
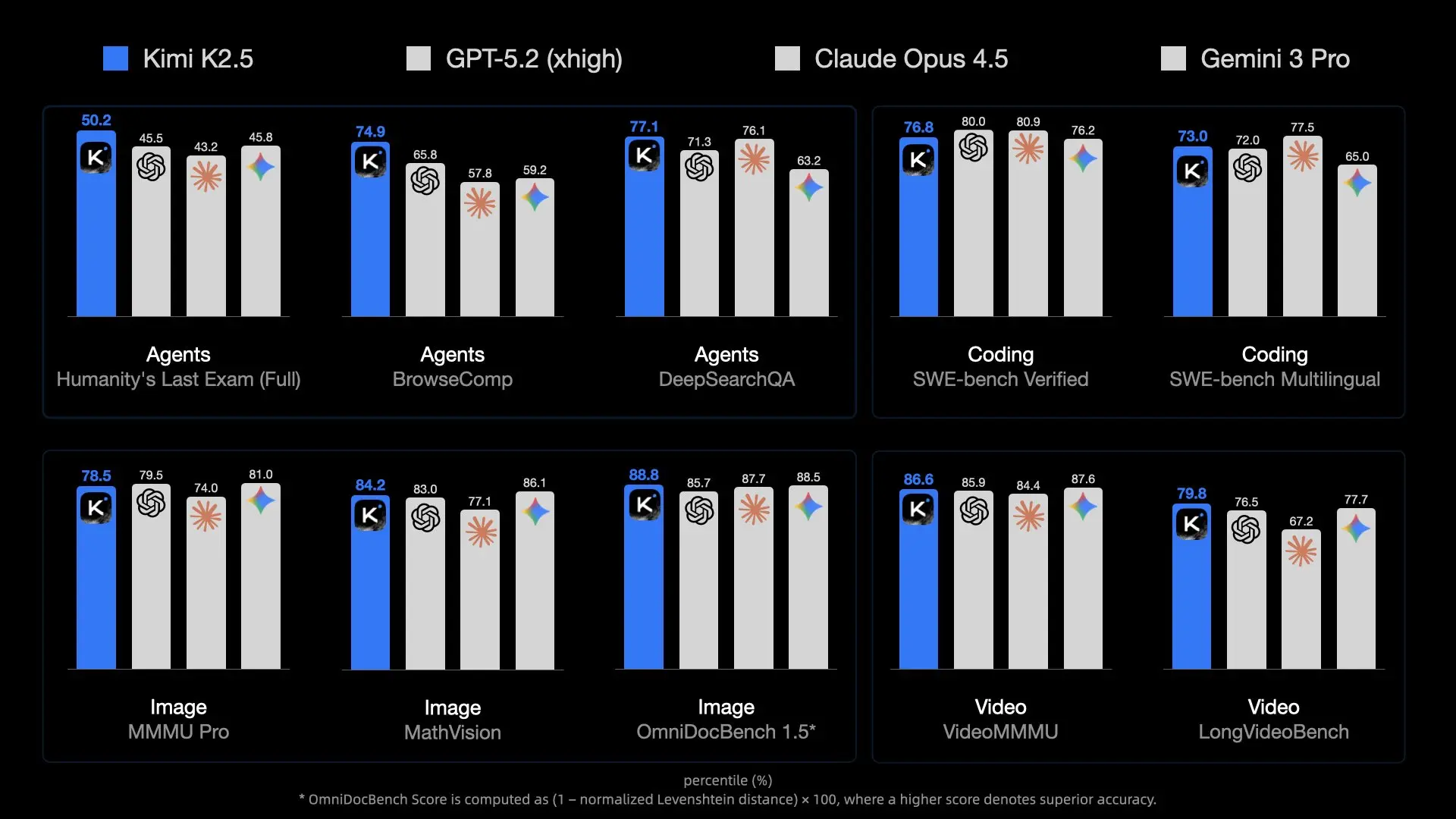
Moonshot AIによるKimi K2.5のリリースは、オープンソースモデルの新たな基準を打ち立てました。1兆のパラメータとMixture-of-Experts (MoE)アーキテクチャを備え、GPT-4oのようなプロプライエタリな巨大モデルと肩を並べます。しかし、その途方もないサイズは、実行する上で大きな課題となります。
開発者や研究者にとって、K2.5をローカルで実行することは、比類のないプライバシー、ゼロレイテンシー(ネットワークに関して)、そしてAPIトークンのコスト削減をもたらします。しかし、7Bや70Bのような小規模モデルとは異なり、これを標準的なゲーミングノートPCに簡単にロードすることはできません。
このガイドでは、Unslothの画期的な量子化技術を活用して、この巨大なモデルをllama.cppを使用して(ある程度)アクセス可能なハードウェアに適合させる方法と、Apidogを使用して開発ワークフローに統合する方法を探ります。
Kimi K2.5の実行が難しい理由 (MoEの課題)
Kimi K2.5は単に「大きい」だけでなく、アーキテクチャ的にも複雑です。Mixtral 8x7Bのような一般的なオープンモデルよりもはるかに多くのエキスパートを持つMixture-of-Experts (MoE)アーキテクチャを採用しています。
スケールの問題
- 総パラメータ数: 約1兆。標準的なFP16精度では、約2テラバイトのVRAMが必要になります。
- アクティブパラメータ: 推論ではトークンごとにパラメータの一部しか使用されませんが (MoEのおかげです)、トークンを正しくルーティングするためには、モデル全体をメモリに保持しておく必要があります。
- メモリ帯域幅: 本当のボトルネックは容量だけでなく、速度です。単一のトークン生成ごとに240GBのデータをメモリチャネルを通じて移動させることは、消費者向けハードウェアにとって大きな負担となります。
だからこそ、量子化(ウェイトあたりのビット数を減らすこと)は譲れない要素です。Unslothの極端な1.58ビット圧縮がなければ、これを実行できるのはスーパーコンピューティングクラスターの領域に限定されるでしょう。
ハードウェア要件: 実行できますか?
