
Dalam dunia kecerdasan buatan yang berkembang pesat, kemampuan untuk melakukan streaming respons dari Large Language Models (LLM) secara waktu nyata telah menjadi penting untuk meningkatkan interaksi pengguna dan meningkatkan kinerja aplikasi secara keseluruhan. Salah satu cara terbaik untuk mencapai ini adalah melalui Server-Sent Events (SSE), teknologi yang kuat yang dibangun di atas protokol HTTP yang menyediakan saluran komunikasi satu arah antara server dan klien. Dalam artikel ini, kita akan membahas bagaimana SSE bekerja, bagaimana ia dapat digunakan untuk melakukan streaming respons LLM, dan bagaimana alat seperti Apidog dapat menyederhanakan debugging dan meningkatkan efisiensi pengembangan.
Apa Itu Server-Sent Events (SSE)?
Server-Sent Events adalah teknologi komunikasi waktu nyata yang ringan berdasarkan protokol HTTP. Dengan SSE, server membangun koneksi satu arah yang berkelanjutan ke klien. Server mendorong pembaruan ke klien tanpa perlu klien berulang kali meminta data baru. Ini membuat SSE ideal untuk melakukan streaming konten dinamis seperti pembaruan waktu nyata, notifikasi langsung, dan, dalam kasus model AI, respons berkelanjutan dari LLM.
Keindahan SSE terletak pada kesederhanaan dan overhead yang rendah. Tidak seperti WebSockets, yang memungkinkan komunikasi dua arah, SSE dirancang untuk skenario di mana server perlu mendorong data secara terus menerus ke klien. Ini sangat berguna saat melakukan streaming konten yang dihasilkan AI secara waktu nyata, karena klien dapat melihat proses berpikir model saat ia menghasilkan setiap bagian dari respons.
Bagaimana SSE Bekerja dalam Streaming LLM
Saat menggunakan LLM, terutama dengan model kompleks seperti DeepSeek R1, respons sering kali tiba dalam potongan-potongan yang terfragmentasi. Dengan SSE, setiap fragmen ini dikirim sebagai "event" terpisah dalam stream. Ini memungkinkan pengembang dan pengguna akhir untuk menyaksikan seluruh proses secara waktu nyata. Saat server mengirim setiap event, klien segera diperbarui, memastikan bahwa pengguna menerima informasi terbaru yang tersedia.
Manfaat Menggunakan SSE untuk Respons Model AI
- Pengiriman Data Waktu Nyata: SSE memungkinkan klien untuk menerima pembaruan segera setelah dihasilkan, tanpa penundaan.
- Komunikasi yang Efisien: Server mengirim data hanya ketika event baru terjadi, mengurangi permintaan yang tidak perlu dan meningkatkan efisiensi sistem.
- Implementasi Sisi Klien yang Disederhanakan: Dengan SSE, klien tidak memerlukan logika kompleks untuk menangani pembaruan data berkelanjutan, karena mereka secara otomatis diterima dan ditampilkan.
Menyiapkan Debugging SSE dengan Apidog
Untuk memulai debugging SSE menggunakan Apidog, pastikan Anda menggunakan versi 2.6.49 atau lebih tinggi. Apidog menyediakan platform yang mudah digunakan untuk bekerja dengan API, sehingga lebih mudah untuk menangani koneksi SSE dan men-debug aliran data waktu nyata dari LLM seperti DeepSeek R1.
Langkah 1: Buat Endpoint Baru di Apidog
Mulailah dengan membuat proyek HTTP baru di Apidog. Ini memungkinkan Anda untuk menyiapkan ruang kerja untuk menguji dan men-debug permintaan API Anda. Setelah proyek Anda disiapkan, tambahkan endpoint baru dengan memasukkan URL model AI. Di sinilah aliran SSE akan berasal. Dalam contoh ini, kita akan menggunakan DeepSeek sebagai model AI. (TIP PRO: Anda dapat mengkloning proyek API DeepSeek siap pakai di API Hub Apidog).
