
Pada tanggal 13 April 2025, SkyworkAI merilis seri Skywork-OR1 (Open Reasoner 1), yang terdiri dari tiga model: Skywork-OR1-Math-7B, Skywork-OR1-7B-Preview, dan Skywork-OR1-32B-Preview.
- Model-model ini dilatih menggunakan pembelajaran penguatan berbasis aturan skala besar yang secara khusus menargetkan kemampuan penalaran matematis dan kode.
- Model-model ini dibangun di atas arsitektur hasil distilasi DeepSeek: varian 7B menggunakan DeepSeek-R1-Distill-Qwen-7B sebagai basisnya, sementara model 32B dibangun di atas DeepSeek-R1-Distill-Qwen-32B.
Ingin platform Terintegrasi, All-in-One agar Tim Pengembang Anda dapat bekerja bersama dengan produktivitas maksimum?
Apidog memberikan semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!

Skywork-OR1-32B: Bukan Sekadar Model Penalaran Sumber Terbuka Lainnya
Model Skywork-OR1-32B-Preview berisi 32,8 miliar parameter dan menggunakan tipe tensor BF16 untuk presisi numerik. Model ini didistribusikan dalam format safetensors dan didasarkan pada arsitektur Qwen2. Menurut repositori model, ia mempertahankan arsitektur yang sama dengan model dasar DeepSeek-R1-Distill-Qwen-32B, tetapi dengan pelatihan khusus untuk tugas penalaran matematis dan pengkodean.
Mari kita lihat beberapa info teknis dasar dari keluarga model Skywork:
Skywork-OR1-32B-Preview
- Jumlah parameter: 32,8 miliar
- Model dasar: DeepSeek-R1-Distill-Qwen-32B
- Tipe tensor: BF16
- Spesialisasi: Penalaran tujuan umum
- Kinerja utama:
- AIME24: 79,7 (Rata-rata@32)
- AIME25: 69,0 (Rata-rata@32)
- LiveCodeBench: 63,9 (Rata-rata@4)
Model 32B menunjukkan peningkatan 6,8 poin pada AIME24 dan peningkatan 10,0 poin pada AIME25 dibandingkan model dasarnya. Ia mencapai efisiensi parameter dengan memberikan kinerja yang sebanding dengan DeepSeek-R1 parameter 671B hanya dengan 4,9% parameter.
Skywork-OR1-Math-7B
- Jumlah parameter: 7,62 miliar
- Model dasar: DeepSeek-R1-Distill-Qwen-7B
- Tipe tensor: BF16
- Spesialisasi: Penalaran matematis
- Kinerja utama:
- AIME24: 69,8 (Rata-rata@32)
- AIME25: 52,3 (Rata-rata@32)
- LiveCodeBench: 43,6 (Rata-rata@4)
Model ini mengungguli DeepSeek-R1-Distill-Qwen-7B dasar secara signifikan pada tugas-tugas matematis (69,8 vs. 55,5 pada AIME24, 52,3 vs. 39,2 pada AIME25), yang menunjukkan efektivitas pendekatan pelatihan khusus.
Skywork-OR1-7B-Preview
- Jumlah parameter: 7,62 miliar
- Model dasar: DeepSeek-R1-Distill-Qwen-7B
- Tipe tensor: BF16
- Spesialisasi: Penalaran tujuan umum
- Kinerja utama:
- AIME24: 63,6 (Rata-rata@32)
- AIME25: 45,8 (Rata-rata@32)
- LiveCodeBench: 43,9 (Rata-rata@4)
Meskipun menunjukkan spesialisasi matematis yang lebih rendah daripada varian Math-7B, model ini menawarkan kinerja yang lebih seimbang antara tugas matematis dan pengkodean.
Dataset Pelatihan Skywork-OR1-32B
Dataset pelatihan Skywork-OR1 berisi:
- 110.000 soal matematika yang dapat diverifikasi dan beragam
- 14.000 pertanyaan pengkodean
- Semua bersumber dari dataset sumber terbuka
Alur Pemrosesan Data
- Estimasi Kesulitan Sadar Model: Setiap soal menjalani penilaian kesulitan relatif terhadap kemampuan model saat ini, yang memungkinkan pelatihan yang ditargetkan.
- Penilaian Kualitas: Pemfilteran ketat diterapkan sebelum pelatihan untuk memastikan kualitas dataset.
- Pemfilteran Offline dan Online: Proses pemfilteran dua tahap diterapkan untuk:
- Menghapus contoh suboptimal sebelum pelatihan (offline)
- Menyesuaikan pemilihan soal secara dinamis selama pelatihan (online)
4. Pengambilan Sampel Penolakan: Teknik ini digunakan untuk mengontrol distribusi contoh pelatihan, membantu mempertahankan kurva pembelajaran yang optimal.