「1.58ビット」量子化は、知能を損なうことなくモデルサイズを約60%圧縮し、これを可能にする魔法です。
最小仕様 (1.58ビット量子化)
- ディスク容量: 240GB以上 (NVMe SSDを強く推奨)
- RAM + VRAM: 合計240GB以上
- 例1: 2x RTX 3090 (48GB VRAM) + 256GB システムRAM (実行可能、遅い)
- 例2: Mac Studio M2 Ultra (192GB RAM) (不十分、クラッシュまたはスワップが多発する可能性が高い)
- 例3: 512GB RAMを搭載したサーバー (CPUで良好に動作)
- 計算能力: AVX2対応CPUまたはNVIDIA GPU
推奨仕様 (パフォーマンス)
実用的な速度(10トークン/秒以上)を得るには:
- VRAM: 可能な限り多く。GPUへのレイヤーオフロードは速度を大幅に向上させます。
- システム: 4x H100/H200 GPU (エンタープライズ向け) または 512GB DDR5 RAM搭載ワークステーション (消費者/プロシューマー向け)。
注
解決策: Unsloth Dynamic GGUF
Unslothは、Kimi K2.5のダイナミックGGUFバージョンをリリースしました。これらのファイルにより、モデルをllama.cppにロードでき、CPU(RAM)とGPU(VRAM)間でインテリジェントにワークロードを分割することが可能になります。
ダイナミック量子化とは?
標準的な量子化は、すべてのレイヤーに同じ圧縮を適用します。Unslothの「ダイナミック」アプローチはより賢明です。
- 重要なレイヤー (アテンション/ルーティング): 知能を維持するために、より高い精度(例: 4ビットまたは6ビット)で保持されます。
- フィードフォワードレイヤー: スペースを節約するために、1.58ビットまたは2ビットに積極的に圧縮されます。
このハイブリッドアプローチにより、1兆パラメータのモデルを約240GBで実行しながら、フル精度で動作する70Bの小規模モデルを凌駕する推論能力を維持できます。
- 1.58ビット (UD-TQ1_0): 約240GB。実行可能な最小バージョンです。
- 2ビット (UD-Q2_K_XL): 約375GB。より優れた推論能力を持ちますが、かなりの量のRAMが必要です。
- 4ビット (UD-Q4_K_XL): 約630GB。ほぼフル精度のパフォーマンスですが、エンタープライズハードウェアのみに対応しています。
ステップバイステップインストールガイド
CPU/GPUのワークロード分割において最も効率的な推論エンジンを提供するため、llama.cppを使用します。
ステップ1: llama.cppのインストール
最新のKimi K2.5サポートを確実にするため、llama.cppをソースからビルドする必要があります。
Mac/Linux:
# 依存関係をインストール
sudo apt-get update && sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
# リポジトリをクローン
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# CUDAサポート付きでビルド (NVIDIA GPUがある場合)
cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# または CPU/Mac Metal向けにビルド (デフォルト)
# cmake -B build
# コンパイル
cmake --build build --config Release -j --clean-first --target llama-cli llama-server
ステップ2: モデルのダウンロード
Unsloth GGUFバージョンをダウンロードします。ほとんどの「ホームラボ」セットアップには1.58ビットバージョンが推奨されます。
huggingface-cliまたはllama-cliを直接使用できます。
オプションA: llama-cliによる直接ダウンロード
# モデル用のディレクトリを作成
mkdir -p models/kimi-k2.5
# ダウンロードして実行 (これによりモデルがキャッシュされます)
./build/bin/llama-cli \
-hf unsloth/Kimi-K2.5-GGUF:UD-TQ1_0 \
--model-url unsloth/Kimi-K2.5-GGUF \
--print-token-count 0
オプションB: 手動ダウンロード (管理に最適)
pip install huggingface_hub
# 特定の量子化バージョンをダウンロード
huggingface-cli download unsloth/Kimi-K2.5-GGUF \
--include "*UD-TQ1_0*" \
--local-dir models/kimi-k2.5
ステップ3: 推論の実行
さあ、モデルを起動しましょう。最適なパフォーマンスを得るために、Moonshot AIが推奨する特定のサンプリングパラメータ(temp 1.0, min-p 0.01)を設定する必要があります。
./build/bin/llama-cli \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--temp 1.0 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--threads 16 \
--prompt "User: Write a Python script to scrape a website.\nAssistant:"
主要パラメータ:
--fit on: 利用可能なVRAMに合わせるため、レイヤーを自動的にGPUにオフロードします(ハイブリッドセットアップに不可欠)。--ctx-size: K2.5は最大256kをサポートしますが、メモリ節約のためには16kの方が安全です。
ローカルAPIサーバーとして実行する
Kimi K2.5をアプリやApidogと統合するには、OpenAI互換のサーバーとして実行します。
./build/bin/llama-server \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--port 8001 \
--alias "kimi-k2.5-local" \
--temp 1.0 \
--min-p 0.01 \
--ctx-size 16384 \
--host 0.0.0.0
ローカルAPIがhttp://127.0.0.1:8001/v1でアクティブになりました。
ApidogをローカルのKimi K2.5に接続する
Apidogは、ローカルLLMをテストするのに最適なツールです。視覚的にリクエストを構築し、会話履歴を管理し、cURLスクリプトを書くことなくトークンの使用状況をデバッグできます。
1. 新しいリクエストを作成する
Apidogを開き、新しいHTTPプロジェクトを作成します。以下のエンドポイントにPOSTリクエストを作成します。http://127.0.0.1:8001/v1/chat/completions
2. ヘッダーを設定する
以下のヘッダーを追加します。
Content-Type:application/jsonAuthorization:Bearer not-needed(ローカルサーバーは通常このキーを無視しますが、良い習慣です)
3. ボディを設定する
OpenAI互換の形式を使用します。
{
"model": "kimi-k2.5-local",
"messages": [
{
"role": "system",
"content": "あなたはローカルで動作するKimiです。"
},
{
"role": "user",
"content": "量子コンピュータについて一文で説明してください。"
}
],
"temperature": 1.0,
"max_tokens": 1024
}
4. 送信して確認する
送信をクリックします。レスポンスがストリームで表示されるはずです。
なぜApidogを使うのか?
- レイテンシートラッキング: ローカルモデルが応答するまでにかかる時間(最初のトークンまでの時間)を正確に確認できます。
- 履歴管理: Apidogはチャットセッションを保持するため、ローカルモデルのマルチターン会話能力を簡単にテストできます。
- コード生成: プロンプトが動作したら、Apidogの「コード生成」をクリックして、このローカルサーバーをアプリで使用するためのPython/JSスニペットを取得できます。
詳細なトラブルシューティングとパフォーマンスチューニング
1兆パラメータのモデルを実行することは、消費者向けハードウェアを限界まで追い込みます。これを安定させるための高度なヒントを以下に示します。
「モデルのロードに失敗しました: メモリ不足」
これは最も一般的なエラーです。
- コンテキストを減らす:
--ctx-sizeを4096または8192に下げます。 - アプリを閉じる: Chrome、VS Code、Dockerをシャットダウンします。RAMのすべてのバイトが必要です。
- ディスクオフロードを使用する (最終手段):
llama.cppはモデルの一部をディスクにマッピングできますが、推論速度は1トークン/秒未満に低下します。
「ゴミのような出力」または反復的なテキスト
Kimi K2.5はサンプリングに敏感です。以下を使用していることを確認してください。
Temperature: 1.0 (驚くほど高いですが、このモデルには推奨されています)Min-P: 0.01 (低確率トークンを排除するのに役立ちます)Top-P: 0.95
生成速度が遅い
0.5トークン/秒の速度しか得られない場合、システムRAMの帯域幅またはCPU速度がボトルネックになっている可能性が高いです。
- 最適化:
--threadsが物理CPUコア数(論理スレッドではない)と一致していることを確認してください。 - GPUオフロード: 小さなGPUに10レイヤーをオフロードするだけでも、プロンプト処理時間を大幅に改善できます。
- NUMAサポート: デュアルソケットサーバーを使用している場合、メモリアクセスを最適化するために
llama.cppのビルドフラグでNUMAアウェアネスを有効にしてください。
クラッシュの対処法
モデルがロードされるものの、生成中にクラッシュする場合:
- スワップの確認: 大容量のスワップファイル(100GB以上)が有効になっていることを確認してください。256GBのRAMがあったとしても、一時的なスパイクでプロセスが終了する可能性があります。
- KVキャッシュオフロードを無効にする: VRAMが不足している場合は、KVキャッシュをCPUに保持してください(
--no-kv-offload)。
構築の準備はできましたか?
Kimi K2.5をローカルで実行できるかどうかに関わらず、あるいはAPIを使用することにした場合でも、ApidogはAI統合のテスト、ドキュメント化、監視のための統合プラットフォームを提供します。Apidogを無料でダウンロードして、今すぐ実験を始めましょう。