
Menjalankan LLM di mesin lokal Anda memiliki beberapa keuntungan. Pertama, ini memberi Anda kendali penuh atas data Anda, memastikan privasi tetap terjaga. Kedua, Anda dapat bereksperimen tanpa khawatir tentang panggilan API yang mahal atau langganan bulanan. Selain itu, penerapan lokal memberikan cara langsung untuk mempelajari bagaimana model-model ini bekerja di balik layar.
Selanjutnya, ketika Anda menjalankan LLM secara lokal, Anda menghindari potensi masalah latensi jaringan dan ketergantungan pada layanan cloud. Ini berarti Anda dapat membangun, menguji, dan melakukan iterasi lebih cepat, terutama jika Anda mengerjakan proyek yang memerlukan integrasi erat dengan basis kode Anda.
Memahami LLM: Ikhtisar Singkat
Sebelum kita membahas pilihan utama kita, mari kita sentuh secara singkat apa itu LLM. Secara sederhana, model bahasa besar (LLM) adalah model AI yang telah dilatih pada sejumlah besar data teks. Model-model ini mempelajari pola statistik dalam bahasa, yang memungkinkan mereka menghasilkan teks seperti manusia berdasarkan perintah yang Anda berikan.
LLM adalah inti dari banyak aplikasi AI modern. Mereka mendukung chatbot, asisten penulisan, generator kode, dan bahkan agen percakapan yang canggih. Namun, menjalankan model-model ini—terutama yang lebih besar—dapat memakan banyak sumber daya. Itulah mengapa memiliki alat yang andal untuk menjalankannya secara lokal sangat penting.
Dengan menggunakan alat LLM lokal, Anda dapat bereksperimen dengan model-model ini tanpa mengirim data Anda ke server jarak jauh. Ini dapat meningkatkan keamanan dan kinerja. Sepanjang tutorial ini, Anda akan melihat kata kunci "LLM" ditekankan saat kita menjelajahi bagaimana setiap alat membantu Anda memanfaatkan model-model canggih ini pada perangkat keras Anda sendiri.
Alat #1: Llama.cpp
Llama.cpp bisa dibilang salah satu alat paling populer dalam menjalankan LLM secara lokal. Dibuat oleh Georgi Gerganov dan dikelola oleh komunitas yang dinamis, pustaka C/C++ ini dirancang untuk melakukan inferensi pada model seperti LLaMA dan lainnya dengan dependensi minimal.

Mengapa Anda Akan Menyukai Llama.cpp
- Ringan dan Cepat: Llama.cpp direkayasa untuk kecepatan dan efisiensi. Dengan pengaturan minimal, Anda dapat menjalankan model kompleks bahkan pada perangkat keras yang sederhana. Ini memanfaatkan instruksi CPU tingkat lanjut seperti AVX dan Neon, yang berarti Anda mendapatkan hasil maksimal dari kinerja sistem Anda.
- Dukungan Perangkat Keras Serbaguna: Apakah Anda menggunakan mesin x86, perangkat berbasis ARM, atau bahkan Apple Silicon Mac, Llama.cpp siap membantu Anda.
- Fleksibilitas Baris Perintah: Jika Anda lebih menyukai terminal daripada antarmuka grafis, alat baris perintah Llama.cpp membuatnya mudah untuk memuat model dan menghasilkan respons langsung dari shell Anda.
- Komunitas dan Sumber Terbuka: Sebagai proyek sumber terbuka, ia mendapat manfaat dari kontribusi dan peningkatan berkelanjutan oleh pengembang di seluruh dunia.
Cara Memulai
- Instalasi: Klon repositori dari GitHub dan kompilasi kode di mesin Anda.
- Pengaturan Model: Unduh model pilihan Anda (misalnya, varian LLaMA terkuantisasi) dan gunakan utilitas baris perintah yang disediakan untuk memulai inferensi.
- Kustomisasi: Ubah parameter seperti panjang konteks, suhu, dan ukuran berkas untuk melihat bagaimana output model bervariasi.
Misalnya, perintah sederhana mungkin terlihat seperti ini:
./main -m ./models/llama-7b.gguf -p "Tell me a joke about programming" --temp 0.7 --top_k 100
Perintah ini memuat model dan menghasilkan teks berdasarkan perintah Anda. Kesederhanaan pengaturan ini merupakan nilai tambah yang besar bagi siapa pun yang baru memulai dengan inferensi LLM lokal.
Beralih dengan lancar dari Llama.cpp, mari kita jelajahi alat fantastis lainnya yang mengambil pendekatan yang sedikit berbeda.
Alat #2: GPT4All
GPT4All adalah ekosistem sumber terbuka yang dirancang oleh Nomic AI yang mendemokratisasi akses ke LLM. Salah satu aspek GPT4All yang paling menarik adalah bahwa ia dibangun untuk berjalan pada perangkat keras kelas konsumen, baik Anda menggunakan CPU atau GPU. Ini membuatnya sempurna untuk pengembang yang ingin bereksperimen tanpa memerlukan mesin yang mahal.
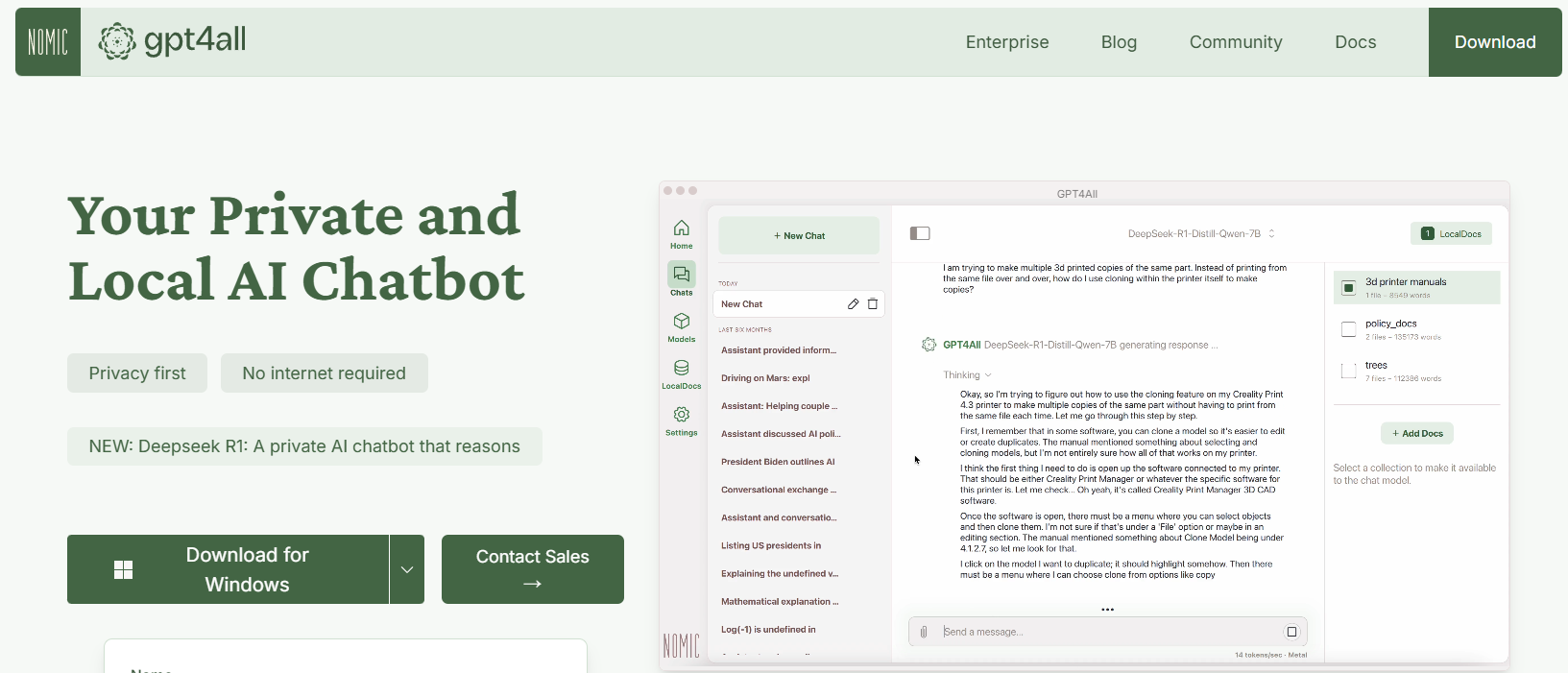
Fitur Utama GPT4All
- Pendekatan Lokal-Pertama: GPT4All dibangun untuk berjalan sepenuhnya di perangkat lokal Anda. Ini berarti tidak ada data yang pernah meninggalkan mesin Anda, memastikan privasi dan waktu respons yang cepat.
