
インテリジェントなアプリケーションを構築する開発者は、GPT-5.2のような最先端モデルをワークフローに統合するという課題に直面することがよくあります。OpenAIがAI機能の最新フロンティアとしてリリースしたGPT-5.2は、コード生成、画像認識、多段階推論において限界を押し広げます。これは実験のためだけでなく、複雑な専門タスクを処理する堅牢でスケーラブルなソリューションをデプロイするために統合されます。しかし、バリアント選択からパラメータ調整に至るまで、APIの奥深さは構造化されたアプローチを必要とします。そこでApidogのようなツールが役立ちます。ApidogはAPI設計、テスト、ドキュメント作成を簡素化し、定型作業ではなくイノベーションに集中できるようにします。
GPT-5.2を理解する:主要な機能と開発者にとってそれが重要である理由
GPT-5.2を選択するのは、精度と効率において先行モデルを凌駕するからです。OpenAIはこれを知識労働に最適化されたスイートとして位置付けており、ベンチマーク全体で最先端の結果を達成しています。例えば、コーディングタスクのSWE-Bench Verifiedでは80.0%のスコアを記録し、より少ないイテレーションでより正確なソフトウェアソリューションを生成できることを意味します。さらに、そのビジョン機能はチャート推論のエラー率を半減させ、自動データ視覚化ツールのようなアプリケーションを可能にします。
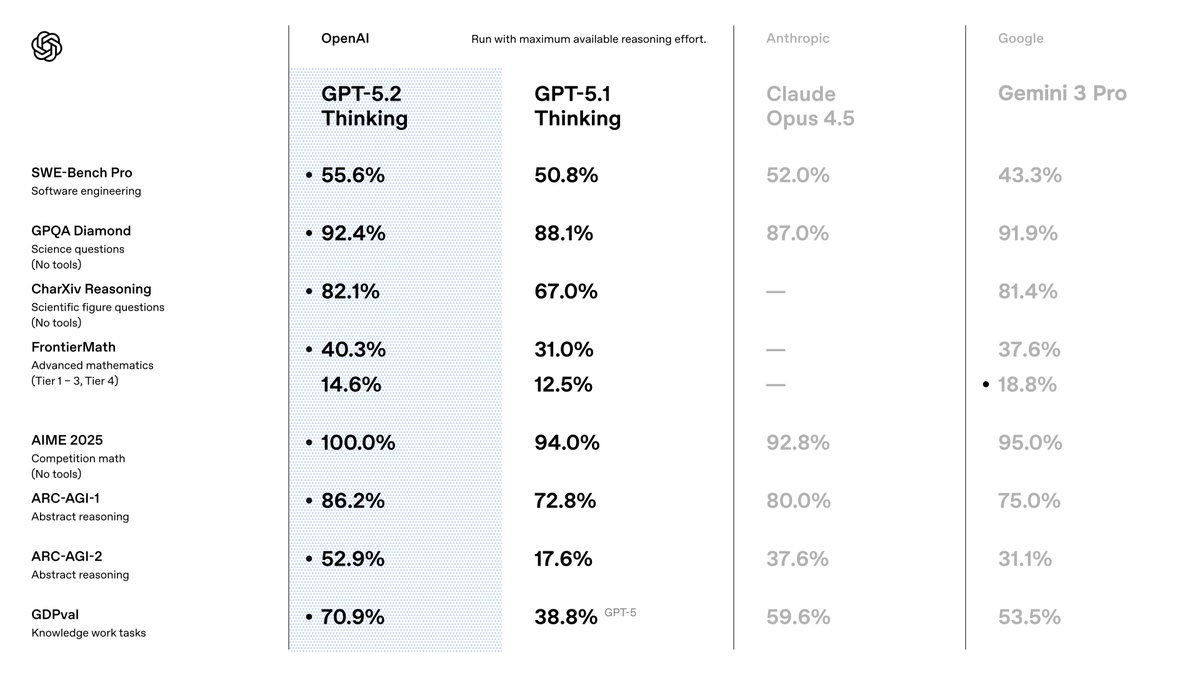
GPT-5.1から移行すると、事実の正確性(検索対応クエリにおけるハルシネーションが30%減少)と、最大256kトークンまでほぼ完璧な精度での長文コンテキスト処理の強化に気づくでしょう。これらの機能が重要なのは、パイプラインでの後処理の必要性を減らすからです。また、マルチターンベンチマークで98.7%を記録するツール呼び出しの改善からも恩恵を受け、エージェントシステムが効率化されます。
APIユーザーにとって、GPT-5.2は既存のOpenAIエコシステムにシームレスに統合されます。チャット補完APIまたは応答APIを介してアクセスし、創造性を制御するためのtemperatureのようなパラメータをサポートします。しかし、成功は適切なバリアントを選択することにかかっています。次にそれらを探ります。
GPT-5.2バリアントの探索:ニーズに合わせてパフォーマンスを調整する
GPT-5.2 は、速度、深さ、コストのバランスをとるバリアントを提供し、モデルの動作をタスクの要求に合わせることができます。モノリシックなモデルとは異なり、これらのオプション(Instant、Thinking、Pro)は柔軟性を提供します。APIリクエスト内の特定のモデル識別子を介してこれらをアクティブ化します。
まず、GPT-5.2 Instant(gpt-5.2-chat-latest)から始めましょう。このバリアントは、迅速な情報検索や技術文書作成など、日常的なインタラクションにおいて低レイテンシを優先します。開発者は、200ms未満の応答時間が不可欠なチャットボットやリアルタイムアシスタントにこれを好んで使用します。翻訳やハウツーガイドを洗練された精度で処理するため、消費者向けアプリに最適です。
