以前はClawdBotとして知られていたMoltBotは、Telegram、WhatsApp、Discord、Slackなどのメッセージングプラットフォームと直接統合するセルフホスト型エージェントとして際立っています。プライバシーと低遅延を維持しながら、お使いのマシン上で実際のタスクを実行します。
Kimi K2.5をMoltBotに接続することで、多機能で費用対効果の高いアシスタントが作成されます。ユーザーは、Claude 3.5 SonnetやGPT-4oのようなモデルの数分の1のコストで、一般的なタスク、クリエイティブな作業、エージェント的な動作において強力なパフォーマンスを得ることができます。プライバシーを重視した設定の場合、量子化されたGGUFウェイトを使用したローカルデプロイメントにより、外部へのデータ送信が不要になります。
このガイドでは、APIとローカルの両方の方法を詳細に説明します。構成例、検証手順、よくある問題の解決策が含まれています。
MoltBotとKimi K2.5を組み合わせる理由
MoltBotは実行レイヤーとして機能し、LLMはインテリジェンスを提供します。Kimi K2.5は、この役割において明確な利点を提供します。
このモデルは、MoE設計を通じて高い容量を提供し、関連するエキスパートを効率的にアクティブ化します。ネイティブでマルチモーダル入力を処理できるため、MoltBotはスクリーンショット、UIデザイン、短いビデオなどを処理して、ビジュアルからのコード生成などのタスクを実行できます。
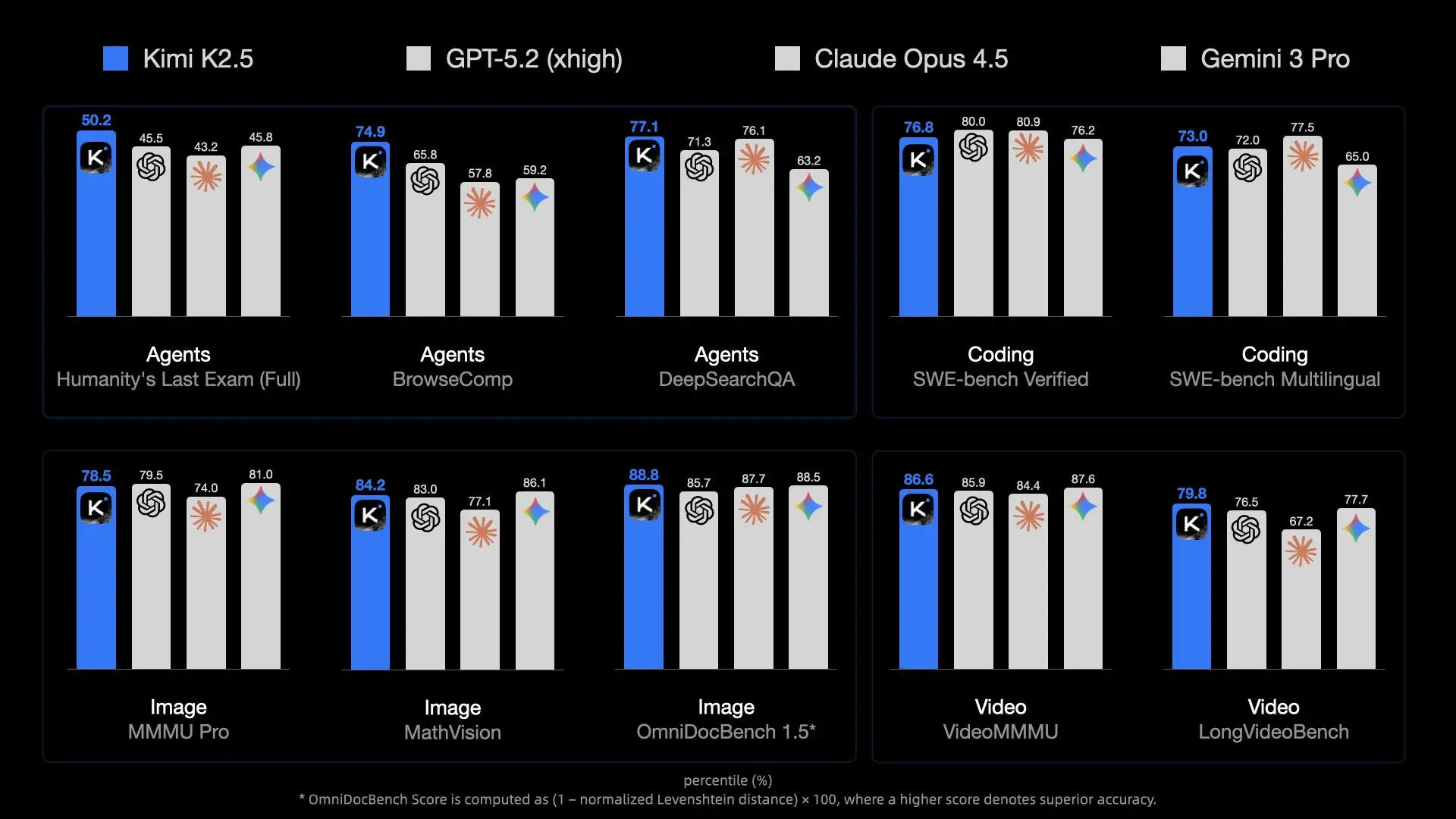
ほとんどのデプロイメントでコンテキスト長は256Kトークンに達し、広範なプロジェクトのコードベース、ドキュメント、または会話履歴を保持できます。これは、永続的なアシスタントにとって不可欠です。
APIコストは、欧米の代替品と比較して低く抑えられます。ヘビーユーザーは時間の経過とともに大幅な節約が可能です。継続的な費用がゼロで最大限の制御が必要な場合は、量子化された消費者向けハードウェアでローカル推論が機能します。
Kimi K2.5は、最大100個のサブエージェントによる自己指示型スウォームを並列ツール実行のために含む、強力なエージェント能力を示します。MoltBotのスキルシステムを通じてルーティングされると、これらの機能はチャットメッセージから直接複雑なワークフローを自動化します。
MoltBotの柔軟性は、OpenAI互換のあらゆるエンドポイントをサポートします。プロバイダーを切り替えるには構成の更新のみが必要なため、ユーザーは簡単に試すことができます。
前提条件
構成の前に、これらの要素を準備してください。
MoltBotを完全にインストールしてください。まだ実行していない場合は、インストールスクリプトを実行してください。
curl -fsSL https://molt.bot/install.sh | bash
このプロジェクトは、Anthropicからの商標要求を受けて、2026年1月27日にClawdBotからMoltBotにブランド変更されました。古いインストールでは`~/.clawdbot`ディレクトリが残っている場合がありますが、最近のバージョンでは`moltbot`コマンドと`~/.moltbot`または類似のパスを使用します。正確なセットアップについては、molt.botのドキュメントまたはGitHubリポジトリ(github.com/moltbot/moltbot)を確認してください。
Kimi K2.5へのアクセスを取得します。
- APIルート:platform.moonshot.aiでアカウントを作成し、APIキーを生成し、プロジェクトの予算制限をメモしてください。
- ローカルルート:量子化されたウェイトをダウンロードします(例:Hugging Faceのmoonshotai/Kimi-K2.5またはunsloth/Kimi-K2.5-GGUFのようなコミュニティリポジトリから)。llama.cppをインストールし、サーバーを起動します。
テスト用にApidogをインストールします。これは認証ヘッダー、JSONボディ、レスポンスストリーミングを効果的に処理します。
MoltBotのためにNode.jsが実行されていることを確認してください。基本的なターミナルの知識はJSONファイルの編集に役立ちます。
方法1:Moonshot API経由での接続(ほとんどのユーザーに推奨)
このアプローチは最小限のハードウェアで、フル256Kのコンテキストとマルチモーダルサポートを提供します。
ステップ1:Apidogを使用してAPI接続を検証する
Apidogを起動し、新しいPOSTリクエストを作成します。
URLを次のように設定します。
https://api.moonshot.ai/v1/chat/completions
ヘッダーを追加します。
Authorization: Bearer sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
(実際のキーに置き換えてください。)
基本的なテストにはこのボディを使用します。
{
"model": "kimi-k2.5",
"messages": [
{
"role": "user",
"content": "Confirm you are Kimi K2.5 and describe your capabilities briefly."
}
],
"temperature": 0.7,
"max_tokens": 256
}
リクエストを送信します。一貫性のある出力とともに200のレスポンスが成功すると、キーが機能していることが確認されます。ここでレートリミットまたは予算のエラーをメモしてください。
ステップ2:構成ファイルを見つけて編集する
MoltBotは設定をJSONファイルに保存します。通常は次のとおりです。
~/.moltbot/moltbot.json- またはレガシー:
~/.clawdbot/moltbot.json/~/.clawdbot/agents/default/config.json
エディタで開きます。
プロバイダーセクションを追加または変更します。
{
"agent": {
"model": {
"primary": "moonshot/kimi-k2.5"
}
},
"models": {
"providers": {
"moonshot": {
"baseUrl": "https://api.moonshot.ai/v1",
"apiKey": "sk-your-moonshot-api-key-here",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5",
"name": "Kimi K2.5 (API)",
"contextWindow": 262144,
"maxTokens": 8192
}
]
}
}
}
}
セキュリティに関する注意:本番環境でキーをハードコードすることは避けてください。環境変数(例:`export MOONSHOT_API_KEY=sk-...`)を設定し、MoltBotが拡張をサポートしている場合はそれを参照してください。
ステップ3:変更を適用して再起動する
ファイルを保存し、再起動します。
moltbot restart
または必要に応じてゲートウェイ/サービスを停止して開始します。
方法2:ローカルKimi K2.5デプロイメント経由での接続
ローカル実行はプライバシーを優先し、定期的なコストを排除しますが、かなりのVRAM/RAMを必要とします。
ステップ1:ローカル推論サーバーを起動する
互換性のためにllama.cppを使用します。
GPUサポートが利用可能な場合は、llama.cppをビルドします。
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_CUDA=1 # または適切なフラグ
量子化されたGGUFバリアントをダウンロードします(例:バランスの良いUD-TQ1_0)。
huggingface-cliまたは直接ダウンロードを使用します。
OpenAI互換サーバーを起動します。
./llama-server \
-m /path/to/Kimi-K2.5-UD-TQ1_0.gguf \
--port 8080 \
--ctx-size 32768 \ # ハードウェアの制限まで調整してください。256Kは極端なリソースを必要とします。
--n-gpu-layers 99 \
--host 0.0.0.0
http://localhost:8080/v1/modelsを参照して検証します。
ステップ2:ローカルエンドポイントのMoltBot構成を更新する
JSONファイルを編集します。
{
"agent": {
"model": {
"primary": "local-kimi/kimi-k2.5"
}
},
"models": {
"providers": {
"local-kimi": {
"baseUrl": "http://127.0.0.1:8080/v1",
"apiKey": "sk-no-key-required",
"api": "openai-completions",
"models": [
{
"id": "kimi-k2.5-local",
"name": "Kimi K2.5 Local",
"contextWindow": 32768, // --ctx-sizeと一致させる必要があります
"maxTokens": 4096
}
]
}
}
}
}
Dockerに関する注意:MoltBotがコンテナ化されている場合は、127.0.0.1を`host.docker.internal`に置き換えてください。
ステップ3:再起動とリソース使用量の監視
MoltBotを再起動し、システムモニターを監視します。ローカル推論はかなりのメモリを消費するため、必要に応じてレイヤーをオフロードしたり、コンテキストを減らしたりしてください。
テストと検証
統合が機能していることを確認します。
MoltBotインスタンスにメッセージを送信します(接続されたアプリ経由):
「現在、誰があなたを動かしていますか?」
Kimi K2.5は通常、Moonshot AIを識別して応答します。
ログを確認します。
moltbot logs
api.moonshot.aiまたはlocalhost:8080へのリクエストを探します。
APIを使用している場合はマルチモーダルをテストします。チャット経由で画像をアップロードし、その説明またはそこからのコード生成を求めます。
よくある問題のトラブルシューティング
プロバイダーの検証が失敗する場合 → Apidogで正確なbaseUrl + keyを再テストしてください。ネットワークプロキシやファイアウォールが干渉することがよくあります。
コンテキストオーバーフローエラー → JSON内の`contextWindow`をサーバーの`--ctx-size`と一致させてください。MoltBotは制限に達すると切り捨てたり要約したりしますが、値が一致しないとクラッシュの原因となります。
ローカルでの応答が遅い場合 → `gpu-layers`を減らす、量子化を低くする、またはllama.cppでフラッシュアテンションを有効にしてください。
予期しないフォーマット/幻覚 → `temperature`(0.6~1.0)を試すか、Kimi固有のチューニングのためにMoltBotエージェント構成にカスタムシステムプロンプトを追加してください。
API予算の枯渇 → platform.moonshot.aiで使用状況を監視し、日次制限を設定してください。
結論
Kimi K2.5とMoltBotの統合は、高性能で経済的、かつオプションで完全にプライベートなパーソナルAIエージェントを提供します。API方式は利便性と最大の機能を提供し、ローカルセットアップは完全なデータ主権を保証します。
両方のアプローチを試してみてください。問題を迅速に特定するために、Apidogを常時使用してください。MoonshotがKimiモデルの更新を続け、MoltBotが進化するにつれて、この組み合わせはユーザーをアクセス可能なエージェントAIの最前線に位置づけます。
今すぐ設定を開始しましょう — 強化されたアシスタントがあなたを待っています。