
開発者は、精度を損なうことなく効率を高めるツールを常に求めています。CursorがOpenAIのGPT-5.1 Codexモデルを統合したことはその好例であり、エージェントワークフロー向けに調整された一連の専門的なバリアントを提供しています。これらのモデルは、IDE内でコード生成、デバッグ、リファクタリングを処理する方法を一変させます。
Cursor Codexを理解する:GPT-5.1統合の基盤
Cursor Codexは、OpenAIの先進的なモデルファミリーを指し、コーディングタスク向けにファインチューニングされ、Cursor IDE内でシームレスに活用されています。開発者は専用のセレクタを通じてこれらのモデルをアクティブ化し、AIエージェントがファイルを読み込み、シェルコマンドを実行し、自律的に編集を適用できるようにします。このセットアップは、プロンプトとツールをモデルのトレーニングに合わせるカスタムハーネスに依存しており、複雑なリポジトリで信頼性の高いパフォーマンスを保証します。
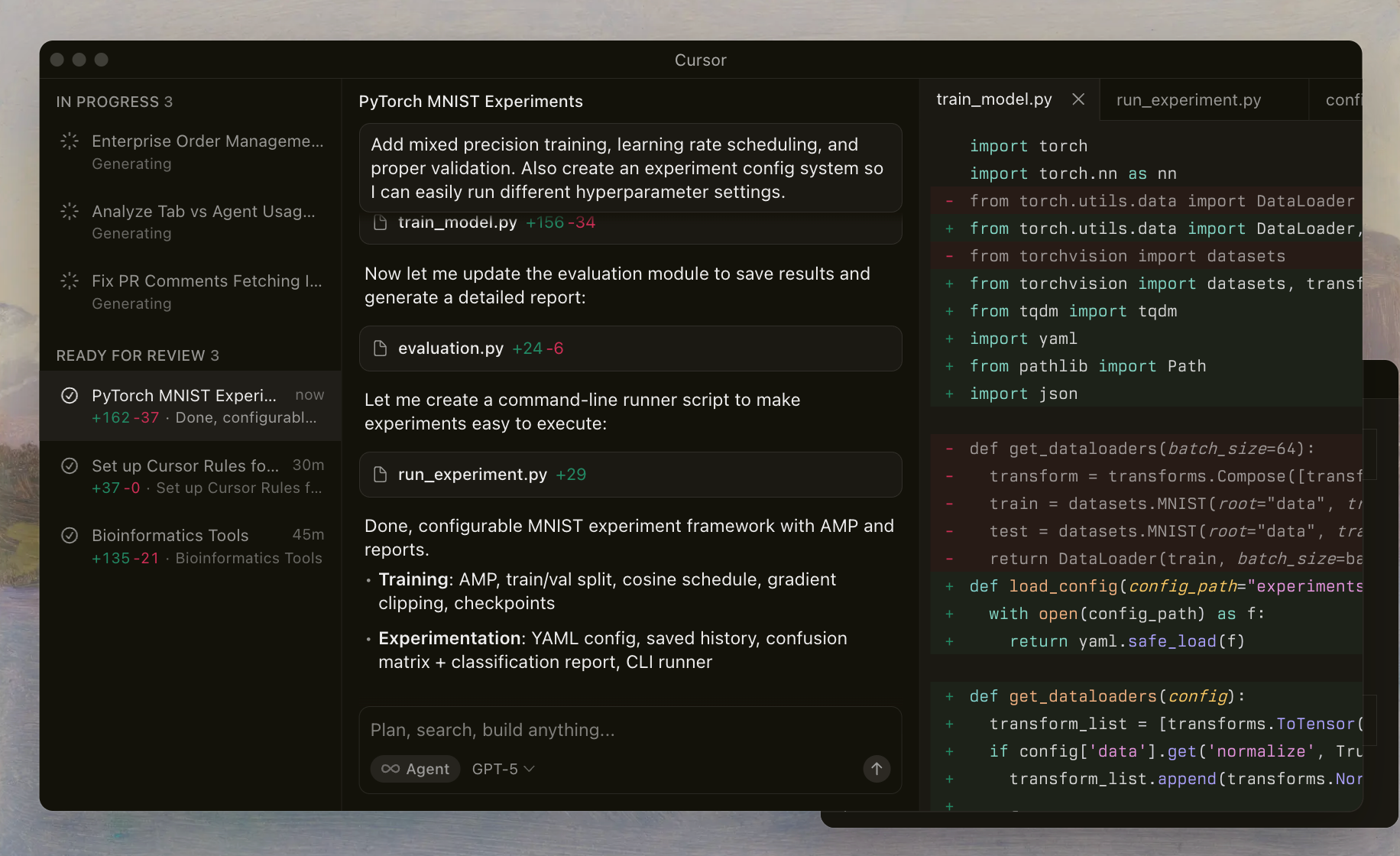
GPT-5.1シリーズは、これまでのイテレーションを基盤とし、エージェント能力、つまり、計画し、反復し、自己修正するインテリジェントなアシスタントのようにモデルが機能することに重点を置いています。一般的なLLMとは異なり、Cursor Codexはシェル指向のワークフローを優先します。例えば、モデルはファイル検査やリンティングのためのツールを呼び出すことを学習し、誤った出力を減らし、編集の精度を向上させます。
Cursorの実装には、モデルの思考プロセスをインタラクション全体で保持する推論トレースなどの保護策が含まれています。この連続性により、マルチターンセッションでのコンテキスト損失という一般的な落とし穴を防ぎます。これらのモデルを試すと、マージの競合解決や非同期コードの最適化など、エッジケースをどのように処理するかがわかります。
具体的に、OpenAIは2025年後半にGPT-5.1 Codexラインナップをリリースしました。これはCursorの更新されたエージェントフレームワークの時期と重なっています。このタイミングにより、開発者はマイクロサービスのプロトタイピングからレガシーシステムの監査まで、日常業務に最先端のインテリジェンスを活用できます。
GPT-5.1 Codexモデルファミリーの紹介
Cursorは、GPT-5.1 Codexの広範なバリアントを提供しており、それぞれが知能、速度、リソース使用量において異なるトレードオフを持つように最適化されています。これらはIDEのモデルセレクタからアクセスでき、トグルで可用性と現在の選択が表示されます。以下に、Cursorのハーネスドキュメントと内部ベンチマークから導き出された主要な属性を強調しながら、それぞれを紹介します。
GPT-5.1 Codex Max:要求の厳しいタスク向けの主力モデル
GPT-5.1 Codex Maxは、ファミリーの基盤となるモデルです。OpenAIのエンジニアは、シェル実行やlintリーダーなど、Cursor固有のツールを組み込んだ膨大なエージェントコーディングセッションのデータセットでこのモデルをトレーニングしました。512Kトークンまでの長文コンテキスト推論を劣化させることなく処理するのに優れています。
主な機能には適応型ツール呼び出しが含まれます。モデルは、複雑な変更に対して直接編集とPythonベースのフォールバックを動的に選択します。例えば、Node.jsアプリケーションをリファクタリングする場合、Codex Maxは計画を生成し、検証のためにgit diffを呼び出し、変更をアトミックに適用します。