次に、GPT-5.2 Thinking(gpt-5.2)を検討してください。これは、長文ドキュメントの要約や論理的な計画など、より深い分析のためにデプロイします。その推論エンジンは数学と意思決定に優れており、FrontierMathの問題の40.3%を解決します。ここでは、複雑なクエリの出力品質を高めるために、reasoningパラメータを「high」または「xhigh」に設定して使用します。例えば、プロジェクト管理ツールでは、最小限のエラーで多段階のワークフローを調整します。
最後に、GPT-5.2 Pro(gpt-5.2-pro)は、困難なドメインでエリートレベルのパフォーマンスを目指します。科学に関するGPQA Diamondで93.2%を誇り、エッジケースの失敗が少ないプログラミングでその能力を発揮します。これは、精度が速度よりも重要視される金融モデリングのような、研究開発プロトタイプやリスクの高い環境のために温存します。
共有された画像は、これら「Max」、「Mini」、「High」、「Low」、「Fast」モードを含むトグルを強調しています。これらは推論の労力と一致します。即時応答には「none」、基本的なタスクには「low」、徹底的な分析には「xhigh」まで設定できます。これらをAPIパラメータを介して切り替えることで、モデルが動的に適応するようにします。例えば、深さを犠牲にせずに速度を優先するバランスの取れたコーディングセッションには、「Max High Fast」に切り替えます。
バリアントを慎重に選択することで、リソースの使用を最適化できます。次に、これらの呼び出しを行うためのアクセスを設定します。
GPT-5.2 APIアクセスの設定:認証と環境準備
APIクレデンシャルを保護することから統合を始めます。OpenAIにはAPIキーが必要であり、それはプラットフォームダッシュボードから生成します。必要であればplatform.openai.comにアクセスしてアカウントを作成し、「API Keys」の下でキーを発行してください。
次に、OpenAI Python SDKをインストールします。ターミナルでpip install openaiを実行してください。このライブラリは、HTTPリクエスト、リトライ、ストリーミングをそのまま処理します。Node.jsユーザーには、npm install openaiが同様の機能を提供します。次のようにインポートします。
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
シンプルな補完で接続をテストします。
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Explain quantum entanglement briefly."}]
)
print(response.choices[0].message.content)
