Kecerdasan buatan terus berkembang pesat, dan pengembang kini menuntut alat yang memberikan kemampuan penalaran tingkat lanjut. NVIDIA memenuhi kebutuhan ini dengan keluarga model NVIDIA Llama Nemotron. Model-model ini unggul dalam tugas-tugas yang membutuhkan penalaran kompleks, menawarkan efisiensi komputasi, dan dilengkapi dengan lisensi terbuka untuk penggunaan perusahaan. Pengembang dapat mengakses model-model ini melalui NVIDIA Llama Nemotron API, yang disediakan melalui layanan mikro NIM NVIDIA, sehingga integrasi ke dalam aplikasi menjadi lancar.
Memahami Model NVIDIA Llama Nemotron
Sebelum menyelami API, mari kita periksa model NVIDIA Llama Nemotron. Keluarga ini mencakup tiga varian: Nano, Super, dan Ultra. Masing-masing menargetkan kebutuhan penerapan tertentu, menyeimbangkan kinerja dan tuntutan sumber daya.
- Nano (8B parameter): Insinyur mengoptimalkan model ini untuk perangkat edge dan PC. Ini memberikan akurasi tinggi dengan daya komputasi minimal, sehingga ideal untuk aplikasi ringan.
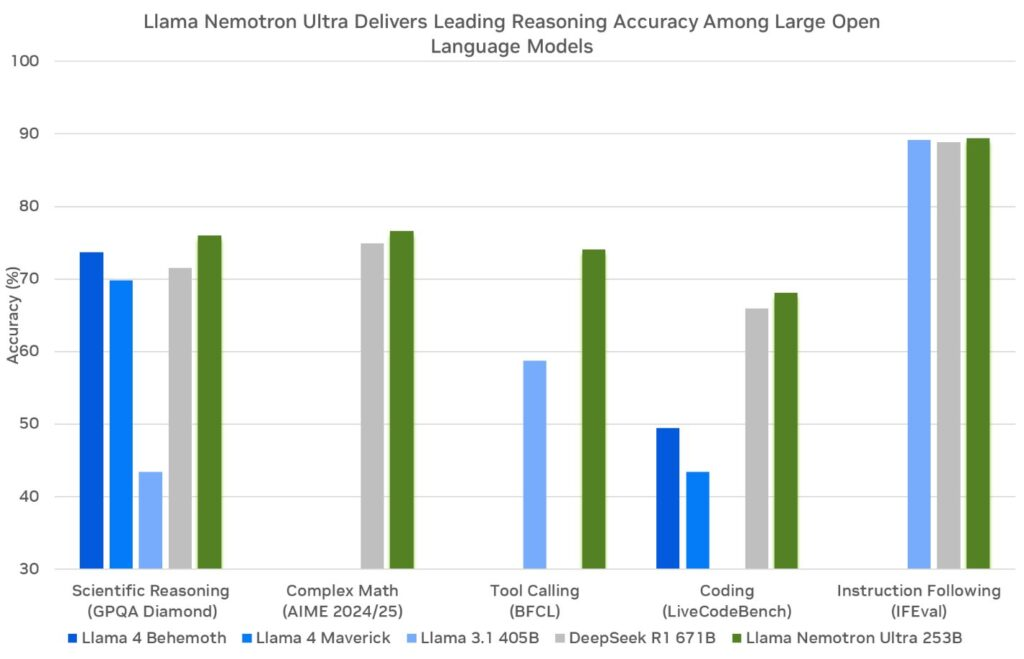
- Super (49B parameter): Pengembang merancang model ini untuk pengaturan GPU tunggal. Ini mencapai keseimbangan antara throughput dan akurasi, cocok untuk tugas-tugas yang cukup kompleks.
- Ultra (253B parameter): Para ahli membuat model ini untuk server pusat data multi-GPU. Ini memberikan akurasi tingkat atas untuk aplikasi agen AI yang paling menuntut.
NVIDIA membangun model-model ini di atas kerangka kerja Llama Meta, meningkatkannya dengan teknik pasca-pelatihan seperti distilasi dan pembelajaran penguatan. Akibatnya, mereka unggul dalam tugas-tugas penalaran seperti analisis ilmiah, matematika tingkat lanjut, pengkodean, dan mengikuti instruksi. Setiap model mendukung panjang konteks 128.000 token, memungkinkan mereka untuk memproses dokumen panjang atau mempertahankan konteks dalam interaksi yang diperluas.
Fitur yang menonjol adalah kemampuan untuk mengaktifkan atau menonaktifkan penalaran melalui perintah sistem. Pengembang mengaktifkan penalaran untuk kueri kompleks, seperti pemecahan masalah, dan menonaktifkannya untuk tugas-tugas sederhana, seperti mengambil informasi statis. Fleksibilitas ini mengoptimalkan penggunaan sumber daya, keuntungan penting dalam aplikasi dunia nyata.
