
イントロダクション
データボリュームが増加し続ける中、機械学習モデルのトレーニングで一般的なアプローチの一つがバッチトレーニングです。この方法ではデータセットを小さなサブセットや「バッチ」に分割し、モデルに一度に一つずつフィードします。
この投稿では、データセットをバッチに分割するための三つの異なる技術を探ります:
- 大きなテンソルを作成する
- HDF5を使用して部分データを読み込む
- Pythonジェネレーターを使用する
この例では、モデルは音声ベースの検出器であると仮定しますが、議論された方法は広く適用可能です。この例は特定のものですが、コアのステップ—分割、前処理、データの反復は普遍的に関連しています。これらの技術は、画像ファイル、SQLクエリからのテーブル、またはHTTPレスポンスなど、さまざまなデータソースで使用できます。ここでの焦点はプロセスそのものです。
各メソッドを評価するために、次の要因を考慮します:
- コードの品質
- メモリ使用量
- 時間効率
始める前に、Postmanの代替品を必要とするAPIテストを行っている場合(それが高額になりつつあり、機能が少なくなっています)、Apidogが理想的な選択肢です!

Apidogは、API管理とテストのために設計されたコラボレーションプラットフォームで、Postmanに似ていますが、日付の取り扱いを容易にする追加機能があります。ここでそれがどのように役立つかを紹介します:
データセットの文脈におけるバッチとは
バッチは一般的に入力-出力ペア (X[i], y[i]) であり、データのサブセットを表します。私たちの音声ベースの検出器の場合、モデルは処理された音声シーケンスを入力として受け取り、特定のイベントが発生する確率を出力します。この場合、バッチは次のものから構成されます:
- X[t] - 時間ウィンドウにわたってサンプリングされた処理された音声トラックを表す行列
- y[t] - イベントの発生を示すバイナリラベル。
ここで、tは時間ウィンドウを指します(図1)。
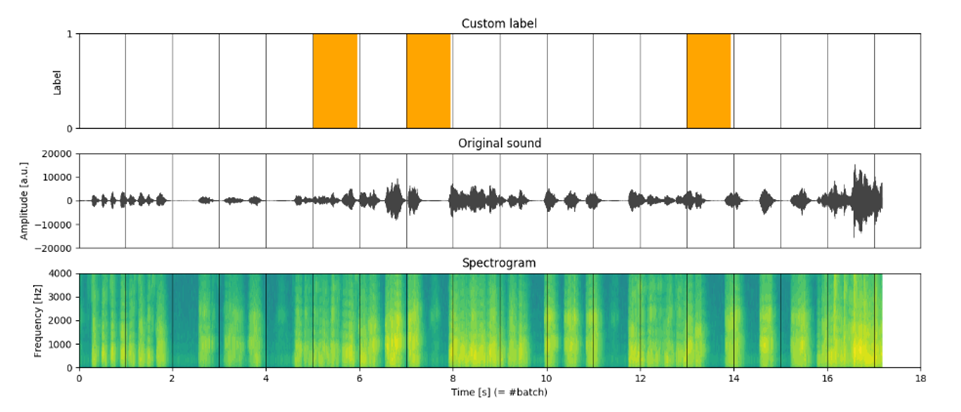
データセットを分割するための異なるアプローチの比較
アプローチ #1 - 大きなテンソルを使用