この呼び出しはセットアップを検証します。エラーが発生した場合は、レート制限(Tier 1のデフォルトは3,500 RPM)またはキーの有効性を確認してください。また、拡張されたコンテキスト用の/compactのようなカスタムエンドポイントのためにベースURLを設定します。例:client = OpenAI(base_url="https://api.openai.com/v1", api_key=...)。
基本が整ったところで、リクエストの作成を探ります。
効果的なGPT-5.2 APIリクエストの作成:パラメータとベストプラクティス
チャット補完エンドポイント(/v1/chat/completions)を使用してリクエストを構築します。ペイロードにはmodel、messages、そしてオプションのパラメータとしてtemperature(決定論性には0-2)、max_tokens(最大4096出力)が含まれます。
GPT-5.2の具体的な設定には、深さを制御するためにreasoning_effortを組み込みます。
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Write a Python function for Fibonacci sequence."}],
reasoning_effort="high", # "Max High" トグルに合わせる
temperature=0.7,
max_tokens=500
)
これにより、段階的な推論を含むコードが生成され、バグが減少します。会話のためにメッセージを連鎖させ、ターン間でコンテキストを保持します。ビジョンタスクの場合、タイプ「image_url」のcontentを介して画像をアップロードします。
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Describe this chart's trends."},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}}
]}
]
ベストプラクティスには、コスト削減のためのリクエストのバッチ処理や、リアルタイムUIのためのストリーミング(stream=True)の使用が含まれます。応答のusageでトークン使用量を監視し、プロンプトを洗練させます。さらに、関数呼び出しのためにツールを有効にし、外部APIのスキーマを定義すると、GPT-5.2がそれらを自律的に実行します。
これらを効率的にテストするには、Apidogを統合します。ApidogはOpenAIエンドポイントをモックし、ライブのクォータに達することなくバリアントをシミュレートできます。
ApidogとのGPT-5.2統合:テストとドキュメント作成を簡素化
Apidogは、GPT-5.2 APIワークフローの管理方法を変革します。オールインワンプラットフォームとして、OpenAPI仕様のインポート、リクエストの構築、および自動テストをサポートしています。OpenAIスキーマをApidogにインポートし、GPT-5.2呼び出しのコレクションを設計します。
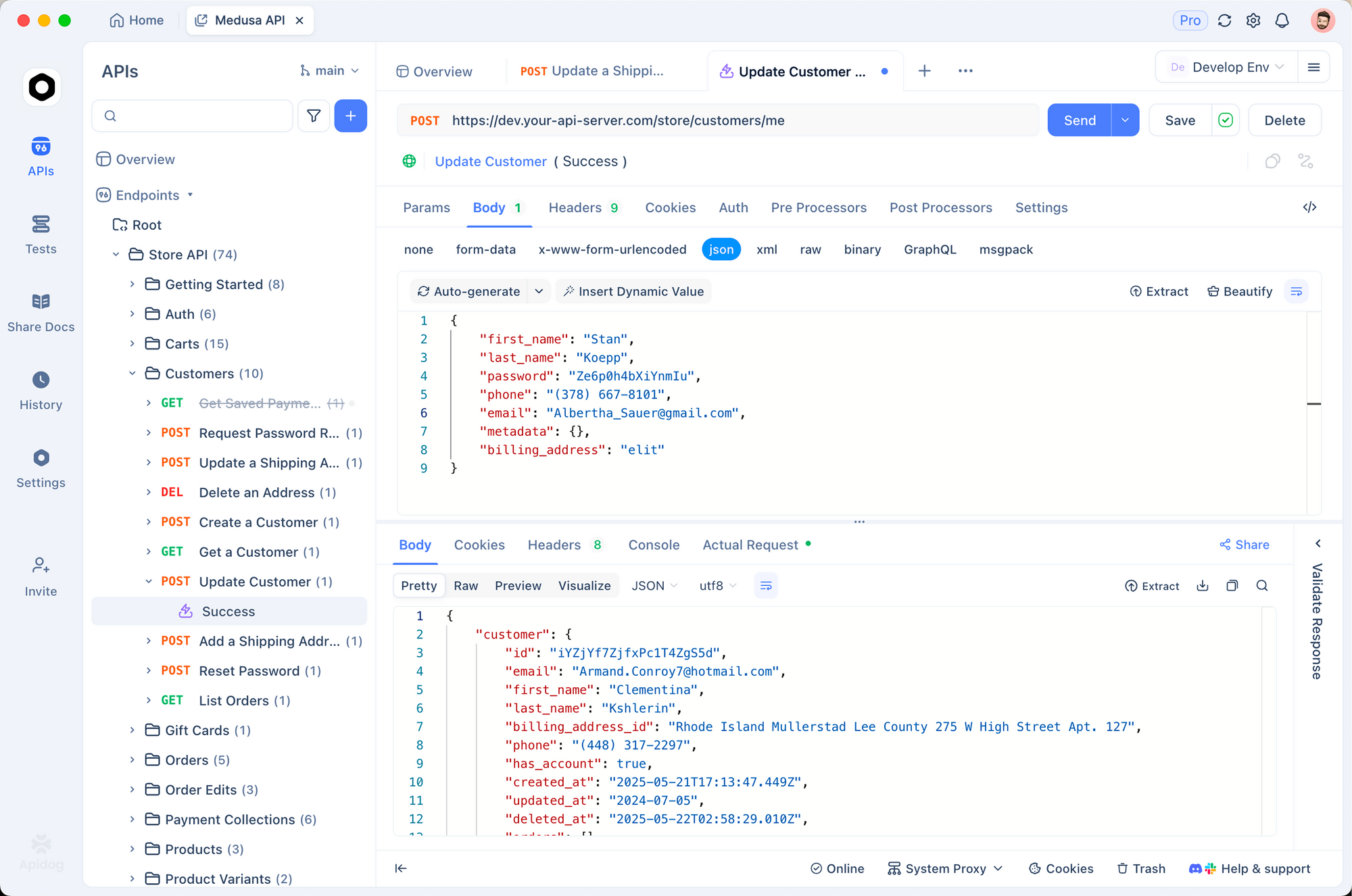