- Ramah Pengguna: Bahkan jika Anda baru mengenal LLM, GPT4All hadir dengan antarmuka yang sederhana dan intuitif yang memungkinkan Anda berinteraksi dengan model tanpa pengetahuan teknis yang mendalam.
- Ringan dan Efisien: Model dalam ekosistem GPT4All dioptimalkan untuk kinerja. Anda dapat menjalankannya di laptop Anda, membuatnya dapat diakses oleh audiens yang lebih luas.
- Sumber Terbuka dan Berbasis Komunitas: Dengan sifat sumber terbukanya, GPT4All mengundang kontribusi komunitas, memastikan bahwa ia tetap mutakhir dengan inovasi terbaru.
Memulai dengan GPT4All
- Instalasi: Anda dapat mengunduh GPT4All dari situs webnya. Proses instalasi sangat mudah, dan biner yang telah dikompilasi tersedia untuk Windows, macOS, dan Linux.
- Menjalankan Model: Setelah diinstal, cukup luncurkan aplikasi dan pilih dari berbagai model yang telah disetel sebelumnya. Alat ini bahkan menawarkan antarmuka obrolan, yang sempurna untuk eksperimen kasual.
- Kustomisasi: Sesuaikan parameter seperti panjang respons model dan pengaturan kreativitas untuk melihat bagaimana output berubah. Ini membantu Anda memahami bagaimana LLM bekerja dalam kondisi yang berbeda.
Misalnya, Anda dapat mengetik perintah seperti:
What are some fun facts about artificial intelligence?
Dan GPT4All akan menghasilkan respons yang ramah dan berwawasan—semua tanpa memerlukan koneksi internet.
Alat #3: LM Studio
Selanjutnya, LM Studio adalah alat yang sangat baik lainnya untuk menjalankan LLM secara lokal, terutama jika Anda mencari antarmuka grafis yang membuat pengelolaan model menjadi mudah.
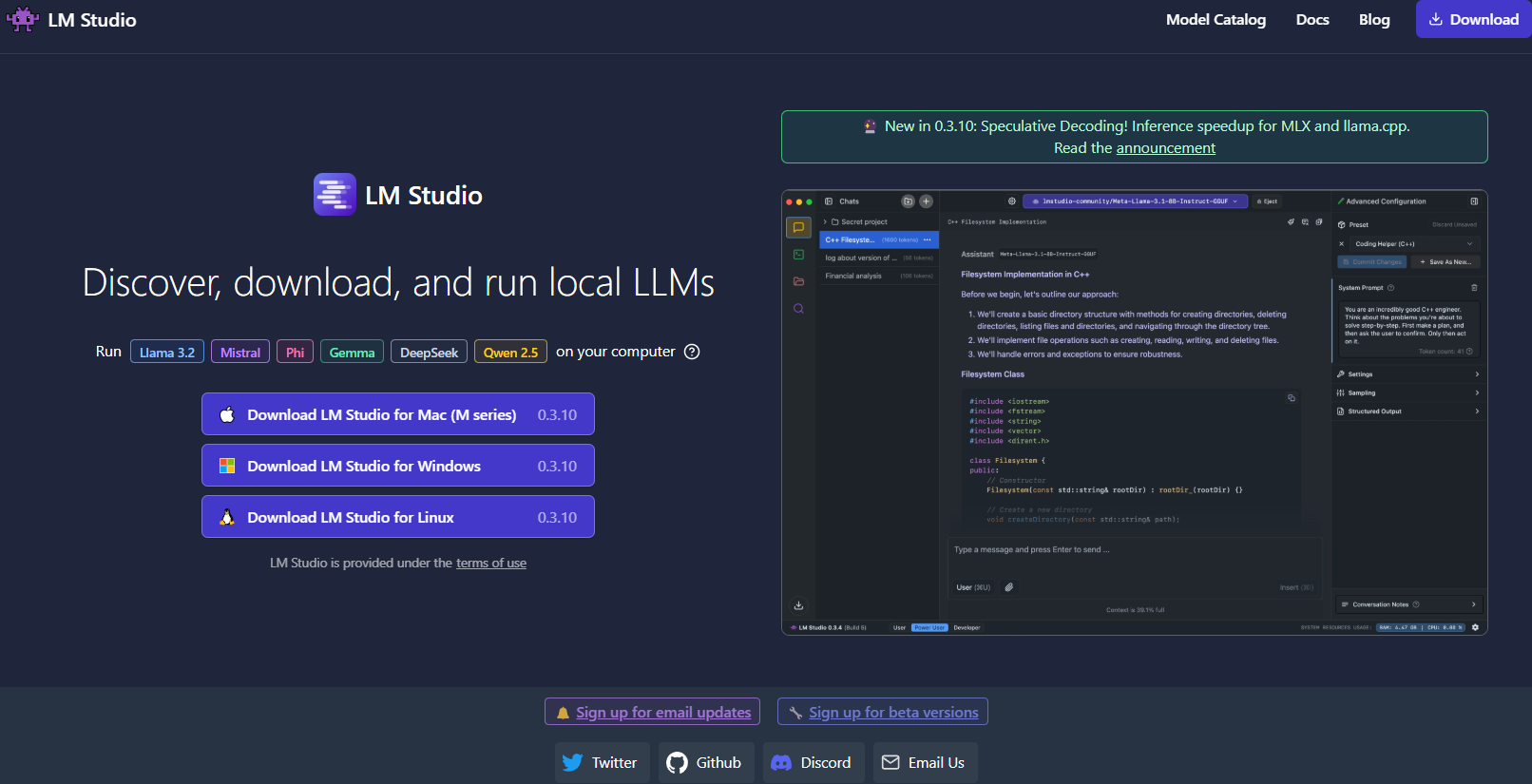
Apa yang Membedakan LM Studio?
- Antarmuka Pengguna yang Intuitif: LM Studio menyediakan aplikasi desktop yang ramping dan ramah pengguna. Ini ideal bagi mereka yang lebih suka tidak hanya bekerja di baris perintah.
- Pengelolaan Model: Dengan LM Studio, Anda dapat dengan mudah menelusuri, mengunduh, dan beralih di antara LLM yang berbeda. Aplikasi ini menampilkan filter bawaan dan fungsi pencarian, sehingga Anda dapat menemukan model yang sempurna untuk proyek Anda.
- Pengaturan yang Dapat Disesuaikan: Sesuaikan parameter seperti suhu, token maksimum, dan jendela konteks langsung dari UI. Umpan balik langsung ini sangat cocok untuk mempelajari bagaimana konfigurasi yang berbeda memengaruhi perilaku model.
- Kompatibilitas Lintas Platform: LM Studio berjalan di Windows, macOS, dan Linux, membuatnya dapat diakses oleh berbagai pengguna.
- Server Inferensi Lokal: Pengembang juga dapat memanfaatkan server HTTP lokalnya, yang meniru API OpenAI. Ini membuat integrasi kemampuan LLM ke dalam aplikasi Anda menjadi lebih sederhana.
Cara Menyiapkan LM Studio
- Unduh dan Instalasi: Kunjungi situs web LM Studio, unduh penginstal untuk sistem operasi Anda, dan ikuti petunjuk penyiapan.