モデルは2Dテンソルの形で入力を受け取ります。バッチ処理に対応するために、テンソルのランクを増やし、第3の次元をバッチサイズを表すために使用できます。このプロセスの手順は次のとおりです:
- 入力データ (X) を読み込む。
- 対応するラベル (y) を読み込む。
- Xとyを小さなバッチに分割する。
- 各バッチの特徴を抽出する(例: スペクトログラム)。
- 処理されたX[t]とy[t]のバッチを組み合わせる。
しかし、このアプローチは理想的ではないかもしれません。理解を深めるための実装例を探ります。
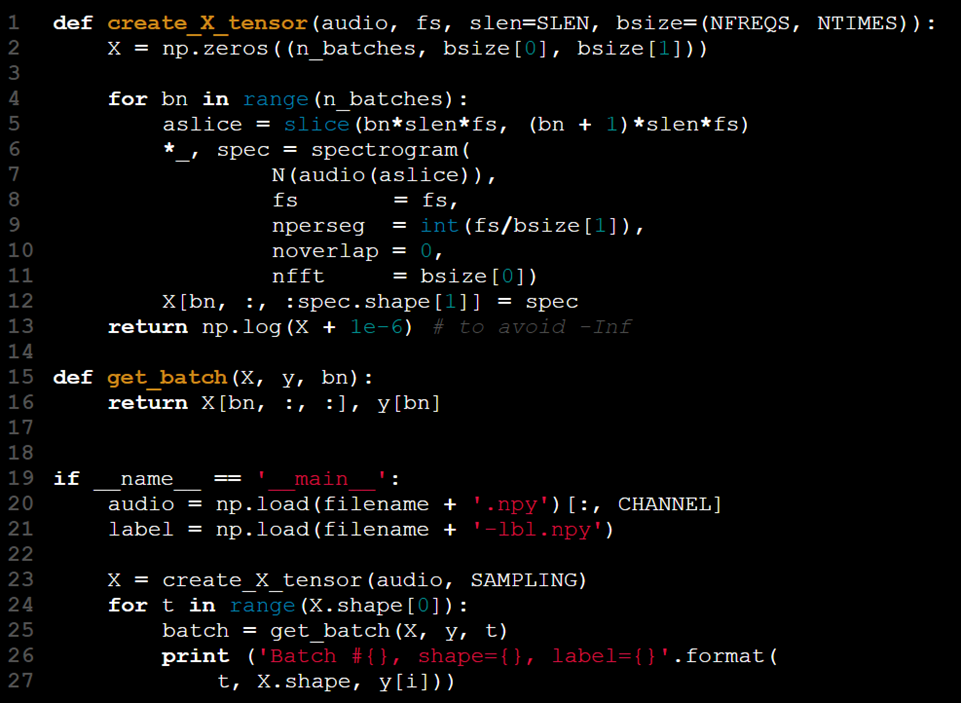
このアプローチは「すべてを一度に読み込んで、後で結果に対処する」と要約できます。
「大きなテンソル」アプローチの長所と短所
Xを自己完結型データセットとして扱うことは有利に見えるかもしれませんが、この方法にはいくつかの欠点があります:
1. メモリ制限: データセット全体をRAMに読み込むと、特に利用可能なメモリがすべてのデータを保持するのに十分でない場合に問題が発生します。
2. バッチ次元の剛性: Xの最初の次元はバッチサイズを表すために使用されますが、これは単なる慣例です。誰かがこの順序を変更することに決めた場合(例: 最後の次元をバッチ用に使用)、コードは調整が必要です。
3. バッチの追跡: X.shape[0] はバッチの正確な数を提供しますが、現在のバッチを追跡するために補助変数(例: t)が必要であり、コードに複雑さを加えます。
4. 冗長な関数: この設計では、バッチ処理のためにXとyをスライスし組み合わせるget_batch関数が必要であり、コードが不必要に複雑になります。
アプローチ #2 - HDF5を使用してバッチを読み込む
すべてのデータをRAMに読み込む問題を解決する一つの方法は、必要なデータの一部のみを読み込むことです。データがファイルに保存されている場合、データセット全体を読むのではなく、小さなセクションを読み込み扱う方が理にかなっています。
CSVファイルの場合、Pandasのread_csv関数のskiprowsとnrows引数を使用すると、ファイルの特定の部分を読み込むことができます。
