開発者は、インテリジェントなアプリケーションを構築するために、効率的で高性能な言語モデルを常に求めています。MiniMax M2.1 APIは、特にエージェントワークフローや複雑なコーディングタスクにおいて、堅牢な選択肢として際立っています。
まず、モデル自体を理解することから始めます。次に、アクセス方法を探ります。最後に、実用的な統合を実装します。
MiniMax M2.1とは何か、そしてそのAPIを使用する理由
MiniMax M2.1は、MiniMax AIからの最新の進歩を表しており、エージェント機能に最適化されたオープンソースモデルとしてリリースされました。開発者はこれを利用して、多言語ソフトウェア開発、多段階の計画、ツール使用を非常に堅牢に処理する自律型アプリケーションを作成します。
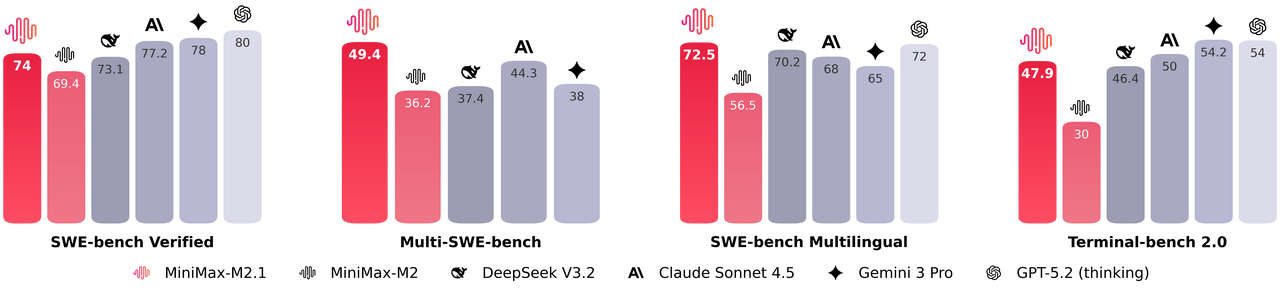
さらに、MiniMax M2.1は推論中にコンパクトなパラメータセットをアクティブ化し、低遅延を維持しながら最先端に近いパフォーマンスを提供します。SWE-bench VerifiedやVIBEなどのベンチマークで優れた成績を収め、コーディングの安定性と指示への追従性において、独自モデルに匹敵するか、しばしばそれを上回ります。さらに、このモデルは、インタラクティブな3Dアニメーション、ネイティブモバイルアプリ、リアルタイムデータダッシュボードの生成を含む高度なデモンストレーションをサポートしています。
透明性と制御性が必要な場合は、MiniMax M2.1を選択します。さらに、そのオープンソースの重みはHugging Faceを介したローカルデプロイメントを可能にしますが、ホスト型APIはインフラ管理なしで即座にアクセスを提供します。
MiniMax M2.1とGLM-4.7:どちらのモデルがあなたのニーズに合っていますか?
