
エンジニアや開発者は、過度なリソースを要求することなく高いパフォーマンスを発揮する効率的なモデルを常に求めています。このような状況において、GLM-4.7-Flashは魅力的な選択肢として登場しました。Zhipu AI (Z.ai)が開発したこの30B-A3B Mixture-of-Experts (MoE)モデルは、その強度と効率性のバランスで際立っています。コーディングベンチマーク、推論タスク、ツール統合において優れており、ローカル展開のシナリオに適しています。
GLM-4.7-Flashをローカルで実行することで、ユーザーはデータプライバシーを維持し、遅延を削減し、統合をカスタマイズできるようになります。Ollama、LM Studio、Hugging Faceなどのツールがこのプロセスを簡素化します。
このガイドを進めることで、インストールと使用に関する実践的な洞察が得られるでしょう。まず、システムの基本的な要件を考慮してください。
GLM-4.7-Flashとは何か、なぜローカルで使うのか?
GLM-4.7-Flashは、オープンソースの言語モデルにおける進歩を象徴しています。glm4_moe_liteアーキテクチャに基づいて構築されており、MITライセンスの下でBF16およびF32テンソル型を使用しています。モデルの論文「GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models」は、arXiv:2508.06471から引用し、ツール利用と推論のためのそのトレーニングについて詳述しています。
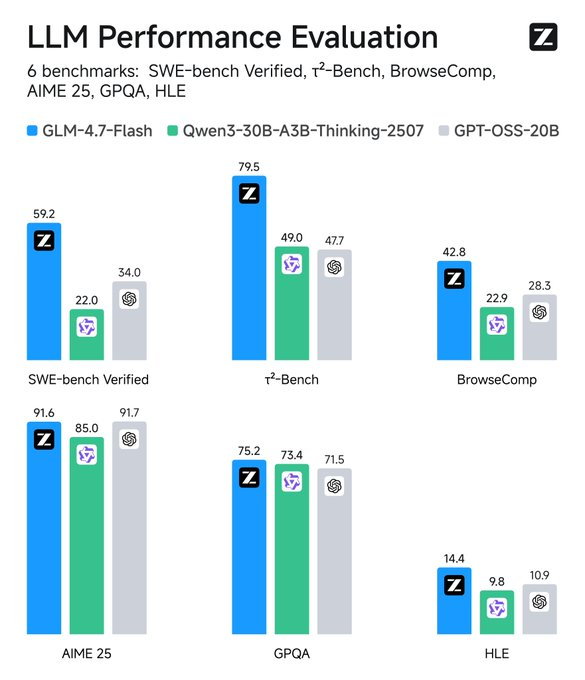
主な機能には、英語と中国語のサポート、テキスト生成、会話タスクが含まれます。マルチモーダル入力をテキストとして処理しますが、テキストのみの出力に焦点を当てています。その規模から制約が生じます。効率的ではありますが、ファインチューニングなしではニッチなドメインでより大規模なモデルに匹敵しない可能性があります。トレーニングデータの詳細は非公開ですが、評価によりコーディングおよびエージェントシナリオでの優位性が確認されています。
ユーザーはAPIコストを回避するためにローカルでの実行を選択します。Z.aiはプラットフォームを通じてGLM-4.7-Flashの無料ティアを提供していますが、ローカル展開により外部サービスへの依存がなくなります。このアプローチは、カスタムアプリケーションを構築する開発者、仮説をテストする研究者、セキュリティを優先する企業に適しています。例えば、ハードウェアの制約に合わせて量子化レベルを制御し、最適なパフォーマンスを確保できます。