しかし、この方法は本当にすべてのシナリオに対応できるのでしょうか?非常に大きく、非常に複雑なデータ、つまり音声ファイルを扱う場合、Pandasのskiprowsやnrowを使用するのは適切でないかもしれません。そこで、別の方法、階層データ形式(HDF5)が登場します。
この形式は、複数の配列の保存をサポートし、NumPy配列のようにそれらにアクセスし操作する便利な方法を提供します。
たとえば、HDF5ファイルに保存された「audio」および「label」という名前のデータセットを扱うことができます。Pythonライブラリのh5pyは、この形式を管理するための便利なツールです。
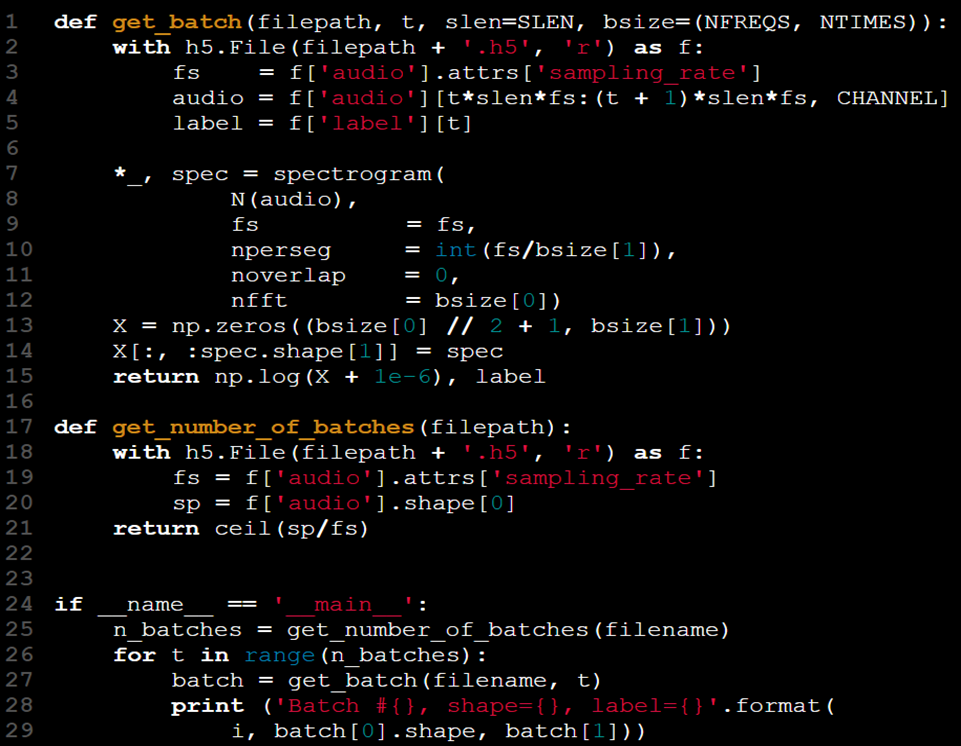
データがより扱いやすくなった今、その全体的な品質も向上しました:
- 以前のget_batch関数は、データを効率的に計算し取得するより実用的なバージョンに置き換えられました。
- Xテンソルを人工的に変更する必要がなくなりました。
- get_batch(X, y, t) を get_batch(filename, t)に変更することにより、データアクセスの抽象化が行われ、Xとyを名前空間に保持する必要がなくなりました。
- データセットは今や単一のファイルに統合されており、データとラベルを別々のファイルから取得する必要がなくなりました。
- サンプリングレート (fs) はHDF5の属性を通じてデータセットファイルの一部として含まれており、別の引数として渡す必要がなくなりました。
これらの改善にもかかわらず、2つの課題が残ります:
- 新しいget_batch関数はその状態を追跡しないため、依然としてtを制御するためにループの使用に依存しています。この関数がループのサイズを知るための組み込みの方法がなく、事前にデータサイズを確認する必要があります。これには、2番目の関数get_number_of_batchesの作成が必要です。
- このセットアップは改善されましたが、完全に状態を保持するget_batch関数の優雅さが不足しており、プロセスのさらなる単純化が可能です。
アプローチ #3 – ジェネレーターを使用
ジェネレーターとは?
