
人工知能は、開発者がオーディオおよび音楽生成に取り組む方法を根本的に変えました。従来のレコーディングセッションや静的なサウンドライブラリに頼るのではなく、チームは現在、洗練されたAI音楽APIやAIオーディオAPIを活用して、動的でパーソナライズされたオーディオ体験を大規模に作成しています。
AI音楽およびオーディオAPIテクノロジーの理解
特定のプラットフォームを評価する前に、これらのAPIが実際に何を達成するのかを理解することが非常に重要です。AI音楽APIは、既存の音楽の膨大なデータセットでトレーニングされた機械学習モデルを通じて、オリジナルの楽曲、編曲、インストゥルメンタル・トラックを生成します。これらのシステムは、音楽理論、和声進行、ジャンルの慣習をきめ細かく理解しています。
AIオーディオAPIはわずかに異なります。音声合成や音声認識から、効果音の作成、音響分析まで、あらゆる種類の音を処理、変更、または生成します。一部のプラットフォームは両方の機能を組み合わせていますが、他のプラットフォームは1つの領域に特化しています。
開発を変革するAI音楽およびオーディオAPIトップ10
1. Hyperreal AI:市場をリードする次世代オーディオインテリジェンス
Hyperreal AIは、AI音楽およびオーディオAPI分野における最先端のプロバイダーとしての地位を確立しています。このプラットフォームは、洗練された音楽生成と高度なオーディオ処理機能を組み合わせることで、創造的かつ機能的なオーディオ機能の両方を必要とする開発者向けに包括的なソリューションを提供します。

料金:無料の開発者向けティアからエンタープライズ契約まで、段階的な構造。大規模展開ではボリュームディスカウントが適用されます。
最適:生成と処理の両方を統一プラットフォームで必要とする完全なオーディオソリューション。
2. Suno:大規模な高度な音楽生成