GLM-4.7-Flashをローカルで実行するためのシステム要件
ハードウェアはモデル推論において重要な役割を果たします。GLM-4.7-Flashは、LM Studioのガイドラインで指定されているように、基本的な操作のために最低16GBのシステムメモリを必要とします。しかし、GPUアクセラレーションは速度を大幅に向上させます。
Ollamaバリアントの場合:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Faceは効率のためにtorch.bfloat16を推奨しており、互換性のあるNVIDIA GPU(Ampere以降のアーキテクチャ)が必要です。CPUのみの推論も可能ですが、大規模なコンテキストでは大幅に速度が低下します。
ソフトウェアの前提条件には、Python 3.8+、pip、およびGitが含まれます。Transformersのようなフレームワークには追加のインストールが必要です。GPUを使用するためにOSがCUDAをサポートしていることを確認してください。Ubuntu 20.04またはWSL2を備えたWindowsがうまく機能します。
リソースが不足している場合、量子化によりメモリ使用量が削減されます。llama.cppやUnslothなどのツールは、4ビットまたは2ビットのバージョンを提供しており、要件を15〜20GBのVRAMに引き下げます。この柔軟性により、RTX 4090などのコンシューマーハードウェアへの展開が可能になります。
要件が満たされたら、インストール方法を検討しましょう。まず、そのシンプルさからOllamaから始めます。
OllamaでGLM-4.7-Flashをインストールして使用する方法
Ollamaは、大規模モデルをローカルで実行するためのアクセスしやすいプラットフォームを提供します。量子化とAPI提供を自動的に管理します。
まず、Ollamaをインストールします。OS用の実行ファイルをダウンロードして実行します。

ollama --versionでインストールを確認し、GLM-4.7-Flashにはバージョン0.14.3以降が必要なため、それを確認してください。

次に、モデルをプルします。ollama pull glm-4.7-flashを実行します。

メモリ使用量を抑えるために、glm-4.7-flash:q4_K_Mのようなバリアントを選択します。このコマンドは、q4バージョンで約19GBをダウンロードします。
モデルをインタラクティブに実行します。ollama run glm-4.7-flashと入力します。「フィボナッチ数列のPythonコードを生成して。」のようなプロンプトを入力してください。モデルは、そのコーディングの強みを活用して、論理的な出力で応答します。
