
エンジニアや開発者は、高度な言語モデルをアプリケーションに統合するための堅牢なツールを常に求めています。EXAONE APIは、LG AI Researchが提供する強力なオプションとして際立っており、Together AIのようなプラットフォームでホストされています。このインターフェースを使用すると、テキスト補完からマルチモーダル処理まで、幅広いタスクを実行できます。
EXAONEは、英語と韓国語をサポートするバイリンガルモデルファミリーとして登場し、32Bパラメータバージョンは推論、数学、コードにおいて優れています。開発者はホストされたサービスまたはローカルセットアップを通じてこれを使用します。まず、その主要な機能を理解し、次に、実践的な実装ステップに進みます。
EXAONE APIアーキテクチャの理解
EXAONEは、LG AI Researchが専門家レベルの言語モデルを通じて人工知能を民主化するというコミットメントを表しています。APIアーキテクチャは、EXAONE 3.0、EXAONE 3.5、EXAONE 4.0、EXAONE Deepなど、複数のモデルバリアントをサポートしており、それぞれ特定のユースケースに最適化されています。
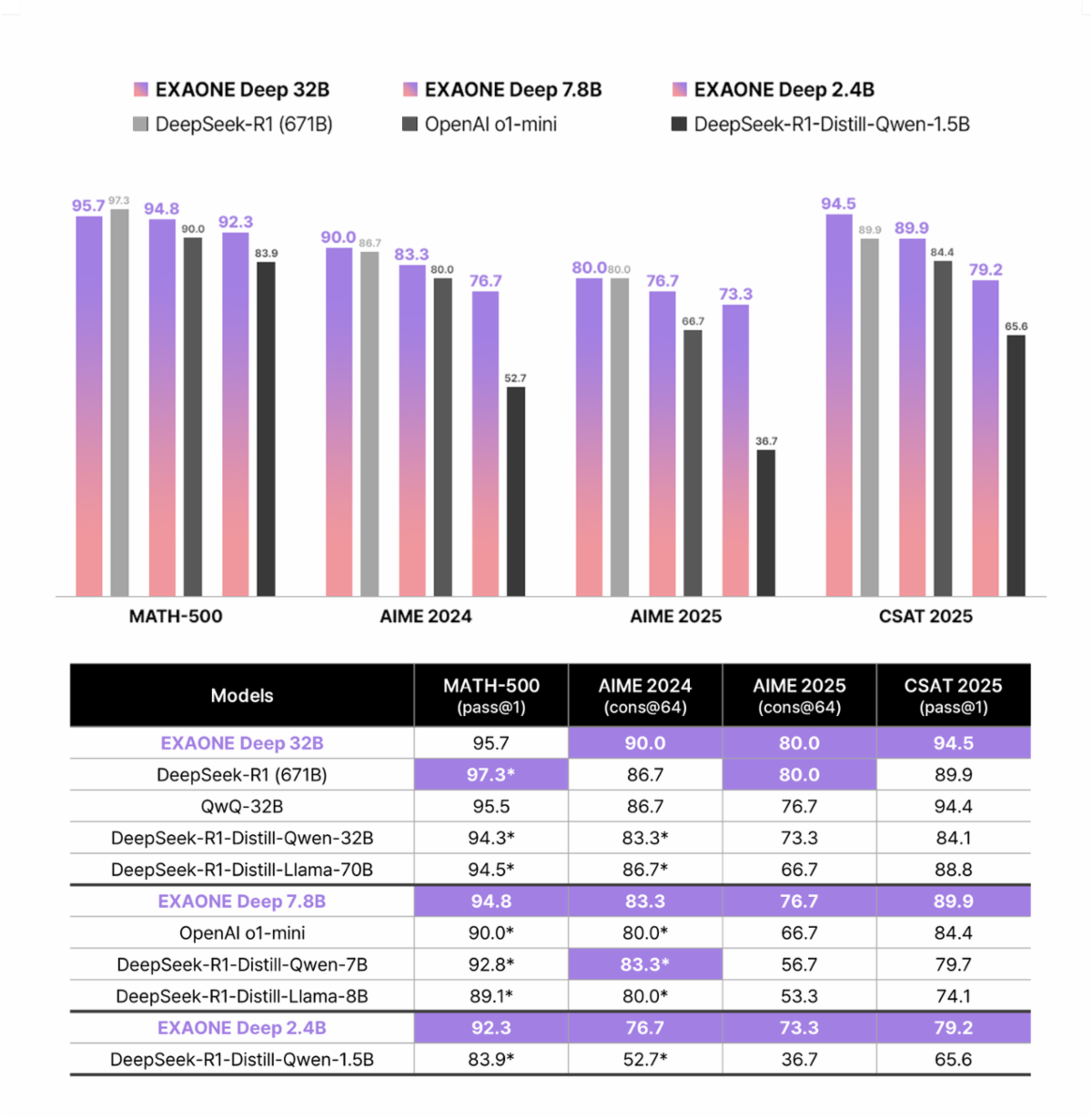
最新のEXAONE 4.0は、画期的なハイブリッドアテンションメカニズムを導入しています。従来のトランスフォーマーアーキテクチャとは異なり、EXAONE 4.0は、32Bモデルバリアントの場合、ローカルアテンションとグローバルアテンションを3:1の比率で組み合わせています。さらに、このアーキテクチャはQK-Reorder-Normを実装しており、LayerNormを従来のPre-LNスキームから、アテンションとMLPの出力に直接適用するように再配置しています。

さらに、EXAONEモデルは英語と韓国語の両方でバイリンガル機能をサポートしています。最近のアップデートでは、多言語サポートがスペイン語にも拡大され、APIは国際的なアプリケーションに適しています。モデルシリーズは、オンデバイスアプリケーション向けの軽量な1.2Bパラメータから、高性能要件向けの堅牢な32Bパラメータまで多岐にわたります。
EXAONE APIセットアップの開始
システム要件と前提条件
EXAONE APIを実装する前に、開発環境が最小要件を満たしていることを確認してください。APIは、クラウドベースのデプロイメントやローカルインストールを含むさまざまなプラットフォームで効果的に動作します。ただし、特定のハードウェア要件は、選択したデプロイメント方法によって異なります。
ローカルデプロイメントシナリオの場合、モデルサイズに基づいてメモリ要件を考慮してください。1.2Bモデルには約2.4GBのRAMが必要ですが、32Bモデルにははるかに多くのリソースが必要です。クラウドデプロイメントオプションは、これらの制約を排除し、スケーラビリティの利点を提供します。
認証とアクセス設定
EXAONE APIへのアクセスは、選択したデプロイメントプラットフォームによって異なります。Hugging Face Hubデプロイメント、Together AIサービス、カスタムサーバー設定など、複数の統合パスが存在します。各方法には異なる認証アプローチが必要です。
Together AIのEXAONE Deep 32B APIエンドポイントを使用する場合、認証にはAPIキー管理が含まれます。Together AIでアカウントを作成し、APIキーを生成し、環境変数を安全に設定してください。APIキーをクライアントサイドのコードや公開リポジトリに決して公開しないでください。
import Together from "together-ai";
const client = new Together({
apiKey: process.env.TOGETHER_API_KEY
});
async function callExaoneAPI(prompt) {
try {
const response = await client.chat.completions.create({
model: "exaone-deep-32b",
messages: [
{
role: "user",
content: prompt
}
],
max_tokens: 1000,
temperature: 0.7
});
return response.choices[0].message.content;
} catch (error) {
console.error("EXAONE API Error:", error);
throw error;
}
}
Ollama統合によるローカルデプロイメント
ローカルデプロイメントは、プライバシー、制御、およびレイテンシの削減という利点を提供します。Ollamaは、複雑なインフラストラクチャ要件なしにEXAONEモデルをローカルで実行するための優れたプラットフォームを提供します。このアプローチは、機密データを扱う開発者やオフライン機能を必要とする開発者にとって特に有益です。
Ollamaのインストールと設定
まず、公式ウェブサイトからOllamaをダウンロードします。インストールプロセスはオペレーティングシステムによって異なりますが、セットアップは簡単です。インストール後、ターミナルで基本的なコマンドを実行してインストールを確認します。
# Install Ollama (MacOS)
brew install ollama
# Start Ollama service
ollama serve
# Pull EXAONE model
ollama pull exaone
インストールが成功したら、EXAONEモデルを効果的に実行するようにOllamaを設定します。設定には、モデルウェイトのダウンロード、適切なメモリ割り当ての設定、および特定のハードウェアのパフォーマンスパラメータの最適化が含まれます。
EXAONEモデルをローカルで実行する
Ollamaのインストールが完了すると、EXAONEモデルのダウンロードは簡単になります。プロセスには、公式リポジトリからモデルウェイトをプルし、ランタイムパラメータを設定することが含まれます。異なるモデルサイズはさまざまなパフォーマンス特性を提供するため、特定の要件に基づいて選択してください。
# Pull specific EXAONE model version
ollama pull exaone-deep:7.8b
# Run model with custom parameters
ollama run exaone-deep:7.8b --temperature 0.5 --max-tokens 2048
ローカルデプロイメントは、カスタムファインチューニングの機会も提供します。上級ユーザーは、モデルパラメータを変更したり、推論設定を調整したり、特定のユースケースに合わせてパフォーマンスを最適化したりできます。この柔軟性により、EXAONEは研究アプリケーションや特殊な実装にとって特に魅力的です。
API統合方法とベストプラクティス
RESTful APIの実装
EXAONE APIは標準的なRESTful規約に従っており、ほとんどの開発者にとって統合が容易です。HTTP POSTリクエストはモデル推論を処理し、GETリクエストはモデル情報とステータスチェックを管理します。適切なエラー処理により、APIの制限やネットワークの問題を適切に管理する堅牢なアプリケーションが保証されます。
import requests
import json
def exaone_api_call(prompt, model_size="32b"):
url = "https://api.together.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": f"exaone-deep-{model_size}",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1500,
"temperature": 0.7,
"top_p": 0.9
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
高度な設定オプション
EXAONE APIは、出力品質とパフォーマンスに大きく影響するさまざまな設定パラメータをサポートしています。Temperatureは生成される応答のランダム性を制御し、top_pは核サンプリングの動作を管理します。Max_tokensは応答の長さを制限し、コストと応答時間の制御に役立ちます。
さらに、APIはシステムプロンプトをサポートしており、複数のリクエスト間で一貫した動作を可能にします。この機能は、特定のトーン、スタイル、またはフォーマットの一貫性を必要とするアプリケーションにとって特に価値があります。システムプロンプトは、会話スレッド全体でコンテキストを維持するのにも役立ちます。
Apidogを使用したEXAONE APIのテスト
効果的なAPIテストは開発を加速し、信頼性の高い統合を保証します。Apidogは、最新のAPIワークフロー向けに特別に設計された包括的なテスト機能を提供します。このプラットフォームは、自動テスト、リクエスト検証、およびパフォーマンス監視をサポートしています。
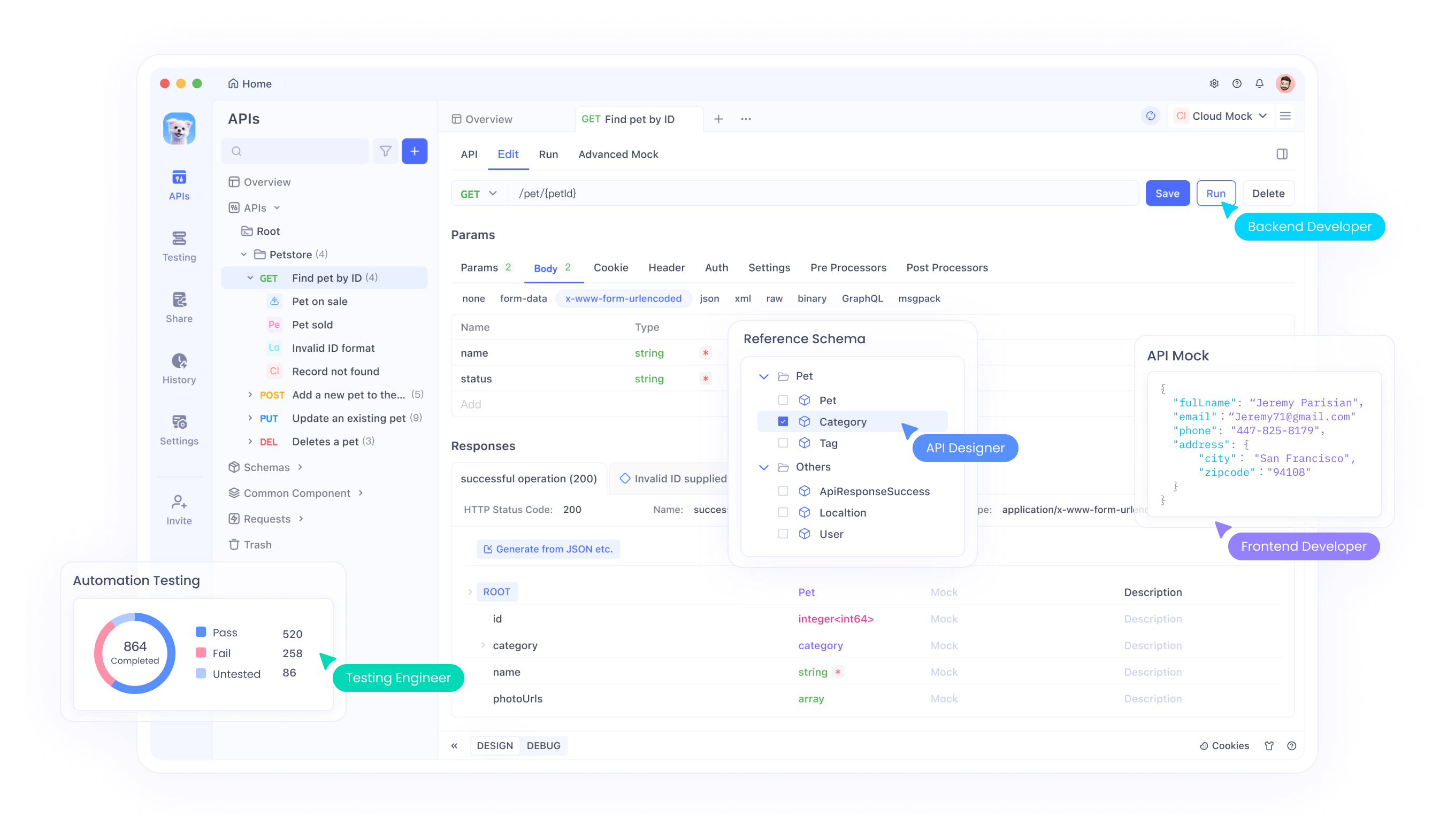
EXAONEテストのためのApidogのセットアップ
まず、Apidogアカウントを作成し、デスクトップアプリケーションをインストールします。このプラットフォームは、ウェブベースとデスクトップバージョンの両方を提供しており、それぞれ強力なテスト機能を提供します。デスクトップバージョンは、ローカルファイルのインポートや強化されたデバッグツールなどの追加機能を提供します。
新しいAPI仕様を作成して、EXAONE APIエンドポイントをApidogにインポートします。リクエストパラメータ、ヘッダー、および期待される応答形式を定義します。このドキュメントは、テスト設定とチームコラボレーションツールの両方として機能し、開発チーム全体で一貫したAPI使用を保証します。
包括的なテストスイートの作成
成功したリクエスト、エラー条件、エッジケースなど、さまざまなシナリオをカバーするテストスイートを開発します。APIの動作を徹底的に理解するために、異なるパラメータの組み合わせをテストします。Apidogのテスト自動化機能により、開発サイクル中の継続的な検証が可能になります。
{
"test_cases": [
{
"name": "Basic Text Generation",
"request": {
"method": "POST",
"url": "{{base_url}}/chat/completions",
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"model": "exaone-deep-32b",
"messages": [
{"role": "user", "content": "Explain quantum computing"}
],
"max_tokens": 500
}
},
"assertions": [
{"path": "$.choices[0].message.content", "operator": "exists"},
{"path": "$.usage.total_tokens", "operator": "lessThan", "value": 600}
]
}
]
}
パフォーマンス最適化戦略
リクエストのバッチ処理とキャッシング
インテリジェントなリクエストのバッチ処理と応答のキャッシングにより、APIのパフォーマンスを最適化します。バッチ処理はネットワークオーバーヘッドを削減し、キャッシングは同一のリクエストに対する冗長なAPI呼び出しを排除します。これらの戦略は、アプリケーションの応答性を大幅に向上させ、コストを削減します。
Redisまたは同様のテクノロジーを使用してキャッシング層を実装します。リクエストパラメータに基づいて応答をキャッシュし、キャッシュの無効化が適切に行われるようにします。アプリケーションの要件とデータの機密性に基づいてキャッシュの有効期限ポリシーを検討してください。
エラー処理と再試行ロジック
堅牢なエラー処理は、APIの問題が発生した場合のアプリケーションの障害を防ぎます。一時的なエラーには指数関数的バックオフ戦略を実装し、永続的なエラーは適切に処理します。レート制限管理により、サービスの中断なしにアプリケーションがAPIクォータ内に収まるようにします。
import time
import random
from typing import Optional
class ExaoneAPIClient:
def __init__(self, api_key: str, max_retries: int = 3):
self.api_key = api_key
self.max_retries = max_retries
def call_with_retry(self, prompt: str) -> Optional[str]:
for attempt in range(self.max_retries):
try:
response = self._make_api_call(prompt)
return response
except Exception as e:
if attempt == self.max_retries - 1:
raise e
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
return None
def _make_api_call(self, prompt: str) -> str:
# Implementation details for actual API call
pass
実世界での実装例
EXAONEによるチャットボット開発
EXAONE APIを使用して会話型AIアプリケーションを構築するには、慎重なプロンプトエンジニアリングとコンテキスト管理が必要です。単純なgpt-ossの代替手段とは異なり、EXAONEの高度な推論機能により、より洗練された対話システムが可能になります。
複数のやり取りでコンテキストを維持するために、会話履歴管理を実装します。トークン制限を管理してコストを制御しながら、会話の状態を効率的に保存します。長時間のチャットセッションの場合、会話の要約を実装することを検討してください。
コンテンツ生成アプリケーション
EXAONEは、技術文書、クリエイティブライティング、コード生成など、さまざまなコンテンツ生成タスクに優れています。APIのバイリンガル機能により、国際的なコンテンツ作成ワークフローに特に適しています。
class ContentGenerator:
def __init__(self, exaone_client):
self.client = exaone_client
def generate_blog_post(self, topic: str, target_language: str = "en") -> str:
prompt = f"""
Write a comprehensive blog post about {topic}.
Language: {target_language}
Requirements:
- Include introduction, main content, and conclusion
- Use engaging tone and clear structure
- Target length: 800-1000 words
"""
return self.client.generate(prompt, max_tokens=1200)
def generate_code_documentation(self, code_snippet: str) -> str:
prompt = f"""
Generate comprehensive documentation for this code:
{code_snippet}
Include:
- Function purpose and behavior
- Parameter descriptions
- Return value explanation
- Usage examples
"""
return self.client.generate(prompt, max_tokens=800)
EXAONEと代替ソリューションの比較
従来のGPTモデルに対する利点
EXAONEは、従来のGPT実装やgpt-ossの代替手段と比較して、いくつかの利点を提供します。ハイブリッドアテンションアーキテクチャは、より優れた長文コンテキスト理解を提供し、推論モードはより正確な問題解決能力を可能にします。
コスト効率は、もう1つの重要な利点です。ローカルデプロイメントオプションはトークンごとの課金を排除するため、EXAONEは大量のアプリケーションにとって経済的です。さらに、プライバシーの利点は、機密データを扱う組織にとって魅力的です。
統合の柔軟性
一部のプロプライエタリなソリューションとは異なり、EXAONEは複数のデプロイメントパターンをサポートしています。特定の要件に基づいて、クラウドAPI、ローカルインストール、またはハイブリッドアプローチの中から選択できます。この柔軟性により、さまざまな組織の制約や技術的嗜好に対応できます。
一般的な問題のトラブルシューティング
接続と認証の問題
ネットワーク接続の問題と認証エラーは、一般的な統合の課題です。APIエンドポイントを確認し、認証資格情報をチェックし、適切なヘッダー設定を確保してください。ネットワークデバッグツールは、接続の問題を迅速に特定するのに役立ちます。
APIレート制限を注意深く監視してください。クォータを超過すると一時的なブロックが発生します。サービスの中断を防ぐために、アプリケーションに適切なレート制限を実装してください。より高い制限が必要になった場合は、APIプランのアップグレードを検討してください。
モデルパフォーマンスの最適化
モデルの応答が一貫しない、または低品質に見える場合は、プロンプトエンジニアリングの技術を見直してください。EXAONEは、適切なコンテキストを持つ明確で具体的な指示によく応答します。希望する出力特性を達成するために、異なるtemperatureとtop_pの値を試してください。
要件に基づいてモデルサイズの選択を検討してください。大規模なモデルはより優れたパフォーマンスを提供しますが、より多くのリソースと処理時間が必要です。リソースの制約と応答時間の要件に対して、パフォーマンスのニーズのバランスを取ってください。
セキュリティに関する考慮事項とベストプラクティス
APIキー管理
安全なAPIキーの保存は、不正アクセスや潜在的なセキュリティ侵害を防ぎます。キーの保存には、環境変数、セキュアなボールト、または構成管理システムを使用してください。APIキーをバージョン管理システムにコミットしたり、クライアントサイドのコードに公開したりしないでください。
セキュリティリスクを最小限に抑えるために、キーローテーションポリシーを実装してください。定期的なキーの更新は、侵害が発生した場合のエクスポージャー期間を短縮します。セキュリティ上の問題を示す可能性のある異常なアクティビティを検出するために、APIの使用パターンを監視してください。
データプライバシーとコンプライアンス
EXAONE APIを通じて機密データを処理する場合、データプライバシーへの影響を慎重に検討してください。ローカルデプロイメントオプションは最大限のプライバシー制御を提供しますが、クラウドデプロイメントではデータ処理ポリシーの慎重な評価が必要です。
APIリクエストの前に機密情報を削除するために、データサニタイズ手順を実装してください。非常に機密性の高いアプリケーションには、追加の暗号化層の実装を検討してください。業界および地理的な場所固有のコンプライアンス要件を確認してください。
将来の開発とロードマップ
今後の機能
LG AI ResearchはEXAONEの機能開発を継続しており、定期的なモデルの更新と機能強化を行っています。今後のリリースには、追加の言語サポート、推論能力の向上、ツール統合機能の強化などが含まれる可能性があります。
公式ドキュメントとコミュニティチャネルを通じてAPIの変更に関する情報を入手してください。新しいモデルバージョンが利用可能になったら、移行パスを計画してください。本番デプロイメントの前に、新しいバージョンを徹底的にテストしてください。
コミュニティとエコシステムの成長
EXAONEエコシステムは、コミュニティの貢献、サードパーティの統合、および特殊なツールによって拡大し続けています。コミュニティの議論に積極的に参加することで、ベストプラクティスと新しいユースケースに関する洞察が得られます。
EXAONE統合に関連するオープンソースプロジェクトへの貢献を検討してください。経験とソリューションを共有することは、開発者コミュニティ全体に利益をもたらし、すべての人にとってプラットフォームを改善する可能性があります。
結論
EXAONE APIは、高度なAI統合オプションを求める開発者にとって強力な機能を提供します。ローカルデプロイメントの柔軟性から洗練された推論機能まで、EXAONEは主流のソリューションに代わる魅力的な選択肢を提供します。包括的なデプロイメントオプション、堅牢なパフォーマンス特性、および成長するエコシステムにより、EXAONEはさまざまなアプリケーションシナリオにとって優れた選択肢となります。
EXAONE APIでの成功は、適切なセットアップ、思慮深い統合計画、および継続的な最適化にかかっています。効率的なテストおよびデバッグワークフローのためにApidogのようなツールを使用してください。セキュリティのベストプラクティスに従い、プラットフォームの更新に関する情報を入手して、実装の効果を最大限に高めてください。