Sunoは、卓越した一貫性で堅牢なAI音楽API機能を提供します。このプラットフォームは、ほぼすべてのジャンルで完全な楽曲を生成し、歌詞、楽器編成、プロのスタジオに匹敵するプロダクション品質を組み込んでいます。
この技術的な実装は、プロンプトベースの生成をサポートしており、目的のトラックを記述すると、システムが一致するオーディオを生成します。このアプローチは、ユーザーがポッドキャスト用のカスタムコンテンツ音楽、ビデオ用のバックグラウンドトラック、またはパーソナライズされたプレイリストを作成するアプリケーションにスムーズに統合されます。
料金:毎月のクレジットが制限された無料ティア。プロフェッショナルプランでは、より高速な生成と高い制限が解除されます。エンタープライズ契約も利用可能です。
最適:高品質なフルソング生成を必要とする音楽中心のアプリケーション。
3. OpenAIのオーディオモデル:幅広いアプリケーションでの汎用性
OpenAIは、Whisperとテキスト読み上げモデルを通じて、包括的なAIオーディオAPIソリューションを提供します。Whisperは、多数の言語とアクセントで驚くべき精度で音声テキスト変換を処理します。テキスト読み上げAPIは、音声ナレーション、アクセシビリティ機能、またはインタラクティブなオーディオ体験を必要とするアプリケーション向けに、自然な音声生成をします。
OpenAIのアプローチの強みは、信頼性と統合の簡素さにあります。彼らのAPIは既存のOpenAIインフラストラクチャとシームレスに連携し、すでにGPTモデルを使用しているチームの摩擦を軽減します。開発者は、数千の推論リクエスト全体でスムーズな実装体験と一貫した出力品質を報告しています。
料金:テキスト読み上げはトークンごとの料金。音声テキスト変換は分ごとの課金。ボリュームディスカウントあり。
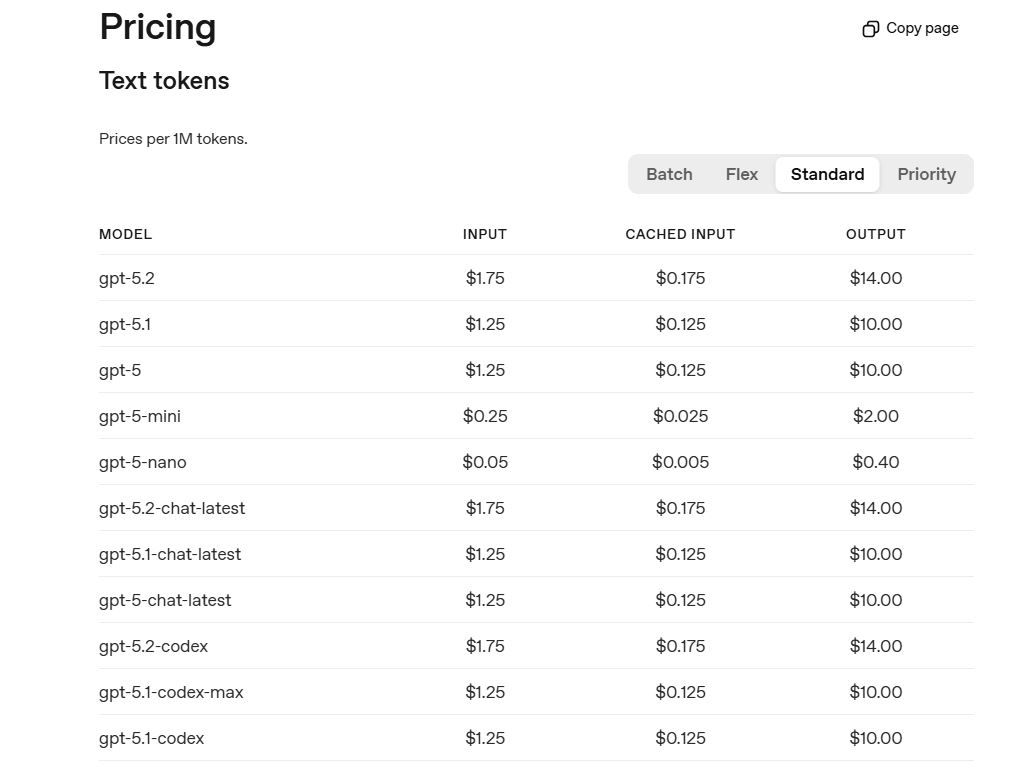
最適:作曲の要件なしに音声合成および音声認識を行うアプリケーション。
4. Google Cloudの生成AIオーディオ:エンタープライズグレードのソリューション