- Luncurkan dan Jelajahi: Buka aplikasi, jelajahi pustaka model yang tersedia, dan pilih salah satu yang sesuai dengan kebutuhan Anda.
- Eksperimen: Gunakan antarmuka obrolan bawaan untuk berinteraksi dengan model. Anda juga dapat bereksperimen dengan beberapa model secara bersamaan untuk membandingkan kinerja dan kualitas.
Bayangkan Anda sedang mengerjakan proyek penulisan kreatif; antarmuka LM Studio memudahkan untuk beralih di antara model dan menyempurnakan output secara real time. Umpan balik visual dan kemudahan penggunaannya menjadikannya pilihan yang kuat bagi mereka yang baru memulai atau bagi para profesional yang membutuhkan solusi lokal yang kuat.
Alat #4: Ollama
Selanjutnya adalah Ollama, alat baris perintah yang kuat namun mudah dengan fokus pada kesederhanaan dan fungsionalitas. Ollama dirancang untuk membantu Anda menjalankan, membuat, dan berbagi LLM tanpa kerumitan pengaturan yang kompleks.
Mengapa Memilih Ollama?
- Penerapan Model yang Mudah: Ollama mengemas semua yang Anda butuhkan—bobot model, konfigurasi, dan bahkan data—ke dalam satu unit portabel yang dikenal sebagai "Modelfile." Ini berarti Anda dapat dengan cepat mengunduh dan menjalankan model dengan konfigurasi minimal.
- Kemampuan Multimodal: Tidak seperti beberapa alat yang hanya berfokus pada teks, Ollama mendukung input multimodal. Anda dapat memberikan teks dan gambar sebagai perintah, dan alat ini akan menghasilkan respons yang mempertimbangkan keduanya.
- Ketersediaan Lintas Platform: Ollama tersedia di macOS, Linux, dan Windows. Ini adalah pilihan yang bagus untuk pengembang yang bekerja di berbagai sistem.
- Efisiensi Baris Perintah: Bagi mereka yang lebih suka bekerja di terminal, Ollama menawarkan antarmuka baris perintah yang bersih dan efisien yang memungkinkan penerapan dan interaksi cepat.
- Pembaruan Cepat: Alat ini sering diperbarui oleh komunitasnya, memastikan bahwa Anda selalu bekerja dengan peningkatan dan fitur terbaru.
Menyiapkan Ollama
1. Instalasi: Kunjungi situs web Ollama dan unduh penginstal untuk sistem operasi Anda. Instalasi semudah menjalankan beberapa perintah di terminal Anda.
2. Menjalankan Model: Setelah diinstal, gunakan perintah seperti:
ollama run llama3
Perintah ini akan secara otomatis mengunduh model Llama 3 (atau model lain yang didukung) dan memulai proses inferensi.
3. Bereksperimen dengan Multimodalitas: Coba jalankan model yang mendukung gambar. Misalnya, jika Anda memiliki file gambar yang siap, Anda dapat menyeret dan meletakkannya ke dalam perintah Anda (atau menggunakan parameter API untuk gambar) untuk melihat bagaimana model merespons.
Ollama sangat menarik jika Anda ingin membuat prototipe atau menerapkan LLM secara lokal dengan cepat. Kesederhanaannya tidak mengorbankan kekuatan, menjadikannya ideal untuk pemula dan pengembang berpengalaman.
Alat #5: Jan
Terakhir, kita memiliki Jan. Jan adalah platform sumber terbuka, lokal-pertama yang terus mendapatkan popularitas di antara mereka yang memprioritaskan privasi data dan operasi offline. Filosofinya sederhana: biarkan pengguna menjalankan LLM yang kuat sepenuhnya pada perangkat keras mereka sendiri, tanpa transfer data tersembunyi.
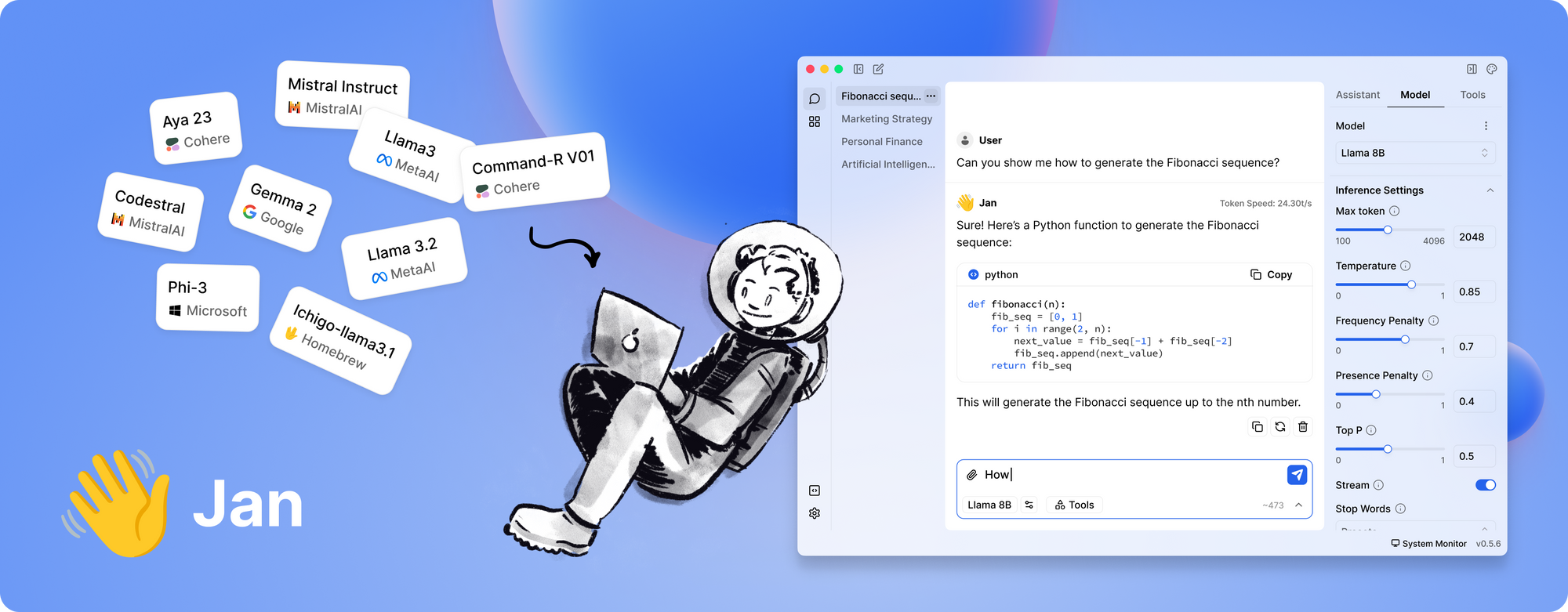
Apa yang Membuat Jan Menonjol?
- Sepenuhnya Offline: Jan dirancang untuk beroperasi tanpa koneksi internet. Ini memastikan bahwa semua interaksi dan data Anda tetap lokal, meningkatkan privasi dan keamanan.
- Berpusat pada Pengguna dan Dapat Diperluas: Alat ini menawarkan antarmuka yang bersih dan mendukung kerangka kerja aplikasi/plugin. Ini berarti Anda dapat dengan mudah memperluas kemampuannya atau mengintegrasikannya dengan alat yang ada.
- Eksekusi Model yang Efisien: Jan dibangun untuk menangani berbagai model, termasuk yang disetel dengan baik untuk tugas-tugas tertentu. Ini dioptimalkan untuk berjalan bahkan pada perangkat keras yang sederhana, tanpa mengorbankan kinerja.
- Pengembangan Berbasis Komunitas: Seperti banyak alat dalam daftar kami, Jan adalah sumber terbuka dan mendapat manfaat dari kontribusi oleh komunitas pengembang yang berdedikasi.