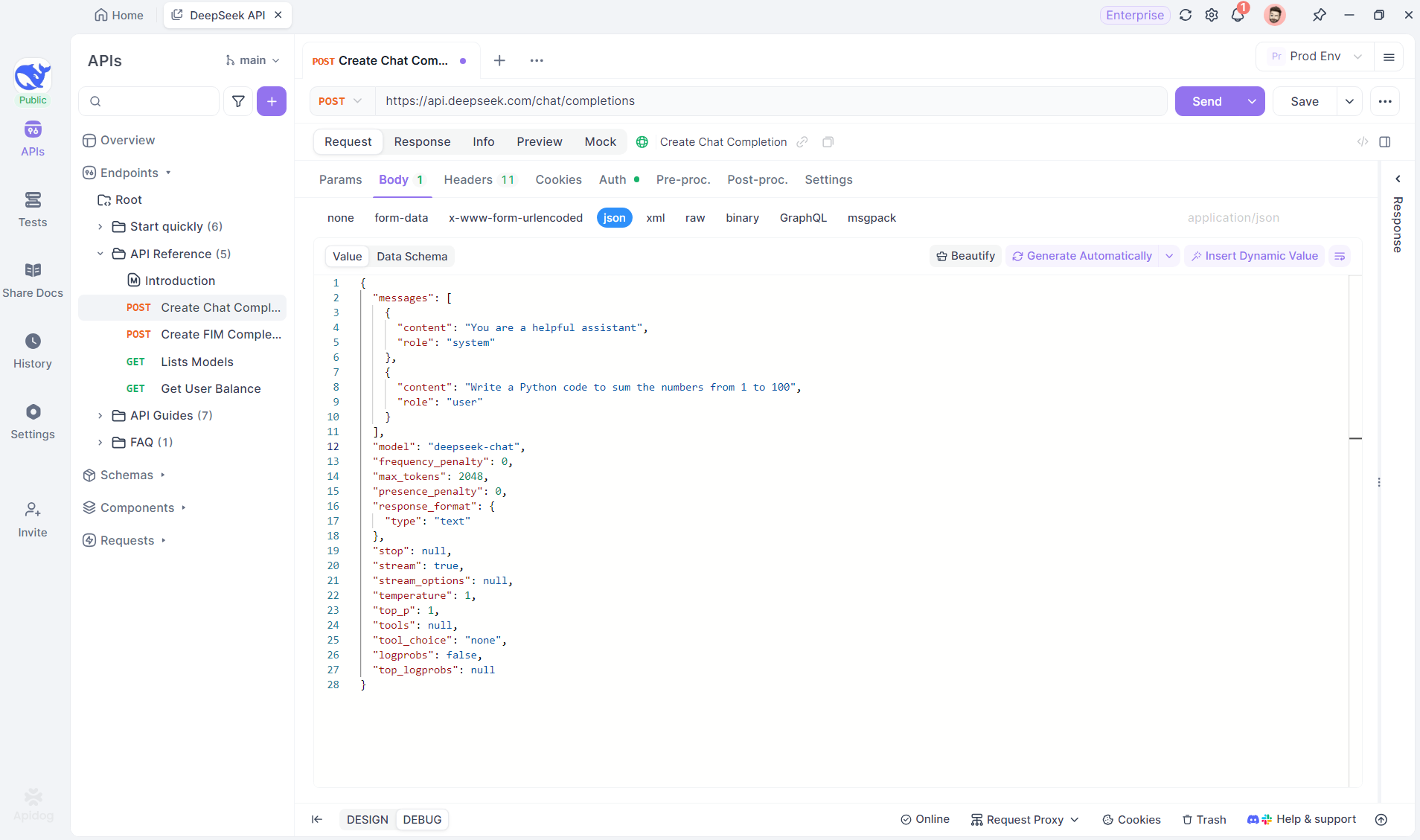
Langkah 2: Kirim Permintaan
Setelah menambahkan endpoint, kirim permintaan ke server dengan mengklik Send di kanan atas. Jika header respons server menyertakan Content-Type: text/event-stream, Apidog akan secara otomatis mengenali bahwa data sedang di-streaming melalui SSE. Sistem cerdas Apidog akan mengurai