
Pemrosesan dokumen telah lama menjadi salah satu aplikasi AI yang paling praktis—namun sebagian besar solusi OCR memaksakan pertukaran yang tidak nyaman antara akurasi dan efisiensi. Sistem tradisional seperti Tesseract memerlukan pra-pemrosesan ekstensif. API Cloud mengenakan biaya per halaman dan menambah latensi. Bahkan model bahasa-visi modern kesulitan dengan ledakan token yang berasal dari gambar dokumen beresolusi tinggi.
DeepSeek-OCR 2 mengubah persamaan ini sepenuhnya. Berdasarkan pendekatan "Contexts Optical Compression" dari versi 1, rilis baru ini memperkenalkan "Visual Causal Flow"—sebuah arsitektur yang memproses dokumen dengan cara manusia membacanya, memahami hubungan visual dan konteks daripada sekadar mengenali karakter. Hasilnya adalah model yang mencapai akurasi 97% sambil mengompresi gambar menjadi sesedikit 64 token, memungkinkan throughput 200.000+ halaman per hari pada satu GPU.
Panduan ini mencakup segala hal mulai dari penyiapan dasar hingga penerapan produksi—dengan kode kerja yang dapat Anda salin-tempel dan jalankan segera.
Apa itu DeepSeek-OCR 2?
DeepSeek-OCR 2 adalah model visi-bahasa sumber terbuka yang dirancang khusus untuk pemahaman dokumen dan ekstraksi teks. Dirilis oleh DeepSeek AI pada Januari 2026, model ini dibangun di atas DeepSeek-OCR asli dengan arsitektur "Visual Causal Flow" baru yang memodelkan bagaimana elemen visual dalam dokumen saling berhubungan secara kausal—memahami bahwa header tabel menentukan bagaimana sel di bawahnya harus diinterpretasikan, atau bahwa keterangan gambar menjelaskan bagan di atasnya.
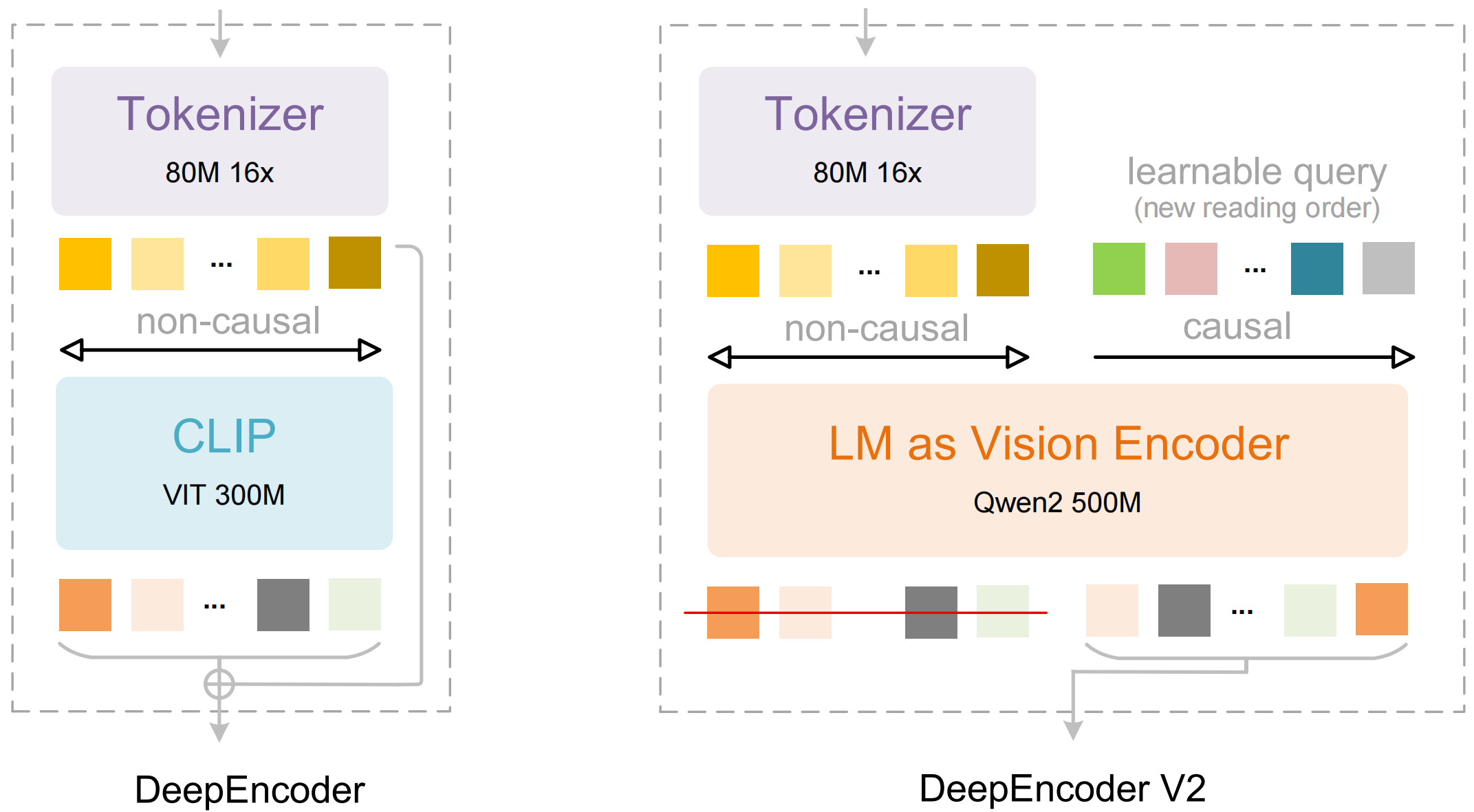
Model ini terdiri dari dua komponen utama:
- DeepEncoder: Sebuah transformer visi ganda yang menggabungkan ekstraksi detail lokal (berbasis SAM, 80 juta parameter) dengan pemahaman tata letak global (berbasis CLIP, 300 juta parameter)
- DeepSeek3B-MoE Decoder: Sebuah model bahasa campuran ahli (mixture-of-experts) yang menghasilkan output terstruktur (Markdown, LaTeX, JSON) dari representasi visual terkompresi
Apa yang membuat DeepSeek-OCR 2 berbeda:
- Kompresi ekstrem: Mengurangi gambar 1024×1024 dari 4.096 patch menjadi hanya 256 token—pengurangan 16×
- Output terstruktur: Menghasilkan Markdown yang bersih dengan tabel, header, dan format yang tepat
- Dukungan multi-format: Menangani PDF, dokumen yang dipindai, tangkapan layar, catatan tulisan tangan, dan lainnya
- 100+ bahasa: Dilatih dengan 30 juta halaman yang mencakup sekitar 100 bahasa
- Bobot terbuka: Berlisensi MIT, tersedia di Hugging Face
Fitur Utama dan Arsitektur
Aliran Kausal Visual (Visual Causal Flow)
Fitur utama versi 2 adalah "Visual Causal Flow"—pendekatan baru untuk memahami dokumen yang melampaui OCR sederhana. Alih-alih memperlakukan halaman sebagai kisi karakter datar, model ini mempelajari hubungan kausal antara elemen visual:
- Inferensi urutan baca: Secara otomatis menentukan urutan yang benar untuk tata letak multi-kolom
- Pemahaman struktur tabel: Mengenali header, sel yang digabung, dan tabel bersarang
- Penautan gambar-keterangan: Mengaitkan gambar dengan deskripsinya
- Parsing ekspresi matematika: Menangani LaTeX inline dan blok secara akurat
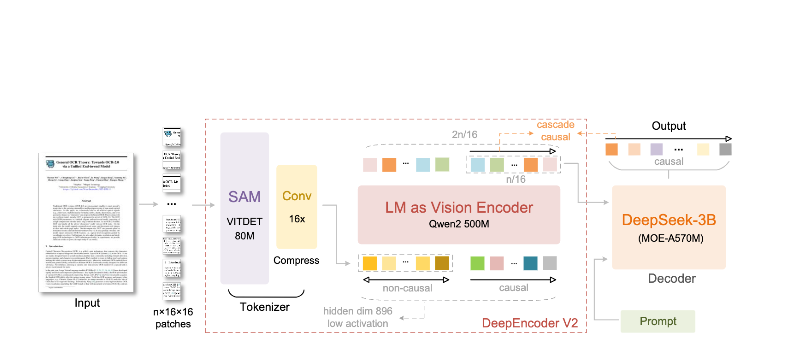
Arsitektur DeepEncoder
DeepEncoder adalah tempat keajaiban terjadi. Ini memproses gambar beresolusi tinggi sambil mempertahankan jumlah token yang dapat dikelola:
Gambar Masukan (1024×1024)
↓
Blok SAM-base (80M parameter)
- Perhatian berjendela untuk detail lokal
- Mengekstrak fitur detail
↓
Blok CLIP-large (300M parameter)
- Perhatian global untuk tata letak
- Memahami struktur dokumen
↓
Blok Konvolusi
- Pengurangan token 16×
- 4.096 patch → 256 token
↓
Output: Token Visi Terkompresi
Pertukaran Kompresi vs. Akurasi
| Rasio Kompresi | Token Visi | Akurasi |
|---|---|---|
| 4× | 1.024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
Titik optimal untuk sebagian besar aplikasi adalah rasio kompresi 10×, yang mempertahankan akurasi 97% sambil memungkinkan throughput tinggi yang membuat penerapan produksi menjadi praktis.
Instalasi dan Penyiapan
Prasyarat
- Python 3.10+ (3.12.9 direkomendasikan)
- CUDA 11.8+ dengan GPU NVIDIA yang kompatibel
- Setidaknya 16GB memori GPU (A100-40G direkomendasikan untuk produksi)
Metode 1: Instalasi vLLM (Direkomendasikan)
vLLM memberikan kinerja terbaik untuk penerapan produksi:
# Buat lingkungan virtual
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Instal vLLM dengan dukungan CUDA
pip install vllm>=0.8.5
# Instal flash attention untuk kinerja optimal
pip install flash-attn==2.7.3 --no-build-isolation
Metode 2: Instalasi Transformers
Untuk pengembangan dan eksperimen:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Metode 3: Docker (Produksi)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Pra-unduh model
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Verifikasi Instalasi
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
Contoh Kode Python
OCR Dasar dengan vLLM
Berikut adalah cara paling sederhana untuk mengekstrak teks dari gambar dokumen:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Inisialisasi model
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Muat gambar dokumen Anda
image = Image.open("document.png").convert("RGB")
# Siapkan prompt - "Free OCR." memicu ekstraksi standar
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Konfigurasi parameter sampling
sampling_params = SamplingParams(
temperature=0.0, # Deterministik untuk OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> untuk tabel
},
skip_special_tokens=False,
)