- Tidak Ada Biaya Berlangganan: Tidak seperti banyak solusi berbasis cloud, Jan gratis untuk digunakan. Ini menjadikannya pilihan yang sangat baik untuk startup, penghobi, dan siapa pun yang ingin bereksperimen dengan LLM tanpa hambatan keuangan.
Cara Memulai dengan Jan
- Unduh dan Instal: Kunjungi situs web resmi Jan atau repositori GitHub. Ikuti petunjuk instalasi, yang mudah dan dirancang untuk membuat Anda siap dan berjalan dengan cepat.
- Luncurkan dan Sesuaikan: Buka Jan dan pilih dari berbagai model yang telah diinstal sebelumnya. Jika diperlukan, Anda dapat mengimpor model dari sumber eksternal seperti Hugging Face.
- Eksperimen dan Perluas: Gunakan antarmuka obrolan untuk berinteraksi dengan LLM Anda. Sesuaikan parameter, instal plugin, dan lihat bagaimana Jan beradaptasi dengan alur kerja Anda. Fleksibilitasnya memungkinkan Anda menyesuaikan pengalaman LLM lokal Anda dengan kebutuhan Anda yang tepat.
Jan benar-benar mewujudkan semangat eksekusi LLM lokal yang berfokus pada privasi. Ini sempurna untuk siapa pun yang menginginkan alat yang bebas repot dan dapat disesuaikan yang menyimpan semua data di mesin mereka sendiri.
Tip Pro: Streaming Respons LLM Menggunakan Debugging SSE
Jika Anda bekerja dengan LLM (Model Bahasa Besar), interaksi waktu nyata dapat sangat meningkatkan pengalaman pengguna. Baik itu chatbot yang memberikan respons langsung atau alat konten yang diperbarui secara dinamis saat data dihasilkan, streaming adalah kuncinya. Server-Sent Events (SSE) menawarkan solusi yang efisien untuk ini, memungkinkan server untuk mendorong pembaruan ke klien melalui satu koneksi HTTP. Tidak seperti protokol dua arah seperti WebSockets, SSE lebih sederhana dan lebih mudah, menjadikannya pilihan yang bagus untuk fitur waktu nyata.
Debugging SSE bisa jadi menantang. Di situlah Apidog masuk. Fitur debugging SSE Apidog memungkinkan Anda untuk menguji, memantau, dan memecahkan masalah aliran SSE dengan mudah. Di bagian ini, kita akan menjelajahi mengapa SSE penting untuk debugging API LLM dan memandu Anda melalui tutorial langkah demi langkah tentang menggunakan Apidog untuk menyiapkan dan menguji koneksi SSE.
Mengapa SSE Penting untuk Debugging API LLM
Sebelum kita masuk ke tutorial, inilah mengapa SSE sangat cocok untuk debugging API LLM:
- Umpan Balik Waktu Nyata: SSE mengalirkan data saat dihasilkan, memungkinkan pengguna melihat respons terungkap secara alami.
- Overhead Rendah: Tidak seperti polling, SSE menggunakan satu koneksi persisten, meminimalkan penggunaan sumber daya.
- Kemudahan Penggunaan: SSE terintegrasi dengan mulus ke dalam aplikasi web, membutuhkan pengaturan minimal di sisi klien.
Siap untuk mengujinya? Mari kita siapkan debugging SSE di Apidog.
Tutorial Langkah demi Langkah: Menggunakan Debugging SSE di Apidog
Ikuti langkah-langkah ini untuk mengonfigurasi dan menguji koneksi SSE dengan Apidog.
Langkah 1: Buat Endpoint Baru di Apidog
Buat proyek HTTP baru di Apidog untuk menguji dan men-debug permintaan API. Tambahkan endpoint dengan URL model AI untuk aliran SSE—menggunakan DeepSeek dalam contoh ini. (TIP PRO: Klon proyek API DeepSeek siap pakai dari API Hub Apidog).
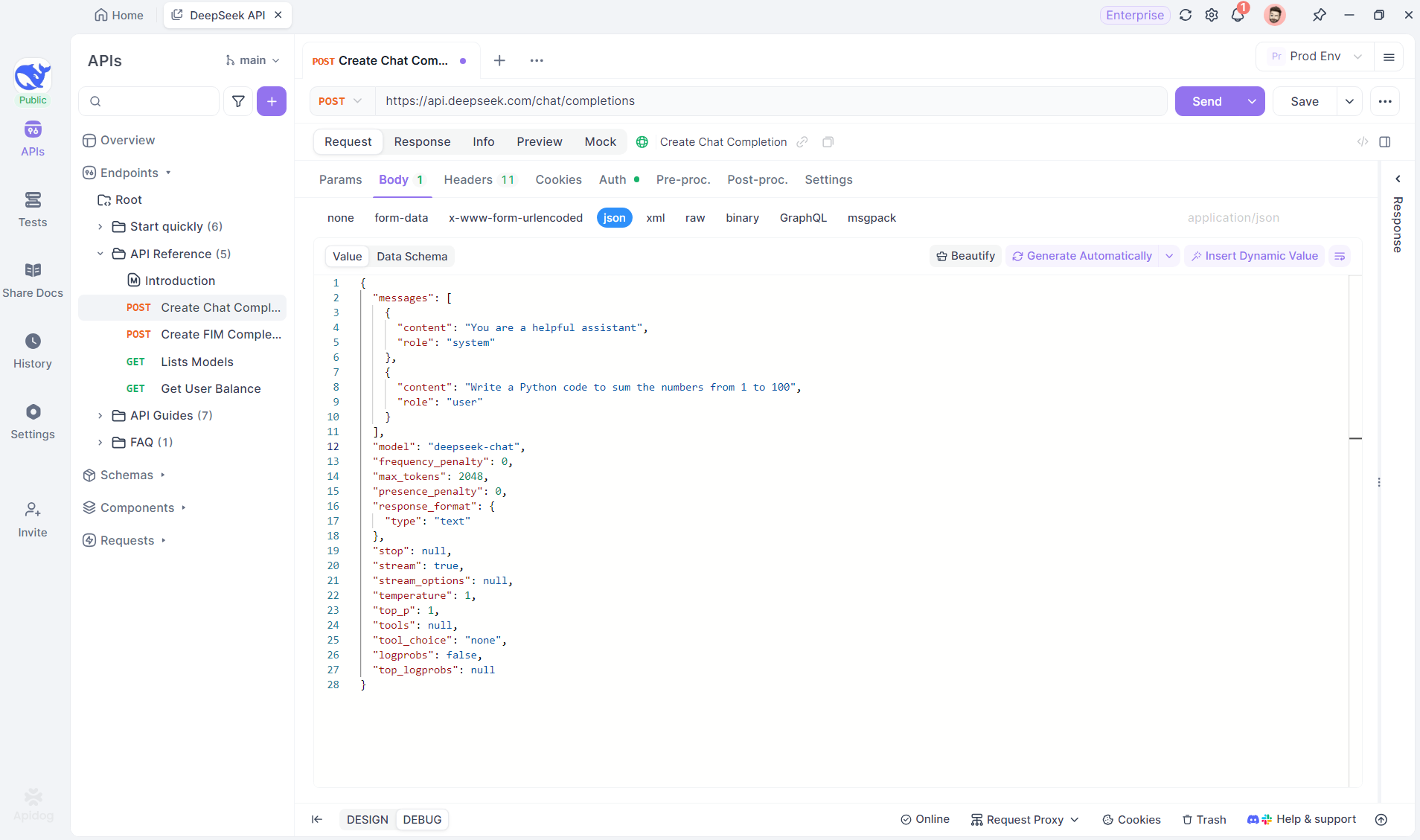
Langkah 2: Kirim Permintaan
Setelah menambahkan endpoint, klik Kirim untuk mengirim permintaan. Jika header respons menyertakan Content-Type: text/event-stream, Apidog akan mendeteksi aliran SSE, mengurai data, dan menampilkannya secara real time.