respons ini dan menampilkannya di panel respons, memungkinkan Anda untuk melihat aliran waktu nyata saat sedang dihasilkan.
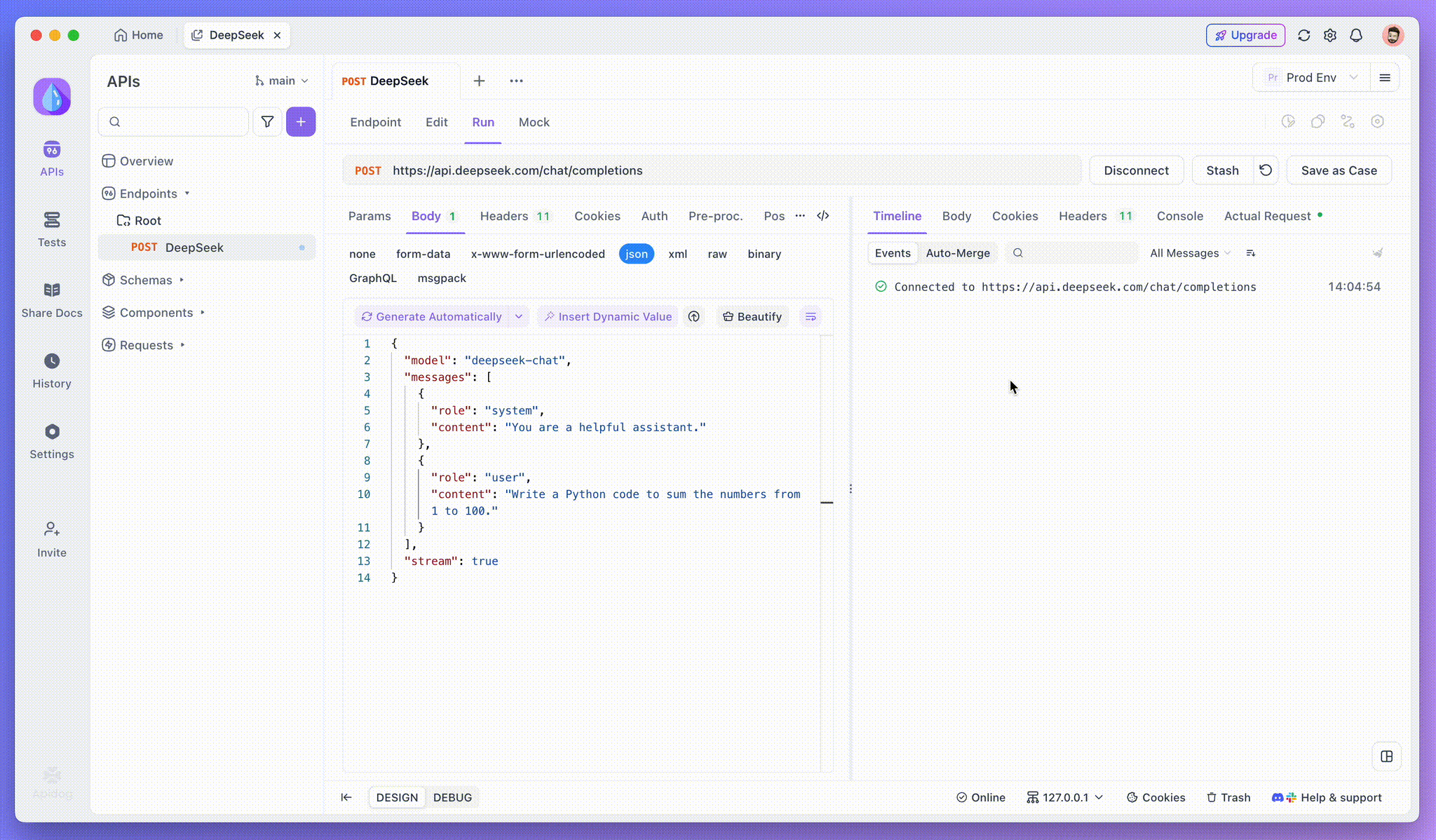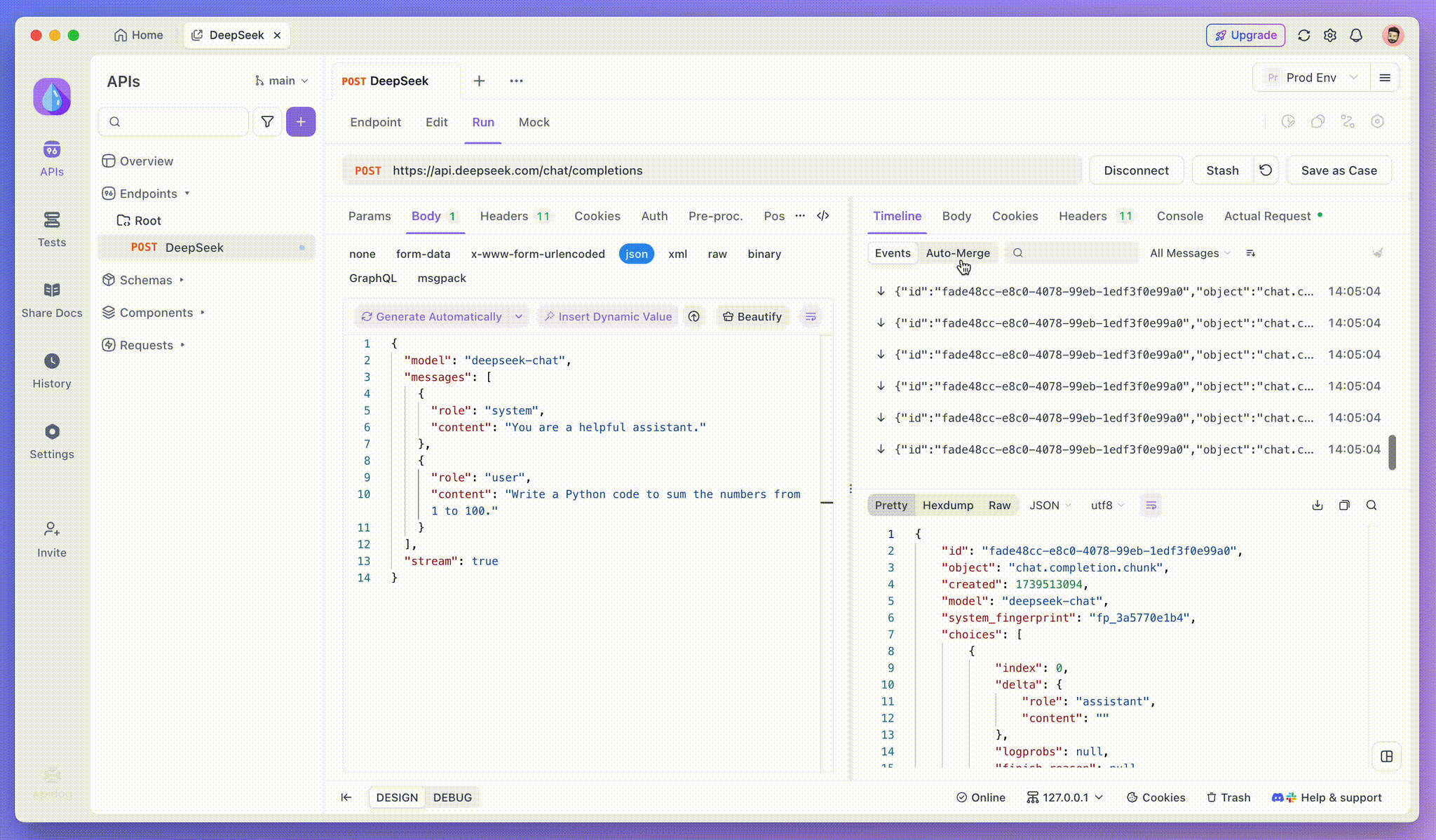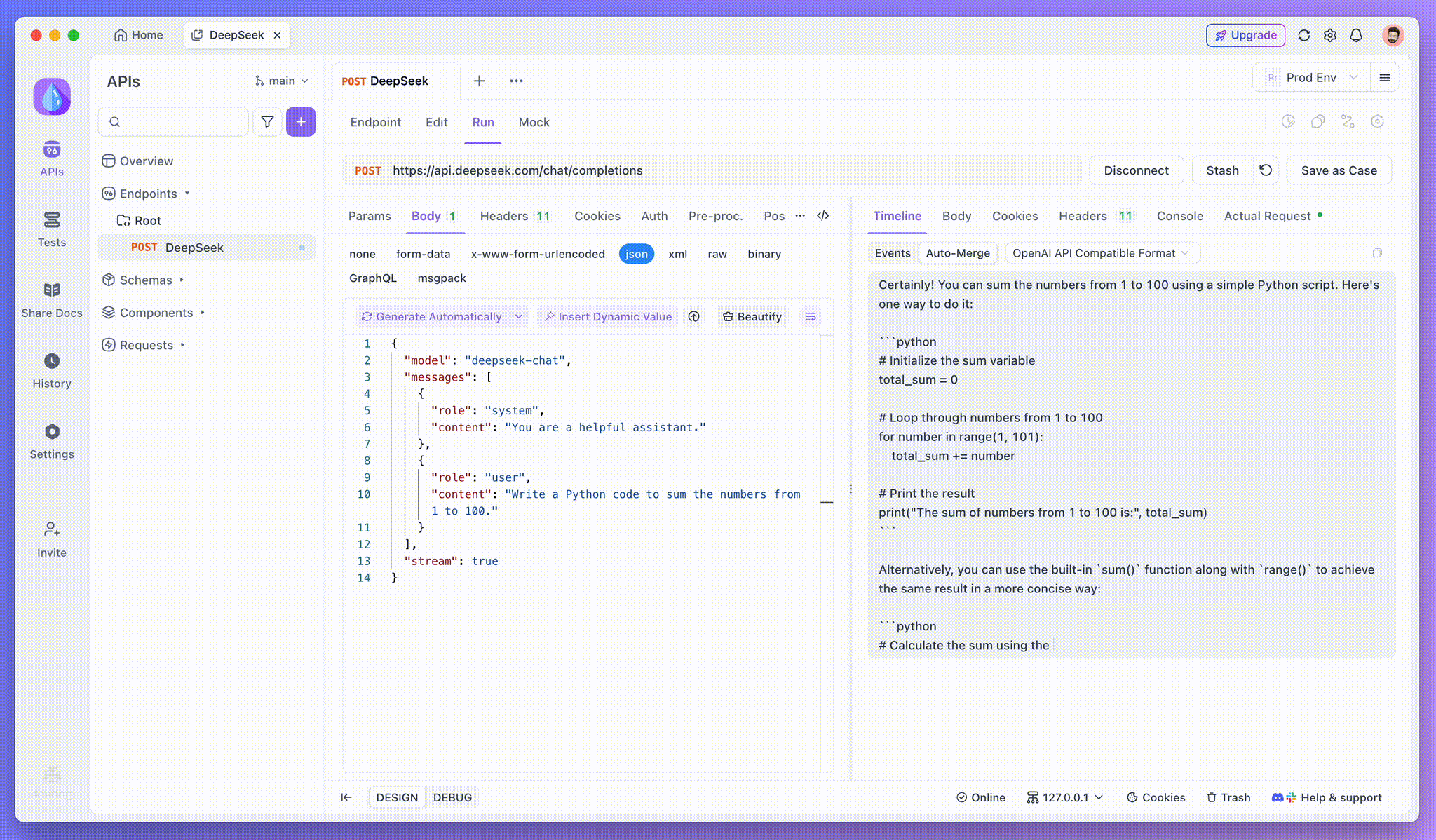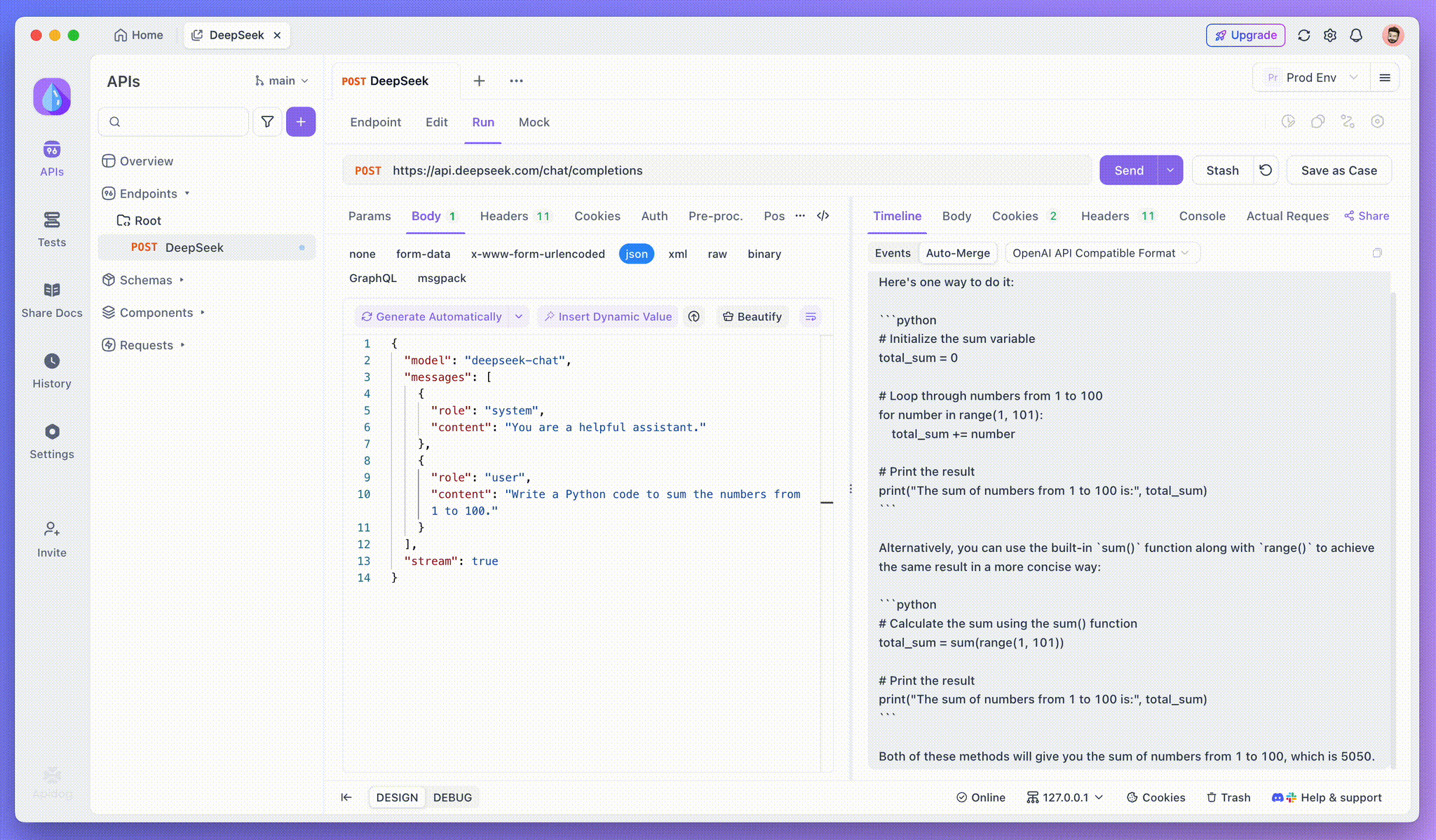
Langkah 3: Lihat Respons Waktu Nyata