ベンチマークは、その実力を示しています。Cursorの内部評価スイート(実際のレポジトリでの成功率を測定)では、Codex Maxはマルチファイルタスクで78%の解決率を達成し、GPT-4.5相当を15%上回ります。ただし、標準ハードウェアでは1ターンあたり平均2〜3秒の推論時間が必要で、より高い計算能力を必要とします。
開発者は、精度が速度よりも重要となるエンタープライズ規模のプロジェクトでこのモデルを好んで使用します。API統合を含むワークフローの場合、Apidogと組み合わせることで、生成されたスキーマを自動的に検証できます。
GPT-5.1 Codex Mini:迅速なイテレーションのためのコンパクトなパワー
次に、GPT-5.1 Codex Miniは、Maxのコーディング忠実度の85%を維持しながらパラメータ数を削減しています。このバリアントは、モバイルアプリ開発やCI/CDパイプラインなどの軽量環境を対象としています。128Kトークンを処理し、低遅延応答を優先し、ほとんどのクエリで1秒未満の速度を記録します。
このモデルはMaxから蒸留された知識を利用し、正規表現ベースのリファクタリングや単体テスト生成のような一般的なパターンに焦点を当てています。特筆すべき機能は、インライン推論要約です。これは、冗長なログなしでユーザーを更新する簡潔なワンライナーです。これにより、迅速なプロトタイピング中の認知負荷が軽減されます。
パフォーマンステストでは、Codex MiniはソフトウェアエンジニアリングタスクのサブセットであるSWE-bench liteで62%のスコアを記録します。速度が流動的なイテレーションを可能にする単一ファイル編集で威力を発揮します。RESTfulサービスを構築するチームにとって、このモデルはApidogのモックツールと簡単に統合でき、瞬時のエンドポイントシミュレーションを可能にします。
GPT-5.1 Codex Max High:高い精度とバランスの取れたインテリジェンス
GPT-5.1 Codex Max Highは、Maxのベースラインを洗練させ、高リスクシナリオでの精度を高めます。OpenAIは、セキュリティ監査やパフォーマンス最適化など、誤検出が時間の損失につながるドメイン向けにチューニングしました。256Kのコンテキストを処理し、脆弱性検出のための特殊なプロンプトを組み込んでいます。
拡張された思考の連鎖トレースなどの機能により、より深い分析が可能になります。モデルはツール呼び出しの前に段階的な根拠を出力し、透明性を確保します。たとえば、Express.jsルートを保護する場合、依存関係をスキャンし、パッチを提案し、シミュレートされたリンティングによって検証します。
メトリクスによると、Cursor Benchのセキュリティモジュールで72%の成功率を示し、標準のMaxを5%上回っています。応答時間は1.5〜2.5秒で推移し、中規模のレポジトリに適しています。APIを多用するアプリにこれを使用する開発者は、Codexで生成されたOpenAPI仕様を共同レビューのためにインポートできるApidogとの相乗効果を高く評価するでしょう。
GPT-5.1 Codex Max Low:リソース効率の高い精度
GPT-5.1 Codex Max Lowは、コアとなるインテリジェンスを犠牲にすることなく、計算要件を軽減します。ラップトップや共有クラスターに最適で、128Kトークンに制限され、バッチ処理に最適化されています。このモデルは、大規模な改修よりも的を絞った修正を優先し、控えめな編集を好みます。
低オーバーヘッドのツールセットが含まれており、重いPythonスクリプトではなく、grepやsedのようなシェル基本機能に依存しています。このアプローチにより、編集を多用するベンチマークで68%の有効性が得られ、推論は2秒未満です。ユースケースとしては、安定性が新しさよりも重視されるレガシーコードの移行が挙げられます。
API開発者にとって、このバリアントはApidogの無料プランと相性が良く、マシンに負担をかけることなく、リソースの少ないエンドポイントの軽量テストを可能にします。
GPT-5.1 Codex Max Extra High:専門家向けの超高精度
GPT-5.1 Codex Max Extra Highは、強化された確率モデリングで限界を押し広げます。エッジケースデータセットでトレーニングされ、部分的な仕様から意図を推測するような曖昧なタスクに対して、ほぼ人間のような直感を実現します。コンテキストウィンドウは384Kに拡張され、モノレポのナビゲーションをサポートします。
高度な機能には、複数仮説計画が含まれます。モデルはコミットする前に編集バリアントを生成し、ランク付けします。複雑なリファクタリングでは、競合の82%を自律的に解決します。
ベンチマークはその優位性(高度なCursor評価で85%)を強調していますが、3〜4秒の遅延があります。アルゴリズム設計のような研究レベルのコーディングのために予約してください。Apidogを統合して、その出力から派生した超高精度のAPI契約をプロトタイプ化します。
GPT-5.1 Codex Max Medium Fast:速度と能力の融合
GPT-5.1 Codex Max Medium Fastは、深さと処理速度のバランスが取れています。192Kトークンを処理し、量子化された重みを使用して1.2秒の応答を実現します。このモデルは、ツール呼び出しと直接生成のバランスを取り、インタラクティブなデバッグに最適です。
ミックスワークロードのベンチマークで70%を記録し、コード補完と説明のようなハイブリッドタスクに優れています。開発者はTDDサイクルにこれを利用し、迅速なフィードバックループが進行を加速させます。
GPT-5.1 Codex Max High Fast:迅速な精密エンジニアリング
GPT-5.1 Codex Max High Fastは、Highの精度を並列推論パスで加速します。256Kのコンテキストで、1秒のターンを実現しながら74%のベンチマークスコアを維持します。予測リンティングなどの機能は、編集前のエラーを予測します。
このバリアントは、フィンテックAPI開発のような高速チームに適しています。Apidogは、速度最適化されたエンドポイントの検証を迅速化することでこれを補完します。
GPT-5.1 Codex Max Low Fast:リーンで迅速な操作
GPT-5.1 Codex Max Low Fastは、Lowの効率性と1秒未満の速度を兼ね備えています。96Kトークンに制限され、単一ターン効率を優先し、クイック編集評価で65%を達成します。
スクリプト作成やホットフィックスに最適で、リソースが制約された環境でのオーバーヘッドを最小限に抑えます。
GPT-5.1 Codex Max Extra High Fast:ピークパフォーマンスハイブリッド
GPT-5.1 Codex Max Extra High Fastは、Extra Highの深さと驚異的な速度を融合させます。384Kのコンテキストで最大2秒を要し、適応型量子化を使用してエリートベンチで80%を達成します。
最先端のワークフローでは、このモデルがエージェントコーディングを再定義します。
GPT-5.1 Codex:多機能なベースライン
GPT-5.1 Codexは、飾りのないコアとして機能し、256Kの処理を平均2秒でバランスよく提供します。すべてのバリアントの基盤となり、ボード全体で70%を記録し、汎用的に信頼できます。
GPT-5.1 Codex High:日常使いの向上したユーティリティ
GPT-5.1 Codex Highは、ベースライン精度を73%に高め、192Kコンテキストでの堅牢な計画に焦点を当てています。
GPT-5.1 Codex Fast:速度優先設計
GPT-5.1 Codex Fastは、1秒の応答と128Kトークンに削減され、60%の有効性で、補完に優れています。
GPT-5.1 Codex High Fast:調整された機敏性
GPT-5.1 Codex High Fastは、Highの特性と速度を融合し、1.2秒で72%の精度を提供します。
GPT-5.1 Codex Low:ミニマリストな精度
GPT-5.1 Codex Lowは、96Kトークンでリソースを節約し、67%のスコアでエッジデバイスに適しています。
GPT-5.1 Codex Low Fast:超効率的
GPT-5.1 Codex Low Fastは、サブ秒で62%を達成し、マイクロタスクに最適です。
GPT-5.1 Codex Mini High:コンパクトな卓越性
GPT-5.1 Codex Mini Highは、Miniを強化し、0.8秒で65%の精度を達成します。
GPT-5.1 Codex Mini Low:予算に優しいコンパクトモデル
GPT-5.1 Codex Mini Lowは、基本的なニーズのために、最小限のコストで58%の精度を提供します。
技術比較:重要な指標
最適なCursor Codexモデルを決定するために、主要な指標である成功率(Cursor Benchより)、遅延、コンテキストサイズ、ツール有効性を分析します。成功率は自律タスク完了度を、遅延は応答時間を、コンテキストはトークン容量を、ツール有効性はシェル統合を評価します。
| モデルバリアント | 成功率 (%) | 遅延 (秒) | コンテキスト (Kトークン) | ツール有効性 (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
これらの数値は、実際のIDEインタラクションをシミュレートするCursorのハーネステストから得られたものです。Maxバリアントが成功率を支配する一方で、Fastサフィックスが遅延において優れていることに注目してください。
さらに、エネルギー効率も考慮してください。OpenAIのレポートによると、LowおよびMiniモデルは消費電力が40%少なくなっています。API中心のプロジェクトでは、ツール有効性は統合品質に直接影響します。スコアが高いほど、Apidogにエクスポートする際の手動調整が少なくて済みます。
ベンチマークの内訳:実世界のパフォーマンスに関する洞察
ベンチマークは具体的な証拠を提供します。Cursor Benchは、Python、JavaScript、Rustなどの言語で500以上のタスクをテストする内部スイートです。GPT-5.1 Codex Maxは、特に10以上のツール呼び出しを伴うエージェントチェーンで78%の解決率を誇ります。専用のread_lints統合のおかげで、リンターエラーの92%を解決します。
GPT-5.1 Codex Mini Fastバリアントはスループットを優先します。スプリント週をシミュレートした100タスクのスプリントでは、MiniはMaxよりも85%多くの反復を完了しますが、微妙なリファクタリングでの精度は20%低くなります。