ジェネレーターはイテレータオブジェクトを返す関数です。すべての結果を先に計算するのではなく、これらのイテレータはデータを一度に一つずつ提供し、次のリクエストを待ってから続行します。これにより、大きなデータセットを効率よく扱うための理想的な選択肢になります。
繰り返しのパターンを特定しましょう:
すべてを一度に読み込むのではなく、データの部分を逐次的にアクセス、処理、配信する必要があります。Pythonは、これをジェネレーターの形で解決する方法を提供します。
ジェネレーターは3つの方法で実装できます:
リスト内包表記に似たジェネレーター式を使用するが、角括弧の代わりに括弧を使用します(例:(i for i in iterable))。
returnの代わりにyieldを使用してジェネレーター関数を作成します。
カスタム_ iter_(またはgetitem_)および _next _メソッドを持つクラスを定義します。
このシナリオでは、yieldキーワードが私たちのニーズに自然にフィットし、データを管理可能なチャンクに処理し返すことを可能にします。
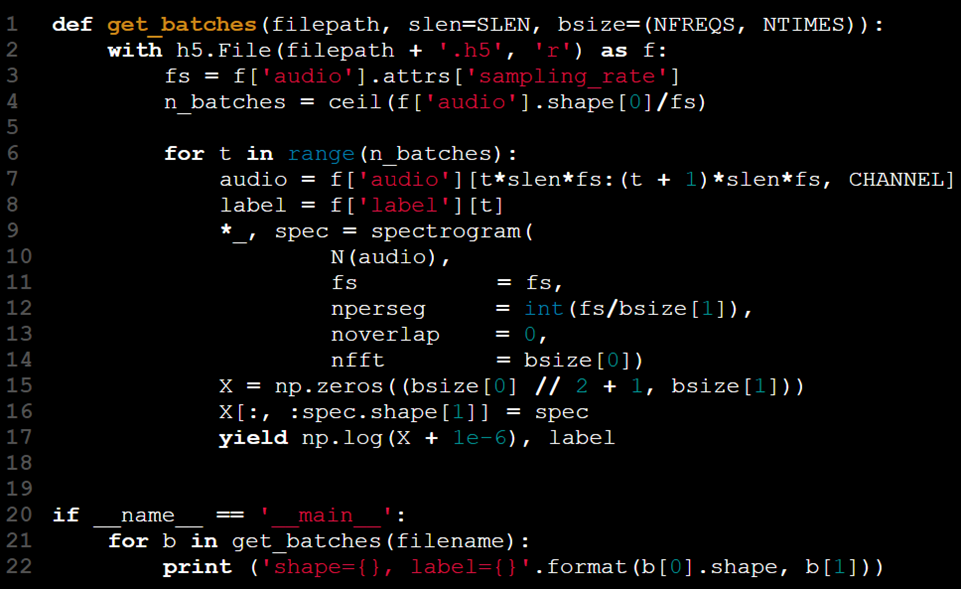
ループは今や関数内に含まれています。yield文を使用することで、ペア(X[t], y[t])はget_batchesがt - 1回呼び出されるまで返されません。これにより、モデルトレーニングコードがループの状態を管理する必要がなくなります。この関数は呼び出し間でその状態を保持し、ユーザーは手動のバッチインデックスなしでバッチを単純に反復できるようになります。
ジェネレーターイテレータは、データが処理されるにつれて徐々に空になるコンテナに例えることができます。各反復でバッチが取得されるため、すべてのデータが消費されるまでプロセスは続き、明示的なインデックス指定や停止条件が不要になります。
パフォーマンス: 時間とメモリ
私たちはコードの品質に焦点を当て始めましたが、これは私たちの解決策がどのように進化してきたかに密接に関連しています。しかし、大きなデータセットを扱う際にはリソース制限を考慮することも同様に重要です。
図2には、私たちが議論した三つの方法を使用してバッチを提供するために必要な時間が示されています。観察されたように、データを処理して転送するための時間は、全ての方法においてほぼ同じです。一度にすべてのデータを読み込んでからバッチに分割するか、最初から段階的に処理するかにかかわらず、結果を得るまでの全体的な時間はほぼ同じです。これは、SSDを使用しているため、データアクセスがより速くなる可能性があります。それにもかかわらず、選択したアプローチは全体的な時間パフォーマンスにほとんど影響がないようです。
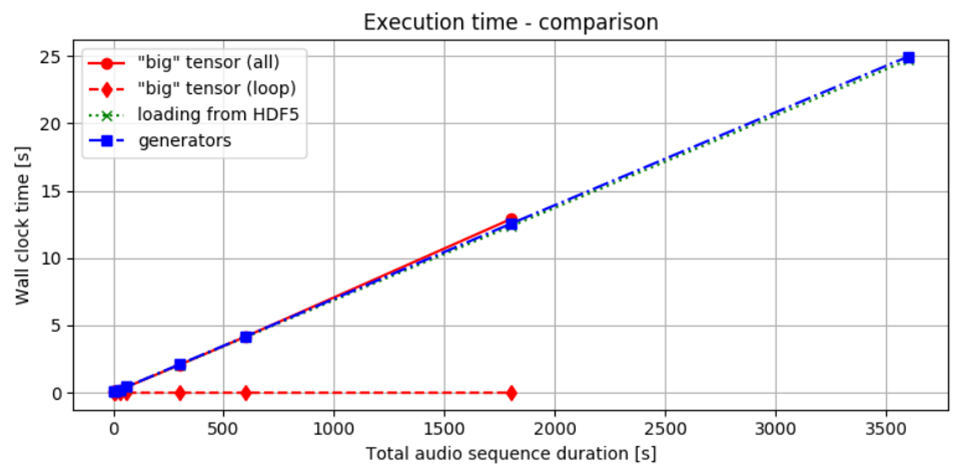
図2. 時間パフォーマンス比較: 赤の実線は、メモリにデータを読み込み、計算を行うのにかかる時間を示しています。赤の点線は、事前に計算されていると仮定したデータスライスを処理するためのループにのみ費やされた時間を示しています。
緑の点線はHDF5ファイルからバッチを読み込むための時間を示し、青の破線はジェネレーターを使用した場合のパフォーマンスを示しています。赤線を比較すると、一度RAMに読み込んだデータにアクセスすることが、最小限の追加コストであることは明らかです。データがローカルにある場合、さまざまな方法間の違いは比較的小さいです。
図3. メモリ使用量の比較: 最初のアプローチは最も高いメモリ消費を示し、1時間の音声サンプルを扱うときにメモリエラーが発生します。対照的に、チャンクベースの読み込み方法は、バッチサイズに基づいてメモリ割り当てを制御し、RAM使用量を安全な範囲内に保つことを保証します。