Timeline View Apidog adalah tempat keajaiban terjadi. Saat model AI melakukan streaming responsnya, tampilan Timeline diperbarui secara dinamis, menampilkan setiap fragmen respons secara waktu nyata. Tampilan ini memungkinkan Anda untuk melacak evolusi proses berpikir AI, memberi Anda wawasan berharga tentang bagaimana ia menghasilkan output akhir.
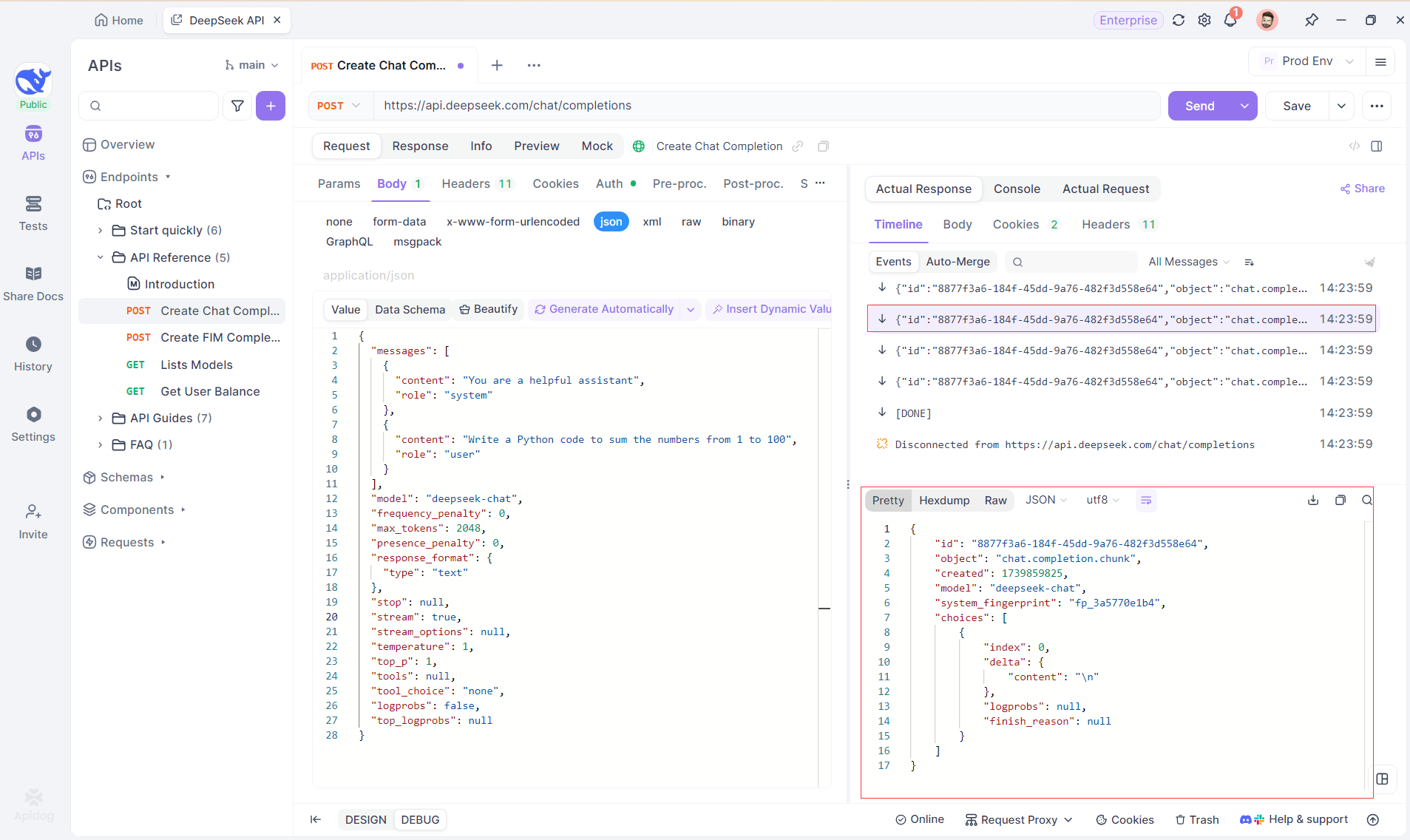