Google Cloudは、Vertex AIプラットフォームを通じて堅牢なAIオーディオAPI機能を提供します。テキスト読み上げサービスは、複数の音声、言語、音響パラメータをサポートしています。開発者は、話速、ピッチ、感情を正確に調整して特定の要件に合わせることができます。
GoogleのAIオーディオAPIを他のGCPサービスと組み合わせることで、真の利点が生まれます。Google Cloud上でインフラストラクチャを運用する組織は、統合認証、一元化された請求、およびサービス間のシームレスなデータフローを実装できます。このアーキテクチャ上の利便性は、複雑なシステムを管理する企業にとって特に重要です。
料金:リクエスト量に基づいた従量課金モデル。コミットメント利用プランでは大幅な割引が適用されます。
最適:HIPAA/SOC2コンプライアンスとGCPエコシステム統合を必要とするエンタープライズ組織。
5. Runway:メディアプロフェッショナルのためのクリエイティブオーディオ
Runwayは、従来のオーディオ生成を超えて、完全なメディア合成へと拡張しています。このプラットフォームは、AIアシスタンスにより音楽、効果音、さらにはビデオも作成します。ビデオエディター、ポッドキャストプラットフォーム、インタラクティブなストーリーテリング体験などのクリエイティブなアプリケーションを構築する開発者向けに、Runwayは包括的なオーディオツールを提供します。
Runway APIは既存のクリエイティブワークフローと統合されます。開発者は、詳細なパラメーターを通じてクリエイティブな制御を維持しながら、アプリケーション内からオーディオ生成をトリガーできます。このプラットフォームは、オーディオが機能的インフラストラクチャではなくクリエイティブな媒体として機能するアプリケーションを構築するチームに特に魅力的です。
料金:利用ベースのクレジットシステム。プロフェッショナルティアには、より高速な生成速度が含まれます。
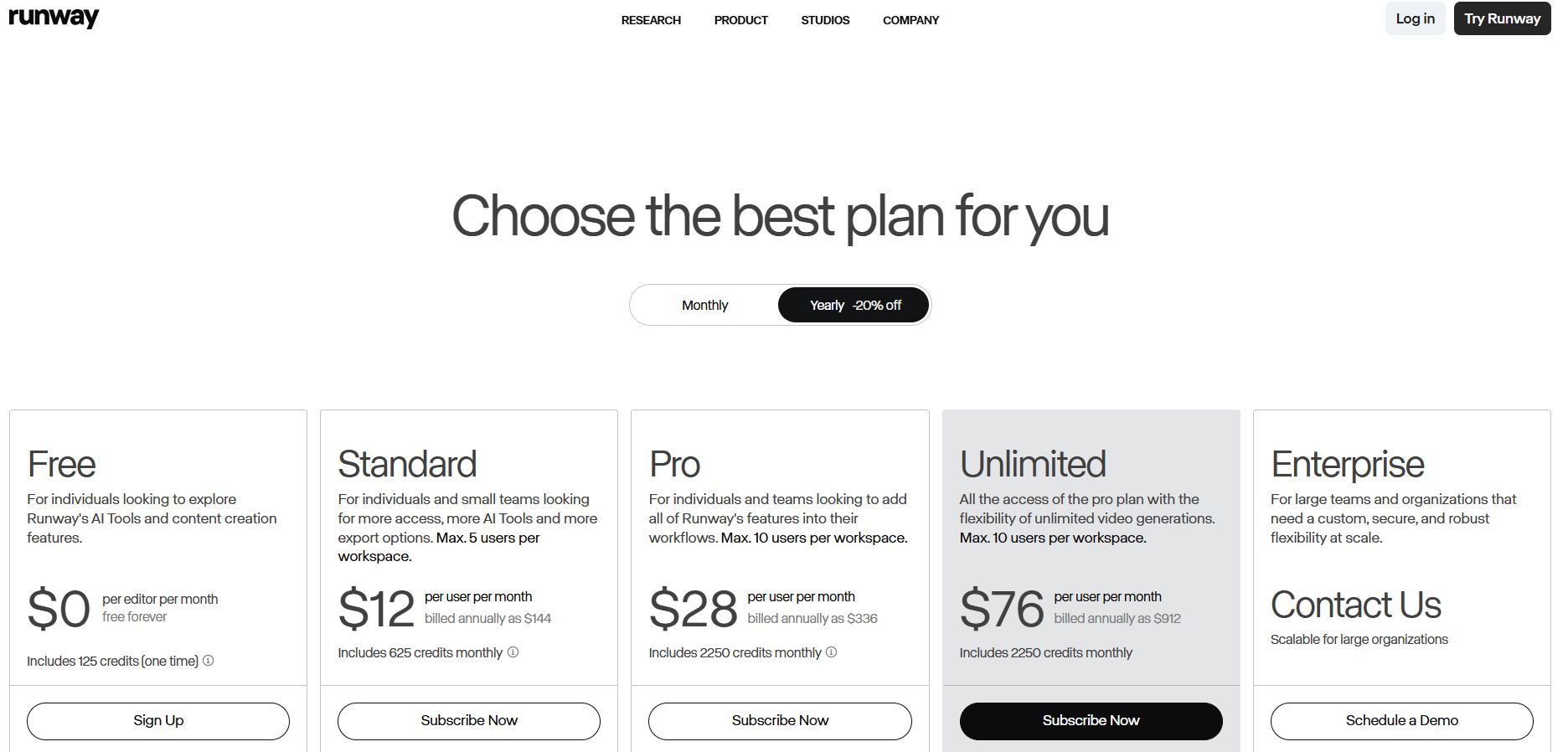