Alur Pelatihan Pembelajaran Penguatan Tingkat Lanjut
Model-model ini menggunakan versi GRPO (Generative Reinforcement via Policy Optimization) yang disesuaikan dengan beberapa peningkatan teknis:
- Alur Pelatihan Multi-tahap: Pelatihan berlangsung melalui fase-fase berbeda, yang masing-masing dibangun di atas kemampuan yang diperoleh sebelumnya. Repositori GitHub menyertakan grafik yang memplot skor AIME24 terhadap langkah-langkah pelatihan, yang menunjukkan peningkatan kinerja yang jelas di setiap tahap.
- Kontrol Entropi Adaptif: Teknik ini secara dinamis menyesuaikan trade-off eksplorasi-eksploitasi selama pelatihan, mendorong eksplorasi yang lebih luas sambil mempertahankan stabilitas konvergensi.
- Fork Kustom Kerangka Kerja VERL: Model-model ini dilatih menggunakan versi modifikasi dari proyek VERL, yang secara khusus diadaptasi untuk tugas-tugas penalaran.
Anda dapat membaca makalah lengkapnya di sini.
Tolok Ukur Skywork-OR1-32B
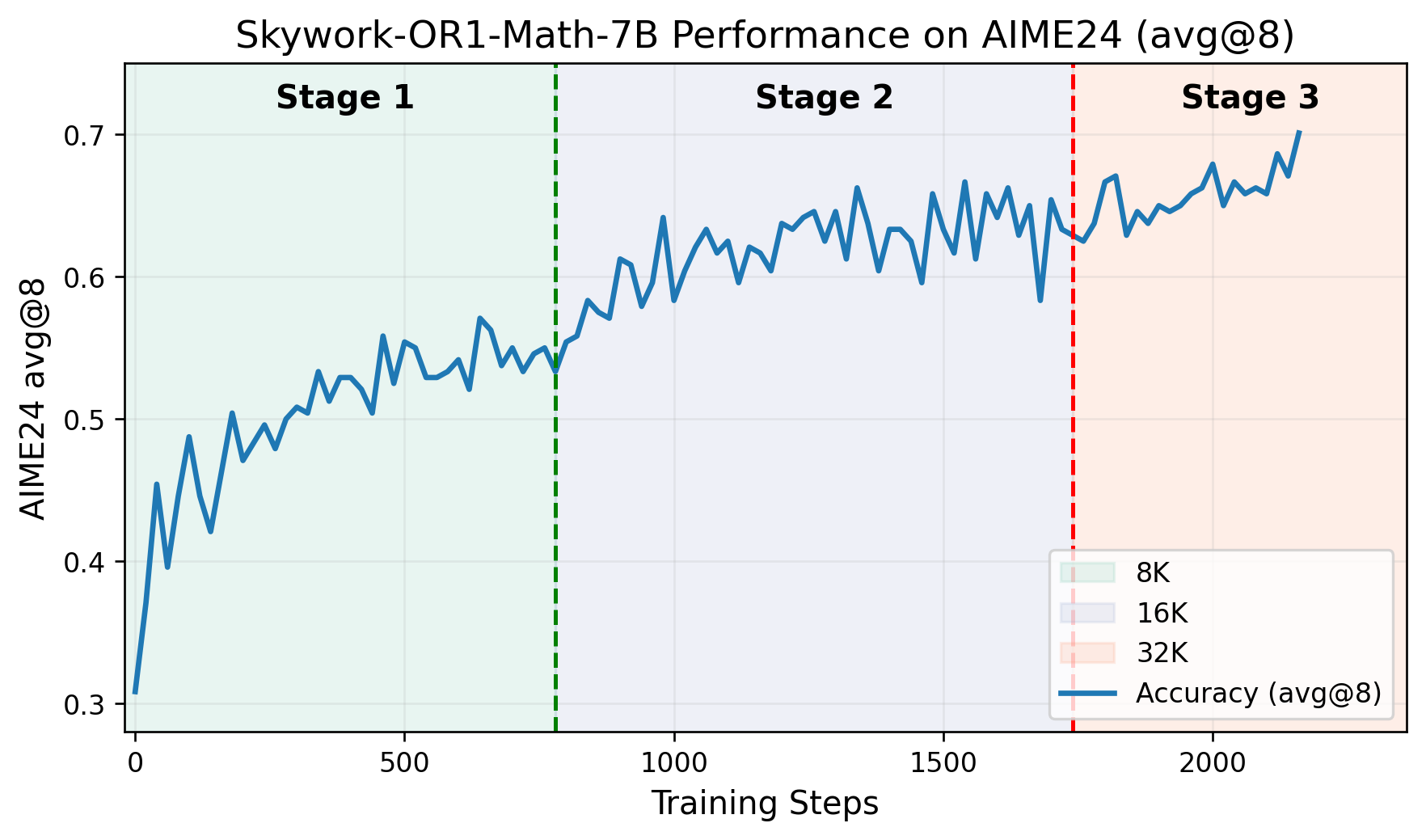
Spesifikasi teknis:
- Jumlah parameter: 32,8 miliar