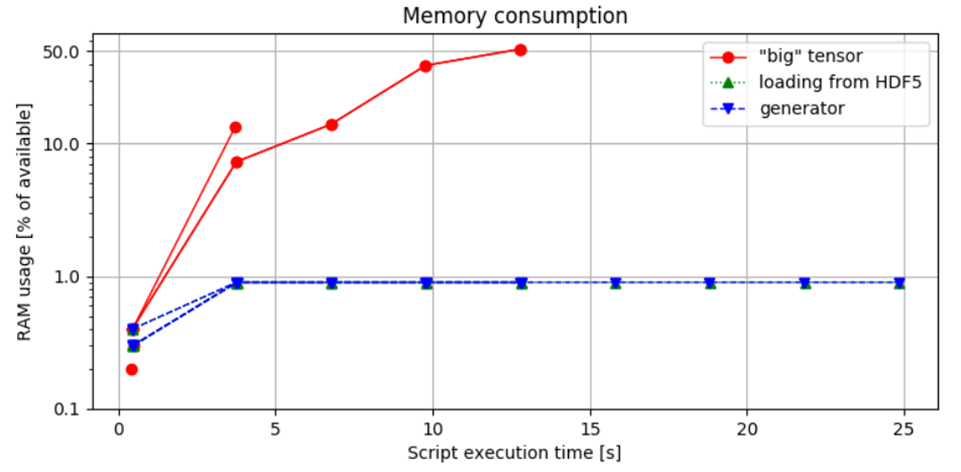
図3. メモリ消費の比較: この図は、スクリプトを実行して測定されたPythonスクリプトによって使用される利用可能なRAMの割合を示します。
python idea.py & top -b -n 10 > capture.log;cat capture.log | egrep python > analysis.log, その後、分析されます。
観察と洞察:
2番目と3番目の方法の比較は、メモリ使用量に有意な差がないことを示しており、ジェネレーターイテレータを実装する選択はメモリフットプリントに影響を与えないことを示しています。この発見は重要な点を強調しています: ジェネレーターは時間とメモリを管理する効率性でしばしば推奨されますが、リソース消費を本質的に減少させるわけではありません。
重要な要素はデータアクセスの効率性と、管理可能な部分でデータを扱う能力です。
HDF5ファイルを利用することは、迅速なデータアクセスを可能にし、すべてのデータを一度に読み込むことを避ける柔軟性を提供するため、有利です。一方、ジェネレーターを組み込むことで、コードの可読性と品質が向上します。
部分データ読み込みのためのHDF5の使用と、ジェネレーターイテレータの組み合わせは、最も効果的なアプローチであるように見え、このことは第3の方法によって示されています。この組み合わせは、メモリ管理とコードの明確さの両方を最適化します。
Pythonでデータセットを分割する方法(例)
Pythonでは、データタイプや使用しているフレームワークに応じて、さまざまな方法でデータセットをバッチに分割できます。以下は、いくつかの一般的なアプローチです:
- 純粋なPython: 簡単なループやジェネレーターを使ってリストや配列を分割します。
- NumPy: 配列を分割するためにnumpy.array_splitを使用します。
- PyTorch: ニューラルネットワークにおいて効率的にバッチ処理するためにDataLoaderを使用します。
- TensorFlow: 効率的なバッチ処理とデータパイプラインのためにtf.data.Datasetを使用します。
- Pandas: リスト内包表記やループを使ってDataFrameを分割します。
1. シンプルなPython関数を使う
リストまたはNumPy配列の形のデータセットがある場合、カスタム関数を使ってデータをバッチに分割できます。
def split_into_batches(data, batch_size):
"""指定されたサイズのバッチにデータを分割します。"""
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
# 使用例
dataset = [i for i in range(100)] # サンプルデータセット
batch_size = 10
batches = list(split_into_batches(dataset, batch_size))
# バッチを印刷
for batch in batches:
print(batch)2. numpy.array_splitを使用
データセットがNumPy配列の形である場合、numpy.array_split()関数を使ってデータセットをバッチに分割できます。
import numpy as np
# サンプルデータセット
dataset = np.arange(100)