最適:音楽、効果音、包括的なオーディオ合成を必要とするクリエイティブなアプリケーション。
6. ElevenLabs:プレミアム音声合成とオーディオ処理
ElevenLabsは、前例のない自然さを持つテキスト読み上げに特化しています。AIオーディオAPIは、リスナーが本当に人間の話者と間違えるような音声を生成します。このプラットフォームは音声クローンをサポートしており、アプリケーションがコンテンツ全体で一貫した話者の識別を維持できるようにします。
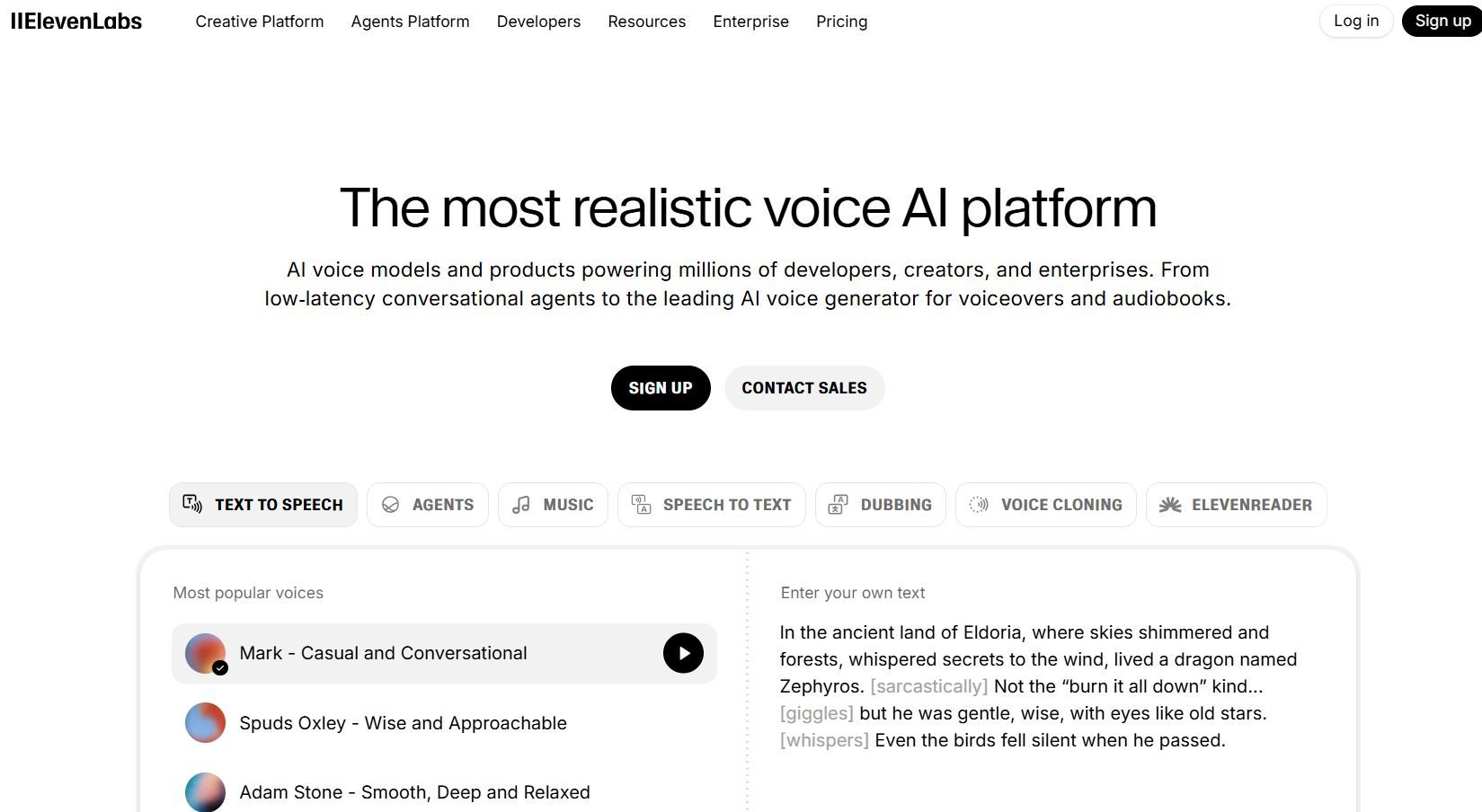
その技術的な品質は、ElevenLabsを一般的なテキスト読み上げソリューションから区別します。生成された音声には感情的なニュアンスが現れ、笑い、息遣い、抑揚の変化が本物らしく聞こえます。プロの声優も、人間のナレーションが費用対効果に見合わないプロジェクトでElevenLabsを利用しています。
料金:クレジットベースのシステム。プレミアム音声は標準オプションよりも高価です。上位ティアでクローン機能が利用可能です。
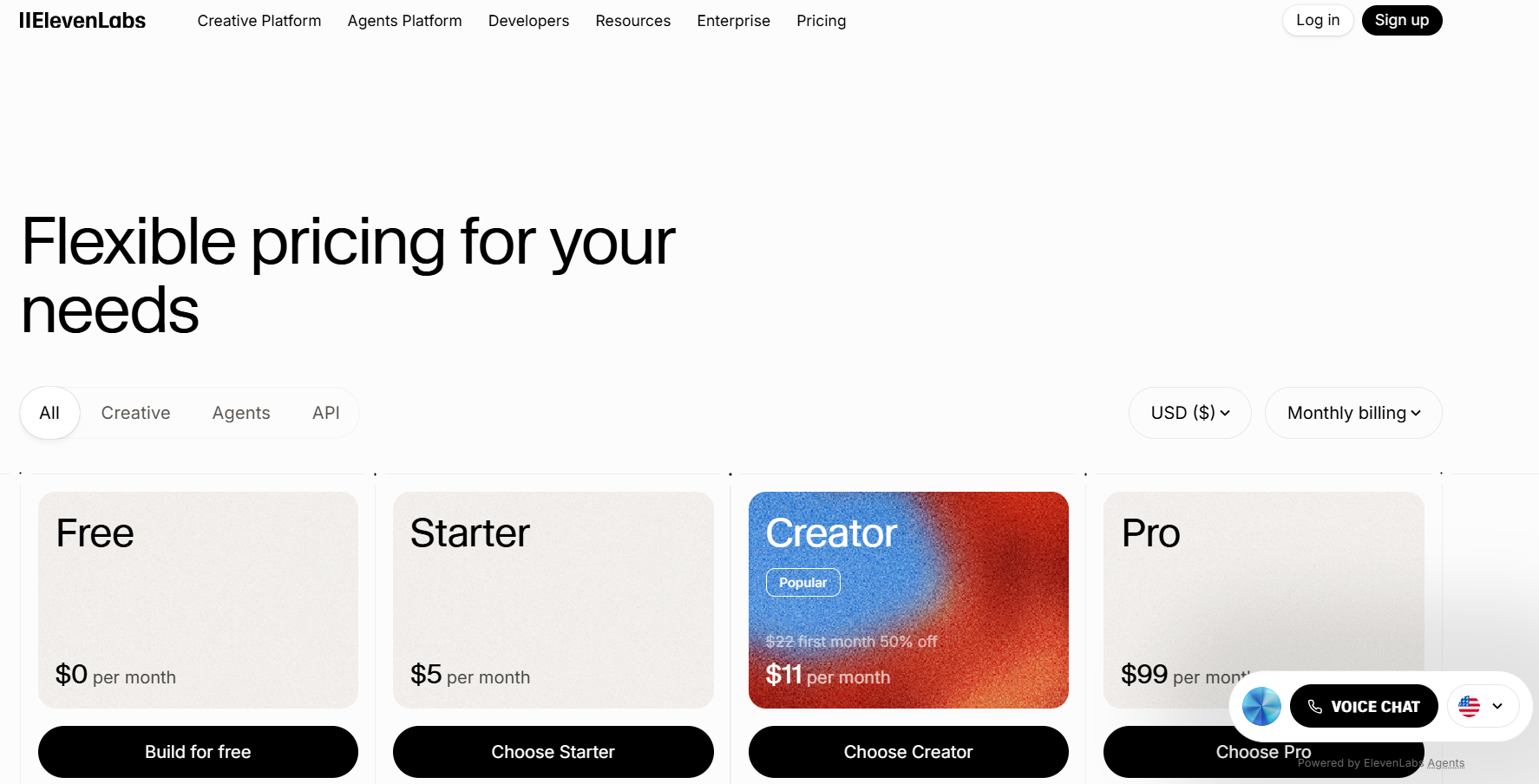
最適:非常に自然な音声合成と音声クローンを必要とするアプリケーション。
7. Stability AI:高品質オーディオ生成と強化
Stability AIは、開発者にアクセスしやすいオーディオ生成機能を提供します。このプラットフォームは、多様なジャンルで質の高い音楽と効果音を生成します。オーディオ強化ツールは、既存のオーディオを処理して品質を向上させ、ノイズを除去し、レベルを正規化します。
APIアーキテクチャは速度を重視しています。Stability AIは多くの競合他社よりも高速にリクエストを処理するため、リアルタイムアプリケーションに適しています。開発者は、迅速な統合体験と応答性の高いサポートを報告しています。