- Tipe tensor: BF16
- Format model: Safetensors
- Keluarga arsitektur: Qwen2
- Model dasar: DeepSeek-R1-Distill-Qwen-32B
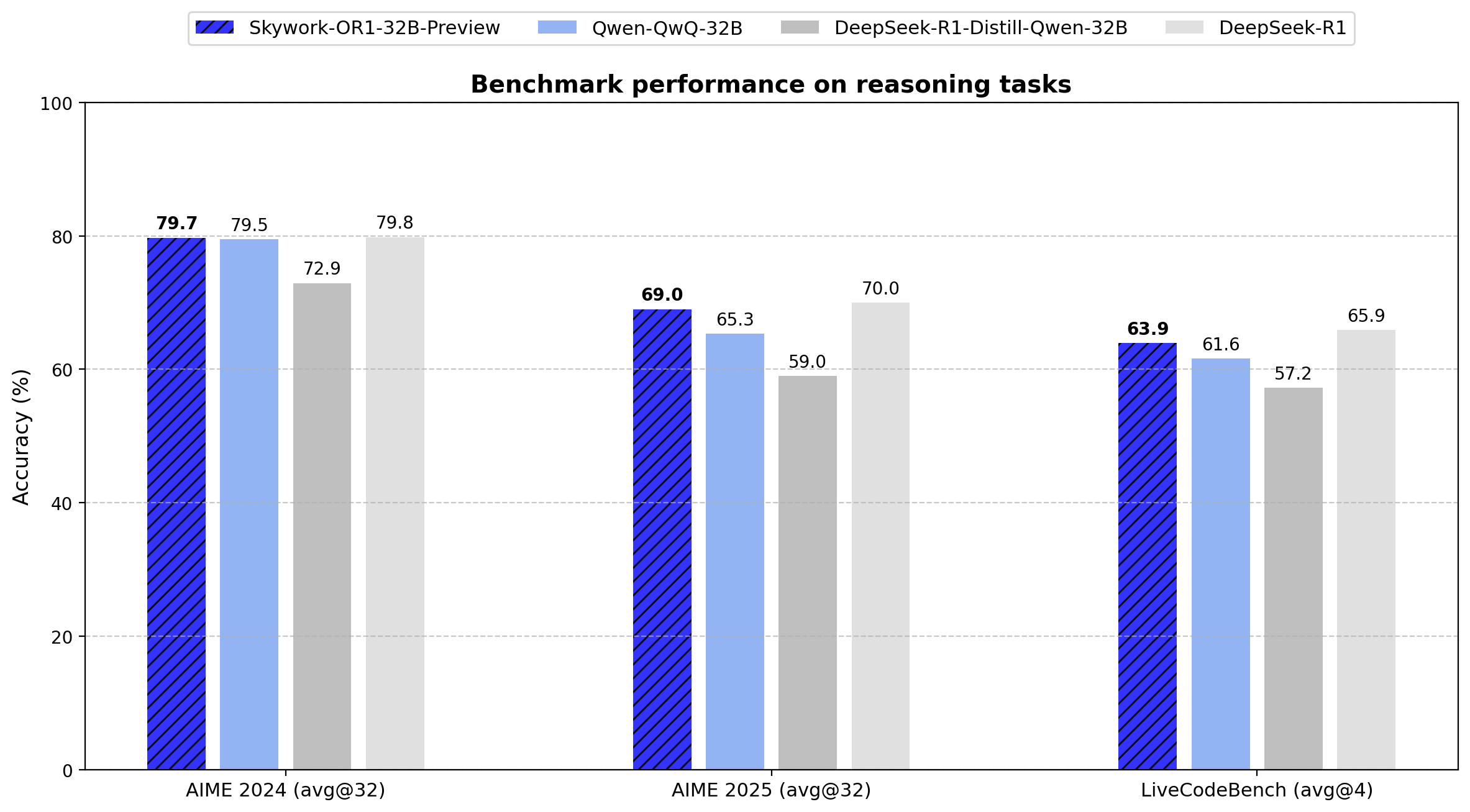
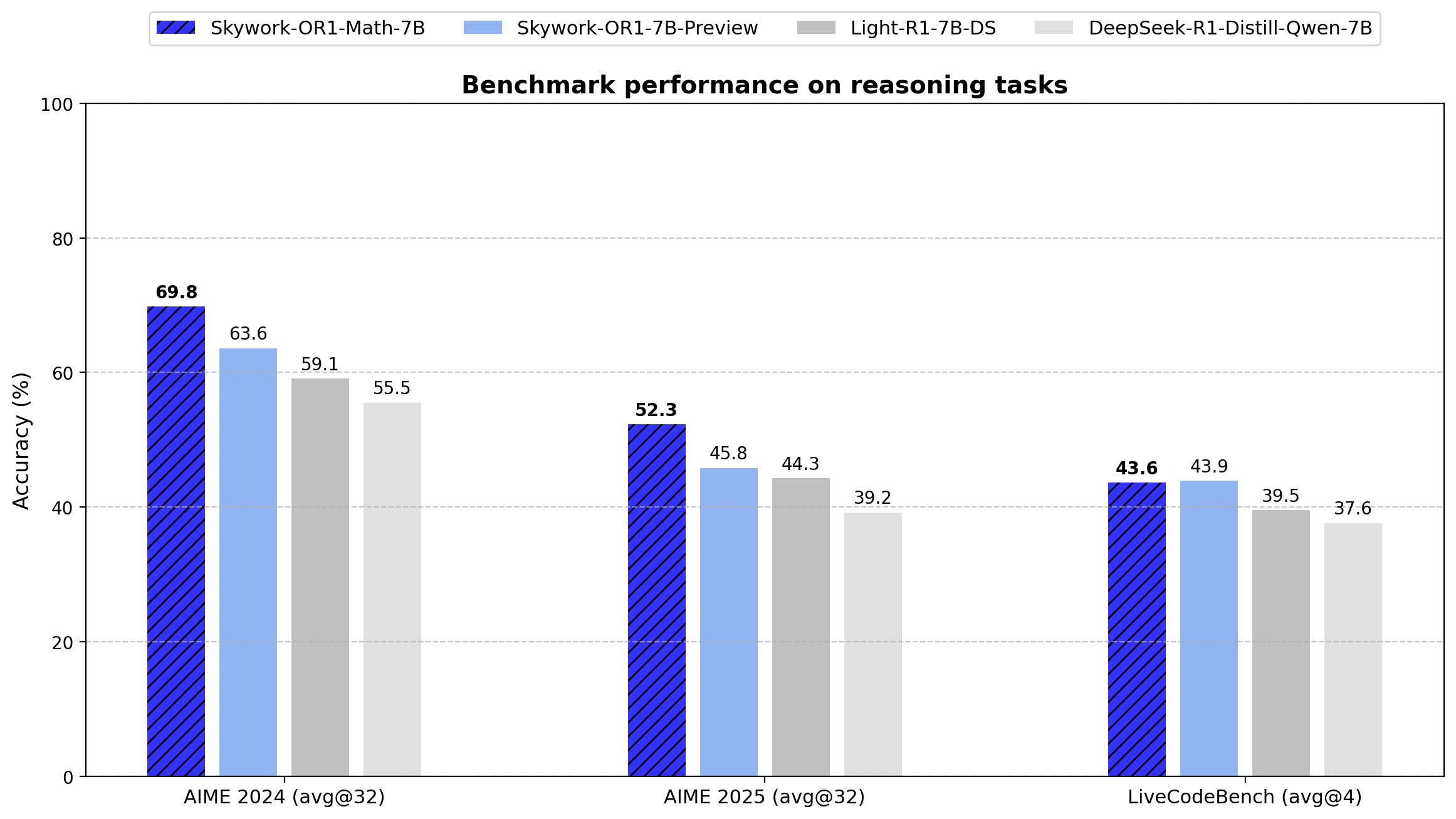
Seri Skywork-OR1 memperkenalkan Rata-rata@K sebagai metrik evaluasi utama mereka alih-alih Pass@1 konvensional. Metrik ini menghitung kinerja rata-rata di beberapa percobaan independen (32 untuk tes AIME, 4 untuk LiveCodeBench), mengurangi varians dan memberikan ukuran konsistensi penalaran yang lebih andal.
