
開発者や研究者は、自律エージェントを動かすために推論を優先するモデルを求めています。DeepSeek-V3.2とその特殊なバリアントであるDeepSeek-V3.2-Specialeは、このニーズに正確に応えます。これらのモデルは、DeepSeek-V3.2-Expのような以前のイテレーションに基づいて構築されており、論理推論、数学的問題解決、およびエージェントワークフローにおける強化された機能を提供します。エンジニアは今、主要なクローズドソースシステムが設定したベンチマークを上回り、複雑なクエリを効率的に処理するツールにアクセスできるようになりました。
これらのモデルを検討するにあたり、その技術的メリットに焦点が当てられます。まず、オープンソースの基盤は幅広い実験を可能にします。次に、APIアクセスはスケーラブルなデプロイメントオプションを提供します。この記事全体を通して、公式ソースからのデータとベンチマークがその可能性を示しています。
DeepSeek-V3.2のオープンソース化:協調的なAI開発の基盤
DeepSeekは、AIコミュニティ全体での幅広い採用を促進するため、寛容なMITライセンスの下でDeepSeek-V3.2をリリースしました。この決定により、開発者は制約的な障壁なしにモデルを検査、修正、デプロイすることが可能になります。結果として、チームは自動コード生成から多段階推論パイプラインまで、エージェントアプリケーションにおけるイノベーションを加速させることができます。
このモデルのアーキテクチャは、長文コンテキスト処理の計算要件を最適化するメカニズムであるDeepSeek Sparse Attention(DSA)を中心に据えています。DSAは、きめ細かいスパース性を採用し、出力品質を維持しながら、アテンションの複雑さを二次からほぼ線形に削減します。例えば、128,000トークンを超えるシーケンス(数百ページ分のテキストに相当)においても、モデルはより小型のモデルに匹敵する推論速度を維持します。
DeepSeek-V3.2は、BF16、F8_E4M3、F32といったテンソルタイプに分散された6850億のパラメータを備え、柔軟な量子化に対応しています。トレーニングには、エージェントが合成タスクでの反復的なフィードバックを通じて学習する、スケーラブルな強化学習(RL)フレームワークが組み込まれています。このアプローチにより、推論パスが洗練され、モデルは論理ステップを効果的に連鎖させることができます。さらに、大規模なエージェントタスク合成パイプラインが多様なシナリオを生成し、推論とツール呼び出しを融合させます。開発者は、これらの事前学習済み重みとベースモデルが格納されているHugging Faceのリポジトリを通じてこれらにアクセスできます。