プログラムによるアクセスには、APIを使用します。curlリクエストを送信します。
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
これにより、応答を含むJSONが返されます。Pythonでは、ollamaライブラリと統合します。
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScriptも同様に、ollama npmパッケージを使用して統合できます。
Modelfileを編集して構成をカスタマイズします。コーディングタスクでの決定的な出力のためにtemperatureを0.7に設定します。Ollamaの最新モードは必要に応じて最近の投稿を取得しますが、ここではローカル推論に焦点を当てます。
この方法は迅速なセットアップに適しています。しかし、グラフィカルインターフェースが必要な場合は、LM Studioを使用してください。
LM StudioでGLM-4.7-Flashをセットアップする
LM Studioは、モデル管理のためのユーザーフレンドリーなGUIを提供します。ダウンロードしてインストールしてください。
モデルハブで「zai-org/glm-4.7-flash」を検索します。リンクされているHugging Faceリポジトリから量子化されたバージョン(MLX-4bit、6bit、または8bit)を選択します。ダウンロードはアプリ内で完了します。
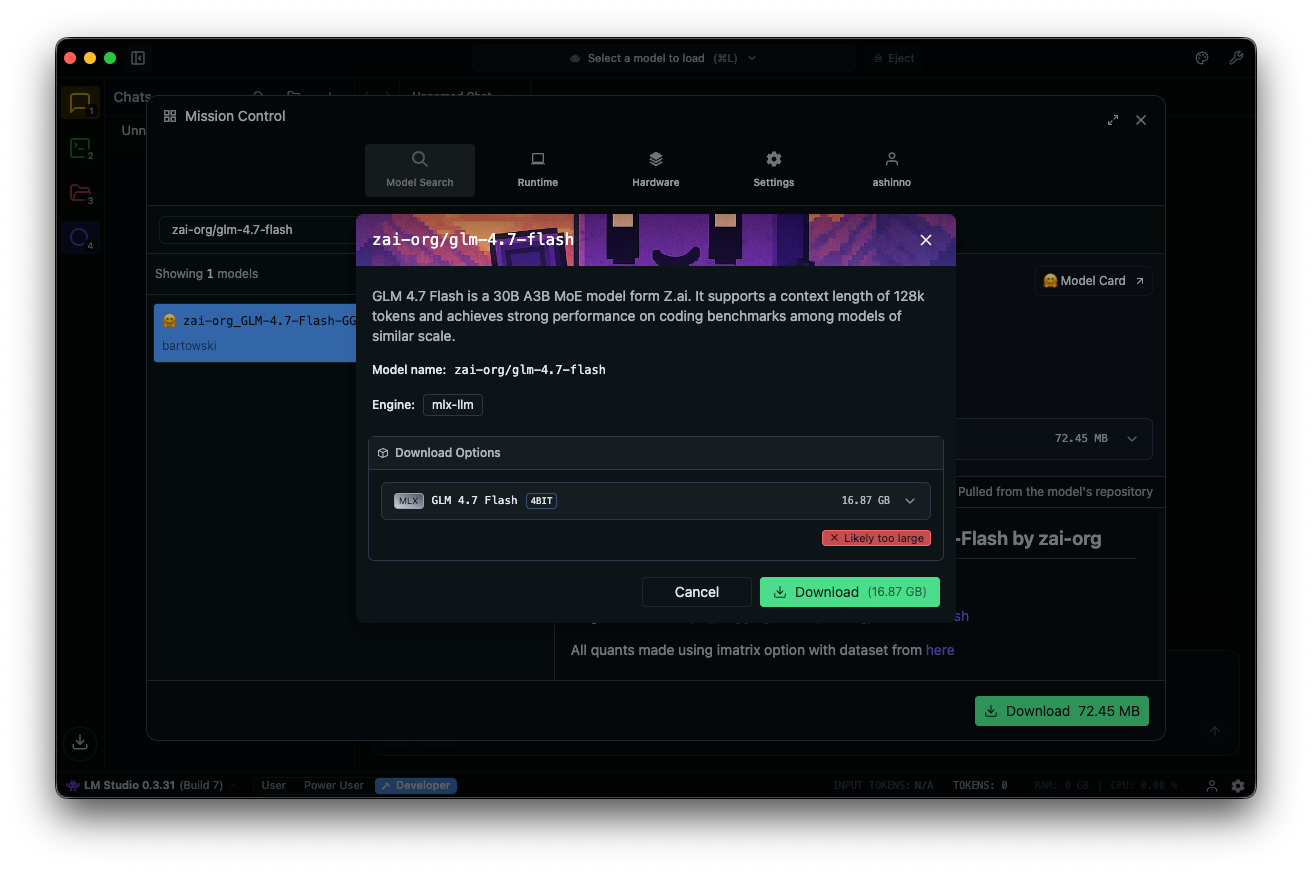
モデルをロードします。チャットインターフェースに移動し、GLM-4.7-Flashを選択し、パラメータを調整します。段階的な推論のために思考を有効にします(デフォルト:true)。temperatureを1、top_kを50、top_pを0.95に設定し、繰り返しペナルティを無効にします。
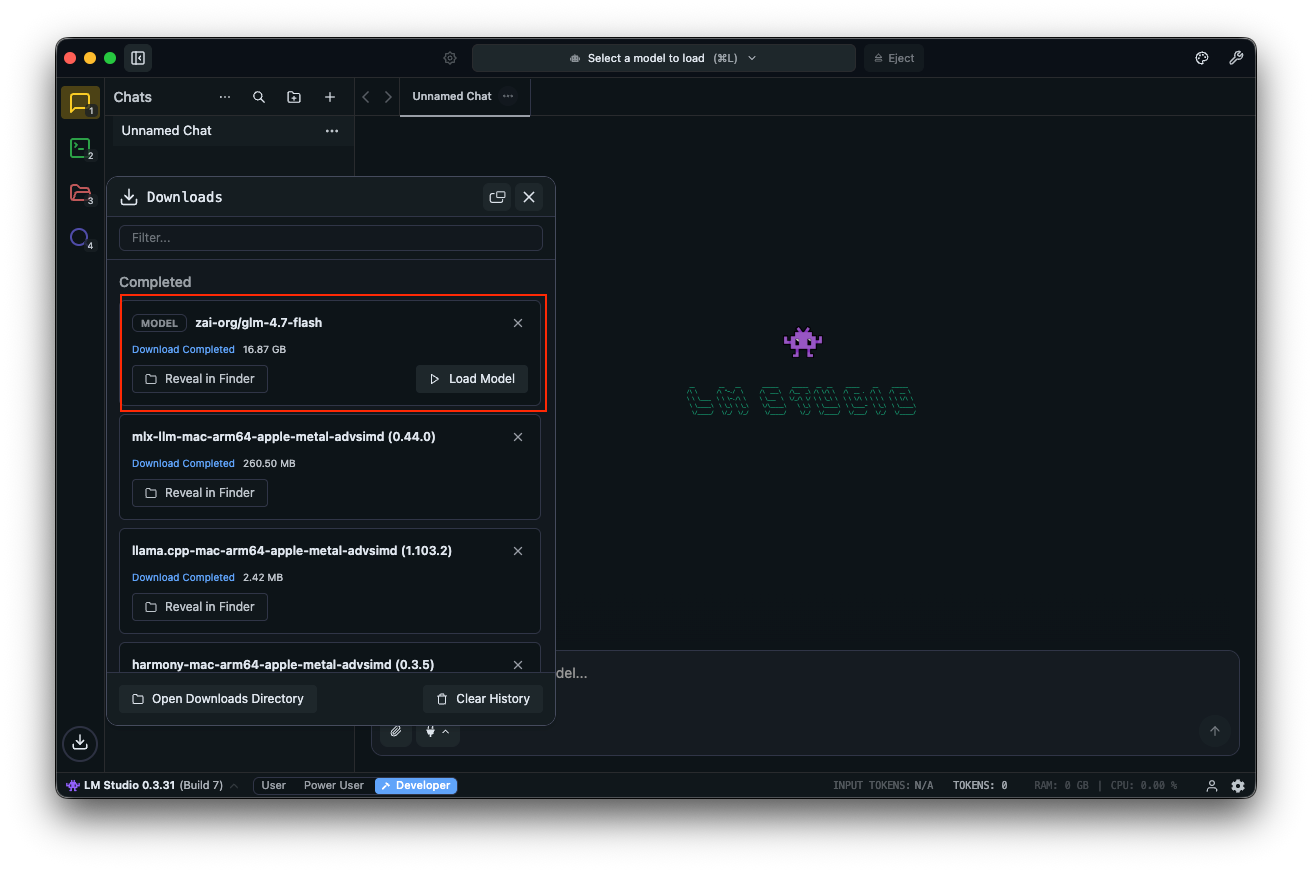
「ユーザー認証のためのREST APIを設計してください。」のようなプロンプトでテストします。LM Studioは、トークン速度とともに結果を表示し、パフォーマンスチューニングに役立ちます。
clear_thinking(デフォルト:false)のようなカスタムフィールドは履歴を管理します。MoEモデルの場合、アクティブなエキスパートを監視します。A3Bは、フォワードパスごとに3つのアクティブなエキスパートが機能することを意味し、効率を最適化します。
LM Studioは、モデルへの直接アクセスを可能にするディープリンクをサポートしています。問題が発生した場合は、システムメモリを確認してください。最低16GBあればクラッシュを防げます。
このツールは実験に優れています。高度なスクリプティングには、Hugging Faceと統合してください。
Hugging Face TransformersでGLM-4.7-Flashを使用する
Hugging Faceは、きめ細かな制御のための堅牢なライブラリを提供します。Transformersをメインブランチからインストールします。
pip install git+https://github.com/huggingface/transformers.git
モデルをロードします。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
入力を準備します。
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
生成します。
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
このセットアップは、VRAMを削減するためにbitsandbytesを介した量子化をサポートしています。モデルのロード時にload_in_4bit=Trueを追加します。
サービングには、vLLMまたはSGLangを使用します。vLLMをインストールします。
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
サーバーを実行します。
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
OpenAI互換のエンドポイント経由でアクセスします。SGLangはソースからのインストールが必要で、同様の手順に従います。
これらのフレームワークは、本番レベルの展開を可能にします。次に、Apidogを使用したAPIテストを検討しましょう。
ローカルGLM-4.7-FlashでのAPIテストにApidogを統合する
OllamaまたはvLLMを介してGLM-4.7-Flashを提供したら、エンドポイントを効率的にテストします。オールインワンAPIプラットフォームであるApidogがこれを容易にします。
Apidogを無料でダウンロードします。ローカルモデルをプロバイダーとして設定することでAI機能をサポートします。該当する場合はAPIキーを使用するか、直接エンドポイントを使用してください。
ApidogのMCPサーバーは、CursorのようなIDEと統合されており、API仕様を使用してコード生成を行います。これはGLM-4.7-Flashのコーディング機能と関連しており、エージェントの出力を直接テストできます。