Di bawah ini adalah hasil tolok ukur yang tepat untuk semua model dalam seri ini:
| Model | AIME24 (Rata-rata@32) | AIME25 (Rata-rata@32) | LiveCodeBench (8/1/24-2/1/25) (Rata-rata@4) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.2 | 37.6 |
| Light-R1-7B-DS | 59.1 | 44.3 | 39.5 |
| DeepSeek-R1-Distill-Qwen-32B | 72.9 | 59.0 | 57.2 |
| TinyR1-32B-Preview | 78.1 | 65.3 | 61.6 |
| QwQ-32B | 79.5 | 65.3 | 61.6 |
| DeepSeek-R1 | 79.8 | 70.0 | 65.9 |
| Skywork-OR1-Math-7B | 69.8 | 52.3 | 43.6 |
| Skywork-OR1-7B-Preview | 63.6 | 45.8 | 43.9 |
| Skywork-OR1-32B-Preview | 79.7 | 69.0 | 63.9 |
Data menunjukkan bahwa Skywork-OR1-32B-Preview berkinerja hampir setara dengan DeepSeek-R1 (79,7 vs. 79,8 pada AIME24, 69,0 vs. 70,0 pada AIME25, dan 63,9 vs. 65,9 pada LiveCodeBench), meskipun yang terakhir memiliki 20 kali lebih banyak parameter (671B vs. 32,8B).
Model Skywork-OR1 dapat diimplementasikan menggunakan spesifikasi teknis berikut:
Cara Menguji Model Skywork-OR1
Berikut adalah kartu model Skywork-OR1-32B, Skywork-OR1-7B, dan Skywork-OR1-Math-7B Hugging Face:
Untuk menjalankan Skrip Evaluasi, ikuti langkah-langkah berikut. Pertama:
Lingkungan Docker:
docker pull whatcanyousee/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te2.0-megatron0.11.0-v0.0.6
docker run --runtime=nvidia -it --rm --shm-size=10g --cap-add=SYS_ADMIN -v <path>:<path> image:tag
Pengaturan Lingkungan Conda:
conda create -n verl python==3.10
conda activate verl
pip3 install torch==2.4.0 --index-url <https://download.pytorch.org/whl/cu124>
pip3 install flash-attn --no-build-isolation
git clone <https://github.com/SkyworkAI/Skywork-OR1.git>
cd Skywork-OR1
pip3 install -e .
Untuk mereproduksi evaluasi AIME24:
MODEL_PATH=Skywork/Skywork-OR1-32B-Preview \\\\
DATA_PATH=or1_data/eval/aime24.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime24_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_32b.sh
Untuk evaluasi AIME25:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/aime25.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime25_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
Untuk evaluasi LiveCodeBench:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/livecodebench/livecodebench_2408_2502.parquet \\\\
SAMPLES=4 \\\\
TASK_NAME=LiveCodeBench_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
Model Skywork-OR1 saat ini diberi label sebagai versi "Pratinjau", dengan rilis final yang dijadwalkan tersedia dalam dua minggu setelah pengumuman awal. Para pengembang telah mengindikasikan bahwa dokumentasi teknis tambahan akan dirilis, termasuk:
- Laporan teknis komprehensif yang merinci metodologi pelatihan
- Dataset Skywork-OR1-RL-Data
- Skrip pelatihan tambahan
Repositori GitHub mencatat bahwa skrip pelatihan "saat ini sedang diatur dan akan tersedia dalam 1-2 hari."

Kesimpulan: Penilaian Teknis Skywork-OR1-32B
Model Skywork-OR1-32B-Preview mewakili kemajuan signifikan dalam model penalaran yang efisien parameter. Dengan 32,8 miliar parameter, ia mencapai metrik kinerja yang hampir identik dengan model DeepSeek-R1 parameter 671 miliar di berbagai tolok ukur.
Meskipun belum diverifikasi, hasil ini menunjukkan bahwa untuk aplikasi praktis yang membutuhkan kemampuan penalaran tingkat lanjut, Skywork-OR1-32B-Preview menawarkan alternatif yang layak untuk model yang jauh lebih besar, dengan persyaratan komputasi yang berkurang secara substansial.
Selain itu, sifat sumber terbuka dari model-model ini, bersama dengan skrip evaluasi dan data pelatihan yang akan datang, menyediakan sumber daya teknis yang berharga bagi para peneliti dan praktisi yang mengerjakan kemampuan penalaran dalam model bahasa.
Ingin platform Terintegrasi, All-in-One agar Tim Pengembang Anda dapat bekerja bersama dengan produktivitas maksimum?
Apidog memberikan semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!