# Hasilkan output
outputs = llm.generate(model_input, sampling_params)
# Ekstrak teks markdown
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Memproses Beberapa Dokumen Secara Batch
Proses beberapa dokumen secara efisien dalam satu batch:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Memproses beberapa gambar dalam satu batch."""
# Muat semua gambar
images = [Image.open(p).convert("RGB") for p in image_paths]
# Siapkan masukan batch
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Hasilkan semua output dalam satu panggilan
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Penggunaan
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # 500 karakter pertama
print()
Menggunakan Transformers Secara Langsung
Untuk kontrol lebih atas proses inferensi:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# Atur GPU
device = "cuda:0"
# Muat model dan tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Muat dan pra-proses gambar
image = Image.open("document.png").convert("RGB")
# Prompt berbeda untuk tugas berbeda
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Konversi dokumen ke markdown.",
"table": "<image>\nEkstrak semua tabel sebagai markdown.",
"math": "<image>\nEkstrak ekspresi matematika sebagai LaTeX.",
}
# Proses dengan prompt pilihan Anda
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Tambahkan gambar ke input (pra-pemrosesan khusus model)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Pemrosesan Asinkron untuk Throughput Tinggi
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Memproses satu dokumen secara asinkron."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Inisialisasi mesin asinkron
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Memproses beberapa dokumen secara bersamaan
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} karakter diekstrak")
asyncio.run(main())
```Menggunakan vLLM untuk Produksi
Memulai Server yang Kompatibel OpenAI
Deploy DeepSeek-OCR 2 sebagai server API:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
Memanggil Server dengan OpenAI SDK
from openai import OpenAI
import base64
# Inisialisasi klien yang mengarah ke server lokal
client = OpenAI(
api_key="EMPTY", # Tidak diperlukan untuk server lokal
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Encode gambar ke base64."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Ekstrak teks dari dokumen menggunakan API OCR."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Penggunaan
result = ocr_document("invoice.png")
print(result)
Menggunakan dengan URL
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Pengujian dengan Apidog
Menguji API OCR secara efektif memerlukan visualisasi dokumen masukan dan output yang diekstrak. Apidog menyediakan antarmuka intuitif untuk bereksperimen dengan DeepSeek-OCR 2.