Menyiapkan NVIDIA Llama Nemotron API
Untuk memanfaatkan NVIDIA Llama Nemotron API, Anda harus terlebih dahulu menyiapkannya. NVIDIA memberikan API ini melalui layanan mikro NIM-nya, yang mendukung penerapan di seluruh lingkungan cloud, on-premise, atau edge. Ikuti langkah-langkah ini untuk memulai:
Bergabung dengan Program Pengembang NVIDIA: Daftar untuk mengakses sumber daya, dokumentasi, dan alat. Langkah ini membuka ekosistem yang Anda butuhkan.
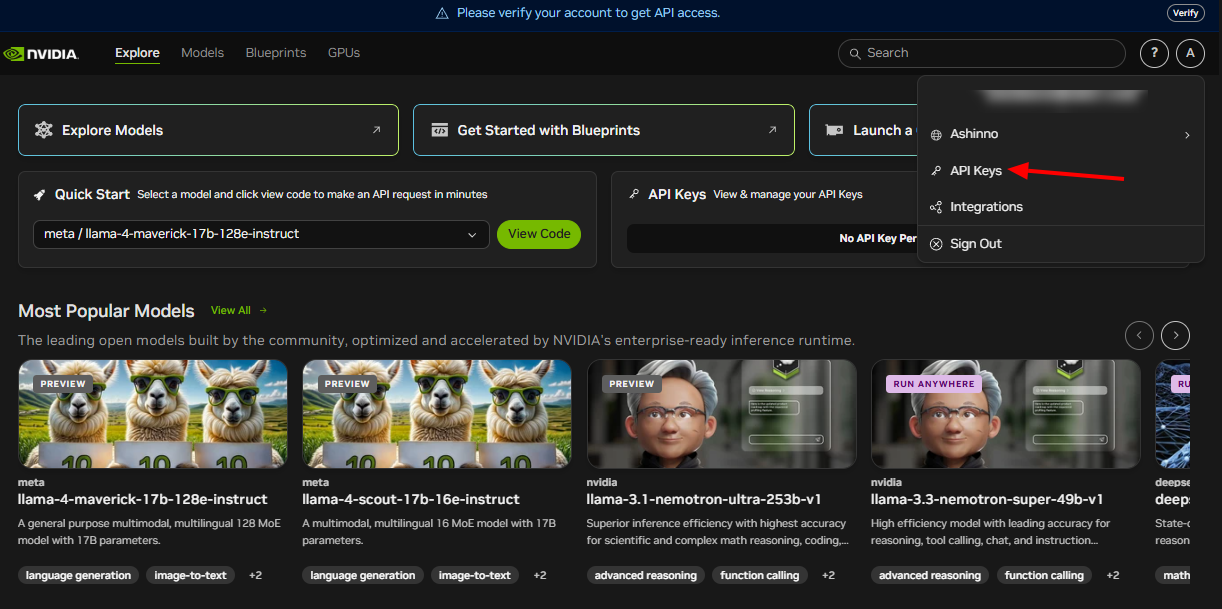
Dapatkan Kredensial API: NVIDIA menyediakan kunci API. Gunakan ini untuk mengautentikasi permintaan Anda dengan aman.
Instal Pustaka yang Diperlukan: Untuk pengembang Python, instal pustaka requests untuk menangani panggilan HTTP. Jalankan perintah ini di terminal Anda:
pip install requests
Dengan langkah-langkah ini selesai, Anda menyiapkan lingkungan Anda untuk berinteraksi dengan NVIDIA Llama Nemotron API. Selanjutnya, kita akan menjelajahi cara membuat permintaan.
Membuat Permintaan API
NVIDIA Llama Nemotron API mematuhi standar RESTful, menyederhanakan integrasi ke dalam proyek Anda. Anda mengirim permintaan POST ke titik akhir API, menyematkan parameter dalam badan permintaan. Mari kita uraikan ini dengan contoh praktis.
Berikut cara Anda menanyakan API menggunakan Python:
import requests
import json
# Define the API endpoint and authentication
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Create the request payload
payload = {
"model": "llama-nemotron-super",
"prompt": "How many R's are in the word 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Send the request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Process the response
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Error: {response.status_code} - {response.text}")
Parameter Kunci Dijelaskan
model: Menentukan varian model—Nano, Super, atau Ultra. Pilih berdasarkan penerapan Anda.prompt: Menyediakan teks input untuk diproses oleh model.max_tokens: Membatasi panjang respons dalam token. Sesuaikan ini untuk mengontrol ukuran output.temperature: Berkisar dari 0 hingga 1. Nilai yang lebih rendah (mis., 0,5) menghasilkan output yang dapat diprediksi, sementara nilai yang lebih tinggi (mis., 0,9) meningkatkan kreativitas.reasoning: Mengaktifkan kemampuan penalaran. Atur ke "on" untuk tugas-tugas kompleks, "off" untuk tugas-tugas sederhana.