Langkah 4: Melihat Respons SSE dalam Balasan Lengkap
Meskipun SSE menyediakan cara yang ampuh untuk melakukan streaming data, seringkali memerlukan penanganan tambahan untuk menangani respons yang terfragmentasi. Fitur Auto-Merge Apidog dirancang untuk mengatasi tantangan ini. Saat melakukan streaming respons AI, data sering kali datang dalam beberapa fragmen, terutama dengan model seperti OpenAI, Gemini, atau Claude. Apidog secara otomatis menggabungkan fragmen-fragmen ini menjadi respons lengkap yang terpadu.
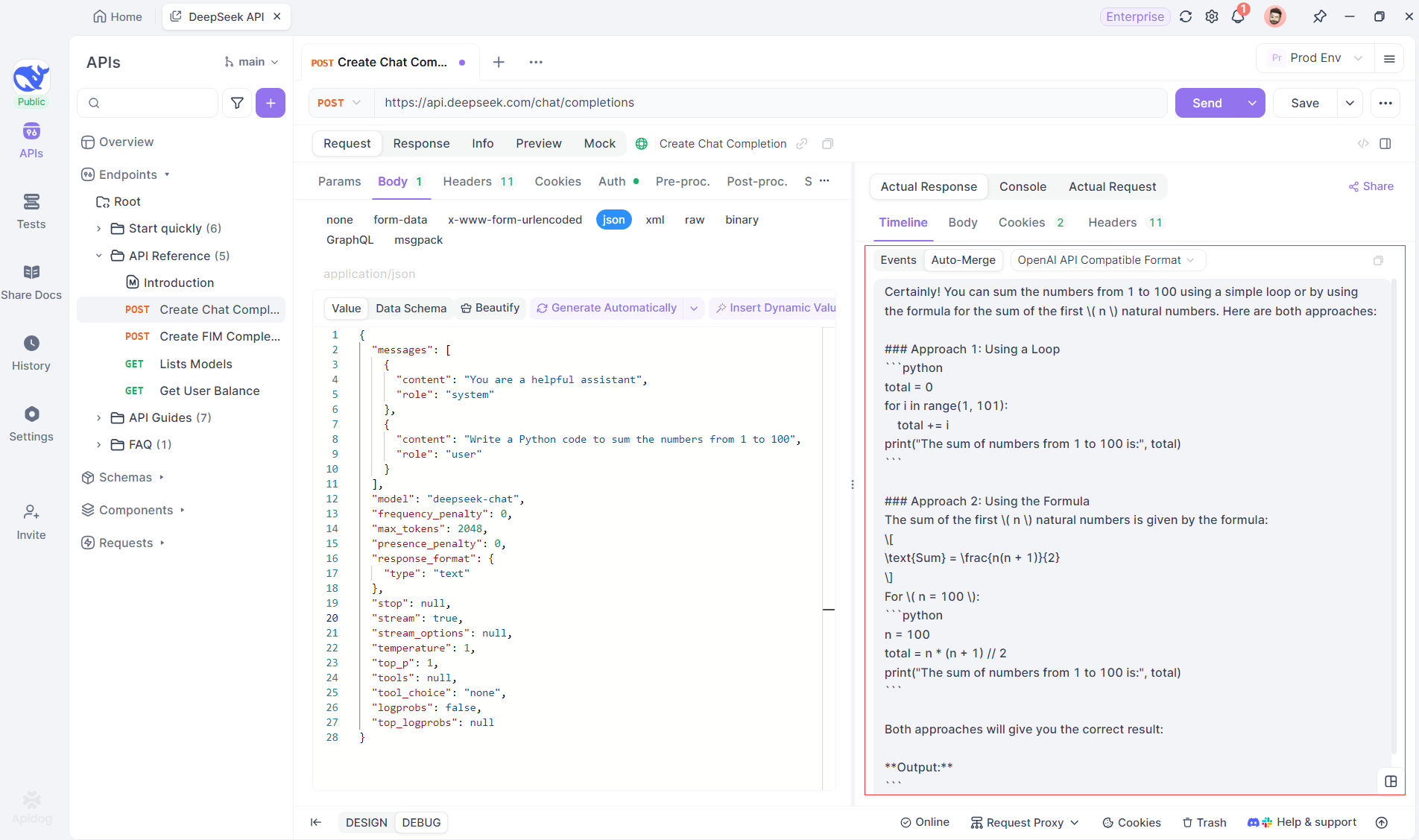
Fitur ini menghilangkan kebutuhan untuk penanganan data manual, memungkinkan pengembang untuk fokus pada analisis output AI alih-alih