例えば、ローカルサーバーにクエリを送信し、応答を検証します。これにより、アプリケーションの信頼性が確保されます。
基本に基づいて、最適化に進みましょう。
GLM-4.7-Flashのパフォーマンスを最適化するための高度なヒント
タスクに合わせてパラメータを微調整します。コーディングにはtemperatureを0.7に、クリエイティブライティングには1.0に設定します。多様性のバランスを取るためにtop_p 0.95を使用します。
llama.cppを介してGGUF形式でさらに量子化します。llama.cppをCUDAでコンパイルしてから変換します。
./llama-gguf-split --model GLM-4.7-Flash.gguf
テンプレートのサポートには--jinjaを付けて実行します。
長いコンテキストを処理します。128Kを超える場合は入力を分割します。複雑なクエリには思考を有効にします。
メトリクスを監視します。TensorBoardのようなツールはレイテンシを追跡します。ベースラインと比較すると、GLM-4.7-FlashはSWE-benchで競合モデルを37.2ポイント上回ります。
ツールを統合します。エージェント的な動作のためにプロンプトに関数呼び出しを追加します。
セキュリティ:データ漏洩を防ぐために隔離された環境で実行します。
これらの戦略は、ユーティリティを最大化します。次に、アプリケーションについて考察しましょう。
一般的な問題のトラブルシューティング
メモリ不足エラーに遭遇しましたか?バッチサイズを減らすか、さらに量子化を下げてください。
推論が遅いですか?GPUをアップグレードするか、vLLMのような高速なフレームワークを使用してください。
互換性の問題ですか?Transformersをメインに更新してください。
Ollamaが失敗した場合、ポート11434の空き状況を確認してください。
LM Studioがクラッシュしますか?モデルの整合性を確認してください。
これらに積極的に対処してください。
結論:GLM-4.7-Flashでワークフローを強化する
GLM-4.7-Flashをローカルで実行すると、強力なAI機能が利用可能になります。Ollamaの使いやすさからHugging Faceの柔軟性まで、選択肢は豊富です。シームレスなAPI管理のためにApidogを導入しましょう。無料でダウンロードしてセットアップを向上させましょう。
テクノロジーが進歩するにつれて、このようなモデルはパフォーマンスとアクセシビリティを結びつけます。これらの手順を実行することで、効率的でプライベートなAI展開を実現できます。パラメータやツールのわずかな調整が大きな改善をもたらし、日常的なタスクを効率的なプロセスへと変革します。