# バッチに分割
batch_size = 10
batches = np.array_split(dataset, len(dataset) // batch_size)
# バッチを印刷
for batch in batches:
print(batch)3. torch.utils.data.DataLoaderを使用(PyTorch)
PyTorchを使用している場合、DataLoaderを使ってデータセットを簡単にバッチ処理できます。DataLoaderはデータをシャッフルし、バッチ処理を行います。
import torch
from torch.utils.data import DataLoader, TensorDataset
# サンプルデータセット
data = torch.arange(100)
labels = torch.arange(100) # ラベルもあると仮定します
# TensorDatasetを作成
dataset = TensorDataset(data, labels)
# DataLoaderを使用してバッチに分割
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# バッチを印刷
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)例: 簡単なリストを用いたインデクサーの実現
import math
import torch
import torch.nn as nn
X = torch.rand(1000,10, 4)
batch_size = 64
num_batches = math.ceil(X.size()[0]/batch_size)
X_list = [X[batch_size*y:batch_size*(y+1),:,:] for y in range(num_batches)]
print(X_list[0].size())4. tensorflow.data.Datasetを使用(TensorFlow)
TensorFlowの場合、tf.data.Dataset APIは、データセットをバッチ処理するための高性能な方法を提供します。
import tensorflow as tf
# サンプルデータセット
dataset = tf.data.Dataset.range(100)
# バッチに分割
batch_size = 10
batched_dataset = dataset.batch(batch_size)
# バッチを印刷
for batch in batched_dataset:
print(batch.numpy())5. DataFramesに対してpandasを使用
データセットがpandasのDataFrameである場合、塊に分割することでバッチに分割できます。
import pandas as pd
# サンプルデータセット
data = pd.DataFrame({'A': range(100), 'B': range(100)})
# バッチに分割
batch_size = 10
batches = [data[i:i+batch_size] for i in range(0, data.shape[0], batch_size)]
# バッチを印刷
for batch in batches:
print(batch)最終的な考え