Apidogで新しいプロジェクトを作成することから始めます。https://api.openai.com/v1/chat/completionsへのHTTPリクエストを追加し、ヘッダー(Authorization: Bearer YOUR_KEY, Content-Type: application/json)を設定し、サンプルボディを貼り付けます。「gpt-5.2-pro」のようなモデルの変数を切り替えて、出力を並べて比較します。
Apidogの強みはそのモックサーバーにあります。GPT-5.2のJSON構造を模倣した偽の応答を生成でき、オフライン開発に最適です。例えば、詳細な推論トレースを含む「Max Extra High」応答をシミュレートします。トークン数やハルシネーション率に対するアサーションを含むテストを実行します。

さらに、Apidogの組み込みエディタでAPIをドキュメント化します。同僚がエンドポイントを探索するために使用できるインタラクティブなドキュメントを生成します。PostmanまたはHARにエクスポートして移植性を高めます。本番環境では、Apidogが呼び出しを監視し、「Low Fast」モードでの高レイテンシのような異常を警告します。
Apidogをプロセスに組み込むことで、イテレーションを加速できます。無料でダウンロードして最初のGPT-5.2リクエストをインポートし、数分でその違いを体験してください。
GPT-5.2 APIの価格設定:コストと能力を戦略的にバランスさせる
GPT-5.2アプリケーションをスケールする際には、価格設定を無視できません。OpenAIは100万トークンあたりのコストを、使用量に応じたティアで構成しています。GPT-5.2 Instant(gpt-5.2-chat-latest)の場合、入力トークン100万あたり$1.75、出力トークン100万あたり$14を想定してください。キャッシュされた入力は$0.175に下がり、90%の節約になるため、繰り返されるコンテキストを奨励します。
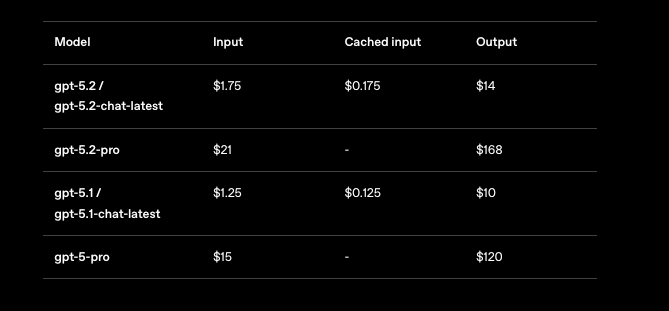
GPT-5.2 Thinking(gpt-5.2)はこれらの料金を反映しており、バランスの取れたタスクに対して費用対効果が高いです。しかし、GPT-5.2 Pro(gpt-5.2-pro)はより高価で、入力100万トークンあたり$21、出力100万トークンあたり$168かかります。このプレミアムは、プロレベルのクエリに対するその優れた精度を反映していますが、ROIを慎重に評価する必要があります。
全体的に見て、GPT-5.2はトークン効率が良く、高品質な出力の場合、GPT-5.1と比較して総支出を抑えることができます。ダッシュボードの使用量アナライザーを通じて追跡します。企業向けには、カスタムティアを交渉してください。Apidogのようなツールは、シミュレートされたトークンフローをログに記録することでコスト予測を支援します。
これらの数値を理解した上で、実践的な例に進みます。
実践例:GPT-5.2によるコード生成とビジョンタスク
具体的なシナリオでGPT-5.2を適用します。コード生成を考えてみましょう。ステート管理を含むReactコンポーネントをプロンプトします。