料金:サードパーティプロバイダー経由で$0.126/ステップから始まるクレジットベースのAPI料金。収益100万ドル未満の中小企業向けには無料のコミュニティライセンス。エンタープライズ向けのカスタム料金も利用可能です。
最適:最大の複雑さなしに一貫したオーディオを必要とする速度重視のアプリケーション。
8. NVIDIA Nemo:高度な音声およびオーディオ処理
NVIDIA Nemoは、クラウドAPIを通じて高度な音声およびオーディオ処理機能を提供します。このプラットフォームは、音声認識、テキスト読み上げ、オーディオ強化を卓越した精度で処理します。NVIDIAのディープラーニング専門知識は、リアルタイムパフォーマンスに最適化された高品質モデルに変換されます。
Nemoは特に困難なオーディオシナリオで優れています。ノイズの多い環境、アクセントのある音声、重なり合う話者など、Nemoはこれらのエッジケースを驚くべき精度で処理します。このプラットフォームは、数十の言語で自動音声認識をサポートしています。
料金:オープンソースモデルは無料のセルフホスティングで利用可能。NVIDIA Riva SDKを通じたエンタープライズ展開はインフラベースの料金設定(AWSで約$60/時間)。従来の従量課金API料金はありません。
最適:困難な音響環境で堅牢な音声処理を必要とする組織。
9. DescriptのオーディオAPI:音声中心のコンテンツ作成
Descriptは、音声転写、合成、編集を中心とした特化したオーディオソリューションを提供します。このプラットフォームは、テキストから高品質な合成音声を生成します。開発者は、音声生成をコンテンツ作成ワークフローに直接統合できます。
Descriptの強みは、ワークフロー統合にあります。AIオーディオAPIは文字起こしサービスと連携し、完全な音声処理パイプラインを構築します。アプリケーションは自動的に文字起こしを生成し、同時に合成ナレーションを作成します。この統合により、個別のツール間のコンテキスト切り替えが不要になります。