この投稿では、データをバッチに分割し処理するための三つの方法を探り、それらのパフォーマンスと全体的なコード品質を比較しました。ジェネレーター単独では効率を必ずしも向上させるわけではないことが観察されましたが、より優雅で可読性の高い解決策に貢献しています。最終的に、各アプローチの効果は時間とメモリの制約によって影響を受けます。
どのアプローチが最も魅力的だと思いますか?
データ形式や処理ニーズに最適な方法を選択してください。
頑張ってください!
Pythonにおけるデータセット分割に関するFAQ
Pythonでデータセットをバッチに分割する方法は?
Pythonでデータセットをバッチに分割するには、NumPyやPyTorchのようなライブラリを使用できます。以下はNumPyを使用したシンプルな例です:
import numpy as np
def create_batches(data, batch_size):
return np.array_split(data, np.ceil(len(data) / batch_size))
# 使用例
data = np.arange(10) # サンプルデータセット
batches = create_batches(data, 3)
print(batches)
この関数は、指定されたサイズのバッチにデータセットを分割します。
自分のデータセットをどのように分割すべきですか?
データセットを分割する際に考慮すべき戦略は次のとおりです:
- ランダム分割: データセットをシャッフルし、トレーニング、検証、テストセットに分割します。
- 層化分割: 各サブセットが元のデータセットと同じターゲットクラスの分布を維持することを確保します。
- 時間ベースの分割: 時系列データの場合、シーケンスを維持するために時間に基づいて分割します。
一般的な方法論は、これらの方法の組み合わせを使用して、各サブセットに代表的なサンプルを確保することです。
データセットを80対20に分割するには?
データセットを80%トレーニング、20%テストに分割するには、sklearn.model_selectionモジュールのtrain_test_split関数を使用できます:
from sklearn.model_selection import train_test_split
data = ... # データセット
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
このコードはデータセットをランダムに分割し、80%をtrain_data、20%をtest_dataに割り当てます。
大きなデータセットのバッチサイズをどのように選択すればよいですか?
大きなデータセットのバッチサイズを選択する際には、いくつかの考慮事項があります:
- メモリ制約: バッチサイズがGPUまたはCPUのメモリ制限内に収まることを確認します。
- トレーニングの安定性: 小さなバッチサイズはより安定したトレーニングをもたらしますが、トレーニング時間が長くなる可能性があります。
- 学習のダイナミクス: 大きなバッチサイズはトレーニングを加速できますが、一般化解の悪化をもたらす可能性があります。
一般的なアプローチは、最初にバッチサイズを32または64から始め、パフォーマンスとリソースの可用性に基づいて調整することです。最適なバッチサイズを見つけるために実験が重要です。
結論に至る前に、Postmanの置き換えが必要なAPIテストを行っている場合(それが高額になり、機能が減少しています)、Apidogが理想的な選択肢です!

Apidogは、API管理とテストのために設計されたコラボレーションプラットフォームで、Postmanに類似するが、日付の処理を容易にする追加機能があります。こちらがその役立ち方です:


