는 취미 프로젝트.
- 하이브리드 시스템의 프런트엔드 라우팅 레이어 (8B를 사용하여 분류하고 필요할 때 30B/235B로 에스컬레이션).
Qwen 3 모델의 API 가격 및 배포 고려 사항
API를 통한 Qwen 3 접근은 고급 AI를 민주화하며, Alibaba Cloud는 경쟁력 있는 요금으로 이를 선도합니다. 토큰별 가격 책정: Qwen3-235B-A22B의 경우 입력 비용은 백만 개당 $0.20–$1.20 (0–252K 범위), 출력은 백만 개당 $1.00–$6.00입니다. Qwen3-30B-A3B는 이와 유사하게 80%의 요율이며, Qwen3-32B와 같은 밀집형 모델은 입력 $0.15/출력 $0.75로 떨어집니다.
Together AI와 같은 타사 제공업체는 Qwen3-32B를 총 백만 토큰당 $0.80에 제공하며, 볼륨 할인이 적용됩니다. 캐시 히트는 청구서를 줄여줍니다. 암시적으로 20%, 명시적으로 10%입니다. GPT-5($3–15/백만)와 비교하여 Qwen 3는 70% 저렴하여 비용 효율적인 확장을 가능하게 합니다.
배포 팁: vLLM을 사용하여 배칭하고, SGLang을 사용하여 OpenAI 호환성을 확보하세요. Apidog는 Qwen 엔드포인트를 모의하고, 페이로드를 테스트하며, 문서를 생성함으로써 CI/CD 파이프라인에 필수적인 기능을 제공하여 이를 향상시킵니다. Ollama를 통한 로컬 실행은 프로토타이핑에 적합하지만, API는 프로덕션에 탁월합니다.
속도 제한 및 중재와 같은 보안 기능은 추가 비용 없이 가치를 더합니다. 따라서 예산에 민감한 팀은 토큰 볼륨을 기반으로 선택합니다. 개발에는 작은 변형을, 추론에는 플래그십을 사용합니다.
결정 테이블 – 2025년에 당신의 Qwen 3 모델을 선택하세요
| 순위 | 모델 | 매개변수 (총/활성) | 강점 요약 | 주요 약점 | 최적 용도 | 대략적인 API 비용 (입력/출력 백만 토큰당) | 최소 VRAM (양자화) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | 최대 추론, 에이전트, 수학, 코드 | 매우 비싸고 무거움 | 최전선 연구, 엔터프라이즈 에이전트, 무오차 정확도 | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (클라우드) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | 최고의 가격 대비 성능, 강력한 추론 | 여전히 서버 GPU 필요 | 프로덕션 코딩 에이전트, 수학/과학 백엔드, 대용량 추론 | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B 밀집형 | 창의적 글쓰기, 쉬운 미세 조정, 속도 | 가장 어려운 작업에서 MoE에 뒤처짐 | 콘텐츠 플랫폼, 도메인 미세 조정, 다국어 챗봇 | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B 밀집형 | 엣지/모바일 가능, 우수한 온디바이스 RAG | 제한적인 다단계 에이전트 능력 | 온디바이스 AI, 개인 정보 보호 중요 앱, 임베디드 시스템 | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B 밀집형 | 노트북/폰 속도, 가장 저렴 | 복잡한 작업에서 명확한 한계 | 프로토타이핑, 개인 비서, 하이브리드 시스템의 라우팅 레이어 | $0.10 / $0.50 | 4–8GB |
2025년을 위한 최종 권장 사항
2025년 대부분의 팀은 Qwen3-30B-A3B를 기본으로 선택해야 합니다. 이 모델은 플래그십 성능의 90% 이상을 훨씬 적은 비용과 하드웨어 요구 사항으로 제공합니다. 추론 품질의 마지막 5-10%가 정말로 필요하고 예산이 충분한 경우에만 235B-A22B로 전환하세요. 창의적이거나 미세 조정 작업이 많은 워크로드에는 32B 밀집형으로, 지연 시간, 개인 정보 보호 또는 장치 제약이 지배적인 경우에는 14B/8B를 사용하세요.
어떤 변형을 선택하든 Apidog는 API 디버깅 시간을 절약해 줄 것입니다. 오늘 무료로 다운로드하여 Qwen 3로 자신 있게 개발을 시작하세요.