標準化された指標であるSWE-bench Verifiedでは、ファミリー全体で平均65%を記録し、GPT-4.1から25%向上しています。Extra Highモデルは82%でピークに達しますが、その遅延のためライブペアプログラミングには適していません。
ユースケースに移行すると、Max Extra Highのような高コンテキストモデルは、モノレポで50以上のファイルを難なくナビゲートし、威力を発揮します。ソロ開発者にとっては、Medium Fastが最適なバランスを提供します。
ユースケース:モデルを開発者のニーズに合わせる
ワークフローの要件に基づいてCursor Codexモデルを選択してください。フルスタックAPI開発の場合、GPT-5.1 Codex Max High Fastは、安全でスケーラブルなエンドポイントを迅速に生成します。GraphQLリゾルバを作成し、その後シェルツールを使用してモックに対してテストします。これをApidogのスキーマバリデータで合理化し、エンドツーエンドの信頼性を確保できます。
組み込みシステムコーディングでは、GPT-5.1 Codex Lowが効率を重視し、制約された環境に適合するC++スニペットを生成します。機械学習パイプラインは、Max Extra Highの確率的計画の恩恵を受け、最小限の試行錯誤でテンソルフローを最適化します。
共同作業環境では、Fastバリアントがリアルタイムの提案を可能にし、チームの相乗効果を促進します。常にトークン使用量を監視してください。制限を超えるとフォールバックがトリガーされ、有効性が15%低下します。
さらに、ハイブリッドアプローチも有効です。アイデア出しにはMiniから始め、実装にはMaxにエスカレートします。この戦略により、計算予算に対するROIが最大化されます。
最適化のヒント:ApidogでCursor Codexを強化する
GPT-5.1 Codexのパフォーマンスを向上させるには、ハーネスを微調整します。設定で推論トレースを有効にすると、Cursorのドキュメントによると、継続性が向上し、成功率が30%向上します。「編集前にread_fileを使用する」といったプロンプトは、モデルをガイドし、生のシェルよりもツール呼び出しを優先させます。
APIワークフローにはApidogを組み込みます。Codexがボイラープレートを生成し、Apidogがそれを即座にテストします。仕様をYAMLとしてエクスポートし、モック応答を作成し、ドキュメントを自動化することで、統合時間を50%短縮できます。
Cursorの組み込みメトリクスで遅延をプロファイルします。ボトルネックが発生した場合は、Lowバリアントに切り替えます。OpenAIは頻繁に反復するため、パッチのためにハーネスを定期的に更新してください。
セキュリティも重要です。インジェクションのリスクを防ぐためにツール出力をサニタイズします。本番環境では、差分レビューを介してCodexの編集を監査します。
結論:GPT-5.1 Codex Maxが総合的に最良である
仕様、ベンチマーク、およびアプリケーションを詳細に分析した結果、GPT-5.1 Codex Maxが最高の座を獲得しました。その比類ない78%の成功率、堅牢な512Kコンテキスト、および多機能なツールセットは、本格的なコーディングにとって不可欠です。Fastモデルは速度で、Miniはアクセシビリティで優れていますが、Maxは包括的な卓越性を提供し、開発者が野心的なプロジェクトに正面から取り組む力を与えます。
今すぐCursorで実験し、Apidogを組み合わせて包括的なAPI処理を行いましょう。あなたの選択が生産性を形作ります。スタックを将来にわたって保証するためにMaxを選択してください。