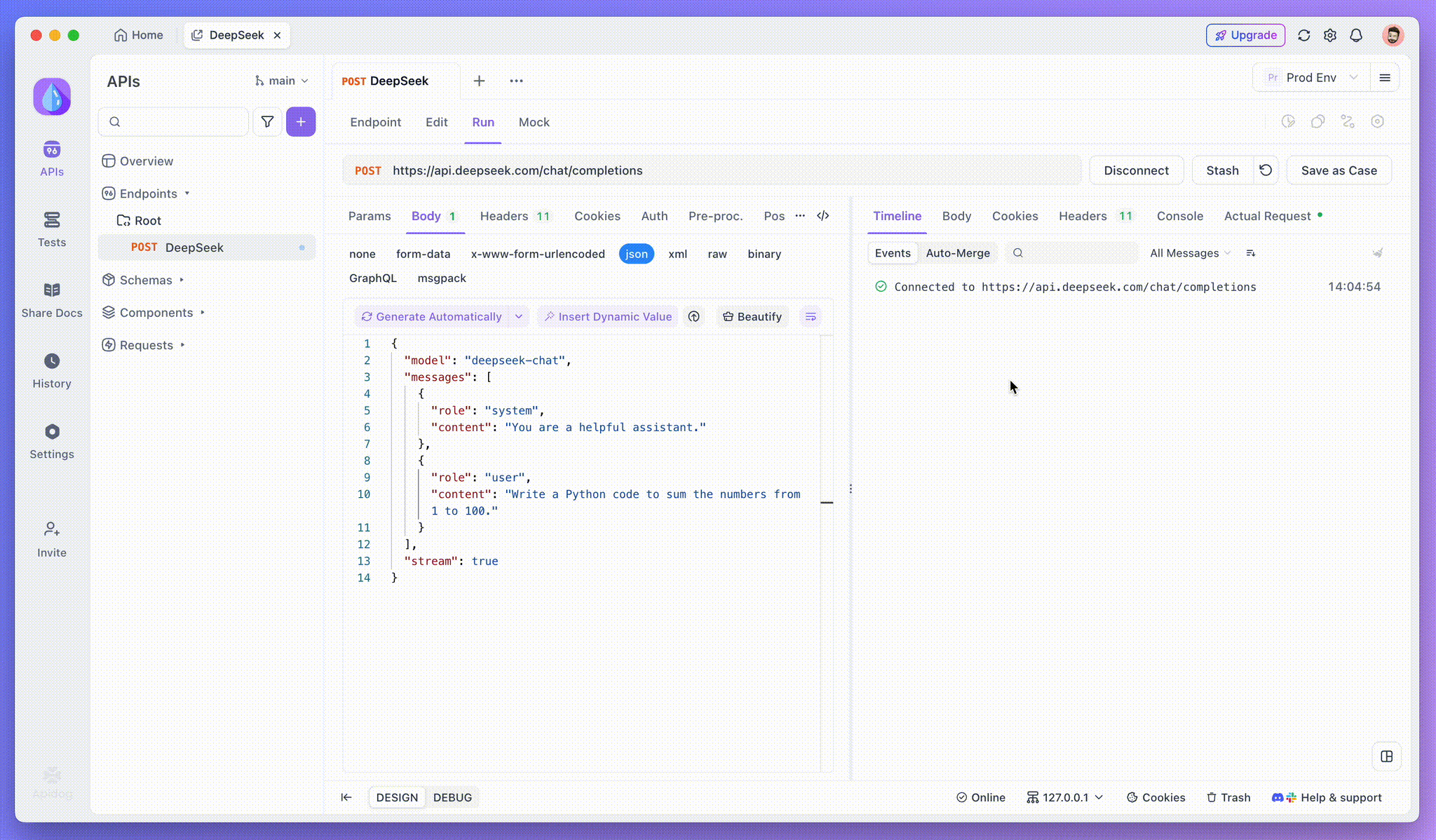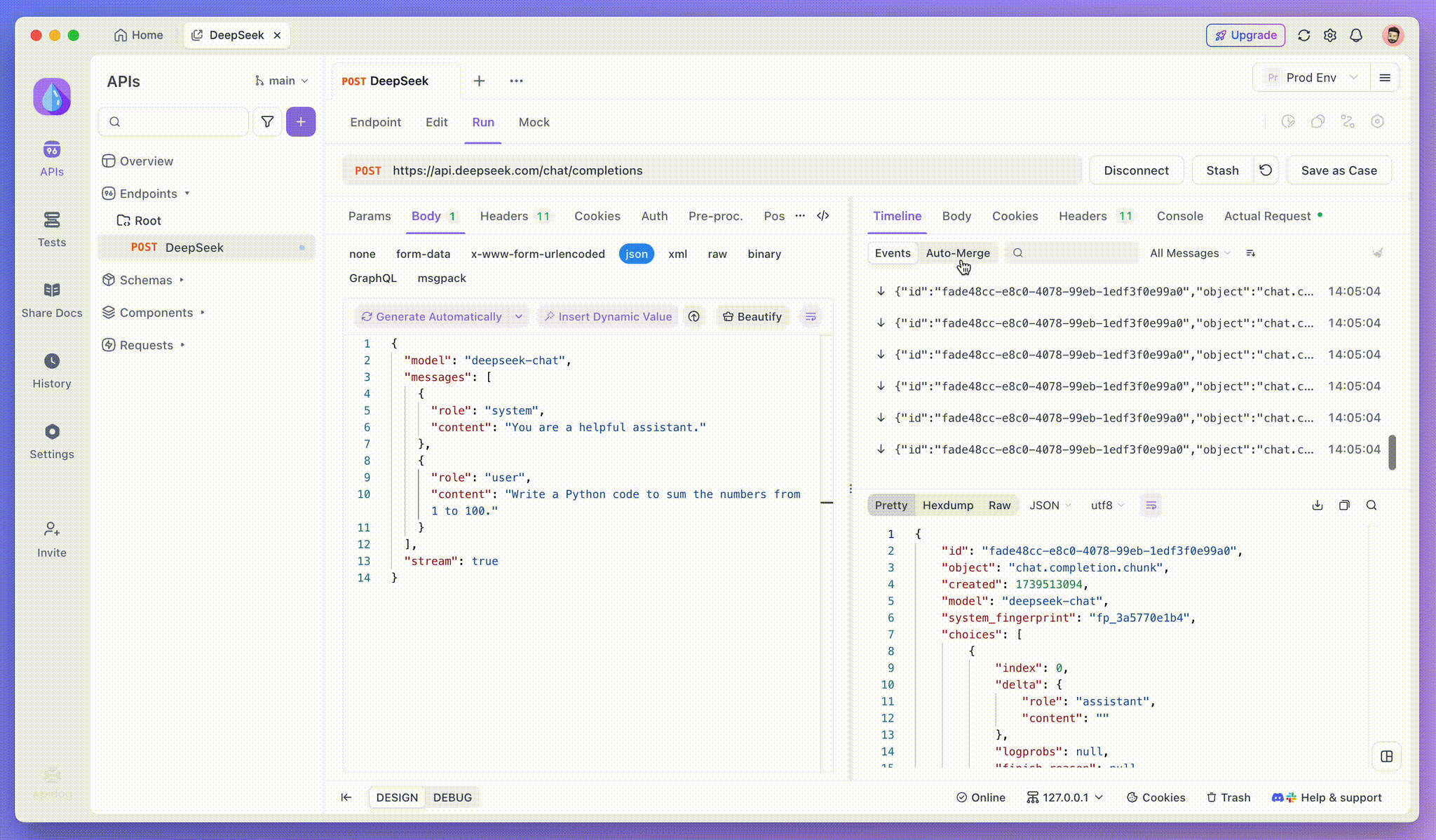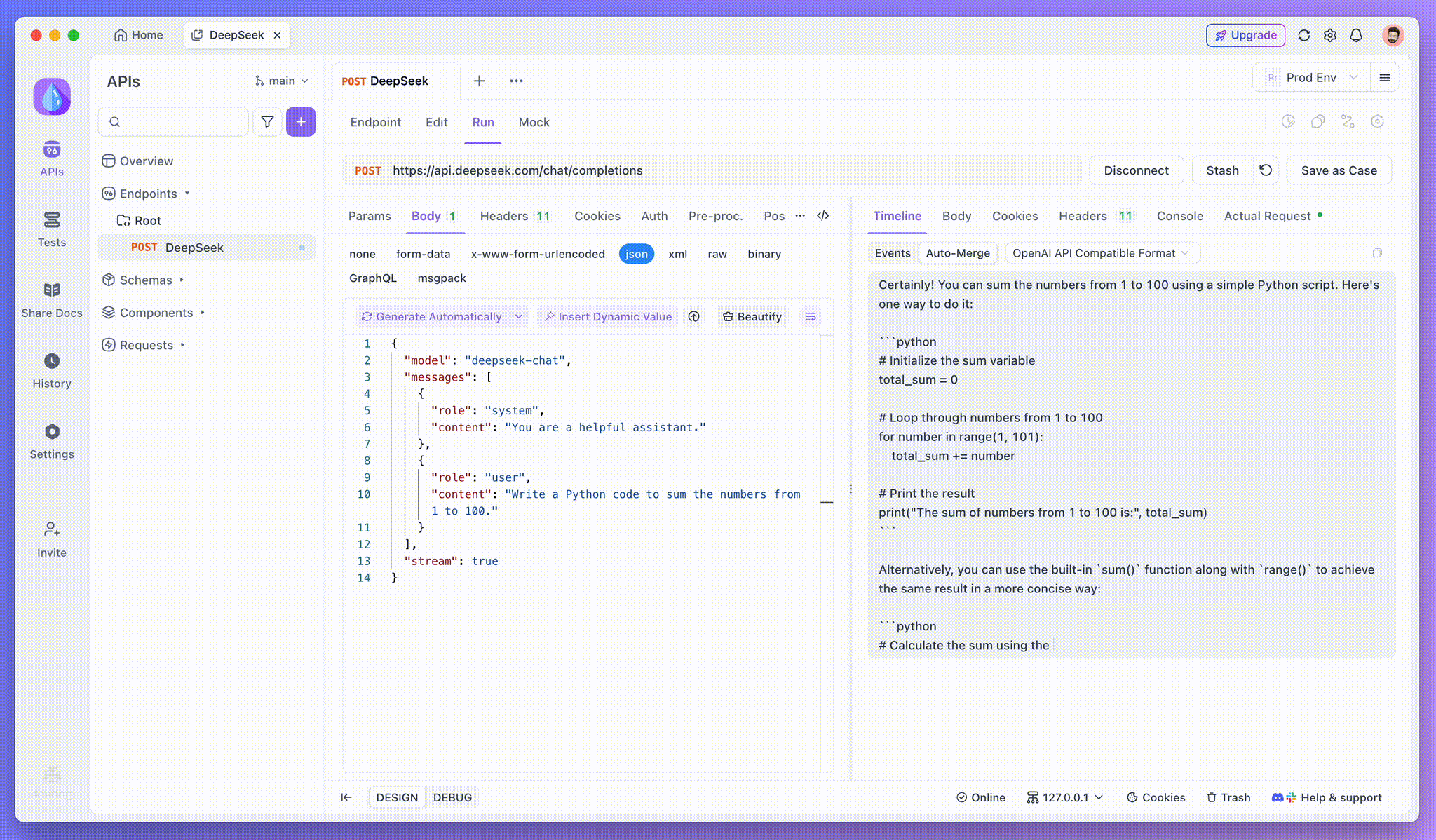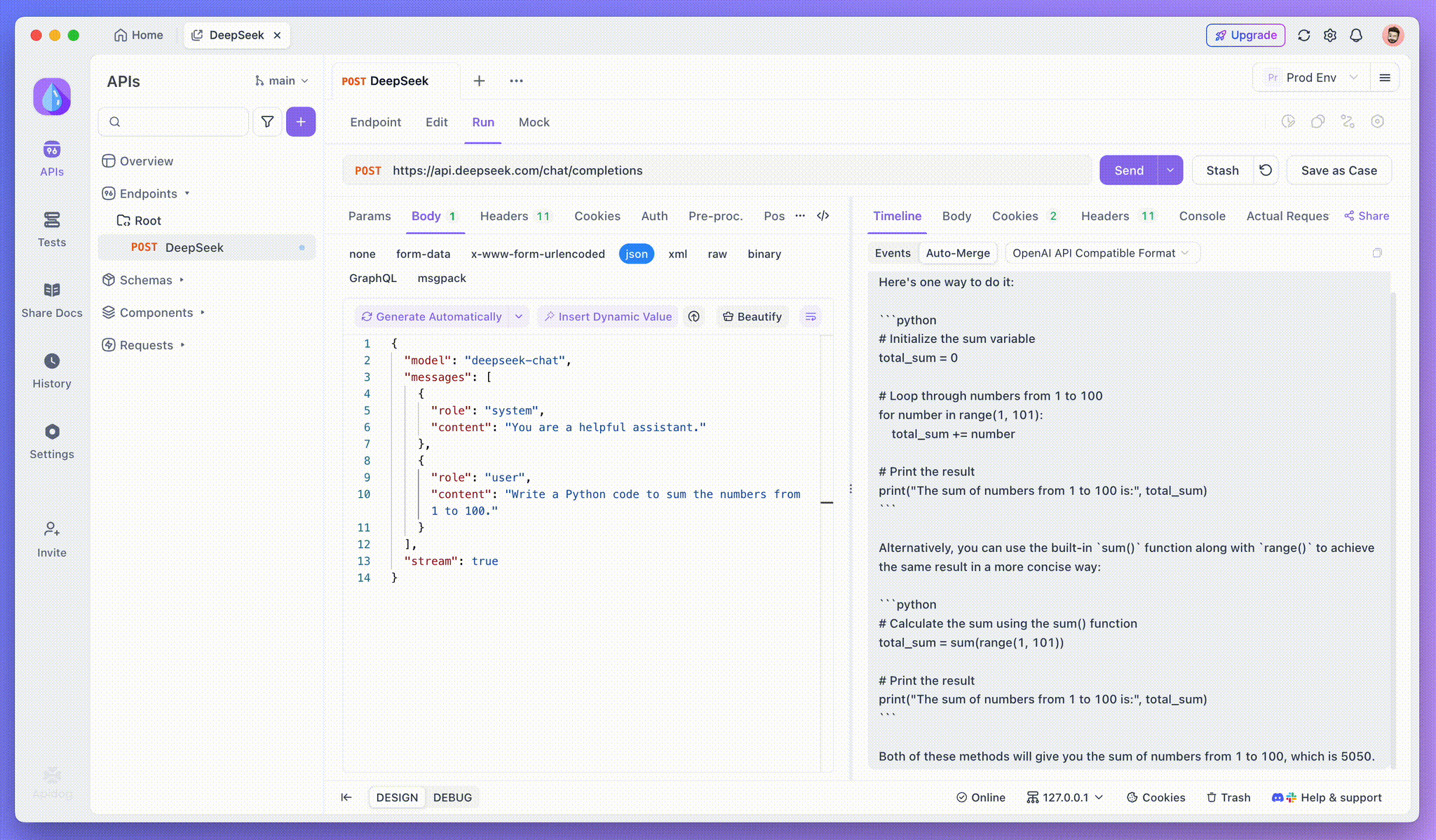
Langkah 3: Lihat Respons Waktu Nyata
Tampilan Timeline Apidog diperbarui secara real time saat model AI mengalirkan respons, menampilkan setiap fragmen secara dinamis. Ini memungkinkan Anda untuk melacak proses berpikir AI dan mendapatkan wawasan tentang generasi outputnya.