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Build a React todo list with useReducer."}],
reasoning_effort="medium"
)
出力はクリーンでコメント付きのコードを生成し、80%がベンチマークに沿っています。反復して「Optimize for performance」(パフォーマンスを最適化する)でさらに洗練させます。
ビジョンの場合、スクリーンショットを分析します。UIモックアップをアップロードし、「アクセシビリティの改善点を提案してください」とクエリします。GPT-5.2は、エラー率が半減したことを活かして、色のコントラストなどの問題を特定します。
マルチツールエージェントでは、データベースクエリ用の関数を定義します。GPT-5.2は呼び出しを調整し、20以上のツールを持つメガエージェントのレイテンシを削減します。
これらの例は多様性を示しています。しかし、エラーは発生します。リトライとフォールバックでそれらを処理します。
GPT-5.2 API呼び出しにおけるエラーとエッジケースの処理
レート制限や無効なパラメータに遭遇することがあります。呼び出しをtry-exceptで囲みます。
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # バックオフ
response = client.chat.completions.create(...)
ハルシネーションの場合、検索ツールで相互検証します。長文コンテキストでは、/compactを使用して履歴を圧縮します。機密性の高いアプリでは、バイアスを監視し、フィルターを適用します。
Apidogがここで役立ちます。エラーシナリオのテストをスクリプト化し、堅牢性を確保します。
高度な最適化:GPT-5.2を本番環境向けにスケールする
プロンプトを微調整し、永続的なスレッドのためにアシスタントAPIを使用することでスケールします。繰り返される入力のためにキャッシングを実装します。グローバルなアプリでは、エッジサーバーを介してルーティングします。
LangChainのようなフレームワークと統合します。GPT-5.2をベクトルストアと連携させてRAGシステムを構築します。
最後に、常に最新情報を入手してください。OpenAIは急速に反復開発しています。
結論:GPT-5.2 APIを習得し、未来を築く
これで、GPT-5.2を効果的に活用するためのツールを手に入れました。バリアントの選択からApidogを活用したテストまで、これらの手順を適用してプロジェクトを向上させましょう。価格は慎重な使用であれば手頃であり、かつて研究室に限定されていた機能を解き放ちます。
今日から実験しましょう。GPT-5.2エージェントをプロトタイプ化し、その成果を測定してください。あなたの成果をコメントで共有し、どのような課題に直面しているか教えてください。さらに深く掘り下げるには、OpenAIのドキュメントを参照してください。大胆に構築しましょう。