開発者は、MiniMax M2.1をGLM-4.7と比較することがよくあります。GLM-4.7は、Z.aiのもう一つの主要なオープンウェイトモデルです。両モデルともコーディングと推論を対象としていますが、アーキテクチャ、効率性、コストの点で異なります。
MiniMax M2.1は、選択的活性化を伴うMixture-of-Experts (MoE) デザインを採用しており、通常、より大きなプールから約100億のアクティブなパラメータを使用します。このアプローチにより、高速な推論と低い運用コストが保証されます。対照的に、GLM-4.7は3580億のパラメータを持つ完全なMoEを利用し、20万トークンという巨大なコンテキストウィンドウと、ターンレベル思考制御のようなネイティブ機能をサポートしています。
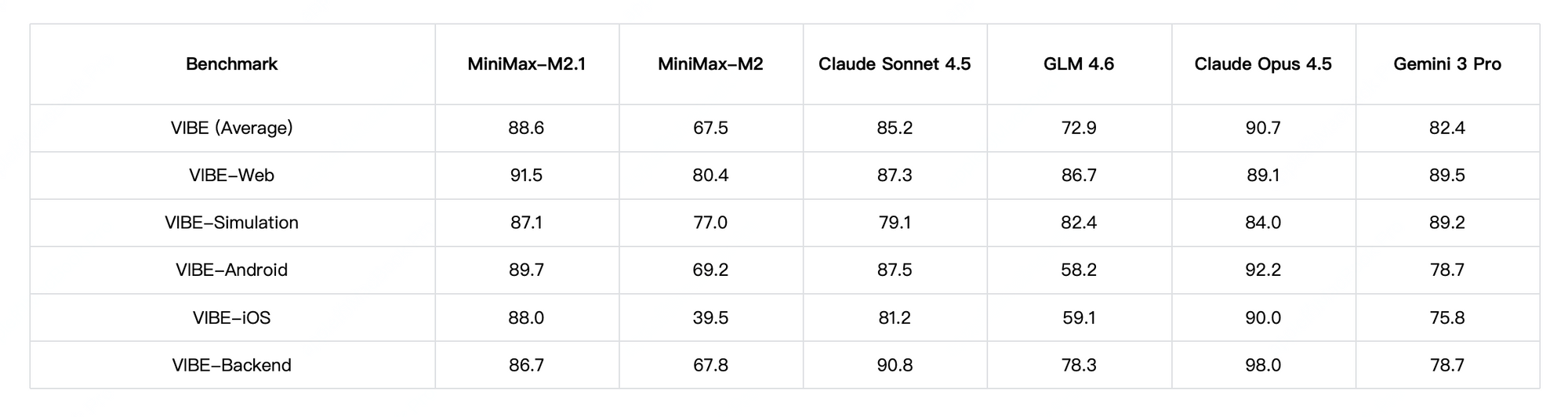
パフォーマンス面では、MiniMax M2.1はエージェントタスクと長期間の計画において優れており、VIBEで高いスコア(平均88.6)を達成し、ツール使用における優れた安定性を示しています。コミュニティテストでは、クリエイティブなコーディングとマルチツール自律性において、以前のGLMバージョンを上回ることが示されています。ただし、GLM-4.7は純粋な推論ベンチマークと構造化出力において優位に立っており、SWE-benchで強力な結果(73.8%)を記録しています。
価格設定は重要な役割を果たします。M2のような先行モデルを含むMiniMaxモデルは、公式プラットフォームで通常100万入力トークンあたり約0.30ドル~0.315ドル、100万出力トークンあたり1.20ドル~1.26ドルを課金します。Z.aiまたはOpenRouterなどのプロバイダーを介して利用可能なGLM-4.7は、100万トークンあたり約0.44ドル~0.60ドルの入力、1.74ドル~2.20ドルの出力から始まり、サブスクリプションで実効レートが下がる場合でも、しばしば高価になります。
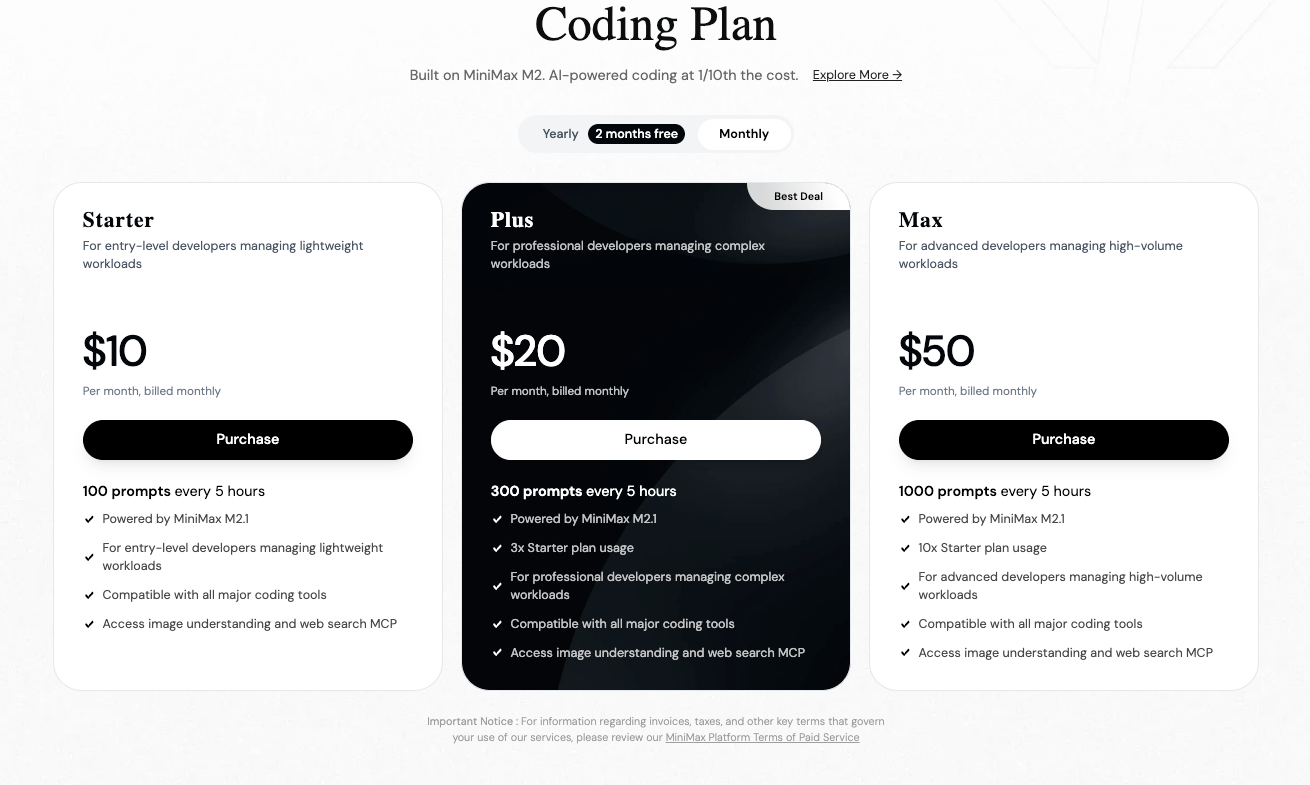
したがって、コスト効率が高く高速なエージェントアプリケーションにはMiniMax M2.1を選択します。一方、拡張されたコンテキストや正確な思考モードが不可欠である場合は、GLM-4.7を選択します。
MiniMax APIプラットフォームに登録するにはどうすればよいですか?
MiniMaxオープンプラットフォームでアカウントを作成することからアクセスを開始します。メールまたは希望する方法でサインアップしてください。
認証後、ログインしてダッシュボードに進みます。ここでは、APIキーと請求を管理します。このプラットフォームはグローバルと地域固有の両方のエンドポイントをサポートしているため、最適なレイテンシを得るためにあなたの場所に基づいて選択します。
さらに、早い段階でドキュメントセクションを確認してください。これらはモデルの利用可能性、レート制限、ベストプラクティスをカバーしています。このキーは安全に、おそらく環境変数またはシークレットマネージャーに保存してください。クライアントサイドのコードに公開してはいけません。
さらに、必要に応じて請求ページから残高をチャージしてください。MiniMaxは従量課金制モデルで運営されており、コストを正確に管理できます。
MiniMax M2.1 APIエンドポイントとリクエスト構造とは?
MiniMax APIは、OpenAIやAnthropicスタイルを含む一般的な形式との互換性を提供します。M2.1によるテキスト生成では、チャット完了エンドポイントをターゲットとします。
通常、ベースURLはhttps://api.minimax.ioまたは地域ごとのバリアントとして表示されます。リクエストペイロードには、「MiniMax-M2.1」などのモデル名を指定します。
標準的なPOSTリクエストには、認証とコンテンツタイプのヘッダーが含まれます。`Authorization: Bearer YOUR_API_KEY` と `Content-Type: application/json` を設定します。
ボディは、他のLLMと同様にメッセージ配列形式に従います。必要に応じて、システム、ユーザー、アシスタントの役割を含めます。
さらに、`temperature`、`max_tokens`、`top_p`、`tool choices` などのパラメータを調整して出力を微調整します。
MiniMax M2.1 APIに最初のリクエストを送信するにはどうすればよいですか?
確認のためにcurlを使用してAPIを迅速にテストします。
以下に基本的な例を示します。
curl https://api.minimax.io/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "MiniMax-M2.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to calculate Fibonacci numbers."}
],
"temperature": 0.7,
"max_tokens": 512
}'
このコマンドは、生成された完了を含むJSON応答を返します。アシスタントの返信については、`choices` 配列を調べます。
さらに、`"stream": true` を追加することで、リアルタイム出力のストリーミングを有効にできます。
Pythonを使用してMiniMax M2.1 APIと対話するにはどうすればよいですか?
Python開発者は、シンプルさのためにライブラリを好みます。MiniMaxは互換性を提供していますが、カスタムベースURLを使用して公式のOpenAI SDKを使用します。
まず、パッケージをインストールします。
pip install openai
次に、クライアントを設定します。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.minimax.io/v1" # Adjust if needed
)
response = client.chat.completions.create(
model="MiniMax-M2.1",
messages=[
{"role": "system", "content": "You are an expert developer."},
{"role": "user", "content": "Explain agentic workflows."}
],
temperature=0.8
)
print(response.choices[0].message.content)
このコードはリクエストを効率的に処理します。本番環境での使用のために、エラー処理とリトライを追加して拡張します。
MiniMax M2.1 API呼び出しのテストと管理にApidogを使用する理由
プロジェクトが大きくなるにつれて、APIを手動でテストするのは面倒になります。Apidogはこのプロセスを大幅に簡素化します。
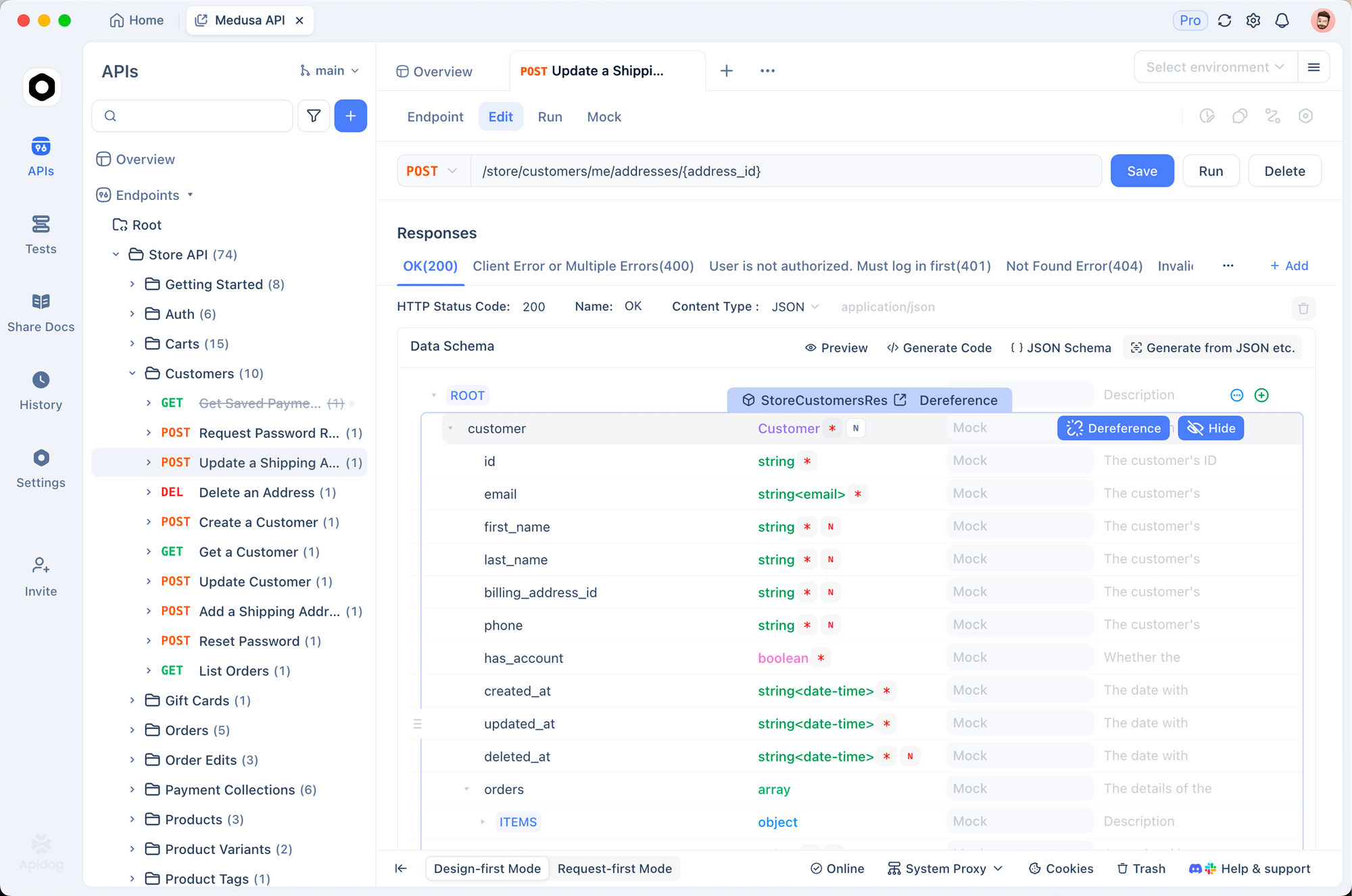
MiniMaxのドキュメントをインポートするか、Apidogで手動でコレクションを作成します。その後、APIキーの環境変数を設定します。
Apidogは、リクエストの送信、整形された応答の表示、エンドポイントのモックをサポートしています。さらに、複数の言語でクライアントコードを自動的に生成します。
例えば、トークンの使用量やストリーミング応答を視覚的にデバッグできます。これは、生のcurlコマンドと比較して何時間もの時間を節約します。
さらに、ApidogはCI/CDパイプラインと統合され、一貫したAPIの動作を保証します。
MiniMax M2.1でツール呼び出しと高度な機能をどのように処理しますか?
MiniMax M2.1は、エージェントアプリケーションにとって重要なネイティブなツール呼び出しをサポートしています。リクエストペイロードでツールを定義します。
モデルはいつツールを呼び出すかを決定し、構造化された呼び出しを返します。アプリケーションはツールを実行し、結果をアシスタントメッセージとして追加します。
このループにより、複数ステップの推論が可能になります。さらに、インターリーブ思考を活用して透明な推論トレースを実現します。
レート制限とエラー処理のベストプラクティスとは?
MiniMaxは、サービス品質を維持するためにレート制限を適用します。応答中の`x-ratelimit-remaining`のようなヘッダーを監視します。
429エラーでのリトライには指数バックオフを実装します。さらに、認証失敗(401)と無効なリクエスト(400)をキャッチします。
リクエストと応答のログ記録はデバッグに役立ちます。予期せぬ事態を避けるために、ダッシュボードを介して使用状況を追跡します。
まとめ:MiniMax M2.1で今日から開発を始めましょう
これで、MiniMax M2.1 APIに効果的にアクセスし、利用するための知識が身につきました。プラットフォームに登録し、キーを生成し、curl、Python、またはApidogを介してリクエストを送信してください。
このモデルは、競争力のあるコストで洗練されたエージェントやコーディングツールを構築する力を与えます。自由に実験し、GLM-4.7のような代替案と比較し、プロジェクトをスケールアップしてください。
Apidogは、強力なテストツールを提供することで、ワークフローをさらに強化します。無料でダウンロードして、開発を加速させましょう。