料金:API使用料が含まれる月額サブスクリプション。ティア制限を超える追加使用は超過料金が発生します。
最適:文字起こしと合成の統合を必要とする音声中心のコンテンツ作成。
10. Audioshake:音楽分離とオーディオ強化
Audioshakeは、音楽のステム分離とオーディオ強化の特殊な機能でトップ10を締めくくります。AIオーディオAPIは、ボーカル、ドラム、ベース、その他の要素を分離し、ミックスされたトラックから個々の楽器を分離します。この機能により、リミックス作成、選択的処理、高度なオーディオ操作が可能になります。
この技術的アプローチは、複雑なミックス内の個々の楽器を認識するようにトレーニングされた高度なニューラルネットワークを使用します。モデルが進化するにつれて、分離品質は向上し続けています。リミックスプラットフォーム、DJアプリケーション、または高度なオーディオ編集ツールを構築する開発者にとって、Audioshakeは不可欠です。
料金:クレジットベースのAPI料金。消費者向けプランは、4回の分離で月額20ドルから。APIステム分離の料金は、カスタム見積もりについては営業にお問い合わせください。文字起こしは1分あたり1.5クレジット。
最適:音楽のリミックス、ステム分離、高度なオーディオ操作アプリケーション。
ApidogによるAPI管理の合理化
複数のAIオーディオAPI統合の管理は、すぐに複雑になります。認証情報はシステム全体に散らばり、プロバイダーによってリクエスト/レスポンスの形式が異なります。APIパフォーマンスの監視には、プラットフォームごとに異なるツールが必要です。
Apidogは、AI音楽およびオーディオAPI管理を単一のインターフェースに統合します。このプラットフォームは、一元化された認証処理、リクエスト/レスポンステスト、および包括的な監視を提供します。ツール間のコンテキスト切り替えなしにAPIインタラクションをデバッグします。共有ワークスペースとドキュメントを通じてチームメンバーと協力します。既存のAPIをインポートし、使用パターンをすぐに可視化できます。