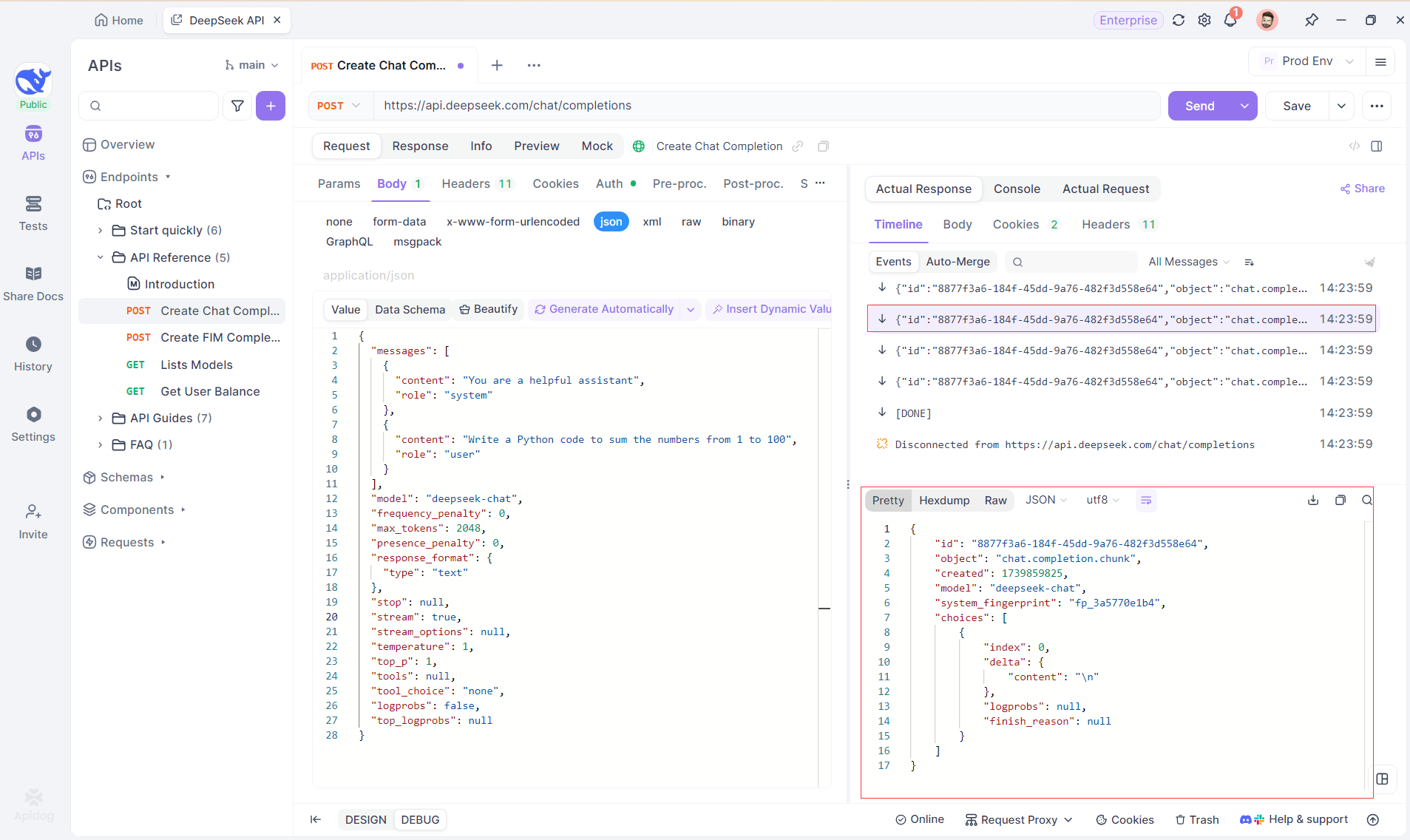
Langkah 4: Melihat Respons SSE dalam Balasan Lengkap
SSE mengalirkan data dalam fragmen, membutuhkan penanganan ekstra. Fitur Gabung Otomatis Apidog memecahkan masalah ini dengan secara otomatis menggabungkan respons AI yang terfragmentasi dari model seperti OpenAI, Gemini, atau Claude menjadi output yang lengkap.
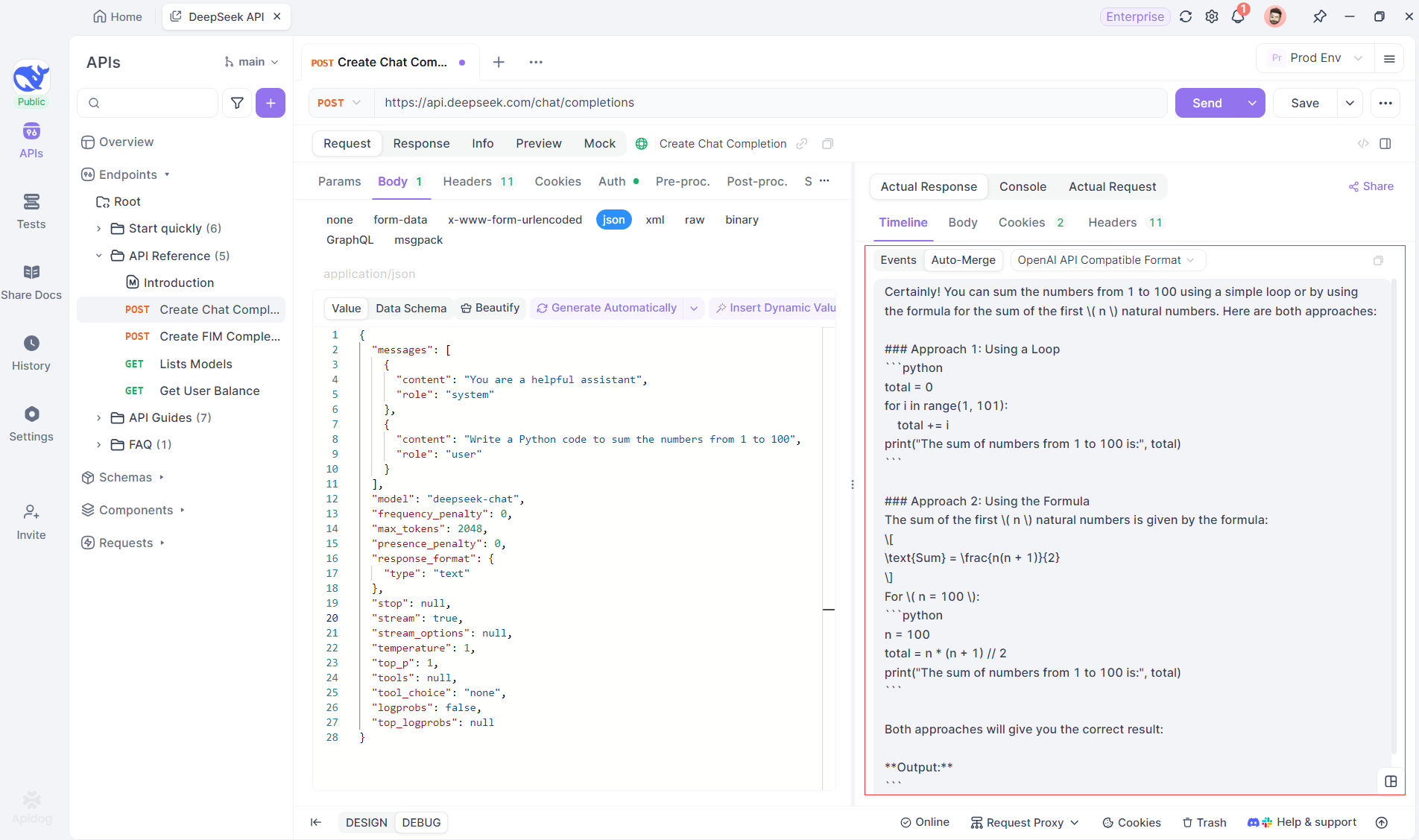
Fitur Gabung Otomatis Apidog menghilangkan penanganan data manual dengan secara otomatis menggabungkan respons AI yang terfragmentasi dari model seperti OpenAI, Gemini, atau Claude.