使用は、モデルのエンコーディングディレクトリにあるPythonスクリプトによって容易にされる、OpenAI互換形式での入力エンコーディングから始まります。チャットテンプレートには、モデルが行動する前に熟考する「ツールと共に思考する」モードが導入されています。サンプリングパラメータ(温度1.0、top_p 0.95)は、一貫性がありながらも創造的な出力を生成します。ローカルデプロイメント向けには、DeepSeek-V3.2-ExpのGitHubリポジトリが、多様なGPUエコシステムに対応するTileLangバリアントを含むCUDA最適化された演算子を提供しています。
さらに、MITライセンスは企業の実行可能性を保証します。組織は、法的障害なしに独自のエージェント向けにモデルをカスタマイズできます。ベンチマークはこのオープン性を検証しており、技術レポートに詳述されているように、DeepSeek-V3.2は集計された推論スコアでGPT-5と同等の性能を達成しています。したがって、オープンソース化はアクセスを民主化するだけでなく、プロプライエタリな巨大企業に対してもベンチマークを設定します。
DeepSeek-V3.2-Speciale:高度な推論要求のための専用強化
DeepSeek-V3.2は汎用目的を果たしますが、DeepSeek-V3.2-Specialeは深い推論に特化しています。このバリアントは、同じ685Bパラメータのベースに高計算量の後処理トレーニングを適用し、抽象的な問題解決能力を増幅させます。その結果、2026年の国際数学オリンピック(IMO)と国際情報オリンピック(IOI)で金メダル相当の成績を収め、提出された解答において人間のベースラインを上回りました。
アーキテクチャ的には、DeepSeek-V3.2-Specialeは、効率的な長文コンテキスト処理のためにDSAを備えた兄弟モデルを模倣しています。しかし、後処理トレーニングでは、オリンピック問題や合成エージェントチェーンを含む厳選されたデータセットでの強化学習に重点が置かれています。このプロセスは、モデルがクエリを検証可能なステップに分解する思考連鎖(CoT)推論を磨きます。特筆すべきは、ツール呼び出しのサポートを省略し、純粋な推論にリソースを集中させることで、定理証明のような計算集約型タスクに理想的です。
Hugging Faceのモデルカードは違いを強調しています。DeepSeek-V3.2-Specialeは、外部依存関係なしに入力を処理し、内部的な熟考に依存します。開発者は同様にメッセージをエンコードしますが、Jinjaテンプレートがないため、出力にはカスタム解析が必要です。不正な形式の応答には検証レイヤーが必要となるため、本番コードでのエラー処理が重要になります。
比較において、DeepSeek-V3.2-Specialeは推論集計でGPT-5-Highを上回り、Gemini-3.0-Proと同等です。例えば、AIME 2026 (Pass@1)では93.1%を記録し、Claude-4.5-Sonnetの90.2%をわずかに上回っています。これらの向上は、論理連鎖を強化するために敵対的なシナリオをシミュレートするターゲットRLに由来しています。結果として、研究者はICPC World Finalsのコード検証やCMO 2026の証明といった最先端のタスクにこれを導入しており、アセットはリポジトリで入手可能です。
全体として、DeepSeek-V3.2-Specialeはエコシステムの範囲を広げます。それは、幅よりも深さが重要となるエッジケースを処理することでベースモデルを補完し、エージェントビルダーに包括的なカバレッジを保証します。
推論およびエージェント機能のベンチマーク:データ駆動型インサイト
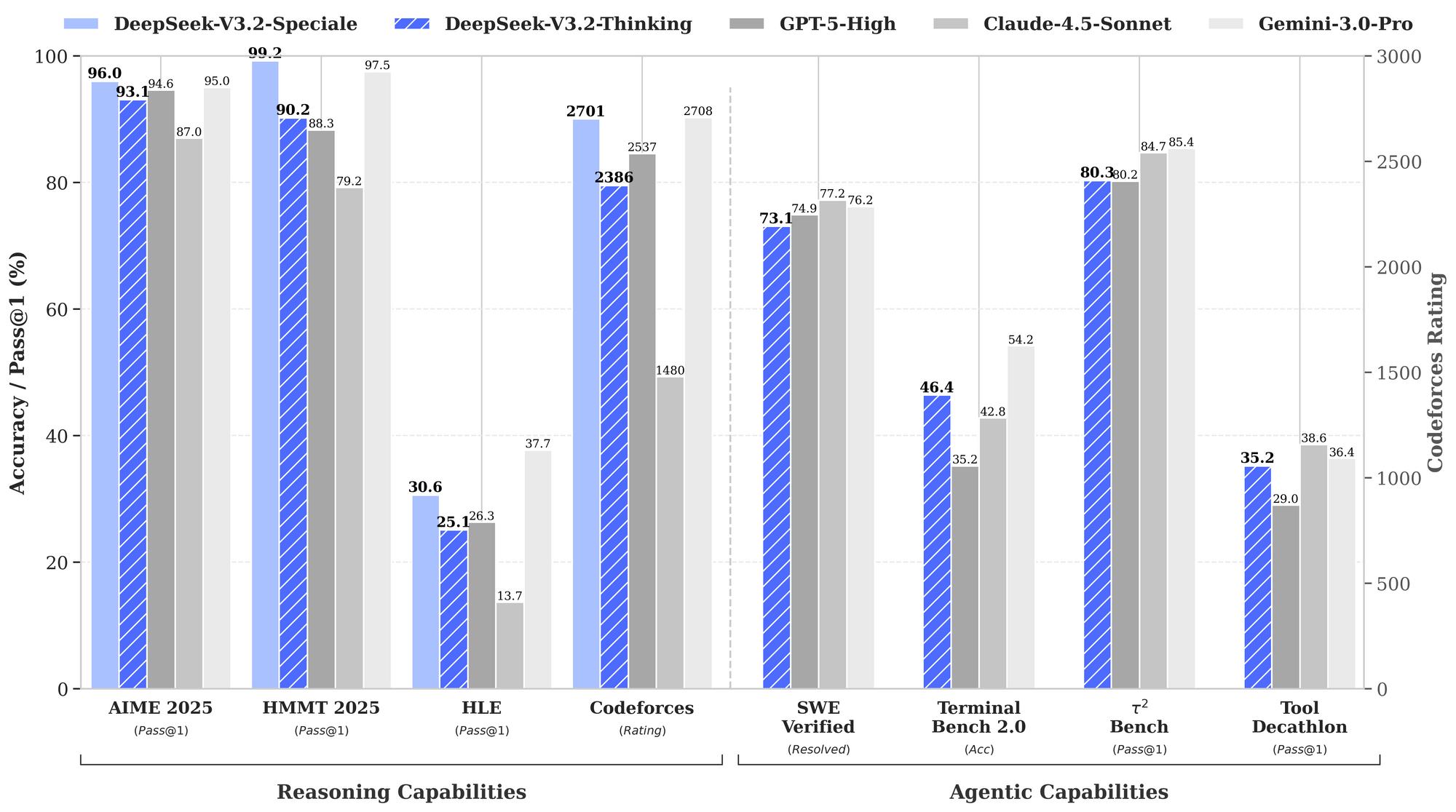
ベンチマークは、特に推論とエージェント領域におけるDeepSeek-V3.2の強みを定量化します。提供されているパフォーマンスグラフは、主要な評価における合格率と精度を示し、これらのモデルをGPT-5-High、Claude-4.5-Sonnet、Gemini-3.0-Proと比較して位置づけています。
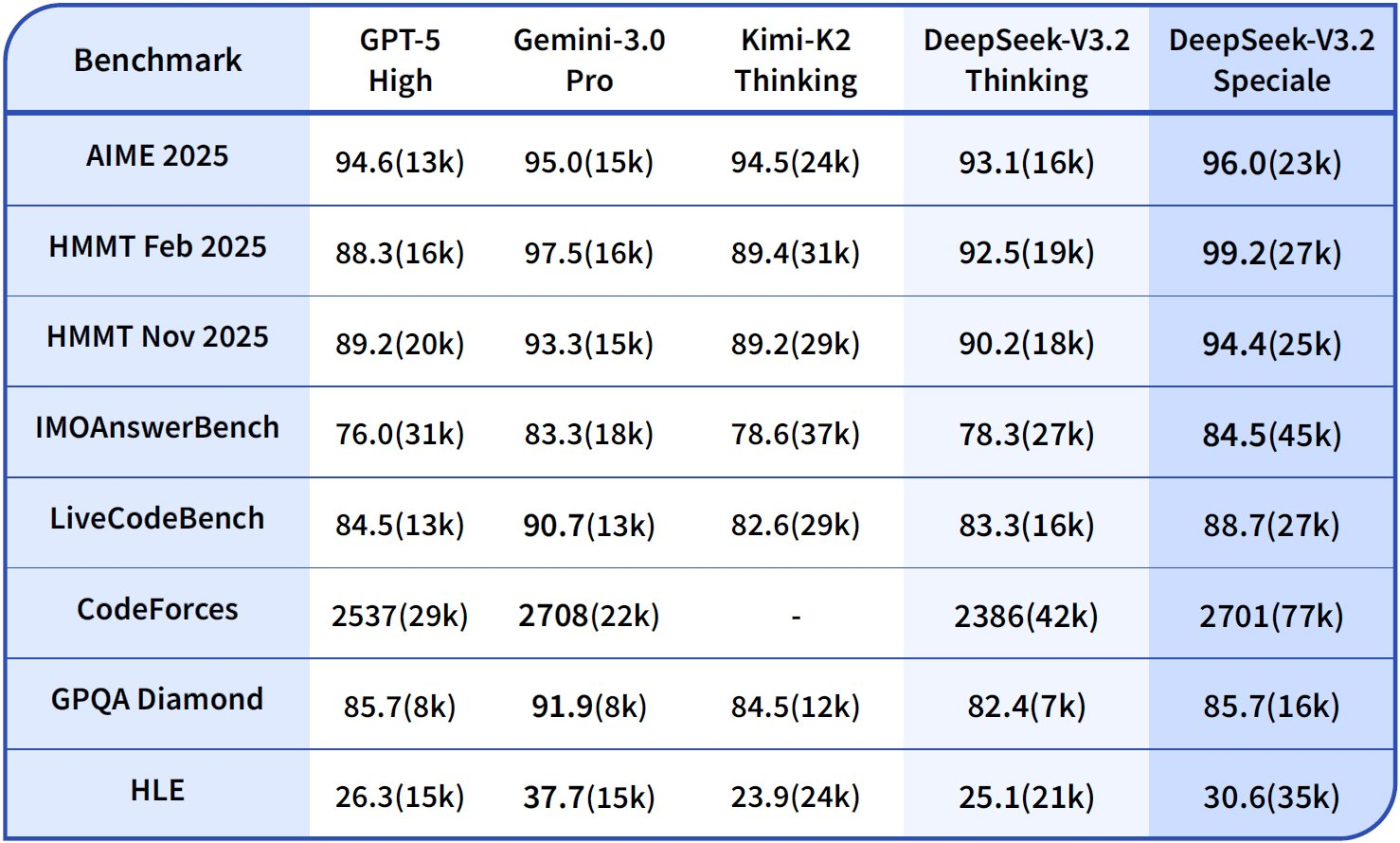
推論能力において、DeepSeek-V3.2-Thinking(Specialeに似た高計算構成)はAIME 2026 (Pass@1)で93.1%を記録し、GPT-5-Highの90.8%およびClaude-4.5-Sonnetの87.0%を上回っています。同様に、HMMT 2026では94.6%を達成し、優れた数学的分解能力を反映しています。HLE評価では95.0%のpass@1を示し、モデルは最小限のリトライで高レベルの英語論理パズルを解決しています。
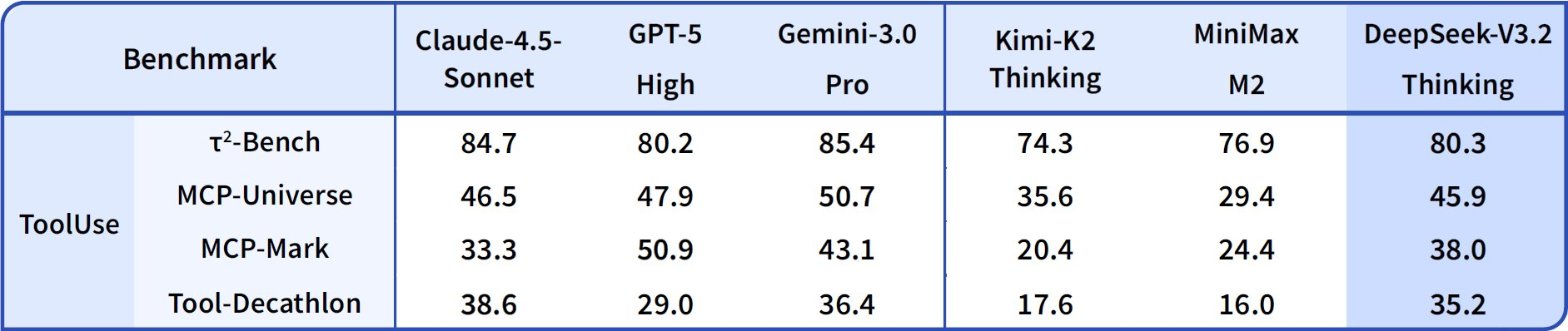
エージェント能力に移行すると、DeepSeek-V3.2はコーディングとツール使用において優れています。ThinkingモードでのCodeforcesレーティングは2708に達し、Gemini-3.0-Proの2537を上回ります。この指標は、時間制約の下で解決された問題を合計し、アルゴリズムの効率性を強調します。SWE-Verified(解決済み)では73.1%を達成し、検証済みコードベースでの信頼性の高いバグ検出と修正生成を示しています。
Terminal Bench 2.0の精度は80.3%で、モデルは自然言語コマンドを介してシェル環境をナビゲートします。T² (Pass@1)は84.8%を記録し、データ取得や合成のようなツール拡張タスクを評価します。ツール評価は84.7%に達し、モデルはAPIを呼び出し、応答を正確に解析しています。
DeepSeek-V3.2-Specialeは、純粋な推論サブセットにおいてこれらの能力を増幅させます。例えば、AIMEでは99.2%、HMMTでは99.0%に向上し、オリンピック形式の数学では完璧に近づいています。しかし、ツールサポートなしではエージェントスコアが低下します(例:Toolが73.1%に対しベースモデルは84.7%)。これは、統合よりも深さを優先した結果です。
これらの結果は標準化されたプロトコルに基づいています。Pass@1は一発の成功を測定し、レーティングはEloのようなスケーリングを取り入れています。ベースラインと比較して、DeepSeekモデルはオープンソースのギャップを埋め、DSAは長文コンテキストで50%の計算コスト削減を可能にします。したがって、ベンチマークは主張を検証するだけでなく、選択を導きます。バランスの取れたエージェントにはV3.2を、集中的なロジックにはSpecialeを使用する、といった具合です。
| ベンチマーク | 指標 | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2026 | Pass@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2026 | Pass@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | Pass@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | 評価 | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | 解決済み (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | 精度 (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | Pass@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| ツール | Pass@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
この表はグラフデータを集計したもので、推論における一貫したリーダーシップと、エージェンシーにおける競争力を示しています。
DeepSeek APIへのアクセス:スケーラブルなデプロイメントのためのシームレスな統合
オープンソースの重みはローカルでの実行を促しますが、APIアクセスは本番エージェントを容易にスケールさせます。DeepSeek-V3.2は、公式APIとアプリおよびウェブインターフェースを介してデプロイされます。開発者はプラットフォームダッシュボードからAPIキーで認証し、OpenAI互換のJSONでエンドポイントを照会します。
DeepSeek-V3.2-Specialeの場合、アクセスはAPIのみに限定され、ローカルのオーバーヘッドなしに高い計算能力のニーズに対応します。エンドポイントはツールのような呼び出しパラメータをサポートしますが、Specialeはツールなしで推論を処理します。コンテキストウィンドウは128,000トークンまで拡張され、キャッシュヒットによって繰り返されるクエリが最適化されます。
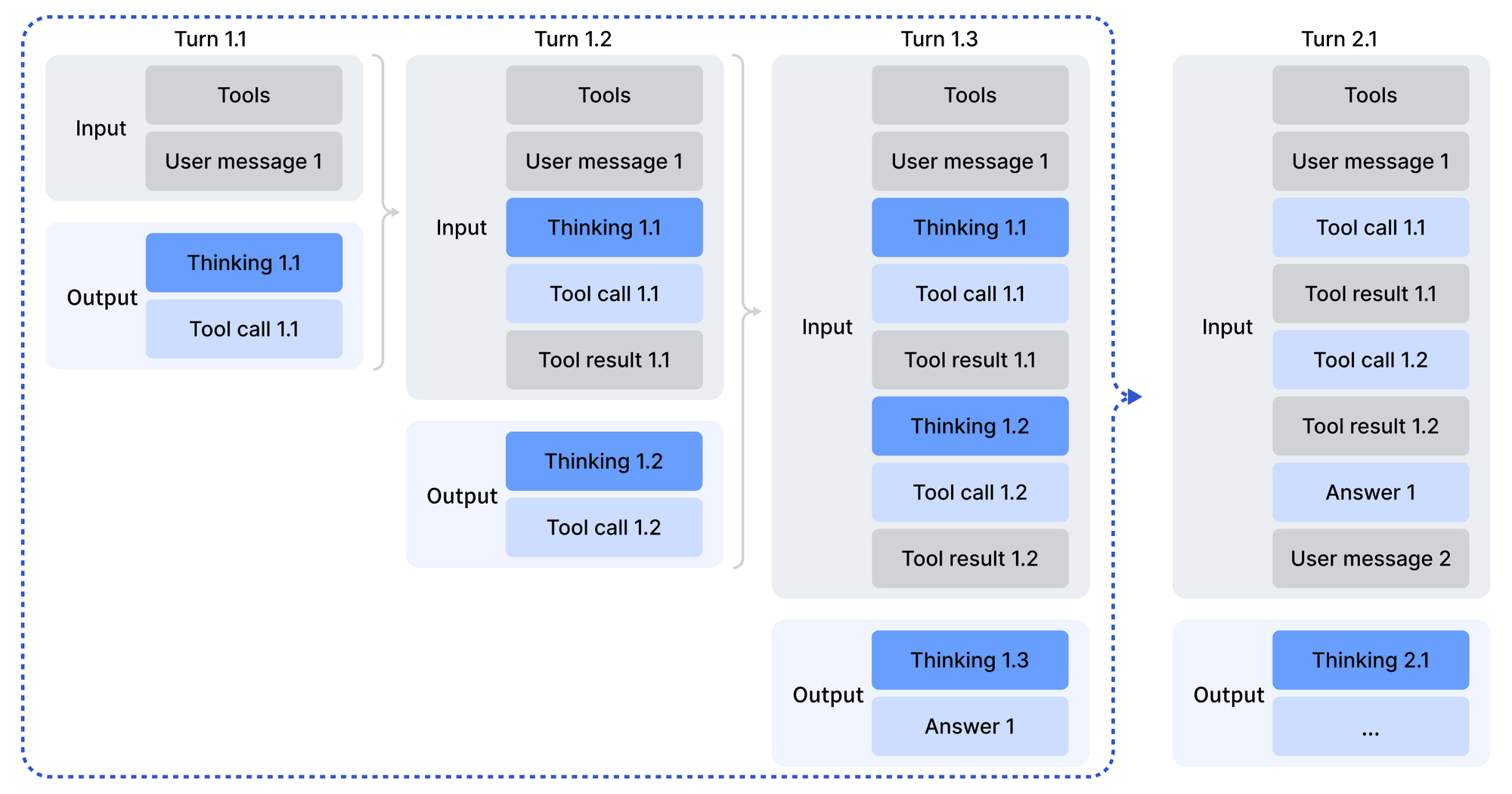
統合は、Python、Node.js、cURLのSDKを活用します。サンプル呼び出しは、エージェントシナリオのために開発者ロールでプロンプトをエンコードします。
import openai
client = openai.OpenAI(
api_key="your_deepseek_key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "このIMO問題を解いてください: ..."}],
temperature=1.0,
top_p=0.95
)
この構造は、提供されたスクリプトを介して出力を解析し、該当する場合はツール呼び出しを処理します。結果として、エージェントは推論の途中で外部サービスを呼び出し、応答を連鎖させます。
このワークフローを強化するために、Apidogは非常に貴重です。API応答のモック、スキーマの文書化、エッジケースのテストを行い、これらはDeepSeekのエンドポイントに直接適用可能です。Apidogを無料でダウンロードして、リクエストフローを視覚化し、デプロイメント前に堅牢なエージェントロジックを確保してください。
API価格設定:コスト効率と高性能の両立
DeepSeekのAPI価格設定は手頃な価格を重視しており、V3.2-ExpのリリースによりV3.1-Terminusからコストが半減しました。開発者は100万トークンあたりで支払い、入力キャッシュヒットで$0.028、ミスで$0.28、出力で$0.42です。この構造は、エージェントのループにとって不可欠な繰り返されるコンテキストに対して報酬を与えます。
競合他社と比較して、これらの料金はGPT-5の100万出力あたり$15~$75を大きく下回ります。キャッシュメカニズム(ミスコストの10%でヒット)により、経済的な長時間のセッションが可能になります。10,000トークンのエージェントインタラクション(80%キャッシュヒット)の場合、コストは$0.01未満にまで下がり、線形にスケーリングします。
無料ティアは初期アクセスを提供し、開発者向けには従量課金制に移行します。エンタープライズプランは量をカスタマイズしますが、ほとんどの場合は基本料金で十分です。したがって、価格設定はオープンソースの精神と一致しており、高度な推論を民主化しています。
計算機によると、100万入力トークン(50%ヒット)と20万出力の場合、合計は約$0.20となり、他の選択肢と比較してごくわずかです。この効率性により、コードレビューからデータ合成まで、大量のタスクを実行できます。
技術詳細:アーキテクチャとトレーニングの革新
DSAが核となり、アテンション行列を動的にスパース化します。位置iでは、ローカルウィンドウとグローバルキーに注目し、100kコンテキストでFLOPを40%削減します。F8_E4M3への量子化は、精度を損なうことなくメモリを半減させ、8x A100のデプロイメントを可能にします。

トレーニングは、10兆トークンでの事前学習、教師付きファインチューニング、およびエージェント報酬によるRLHFにまたがります。合成パイプラインは100万以上のタスクを生成し、現実世界のエージェントの動作をシミュレートします。Specialeの後処理トレーニングでは、計算リソースが10倍に割り当てられ、軌跡から推論が抽出されます。
これらの革新は、HLEの失敗の85%での自己修正やT²でのツール成功率92%といった新たな挙動を生み出します。将来のイテレーションでは、ロードマップに従ってマルチモダリティが組み込まれる可能性があります。
結論:エージェントの未来に向けたDeepSeekの位置づけ
DeepSeek-V3.2とDeepSeek-V3.2-Specialeは、オープンソースの推論を再定義します。ベンチマークはその優位性を確認し、オープンアクセスは協業を促し、手頃な価格のAPIはスケールを可能にします。開発者は、オリンピックの問題解決者から企業の自動化ツールまで、優れたエージェントを構築します。
AIが進化するにつれて、これらのモデルは前例を確立します。今すぐ実験を始めましょう — Hugging Faceから重みをダウンロードし、API経由で統合し、Apidogでテストしてください。インテリジェントシステムへの道はここから始まります。