視覚的なリクエストビルダーは、AIオーディオAPIへの複雑な呼び出しの構築を簡素化します。JSONペイロードを手書きするのではなく、直感的なインターフェースを通じてパラメーターを選択できます。実行前にリクエストをプレビューできます。繰り返しの操作のためにテンプレートを保存できます。チームメンバーと作業構成をシームレスに共有できます。
Apidogの監視ダッシュボードは、すべてのプロバイダーでAPIパフォーマンスを追跡します。どのAI音楽およびオーディオAPIエンドポイントが最も速くクレジットを消費しているかを特定します。本番環境に影響を与える前に統合の問題を発見します。コスト配分と最適化のために使用状況レポートを生成します。
結論:今日のAI搭載オーディオの実装
最高のAI音楽およびオーディオAPIは、スムーズに統合され、プロフェッショナルグレードの結果を提供する、信頼性の高い本番環境対応のインフラストラクチャへと進化しました。適切なソリューションを選択することは、もはや技術の成熟度を問うことではなく、プラットフォームの強みを特定のユースケースに合わせることです。スケーリングする前に、統合、コスト、オーディオ品質を検証するために小規模なパイロットから始めてください。Hyperreal AI(フルスタックオーディオ)、Suno(音楽生成)、ElevenLabs(音声合成)、Audioshake(ステム分離)のような市場リーダーは、エコシステムの多様性を際立たせ、ほぼすべてのアプリケーションに適したものがあることを保証しています。インテリジェントオーディオが標準インフラストラクチャとなるにつれて、今日適切なAI音楽またはオーディオAPIを選択することで、あなたの製品は追随するのではなく、リードする立場に立つことができます。
AI音楽およびオーディオAPIの統合を合理化する準備はできていますか?今すぐApidogを無料でダウンロードし、開発者向けに設計されたプロフェッショナルツールで、すべてのAPIを管理しましょう。