berurusan dengan kompleksitas penggabungan pesan yang terfragmentasi.
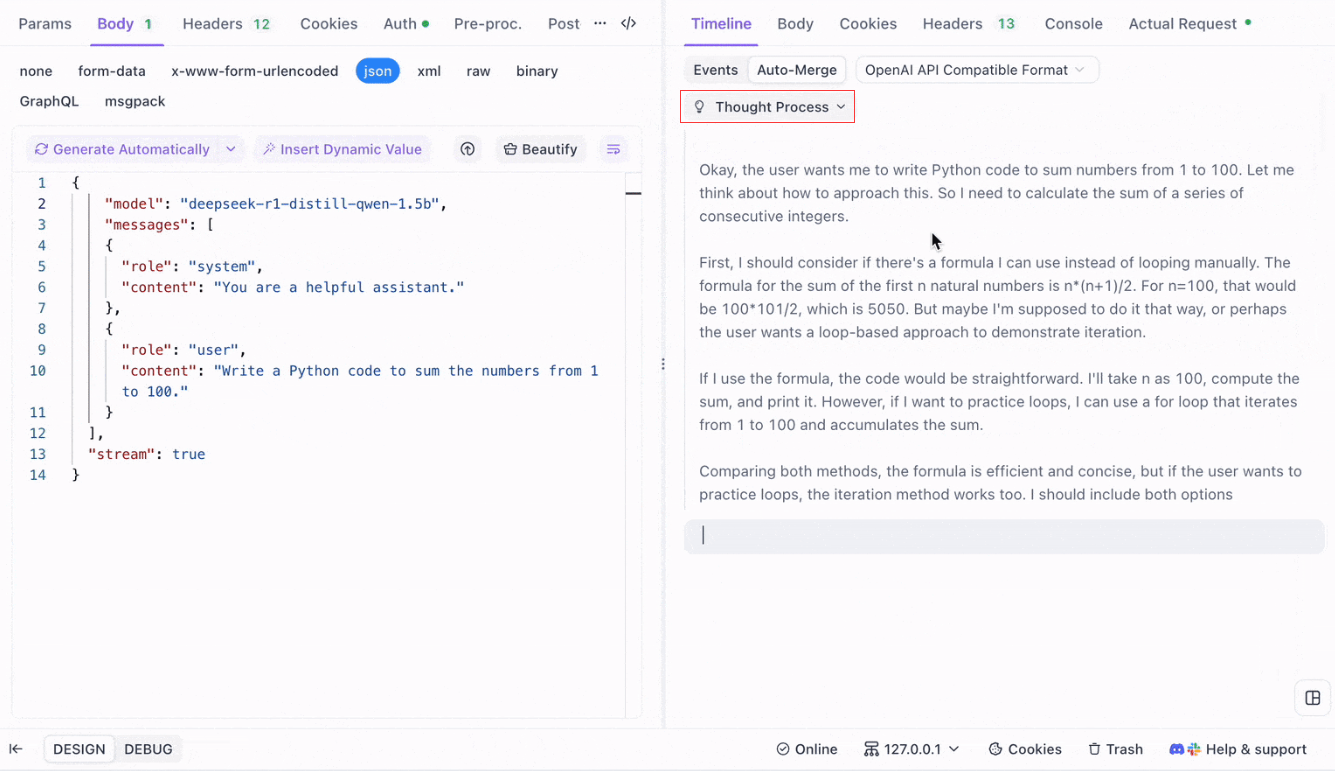
Memvisualisasikan Proses Berpikir Model Penalaran: Salah satu fitur menonjol saat bekerja dengan model penalaran seperti DeepSeek R1 adalah kemampuan Apidog untuk menampilkan proses berpikir model secara langsung di tampilan Timeline.