Misalnya, mengaktifkan penalaran cocok untuk tugas-tugas seperti memecahkan masalah matematika, sementara menonaktifkannya berfungsi untuk pencarian dasar. Anda juga dapat menambahkan parameter seperti top_p untuk kontrol keragaman atau stop_sequences untuk menghentikan pembuatan pada token tertentu, seperti "\n\n".
Berikut adalah contoh yang diperluas:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explain recursion in programming.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Permintaan ini menghasilkan penjelasan rinci tentang rekursi, berhenti pada baris baru ganda. Alat seperti Apidog membantu Anda menguji dan menyempurnakan permintaan ini secara efisien.
Menangani Respons API
Setelah mengirim permintaan, NVIDIA Llama Nemotron API mengembalikan respons JSON. Ini mencakup teks dan metadata yang dihasilkan. Berikut adalah contoh respons:
{
"text": "There are three R's in the word 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Berisi output model.tokens_generated: Menunjukkan jumlah token yang dihasilkan.time_taken: Mengukur waktu pembuatan dalam detik.
Selalu verifikasi kode status. Kode 200 menandakan keberhasilan, memungkinkan Anda untuk mengurai JSON. Kesalahan mengembalikan kode seperti 400 atau 500, dengan detail dalam badan respons untuk debugging. Terapkan penanganan kesalahan, seperti percobaan ulang atau fallback, untuk memastikan ketahanan dalam produksi.
Misalnya, perluas kode sebelumnya:
if response.status_code == 200:
result = response.json()
print(f"Response: {result['text']}")
print(f"Tokens used: {result['tokens_generated']}")
else:
print(f"Failed: {response.text}")
# Add retry logic here if needed
Pendekatan ini menjaga aplikasi Anda tetap andal dalam berbagai kondisi.
Praktik Terbaik dan Kasus Penggunaan
Untuk memaksimalkan potensi NVIDIA Llama Nemotron API, terapkan praktik terbaik ini:
- Optimalkan Penggunaan Sumber Daya: Aktifkan penalaran hanya untuk tugas-tugas kompleks. Ini mengurangi biaya komputasi secara signifikan.
- Pantau Kinerja: Lacak
time_takenuntuk memastikan respons tepat waktu, terutama untuk aplikasi waktu nyata. - Sesuaikan Parameter: Bereksperimen dengan
temperaturedanmax_tokensuntuk menyeimbangkan kreativitas dan presisi. - Amankan Kredensial: Simpan kunci API dalam variabel lingkungan atau brankas aman, jangan pernah dalam kode.
- Permintaan Batch: Proses beberapa perintah dalam satu panggilan untuk meningkatkan efisiensi.
Kasus Penggunaan Praktis
Keserbagunaan API mendukung beragam aplikasi:
- Dukungan Pelanggan: Kembangkan chatbot yang menyelesaikan kueri rumit dengan penalaran, seperti memecahkan masalah perangkat keras.
- Pendidikan: Bangun tutor yang menjelaskan konsep, seperti kalkulus, dengan logika langkah demi langkah.
- Penelitian: Bantu ilmuwan dalam menganalisis data atau menyusun hipotesis.
- Pengembangan Perangkat Lunak: Hasilkan kode atau debug skrip berdasarkan input bahasa alami.
Untuk contoh pengkodean:
payload = {
"model": "llama-nemotron-super",
"prompt": "Write a Python function to calculate a factorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
Model mungkin mengembalikan:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Ini menunjukkan kemampuannya untuk bernalar melalui logika rekursif. Apidog dapat membantu dalam menguji panggilan API semacam itu, memastikan akurasi.
Kesimpulan
NVIDIA Llama Nemotron API memberdayakan pengembang untuk membuat agen AI tingkat lanjut dengan kemampuan penalaran yang kuat. Fitur penalaran yang dapat diubah-ubah mengoptimalkan kinerja, sementara skalabilitasnya di seluruh model Nano, Super, dan Ultra sesuai dengan beragam kebutuhan. Apakah Anda membangun chatbot, alat pendidikan, atau asisten pengkodean, API ini memberikan fleksibilitas dan kekuatan.
Selain itu, mengintegrasikannya dengan alat seperti Apidog meningkatkan alur kerja Anda. Uji titik akhir, validasi respons, dan ulangi dengan cepat untuk fokus pada inovasi. Seiring kemajuan AI, menguasai NVIDIA Llama Nemotron API menempatkan Anda di garis depan bidang transformatif ini.