Menyiapkan Titik Akhir OCR
Langkah 1: Buat Permintaan Baru
Buka Apidog dan buat proyek baruTambahkan permintaan POST kehttp://localhost:8000/v1/chat/completions
Langkah 2: Konfigurasi Header
Content-Type: application/json
Langkah 3: Konfigurasi Badan Permintaan
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Menguji Berbagai Jenis Dokumen
Buat permintaan tersimpan untuk jenis dokumen umum:
Ekstraksi faktur - Uji ekstraksi data terstrukturMakalah akademik - Uji penanganan matematika LaTeXCatatan tulisan tangan - Uji pengenalan tulisan tanganTata letak multi-kolom - Uji inferensi urutan baca
Membandingkan Mode Resolusi
Siapkan variabel lingkungan untuk menguji mode yang berbeda dengan cepat:
| Mode | Resolusi | Token | Kasus Penggunaan |
|---|---|---|---|
tiny | 512×512 | 64 | Pratinjau cepat |
small | 640×640 | 100 | Dokumen sederhana |
base | 1024×1024 | 256 | Dokumen standar |
large | 1280×1280 | 400 | Teks padat |
gundam | Dinamis | Variabel | Tata letak kompleks |

Mode Resolusi dan Kompresi
DeepSeek-OCR 2 mendukung lima mode resolusi, masing-masing dioptimalkan untuk kasus penggunaan yang berbeda:
Mode Tiny (64 token)
Terbaik untuk: Deteksi teks cepat, formulir sederhana, masukan resolusi rendah
# Konfigurasi untuk mode tiny
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Mode Small (100 token)
Terbaik untuk: Dokumen digital bersih, teks satu kolom
Mode Base (256 token) - Default
Terbaik untuk: Sebagian besar dokumen standar, faktur, surat
Mode Large (400 token)
Terbaik untuk: Makalah akademik padat, dokumen hukum
Mode Gundam (Dinamis)
Terbaik untuk: Dokumen multi-halaman kompleks dengan tata letak bervariasi
# Mode Gundam menggabungkan beberapa tampilan
# - n × 640×640 tile lokal untuk detail
# - 1 × 1024×1024 tampilan global untuk struktur
Memilih Mode yang Tepat
def select_mode(document_type: str, page_count: int) -> str:
"""Pilih mode resolusi optimal berdasarkan karakteristik dokumen."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Default
Memproses PDF dan Dokumen
Mengonversi PDF ke Gambar
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""Konversi halaman PDF ke Gambar PIL."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Render pada DPI yang ditentukan
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# Konversi ke Gambar PIL
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Penggunaan
images = pdf_to_images("report.pdf", dpi=200)
print(f"Mengekstrak {len(images)} halaman")
Pipeline Pemrosesan PDF Lengkap
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Memproses seluruh PDF dan mengembalikan markdown gabungan."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Konversi halaman ke gambar
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# OCR halaman
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Halaman {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Penggunaan
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# Simpan ke file
Path("output.md").write_text(markdown)
Kinerja Benchmark
Benchmark Akurasi
| Benchmark | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| Token/halaman | 100-256 |