Saat AI menghasilkan respons, Apidog tidak hanya menampilkan data respons tetapi juga memberikan representasi visual tentang bagaimana model sampai pada kesimpulannya. Ini menawarkan cara yang lebih intuitif untuk men-debug dan memahami penalaran di balik respons AI.
Format yang Didukung untuk Auto-Merge
Apidog dapat secara otomatis mengenali dan menggabungkan respons dari beberapa format model AI populer:
- Format OpenAI API
- Format Gemini API
- Format Claude API
Ketika respons dari model AI cocok dengan salah satu format ini, Apidog dengan mulus menggabungkan fragmen-fragmen tersebut menjadi balasan lengkap. Ini membuat debugging respons SSE lebih efisien, karena pengembang tidak perlu menjahit potongan-potongan tersebut secara manual.
Mengapa Menggunakan Auto-Merge untuk Debugging LLM?
- Efisiensi Waktu: Pengembang dapat menghindari tugas yang membosankan untuk menggabungkan fragmen respons secara manual.
- Debugging yang Ditingkatkan: Respons lengkap yang terpadu memungkinkan analisis yang lebih jelas tentang perilaku AI.
- Wawasan yang Ditingkatkan: Memvisualisasikan proses berpikir model menambahkan lapisan pemahaman ekstra, terutama untuk model kompleks seperti DeepSeek R1.
Menyesuaikan Aturan Debugging SSE di Apidog
Dalam beberapa kasus, fitur Auto-Merge bawaan mungkin tidak berfungsi seperti yang diharapkan, terutama saat berhadapan dengan model AI khusus atau format non-standar. Apidog memungkinkan Anda untuk menyesuaikan cara respons ditangani menggunakan Aturan Ekstraksi JSONPath atau Skrip Pasca-Pemroses.
Mengonfigurasi Aturan Ekstraksi JSONPath
Jika respons SSE dalam format JSON tetapi tidak sesuai dengan aturan pengenalan bawaan untuk format seperti OpenAI, Claude atau Gemini, Anda dapat mengonfigurasi JSONPath untuk mengekstrak konten yang diperlukan.
Misalnya, pertimbangkan respons SSE mentah berikut:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}Untuk mengekstrak konten dari bidang message.content, Anda akan mengonfigurasi JSONPath sebagai berikut: $.choices[0].message.content
Konfigurasi ini akan menarik konten: Hi
Dengan menggunakan JSONPath, Anda dapat menyesuaikan cara Apidog menangani respons, memastikan bahwa Anda selalu mengekstrak data yang benar.
Menggunakan Skrip Pasca-Pemroses untuk SSE Non-JSON
Untuk respons non-JSON, Apidog menyediakan kemampuan untuk menggunakan Skrip Pasca-Pemroses untuk memanipulasi dan mengekstrak data dari aliran SSE. Ini memungkinkan Anda untuk menulis skrip khusus yang menangani format data tertentu yang tidak sesuai dengan struktur JSON tradisional.
Jika Anda berurusan dengan format model yang tidak didukung, Anda juga dapat menghubungi dukungan teknis Apidog untuk meminta agar format tersebut ditambahkan untuk dukungan bawaan.
Praktik Terbaik untuk Streaming Respons LLM dengan SSE
Saat melakukan streaming respons LLM menggunakan SSE, ada beberapa praktik terbaik yang perlu diingat untuk memastikan debugging yang lancar dan efisien:
- Tangani Fragmentasi dengan Baik: Selalu antisipasi bahwa respons model AI mungkin datang dalam beberapa fragmen, dan gunakan fitur
Auto-Mergeuntuk menyederhanakan proses ini. - Uji dengan Model AI yang Berbeda: Gunakan model seperti OpenAI, Gemini, dan DeepSeek R1 untuk menjelajahi perilaku format yang berbeda dan memastikan pengaturan Anda dapat menangani beberapa jenis respons.
- Gunakan Timeline View untuk Debugging: Manfaatkan tampilan Timeline Apidog untuk mendapatkan rincian langkah demi langkah secara waktu nyata tentang bagaimana respons berkembang, terutama untuk model AI yang kompleks.
- Sesuaikan untuk Format Non-Standar: Jika perlu, gunakan JSONPath atau Skrip Pasca-Pemroses untuk menangani format SSE non-standar atau untuk menyempurnakan proses ekstraksi data.
Kesimpulan: Meningkatkan Streaming LLM dengan SSE
Server-sent events menyediakan mekanisme yang ampuh untuk melakukan streaming respons waktu nyata dari model AI, terutama saat berhadapan dengan LLM yang besar dan kompleks. Dengan menggunakan alat debugging SSE Apidog, termasuk fitur Auto-Merge dan visualisasi yang ditingkatkan, pengembang dapat menyederhanakan proses penanganan respons yang terfragmentasi dan mendapatkan wawasan yang lebih dalam tentang perilaku model. Apakah Anda sedang men-debug respons dari model populer seperti OpenAI atau bekerja dengan solusi AI khusus, Apidog memastikan bahwa Anda dapat dengan mudah melacak, menggabungkan, dan menganalisis data SSE dengan cara yang efisien dan berwawasan.