Untuk model penalaran seperti DeepSeek R1, Tampilan Timeline Apidog secara visual memetakan proses berpikir AI, membuatnya lebih mudah untuk men-debug dan memahami bagaimana kesimpulan dibentuk.
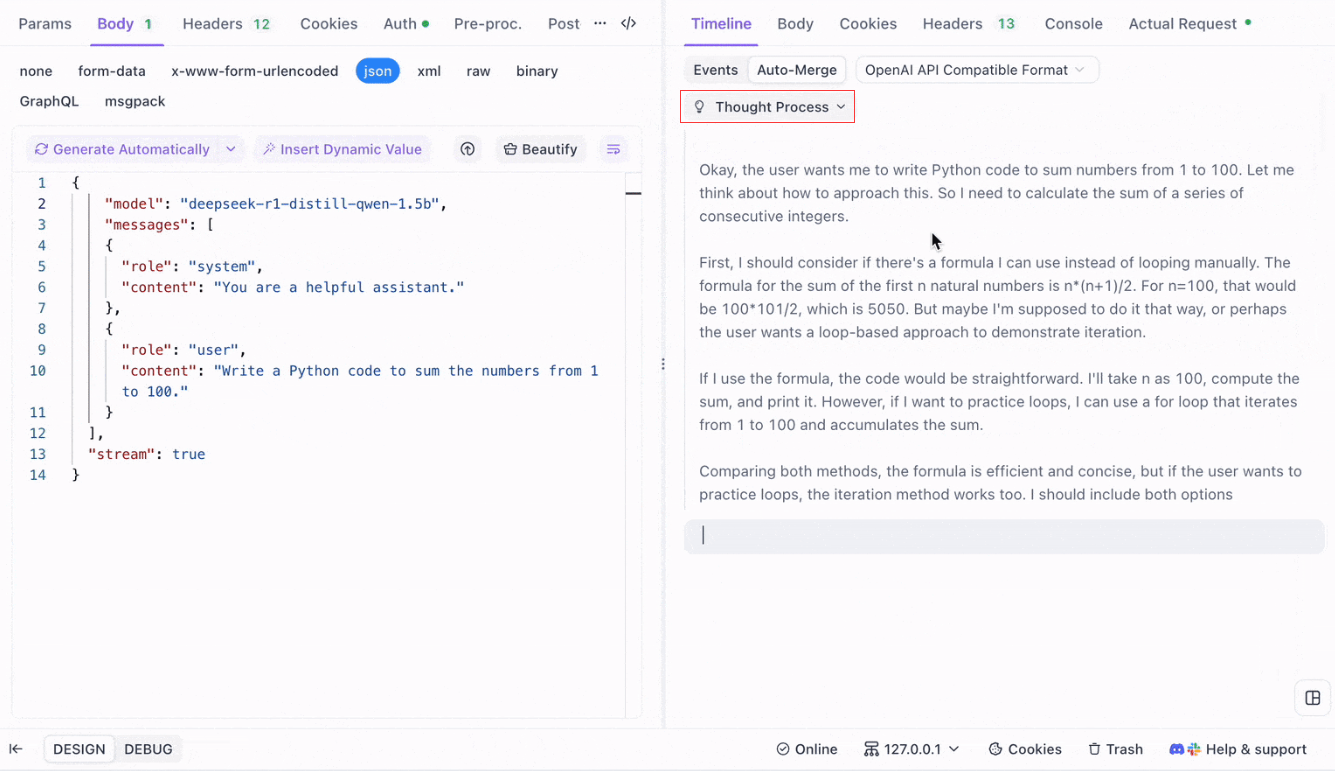
Apidog dengan mulus mengenali dan menggabungkan respons AI dari:
- Format API OpenAI
- Format API Gemini
- Format API Claude
Ketika respons cocok dengan format ini, Apidog secara otomatis menggabungkan fragmen, menghilangkan penjahitan manual dan menyederhanakan debugging SSE.
Kesimpulan dan Langkah Selanjutnya
Kita telah membahas banyak hal hari ini! Untuk meringkas, berikut adalah lima alat luar biasa untuk menjalankan LLM secara lokal:
- Llama.cpp: Ideal untuk pengembang yang menginginkan alat baris perintah yang ringan, cepat, dan sangat efisien dengan dukungan perangkat keras yang luas.
- GPT4All: Ekosistem lokal-pertama yang berjalan pada perangkat keras kelas konsumen, menawarkan antarmuka intuitif dan kinerja yang kuat.
- LM Studio: Sempurna untuk mereka yang lebih menyukai antarmuka grafis, dengan pengelolaan model yang mudah dan opsi kustomisasi yang luas.
- Ollama: Alat baris perintah yang kuat dengan kemampuan multimodal dan pengemasan model yang mulus melalui sistem "Modelfile"-nya.
- Jan: Platform sumber terbuka yang mengutamakan privasi yang berjalan sepenuhnya offline, menawarkan kerangka kerja yang dapat diperluas untuk mengintegrasikan berbagai LLM.
Masing-masing alat ini menawarkan keuntungan unik, baik itu kinerja, kemudahan penggunaan, atau privasi. Bergantung pada persyaratan proyek Anda, salah satu solusi ini mungkin sangat cocok untuk kebutuhan Anda. Keindahan alat LLM lokal adalah bahwa mereka memberdayakan Anda untuk menjelajahi dan bereksperimen tanpa khawatir tentang kebocoran data, biaya berlangganan, atau latensi jaringan.
Ingatlah bahwa bereksperimen dengan LLM lokal adalah proses pembelajaran. Jangan ragu untuk mencampur dan mencocokkan alat-alat ini, menguji berbagai konfigurasi, dan melihat mana yang paling sesuai dengan alur kerja Anda. Selain itu, jika Anda mengintegrasikan model-model ini ke dalam aplikasi Anda sendiri, alat seperti Apidog dapat membantu Anda mengelola dan menguji endpoint API LLM Anda menggunakan Server-sent Events (SSE) dengan mulus. Jangan lupa untuk mengunduh Apidog secara gratis dan tingkatkan pengalaman pengembangan lokal Anda.
Langkah Selanjutnya
- Eksperimen: Pilih salah satu alat dari daftar kami dan siapkan di mesin Anda. Bermain-main dengan model dan pengaturan yang berbeda untuk memahami bagaimana perubahan memengaruhi output.
- Integrasikan: Jika Anda mengembangkan aplikasi, gunakan alat LLM lokal sebagai bagian dari backend Anda. Banyak dari alat ini menawarkan kompatibilitas API (misalnya, server inferensi lokal LM Studio) yang dapat membuat integrasi lebih lancar.
- Berkontribusi: Sebagian besar proyek ini adalah sumber terbuka. Jika Anda menemukan bug, fitur yang hilang, atau hanya memiliki ide untuk perbaikan, pertimbangkan untuk berkontribusi pada komunitas. Masukan Anda dapat membantu membuat alat-alat ini menjadi lebih baik.
- Pelajari Lebih Lanjut: Terus jelajahi dunia LLM dengan membaca topik-topik seperti kuantisasi model, teknik optimasi, dan rekayasa perintah. Semakin banyak Anda memahami, semakin Anda dapat memanfaatkan model-model ini secara maksimal.
Sekarang, Anda seharusnya memiliki dasar yang kuat untuk memilih alat LLM lokal yang tepat untuk proyek Anda. Lanskap teknologi LLM berkembang pesat, dan menjalankan model secara lokal adalah langkah kunci menuju membangun solusi AI yang privat, terukur, dan berkinerja tinggi.
Saat Anda bereksperimen dengan alat-alat ini, Anda akan menemukan bahwa kemungkinannya tidak terbatas. Baik Anda sedang mengerjakan chatbot, asisten kode, atau alat penulisan kreatif khusus, LLM lokal dapat menawarkan fleksibilitas dan kekuatan yang Anda butuhkan. Nikmati perjalanannya, dan selamat membuat kode!


